5. Convolutional Neural Networks
-
Main assumption: 아래 두 가지 덕분에 FC layer에 비해 연산량이 급격히 줄어든다.
-
Spatial locality
Each filter looks at nearby pixels only. -
Positional invariance
Same filters are applied to all locations in the image.
→ 반면, X-ray 같은 경우, 폐의 위치가 정해져 있으므로 모든 곳을 볼 필요가 없다. 이렇게 domain knowledge를 활용하여 연산량을 줄이는 등 여러 효과를 기대할 수 있다.
-
-
Same padding
"첫 픽셀이 필터의 정중앙에 위치하게 하려면?"으로 접근하면 계산이 쉬워진다.- →
- →
- →
8. CNN Case Studies
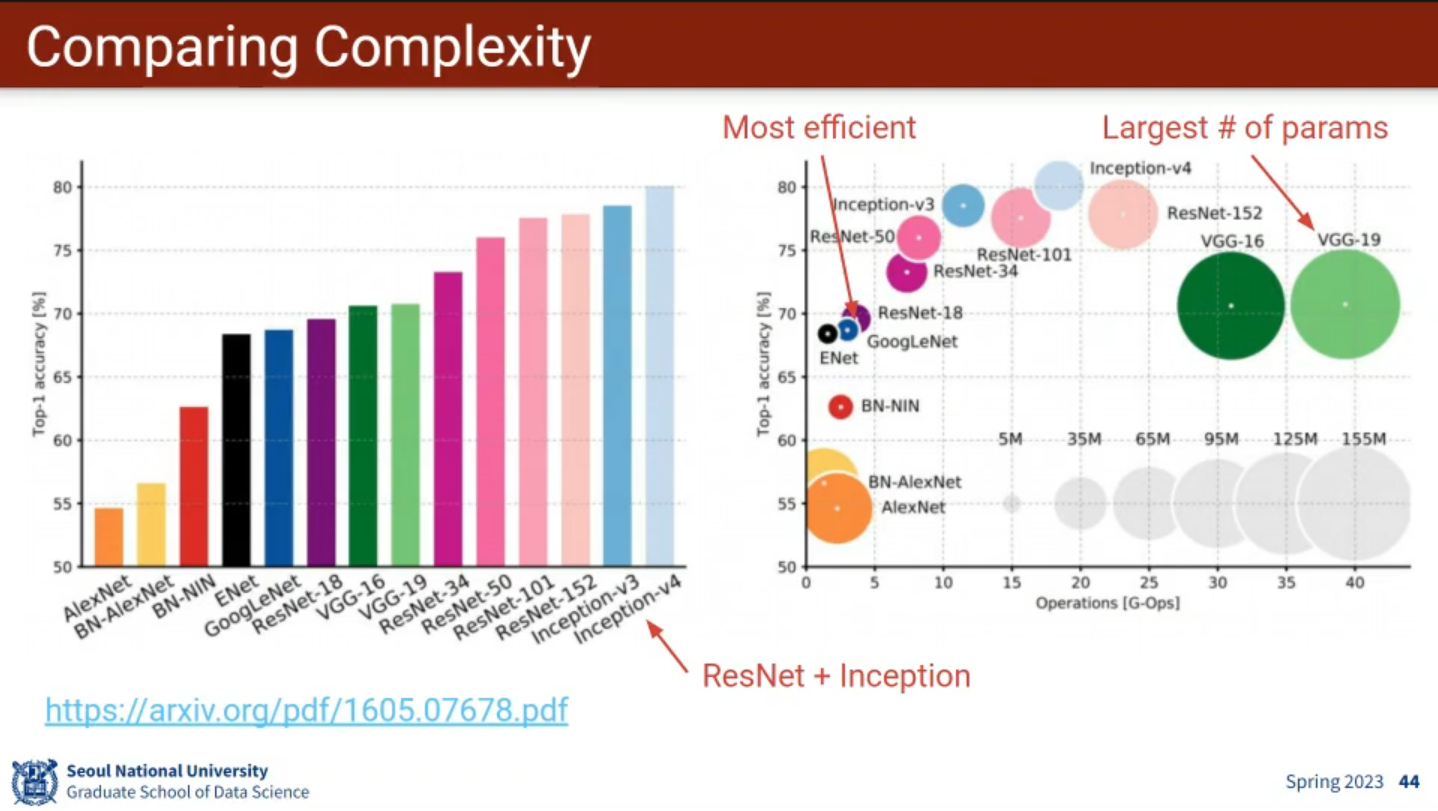
- AlexNet & ZFNet
- VGGNet
- conv filters only.
- Stacked conv (stride 1) layers has the same effective receptive field as conv layer.
- vs. where is the receptive filed size.
- With 1 layer of filter:
- With 3 layer of filter:
- The difference becomes more dramatic for larger receptive fileds.
- With more layers, we have more nonlinearities, with a better expressive power of more complicated relationships.
- Most memory is consumed in early Conv.
- Most parameters are in late FC.
- conv filters only.
- GoogLeNet (참고: zzwon1212 - GoogLeNet (1 x 1 convolution and Inception network
))- Multiple receptive filed sizes for conv . Better performance.
- Improved efficiency by using Inception module (using conv) and by avoiding expensive FC layers.
- ResNet (참고: zzwon1212 - ResNet (Deep Residual Learning for Image Recognition))
- Inception-v2, 3, 4
- ResNeXt
- DenseNet
- MobileNets
9 & 10. Video Classification
-
Tasks
- Video Classification
- Objects + Actions
- Video Retrieval
- The query may abe in various forms (e.g. test, another video, user)
- Understanding of topicality rather than fine-grained action recognition.
- Video Recommendation
- Personalized
- Video Question & Answering
- Video Prediction & Generation
- Video prediction: Given a video clip, conditionally generate the next frames.
- Unconditional video generation: Given a random seed, generate a plausible video.
- Video Compression & Learning from Compressed Videos
- Video Classification
-
Challenges
- Storage cost
- Processing
- Decompression
- N (# of frames) times inference cost, even from a pre-trained model
- More complex modeling
- Labeling cost
- Hard to scale (in terms of # videos, length, resolution)
- Copyright
- Most large video datasets provide only video features.
- Additional (time) dimension
- Capturing long context
- Temporal resolution may be different.
-
First Ideas in Action Recognition
- Single Frame
- Multiple Frames
- frame-level features to video-level classes
- score fusion
- feature fusion
- frame-level features to video-level classes
-
Action Recognition Models Overview
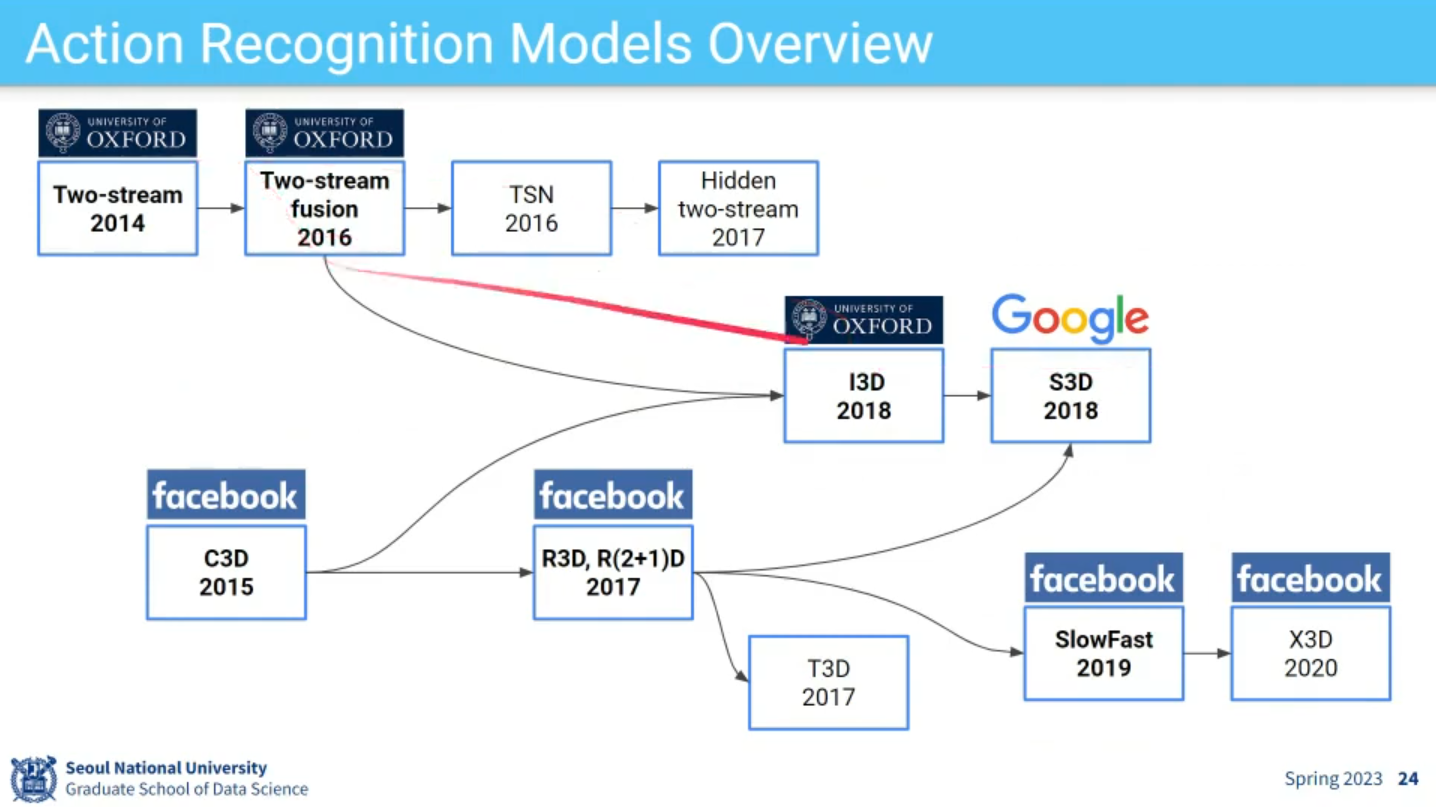
-
Two-Stream Models
explicitly separate appearance (spatial) and motion (temporal)(Optical Flow) in trainig.- Limitations
- false label assignment
- costing storage
- no end-to-end training
- Limitations
-
3D Convolution
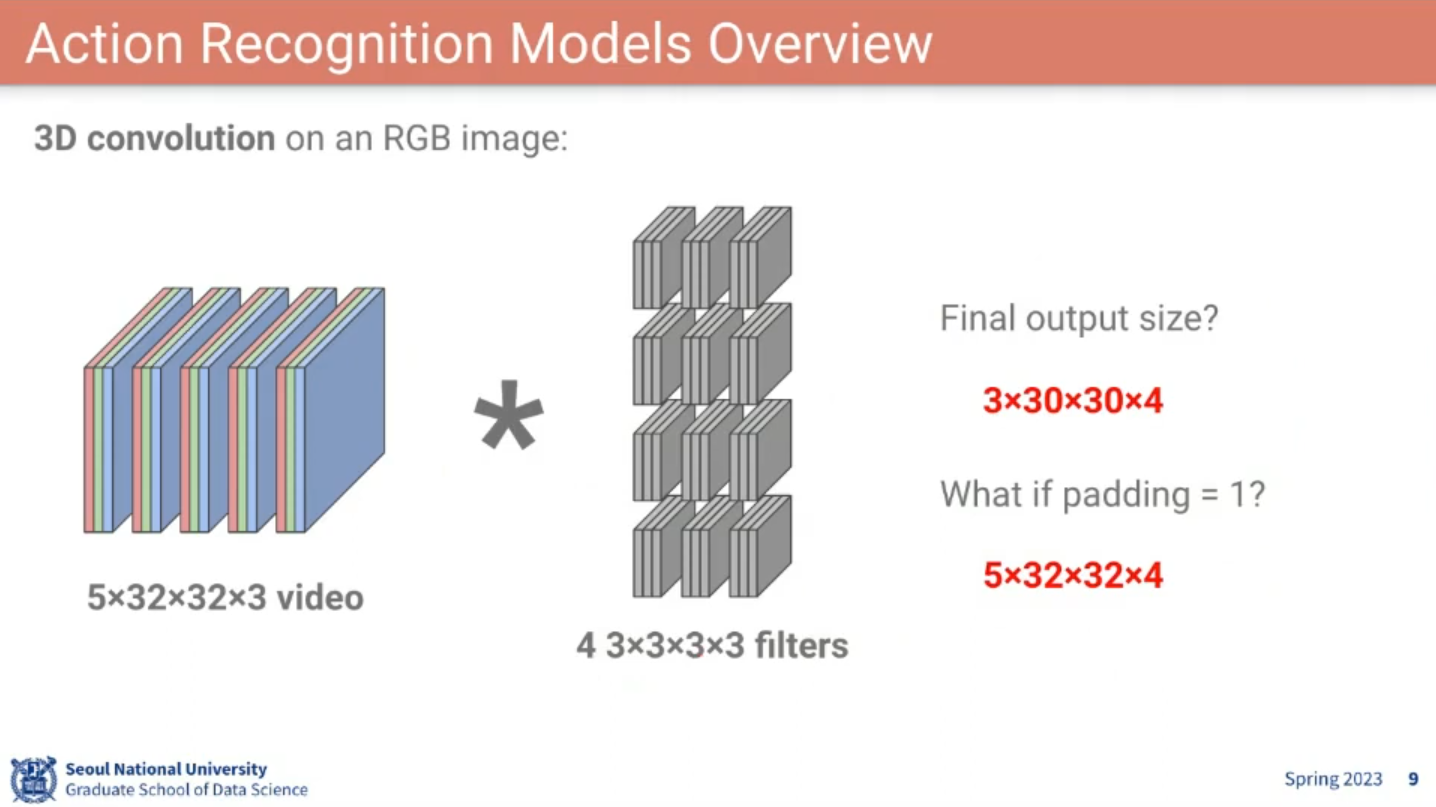
📙 강의

JUST DO IT.