2. First Approaches for Image Classification
-
Challenge in Image Classification
- Scale variation
- Viewpoint variation
- Background clutter
- Illumination
- Occlusion
- Deformation
- Intraclass variation
-
Time complexity
Prediction should be fast.
3. Loss Functions & Optimization
-
Sigmoid 값은 편의상 확률처럼 해석할 수 있지만, 엄밀하게 확률이라고 할 수는 없다.
-
Saddle point는 최저이면서 최고점, 미분값이 어디서나 0이기 때문에 문제가 됨.
-
mini-batch size
- 1개는 noisy하고, 전부는 slow하다.
- diminishing returns
size가 작을 때 이를 늘려주면 gradient estimation이 안정적이게 되지만, size가 커질수록 안정시키는 효과는 줄어들고 cost가 더욱 커지게 된다.
4. Neural Networks & Backpropagation
-
Multi layers에 non-linear layers가 없다면 그냥 linear layers, 즉, 와 다를 바 없게 됨.
-
같은 곳에서의 forward와 backward는 항상 같은 shape을 가짐.
6 & 7. Training Neural Networks
- Activation Functions
- Data Processing
- Data Augmentation
- Weight Initialization
- Learning Rate Scheduling
- Regularization (참고: zzwon1212 - L2 Regularization)
- Lasso는 대부분의 점이 ◇의 꼭짓점으로 모이게 된다. 즉, 중요하지 않은 (weight)의 대부분이 0이 된다. "encouraging sparser representation"
- Weight Decay
- Dropout
test 때 scale 고려할 필요가 없도록 train 때 scale 변화에 대응해야 한다. 라이브러리 사용하면 다 반영해 준다. - Data Augmentation
- Early Stopping
- Opimization (참고: zzwon1212 - Optimizer)
- SGD의 문제점
- When the loss changes much quickly in one direction than another, SGD progresses very slowly, jittering along the steep direction.
- Saddle point
- Estimation using mini-batch may not be accurate.
- Momentum
- AdaGrad
- RMSprop
- Adam
- SGD의 문제점
- Batch Normalization (참고: zzwon1212 - Batch Normalization)
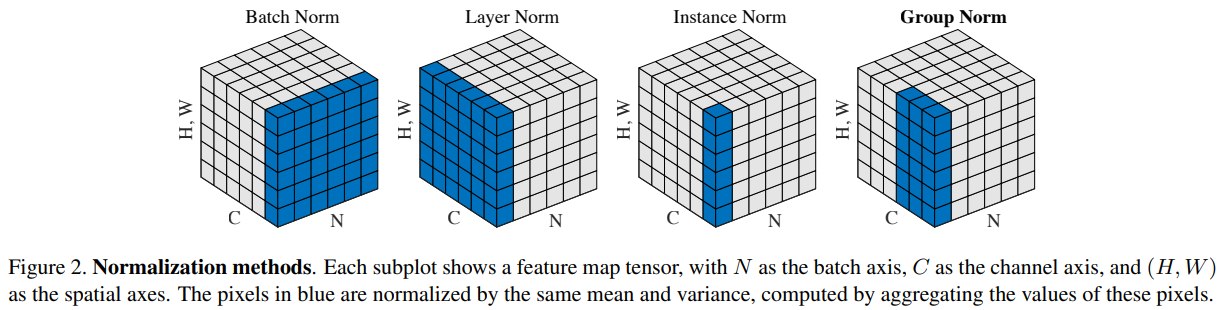
- Batch Norm
- Layer Norm (?)
- Transfer Learning
📙 강의

JUST DO IT.