1. Residual block
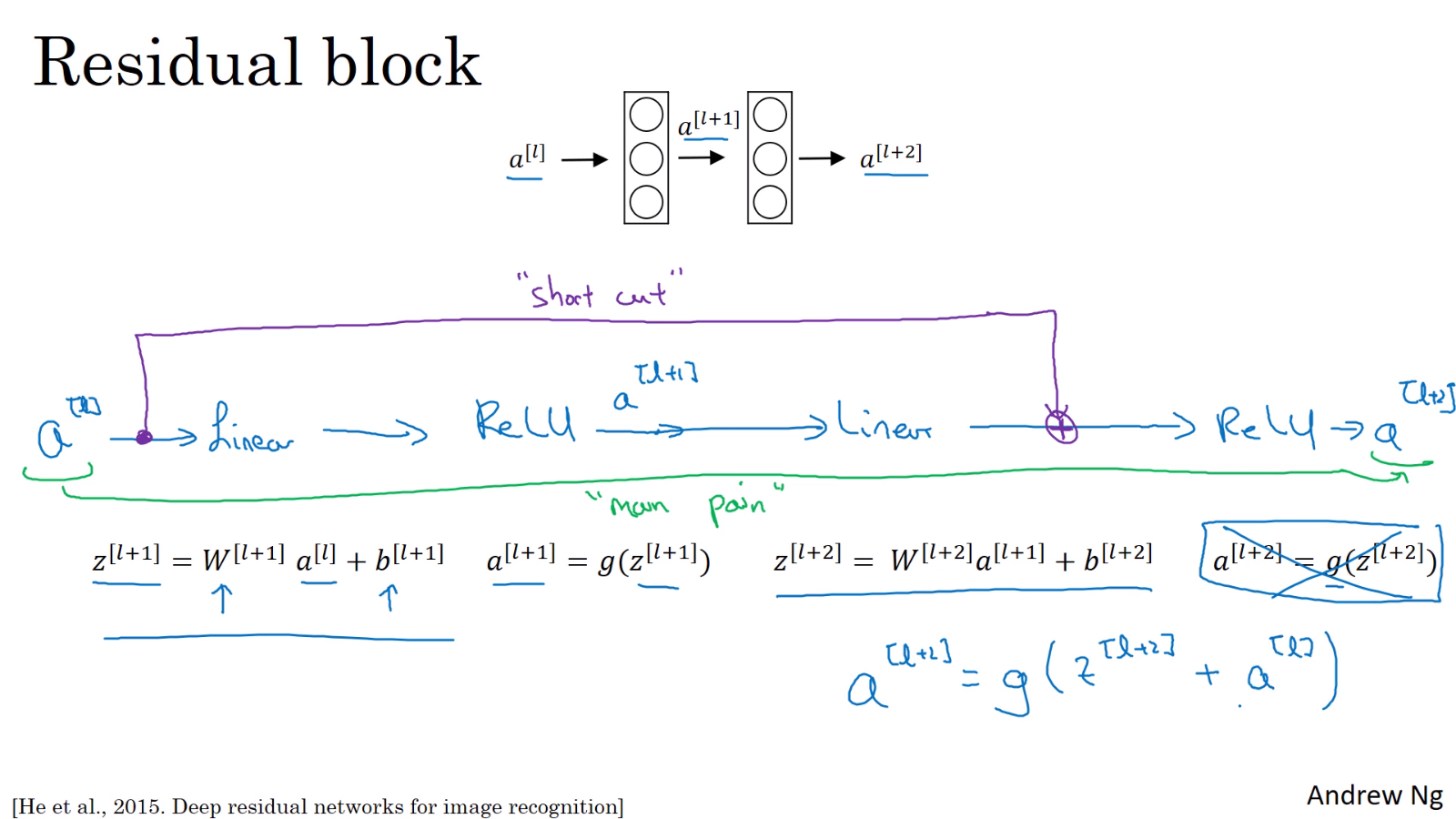
활성화 함수 출력값인 를 main path와 shortcut, 두 길로 통과시킨다. main path는 일반적인 딥러닝 네트워크의 forward 방식이지만, shortcut은 몇 개의 layer를 건너뛴 후 목표 지점의 linear 연산 이후, 활성화 함수 이전 위치에 대입해주는 방식이다. shortcut은 skip connection이라고 불리기도 한다. ResNet은 이러한 residual block을 쌓아서 만든 신경망이다.
2. ResNet (Residual Network)
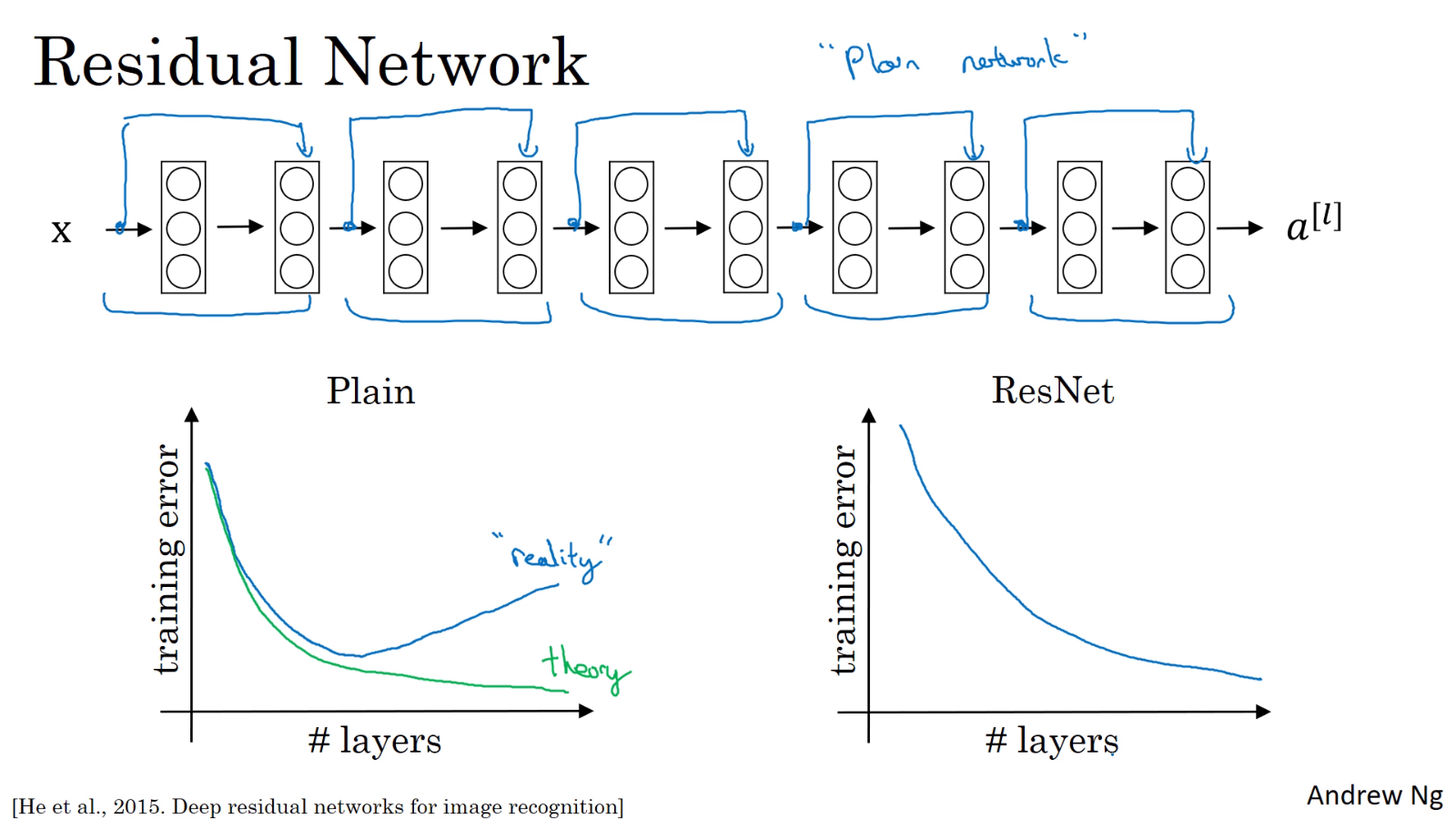
이론상 신경망의 층이 깊어질수록 training error가 감소한다. 하지만 실제로는 residual block이 없는 "plain network"는 신경망의 층이 깊어지면 training error가 감소하다가 다시 증가하는 경향을 보인다. 반면에 ResNet은 신경망의 층이 깊어지더라도 이론대로 training error가 계속 감소한다.
이처럼 residual block은 vanishing or exploding gradient problem을 해결하고 훨씬 깊은 네트워크를 학습할 수 있게 해준다.
3. Why ResNets work?
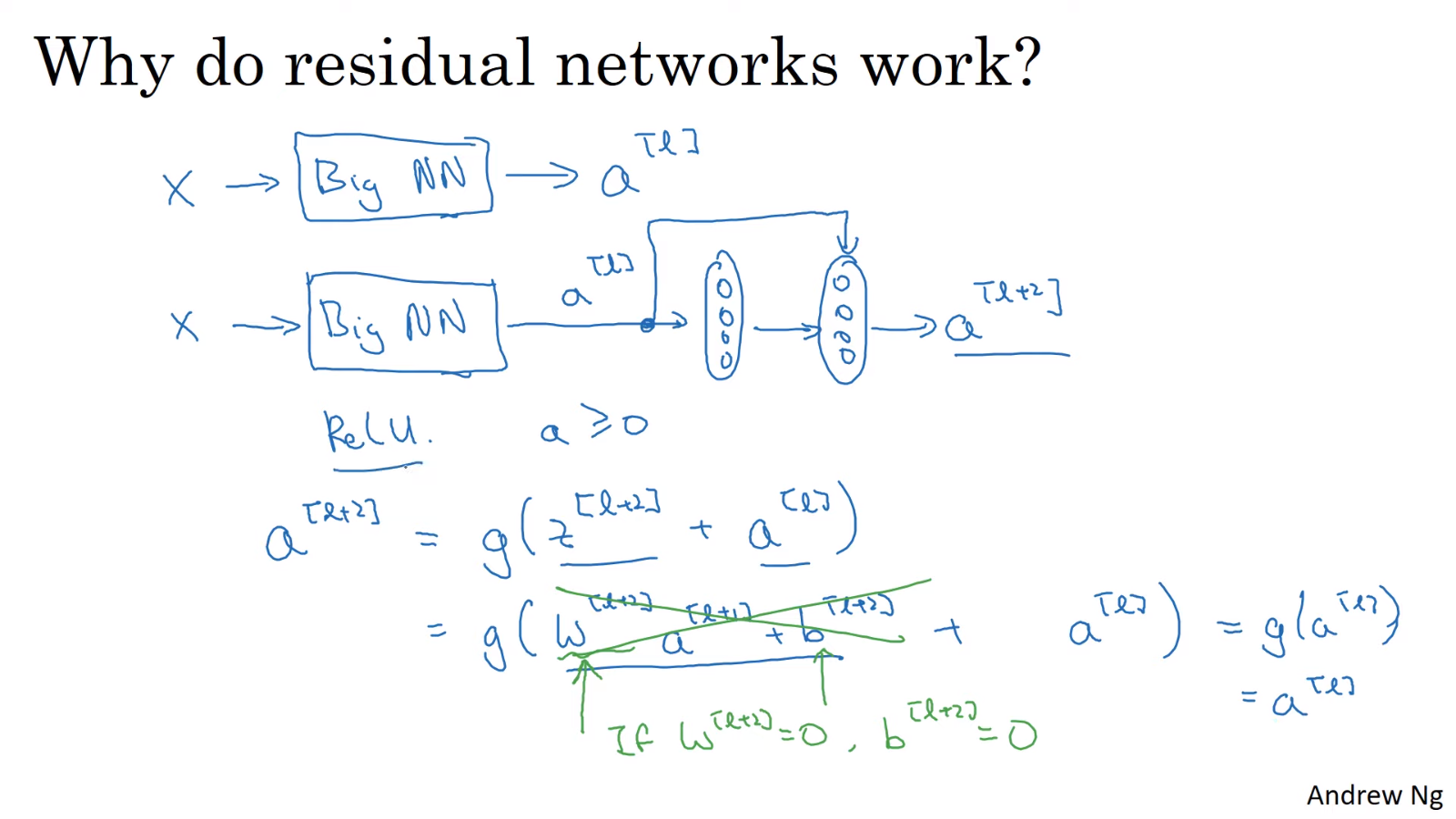
활성화 함수가 ReLU일 경우, 모든 활성화 함수 출력값 는 0보다 크거나 같다.
L2 regularization의 영향으로 가 0에 가까워지더라도, residual block을 사용하면 이 되기 때문에 두 층이 추가되지 않은 더 간단한 신경망만큼의 성능이 보장된다. 즉, 신경망에 두 층을 추가하더라도 성능에 지장이 없다. 심지어 운이 좋아 신경망이 더 깊은층을 학습할 수 있다면 성능을 향상시킬 수도 있다.
한편, 덧셈이 가능하게 하기 위해서 와 의 차원이 같아야 한다. same convolution으로 차원을 맞춰줄 수 있다. 또는 에 를 곱하여 차원을 맞춰줄 수도 있다. 는 학습 가능한 parameter로 설정할 수도 있고 zero-padding으로 고정값을 가진 행렬로 설정할 수도 있다.
📙 참고
