Object detection에서 one-stage detector는 two-stage detector보다 간단하고 빠르지만, 정확도가 낮다. Focal Loss는 one-stage를 빠르면서도 two-stage만큼의 정확도를 달성하도록 학습하기 위해 고안되었다. 한편, 이 논문에서는 RetinaNet이라고 명명한 네트워크를 사용하였다.
1. 객체와 배경의 클래스 불균형

Object detector 학습에 사용되는 이미지는 객체(foreground)와 배경(background)의 클래스 불균형이 심하다. COCO dataset의 한 이미지에는 평균적으로 7개의 객체가 존재하지만 one-stage 모델들은 수많은 bounding box를 그린다.
- bbox 수
- YOLO v1: 98개
- YOLO v2: ~1k
- OverFeat: ~1~2k
- SSD: ~8~26k
- FocalLoss: ~100k
Some of 배경들은 구별하기 어렵기(hard negative) 때문에 informative하지만, 많은 배경들은 구별하기 쉽기(easy negative) 때문에 uninformative하다.
2. 클래스 불균형이 학습에 방해되는 이유
(논문에서는 notational convenience를 위해 (1) 대신 (2)를 사용)
one-stage detecotr의 정확도가 상대적으로 낮은 것은 많은 easy negative가 Cross Entropy loss로 학습하는 데에 방해가 되기 때문이다. Cross Entropy를 loss로 사용하면 grount truth를 높은 확률로 예측할수록 loss값이 0에 가까워지고, 낮은 확률로 예측할수록 loss값이 무한에 가까워진다. 이는 합리적으로 보이지만, object detection에서는 그렇지 않다. easy example 하나의 loss값은 작지만, 객체와 배경의 클래스 불균형으로 인한 수많은 easy negative가 모이면 전체 loss에서 차지하는 비중이 매우 커지기 때문이다. 이렇게 되면 모델이 uninformative한 부분(easy example)에 집중하게 되어 학습을 제대로 할 수 없게 된다.
해결책은 모델이 informative한 부분(hard example)에 집중하게 만드는 것이다.
3. Focal Loss
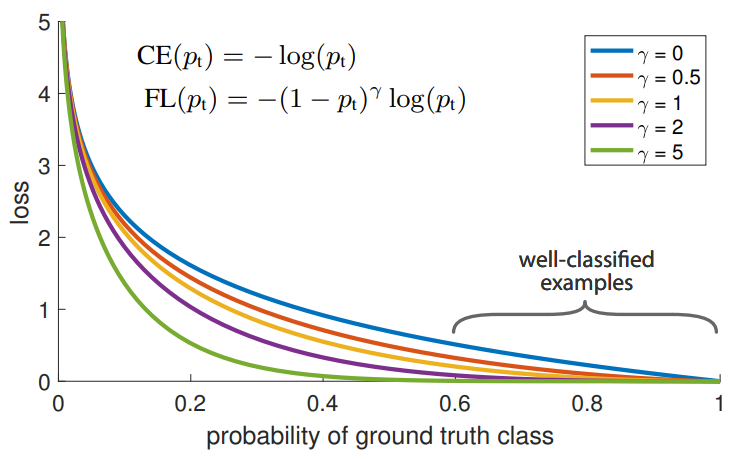
은 Focal Loss를 표현한 식이다. 이 식에서 가 1에 가까워질수록 가 0에 가까운 값이 되어 loss가 아주 작은 값이 된다. 반면 가 0에 가까워지면 은 1에 가까운 값이 되고 따라서 loss는 약간 작아질 뿐이다. 이는 아래 그림에서도 확인할 수 있다.
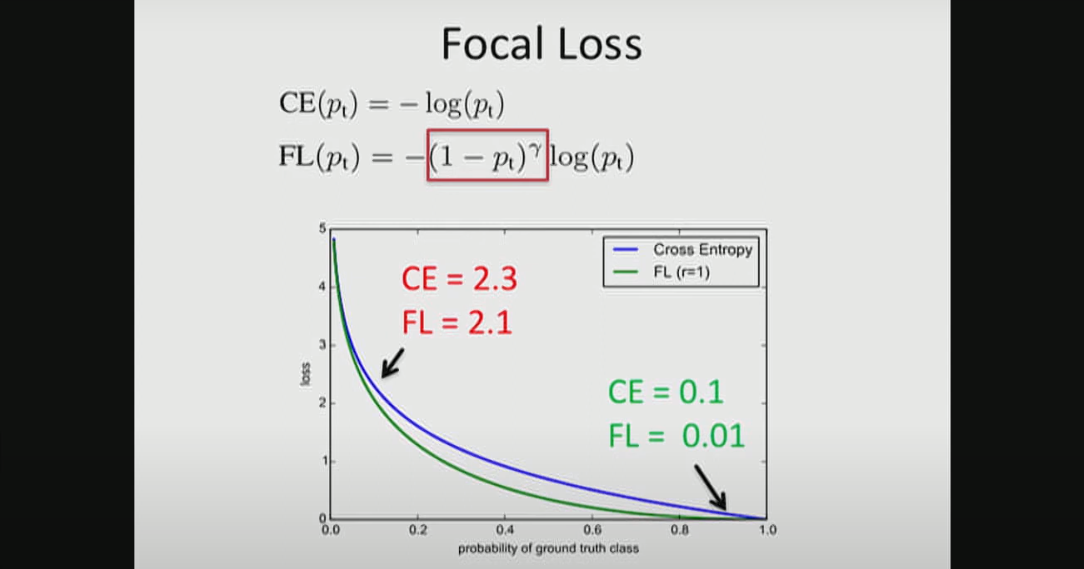
Focal Loss를 사용할 경우, easy example의 loss는 Cross Entropy의 10% 수준이 되지만, hard example의 loss는 90% 수준이 된다.
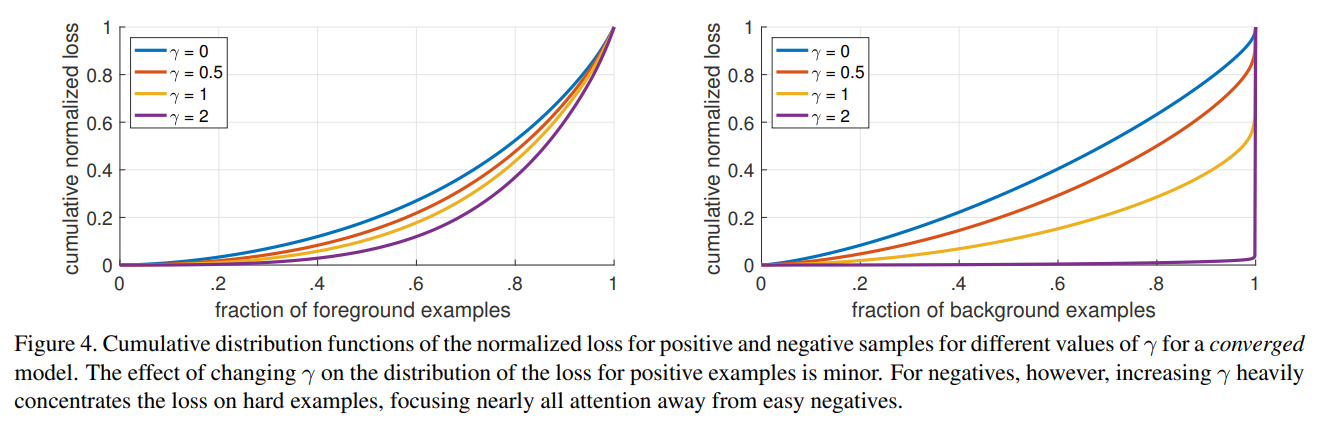
Focal Loss를 사용하면 이렇게 수많은 easy example의 loss를 크게 줄여서 모델이 informative한 hard example에 집중할 수 있도록 돕는다.
📙 참고
