18 & 19. Multimodal Learning
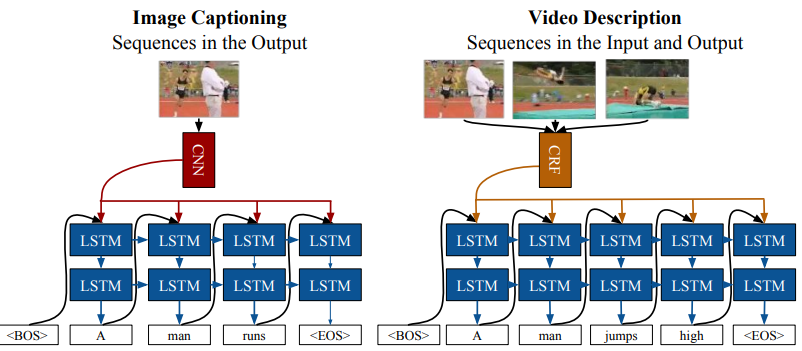
18.1. Image Captioning
18.1.1. LRCN for Image Captioning
18.1.2. NCE for Image Captioning
- (참고: zzwon1212 - NCE)
- positive pairs
- negative pairs
- Overall objective function
- where
- where
18.1.3. Show, Attend, and Tell
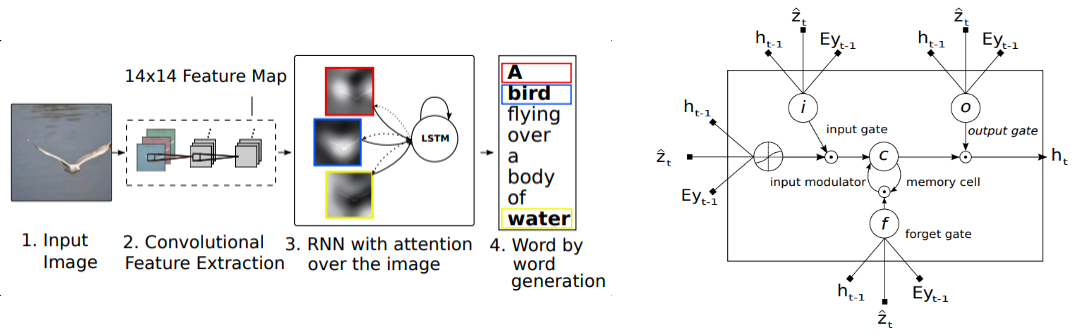
- The output word probability
- Encoded word:
- Query:
- Key: (annotation vectors from CNN)
- Value:
- Attention Score:
- Attention Coefficients:
- Attention Value:
- Model Parameters:
18.2. Video Captioning
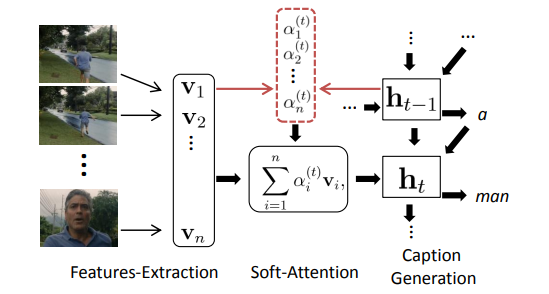
18.2.1. Temporal Attention for Video Captioning
18.3. Transformer-based Image-Text Models
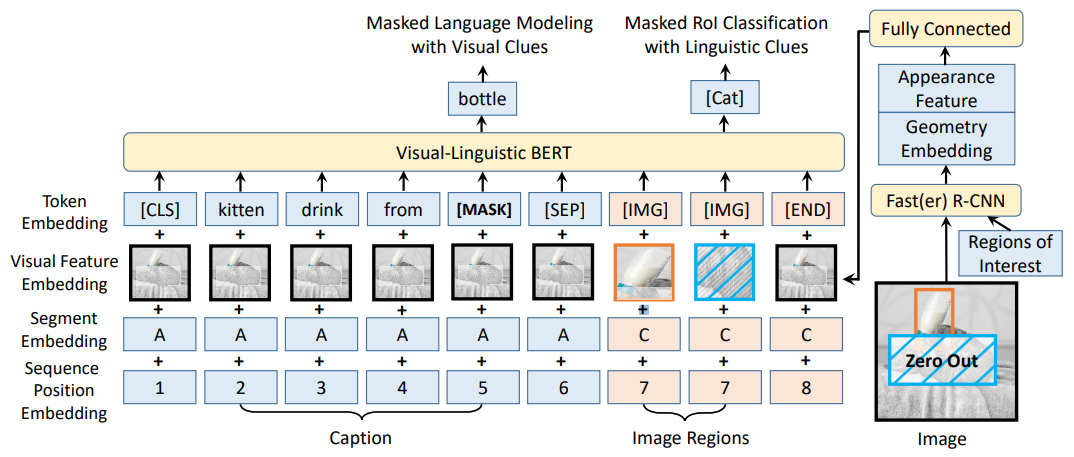
18.3.1. VL-BERT
-
Text part
- is almost identical to the original BERT, except
- For the visual feature, the entire image feature is added by default.
- Segment embedding: A is for text, B is for another text (for VQA), C is for image.
- MLM itself is the same, but it now attends the visual tokens as well as other words.
-
Image part
- is new.
- Using Fast(er) R-CNN, RoI are extracted, and each of them is treated as a token.
- Similarly to MLM, some RoIs are zeroed out.
- Masked RoI classification: classify the zeroed out region based on context (visual + linguistic).
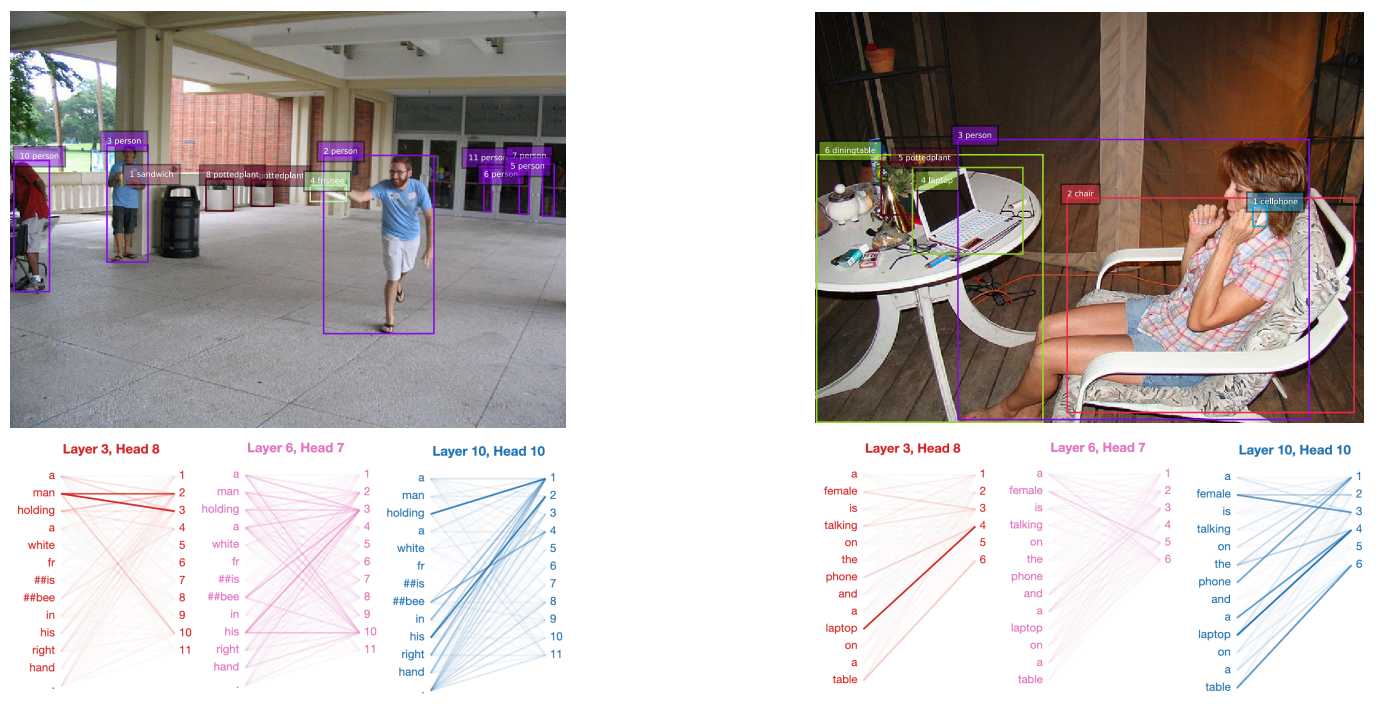
18.3.2. VilBERT
- Similar to VL-BERT, but added cross-modal attention within the BERT.
- Image region features are extracted using a pre-trained Faster R-CNN model.
- Text tower is embedded using a pre-trained BERT model, then goes through additional Transformer blocks. No such additional tuning on visual side.
- Each tower repeatedly attends cross-modal and itself, similarly to the Transformer decoder.
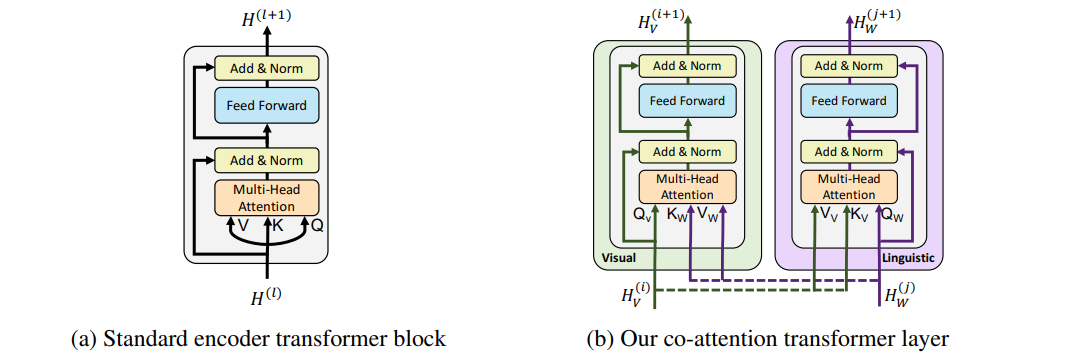
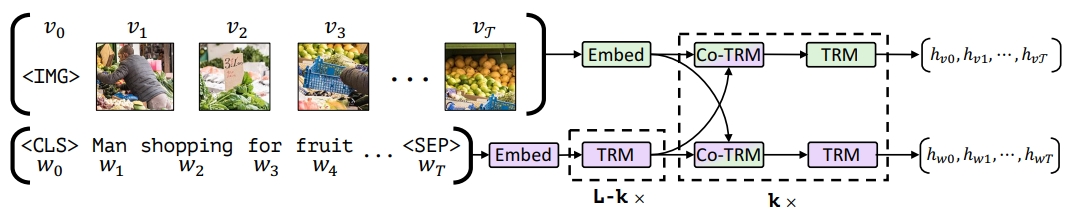
- Co-attention Transformer layer
- Q is from the self-mode.
- K, V are from the other side.

- Caption-Based Image Retrieval

19.1. Transformer-based Video-Text Models
19.1.1. VideoBERT
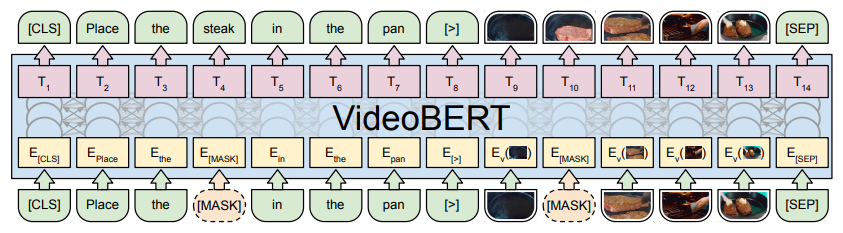
-
VideoBERT
- Frames are sampled temporally.
- S3D features are extracted to represent each frame (1024-D).
- Both visual and text (ASR) are from a part of a video.
- The main training task is temporal correspondence between the frames and ASR.
-
Training
- Linguistic-Visual alignment task: From [CLS] token, classify if the input video clip and text is aligned or not.
- Masked language modeling (MLM): Same as BERT
- Masked frame modeling (MFM): Similar to MLM; Classify the image cluster

-
Downstream Tasks
- Recipe illustration

- Future frame prediction

- Zero-shot action classification

- Video captioning
- Recipe illustration
19.1.2. CBT (Contrastive Bidirectional Transformer)

-
Visual and text towers are trained separately with unimodal BERTs, followed by cross-modal Transformer to learn multimodal correspondence.
- c.f., VilBERT mixed cross-modal and unimodal attention repeatedly.
-
NCE loss does not need labels.
-
The entire model is trained end-to-end, weighted-summing all three losses (BERT, CBT, Cross-modal).
- End-to-end training was not possible with VideoBERT, due to the frame clustering.
- Now, with the NCE loss, the entire training can be done end-to-end.
19.1.3. Hammer
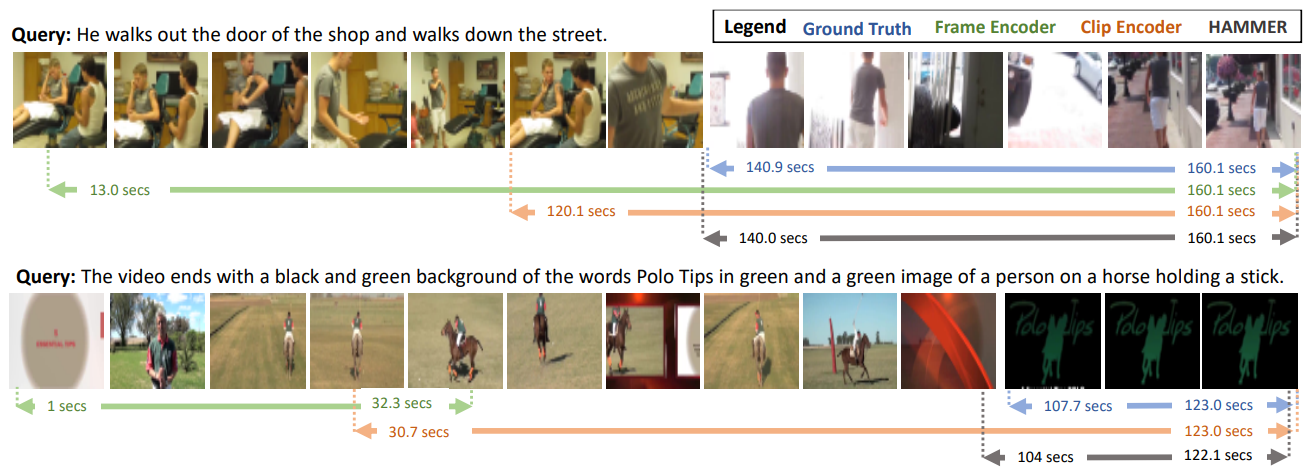
-
Task: Moment localization in Video Corpus (MLVC)
-
Two-Stage approach
- Video retreival
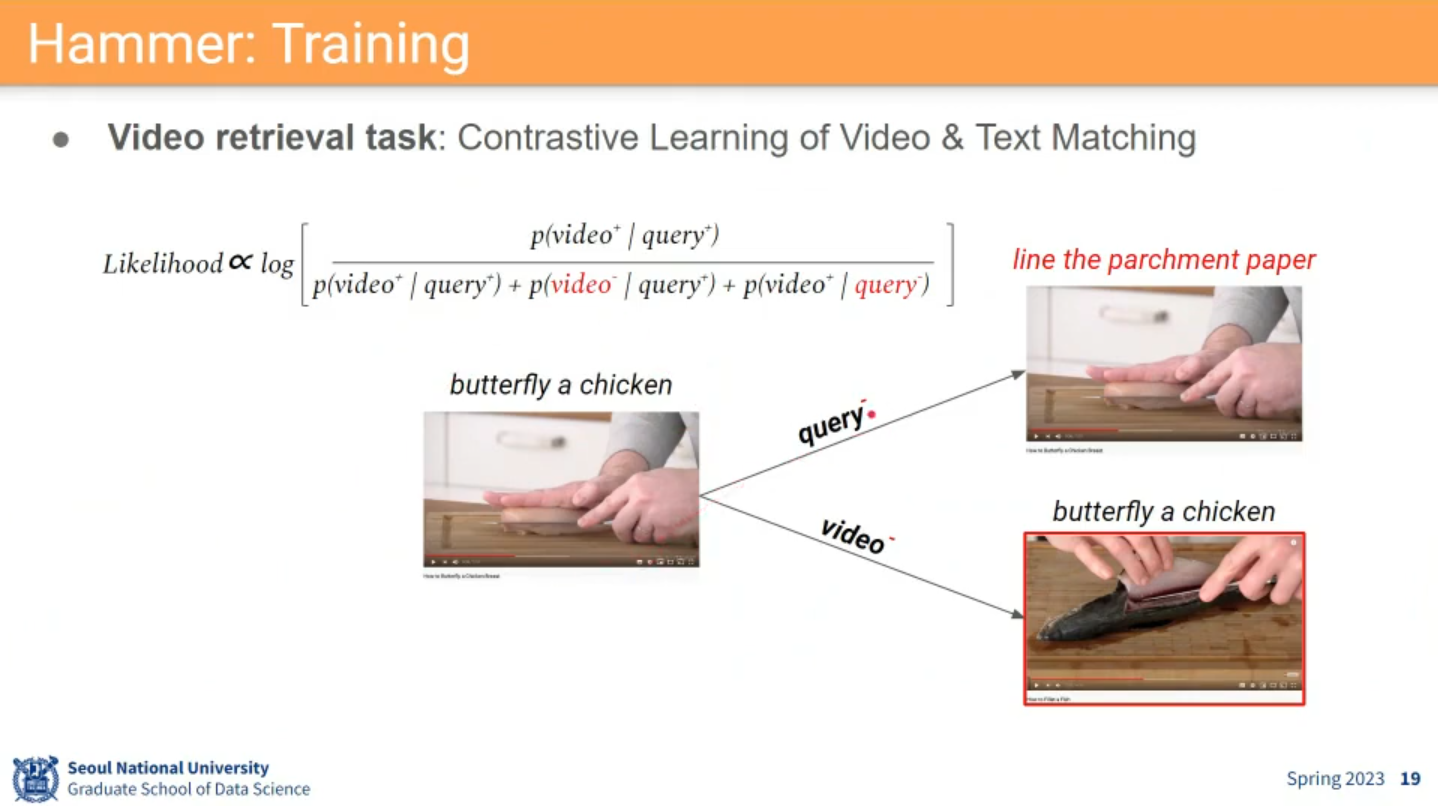
- Moment localization in (top-k) single video
- Video retreival
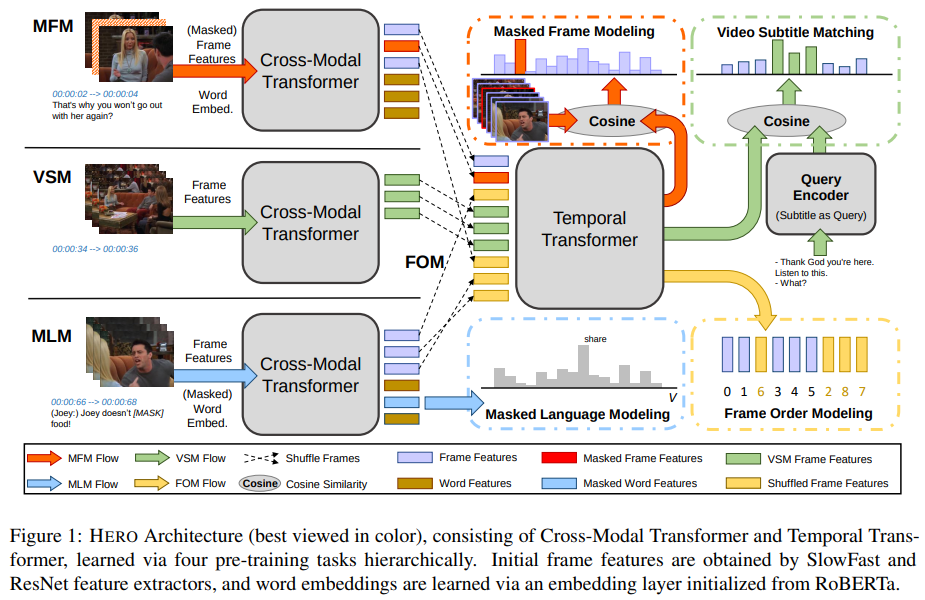
19.1.4. HERO
- Hierarchical Encoder for Video+Language Omni-representation Pre-training
19.1.5. MERLOT
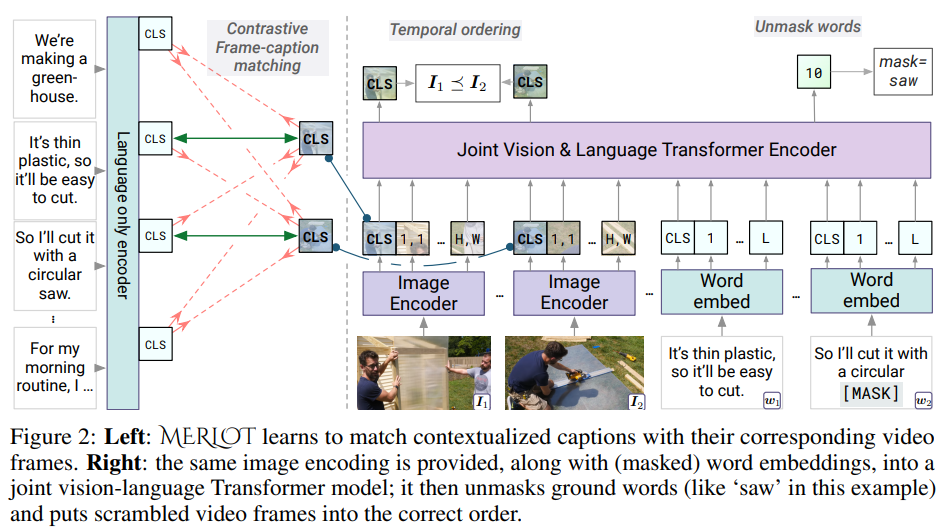
-
Learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech (ASR) - in an entirely label-free, self-supervised manner.
-
Learning objectives
- Frame-level (spatial): to match images to temporally corresponding words
- Video-level (temporal): to contextualize what is happening globally over time
19.2. Audio Modeling
- Spectrogram
19.2.1. AST (Audio Spectrogram Transformer)
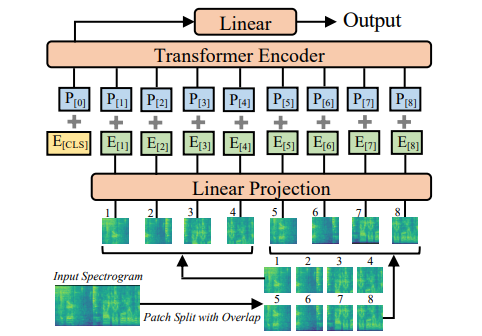
- ViT-like Transformer model (참고: zzwon1212 - ViT)
- ViT requires lots of data, but no such data exists for audio. Hence, ImageNet-pretrained ViT is used to initialize the weights.
19.2.2. VATT
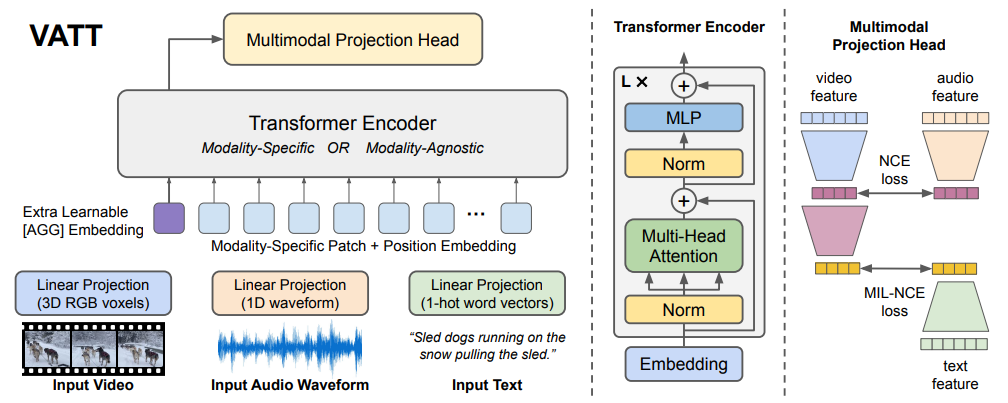
-
Visual + Audio + Text
-
(Multimodal) Contrastive learning setting
- (at section 3.4. in the paper)
- Positive pairs: streams from the same location in the video
- Negative pairs: from any non-matching locations in the video
-
Multimodal Projection Head
- Video and Audio have fine-grained information.
- Text has coarse-grained information.
- Common Space Projection (at section 3.3. in the paper)
19.3. Multimodal Metric Learning
19.3.1. CLIP
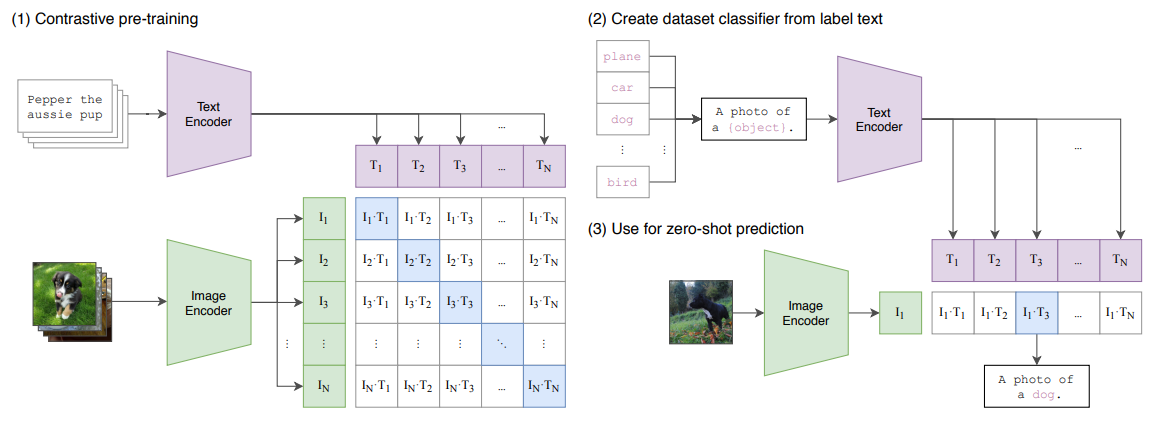
-
A multimodal metric learning using large-scale paired dataset
- At training: Jointly trains an image encoder and a text encoder to predict the correct-pairings of a batch of (image, text) training examples.
- Mathematically, identical to making the outer-product of image and text matrices closer to an identity matrix. (the same as contrastive learning or NCE loss)
- At testing: the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the targe dataset's classes.
- To make this as a classifier, use a text prompt: "A photo of a ____". Because in pre-training dataset, the text is usually a full sentence.
- At training: Jointly trains an image encoder and a text encoder to predict the correct-pairings of a batch of (image, text) training examples.
-
The text and image encoders are useful themselves!
- Image embedding is semantically powered by language pairs.
- Text embedding is also powered by visual cues.
- Common use cases
- Embed a text, then retrieve the closest images / videos.
- Embed an image, then select / generate a sentence describing it.
19.3.2. MuLan
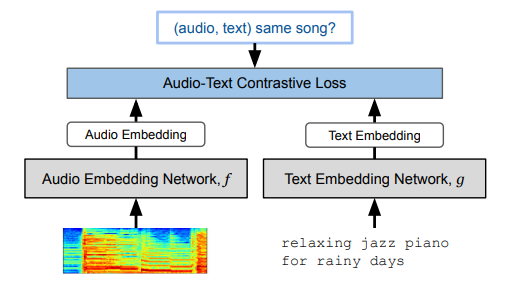
- Music-Language matching: Audio / Music version of CLIP
📙 강의
