R Girshick. Fast R-CNN. ICCV 2015.
1. 문제 정의
R-CNN은 느리고 복잡하다. 아래는 Fast R-CNN 논문이 제시한 R-CNN의 단점이다.
-
Training is a multi-stage pipeline.
fine-tuning → fitting detectors (SVMs) → fitting regressor -
Training is expensive in space and time.
SVM, bbox regressor를 training할 때, 한 이미지의 각 proposal마다 feature를 계산해야 하므로 느리며, 이 feature를 저장해 두어야 하기 때문에 많은 저장 공간이 필요하다. -
Object detection is slow.
test-time에 한 이미지의 각 proposal마다 feature를 계산해야 하므로 느리다.
결국 multi-stage pipeline 그리고, 한 이미지에서 여러 번의 convolutional forward pass가 문제였다.
1.1. 한 이미지에서 여러 번의 convolutional forward pass
-
Spatial pyramid pooling (SPP)
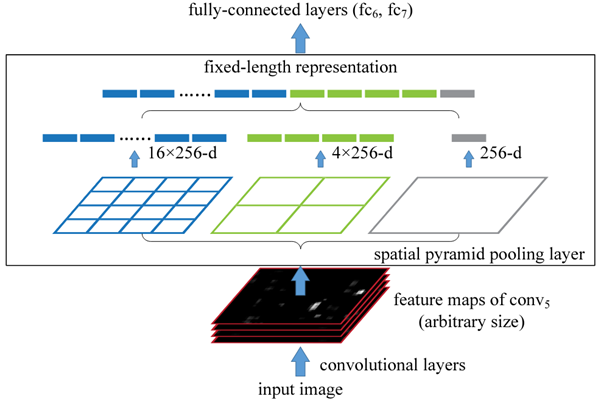
SPPnet은 SPP로 여러 번의 forward pass 문제를 효과적으로 풀어냈고, R-CNN의 느린 속도를 개선하였다. 핵심은 한 이미지에서 convolutional feature를 한 번만 계산해도 되도록 한 것이다. 각 proposal의 feature는 이 shared feature map으로부터 projection을 통해 추출하였다. 이렇게 추출된 각 proposal의 feature는 그 크기가 다양하다. 그러나 fully-connected layer는 고정된 크기의 input을 요구하므로 이 다양한 크기의 feature에 SPP를 적용하여 고정된 크기의 feature로 max-pooling하였다. 이로써 R-CNN보다 3배 빠른 training-time, 10~100배 빠른 test-time을 얻게 되었다. 그러나 SPPnet 역시 여전히 multi-stage였다. 또한 SPP 이전에 위치한 conv layers를 update할 수 없었고, 이는 아주 깊은 network의 정확도를 제한하였다.
-
ROI pooling layer
Fast R-CNN은 여러 번의 forward pass 문제를 RoI pooling layer로 해결하였다. RoI pooling layer는 SPP의 special case로써 하나의 pyramid level만을 사용한 것이다. 또한 conv layers를 update하지 못했던 SPP의 단점은 hierarchical sampling으로 해결하였다. ?.?
1.2. multi-stage pipeline
- Multi-task loss
Fast R-CNN은 multi-task loss를 이용하여 multi-stage 학습을 단 한 번의 학습으로 개선하였다. ?.?
이로써 R-CNN은 아래 세 가지의 main results를 얻게 되었다.
- SOTA mAP
- training과 testing 시간 단축
- conv layers의 update를 통한 mAP 향상
2. Fast R-CNN
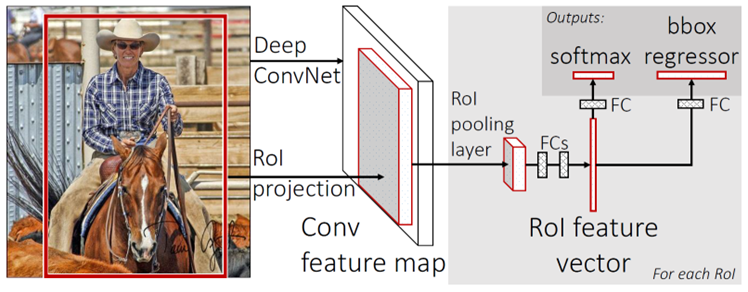
1) 한 이미지에서 conv feature map을 한 번만 계산
2) 각 proposal을 shared feature map에 projection하여 feature map 얻기
3) 크기가 제각각인 proposal의 feature map에 RoI pooling을 적용하여 고정된 크기의 feature vector 추출
4) fc layers를 지나며 classification ()과 regression ( values for each classes) 결과를 출력
2.1. RoI Pooling Layer
(참고 - PyTorch source code)
RoI pool은 먼저 아래 식과 같이 RoI를 shared feature map으로 projection한다.
- : original pixel coordinate of RoI
- : shared feature map에서 RoI의 pixel coordinate
- : round
- : feature map stride (VGG16의 경우 16)
이후 feature map에서의 RoI에 max-pooling을 적용하며, input과 output은 아래와 같다.
-
Input
arbitrary 크기 ()인 RoI의 feature map -
Output
고정된 크기 () (e. g. )인 feature map
이때 bins에서 ()-th bin의 max-pooling은 아래 범위에서 이루어진다.
- : floor
- : ceil
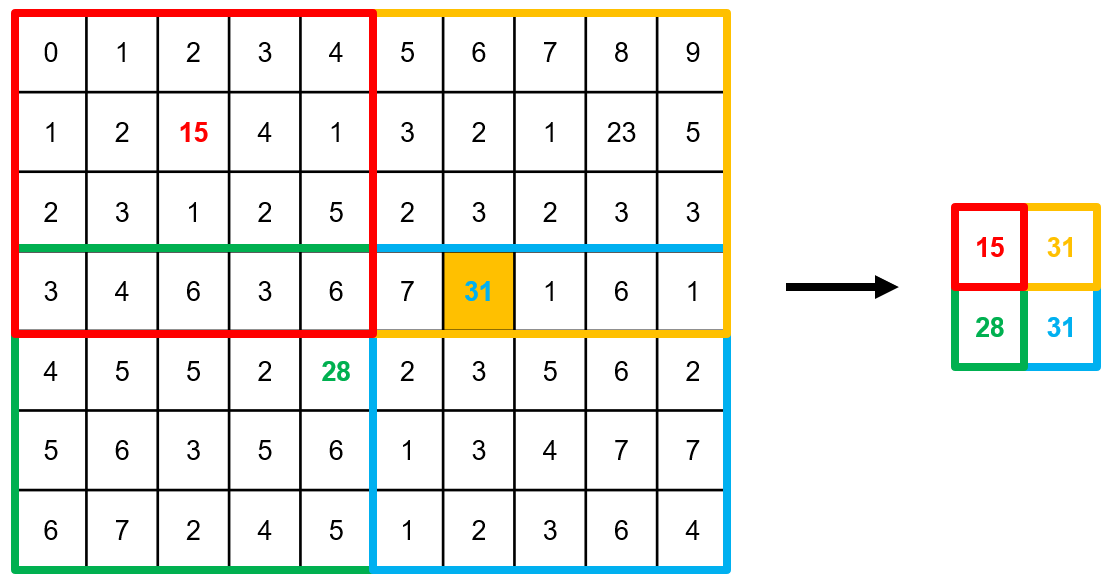
예를 들어 ()인 input feature map을 ()인 output feature map으로 만들면 아래와 같다.
2.2. Fine-tuning
모델의 훈련은 다음과 같이 진행하였다.
-
ImageNet 데이터로 pre-train
-
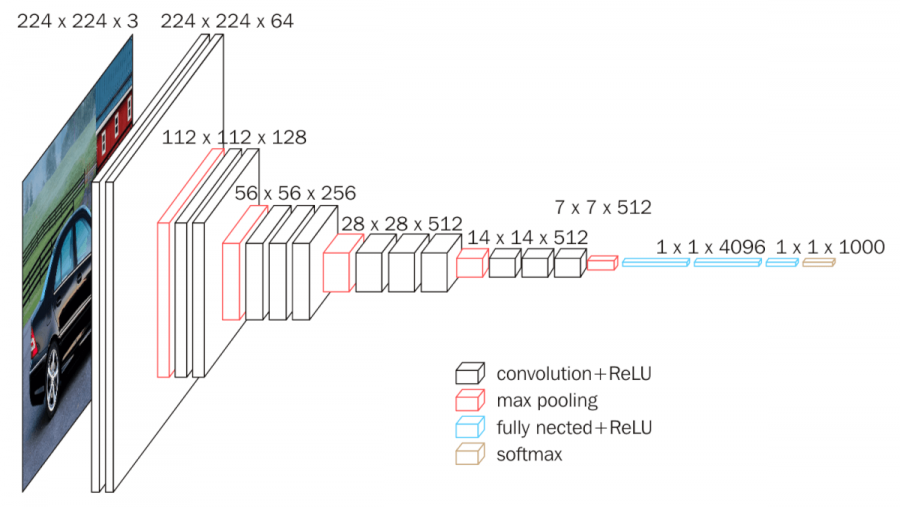
모델의 깊이와 넓이에 따라 S, M, L로 구분. L의 경우 위 그림의 VGG16 구조.
-
첫 번째 fc layer와 맞도록 하기 위해 마지막 max pooling layer를 고정된 크기를 출력하는 RoI pooling layer로 변경.
-
마지막 fc layer와 softmax (1000-way)를 아래와 같이 변경.
- classes를 구별하는 classfier
- 각 클래스마다 4개의 실수로 encoding된 refined bbox의 위치를 출력하는 category-specific regressor로 변경.
논문의 2.2 initializing 포함, 2.3까지 작성
2.2.3. hierarchical sampling (IoU 기준 포함)
2.2.4. multi-task loss
2.3. Truncated SVD
3. Experiments
3.1. Results on VOC 2007, 2010 and 2012
-
VOC 2012

Fast R-CNN은 가장 높은 mAP를 기록하였다. 또한 R-CNN pipeline을 이용한 다른 methods보다 100배 더 빨랐다.
-
VOC 2010

SegDeepM이 Fast R-CNN보다 높은 mAP를 기록하였다. SegDeepM은 R-CNN에 Markov random field을 적용하였다. R-CNN 대신 Fast R-CNN을 사용하면 더 나은 결과를 얻을 수 있을 것이다.
-
VOC 2007
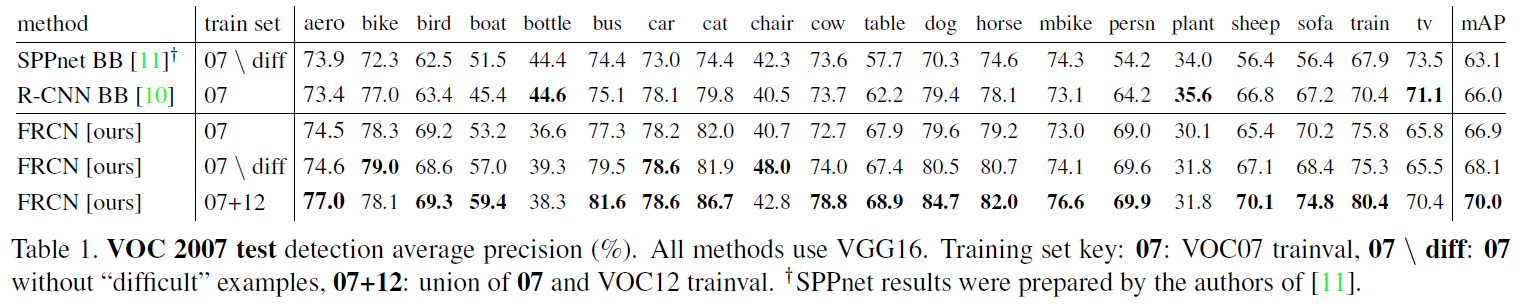
SPPnet은 training과 testing에서 5개 scales를 사용하였지만, single scale을 사용한 Fast R-CNN이 더 높은 mAP를 기록하였다.
3.2. Trainig and Testing Time
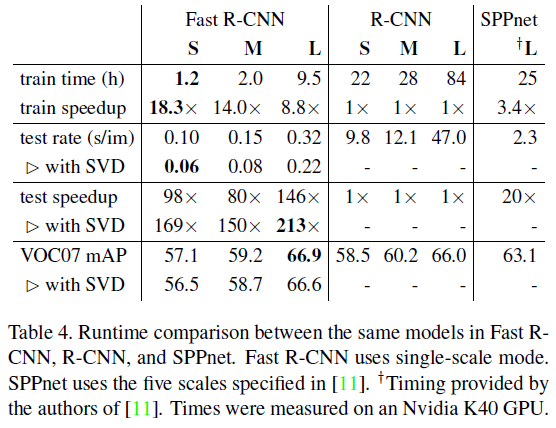
VGG16을 사용한 Fast R-CNN은 R-CNN에 비해 train에서 약 9배, test에서 146배 더 빨라졌다. SPPnet과 비교해도 역시 빨라졌다. 또한 Fast R-CNN은 feature를 저장하지 않아도 되었기 대문에 수백 기가의 저장 공간을 절약하였다.
3.3. Truncated SVD
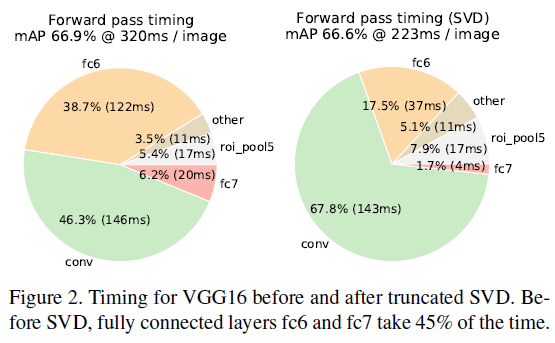
truncated SVD는 아주 작은 mAP의 감소만을 가져오며 detection time을 30% 가까이 줄였다. compression 이후 fine-tuning을 진행한다면, 더 적은 mAP drop만으로 더 빠른 detection이 가능할 것이다.
3.4. Which Layers to Fine-tune?

덜 깊은 network를 이용한 SPPnet은 fc layers만을 fine-tuning하였고, 충분히 좋은 정확도를 보였다. 그러나 Fast R-CNN은 VGG16과 같은 깊은 network에서는 conv layers도 fine-tuning하는 것이 중요하다고 가정하였다. 이를 위해 먼저 fc layers만을 update하였는데, SPPnet보다 낮은 mAP를 기록하였다. 이후 conv3_1까지 update한 경우와 더 깊이 conv2_1까지 update한 경우를 비교하였다. 후자가 더 높은 mAP를 기록하였지만 0.3밖에 상승하지 않았고, training은 1.3배 오래 걸렸다. 따라서 conv3_1까지만 update하였다.
3.5. Multi-task Training

multi-task training은 복잡한 pipeline이 없기 때문에 간편하면서도, shared conv layers를 통해 각 task가 서로에게 영향을 주기 때문에 더 나은 성능을 얻을 수 있다.
bbox regressors (test-time에 제외)는 pure classification accuracy를 0.8~1.1 mAP points 향상시켰다.
stage-wise와 multi-task의 비교에서는 multi-task가 더 높은 mAP를 기록하였다.
이로써 multi-task training이 성능에 기여함을 확인하였다.
3.6. SVM vs. Softmax
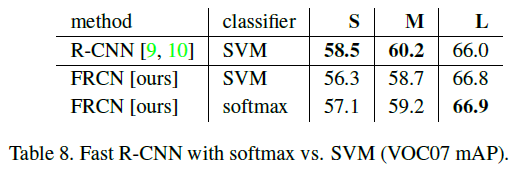
작은 차이지만 softmax가 SVM보다 나은 결과를 얻음으로써 one-shot fine-tuning이 충분함을 증명하였다.
3.7. More Proposals

solid blue line을 보면 proposals가 늘어나는 경우 오히려 정확도를 낮추는 것을 확인할 수 있다.
solid red line을 보면 proposals가 늘어나는 경우 AR은 mAP와 uncorrelate함을 알 수 있다.
4. Conclusion
