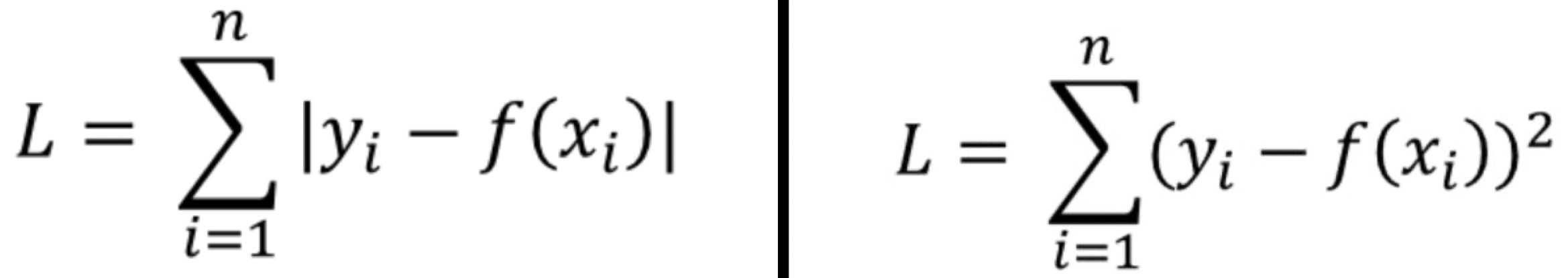
Traditional Classification Method
SVM (Support Vector Machine)
SVM이란?
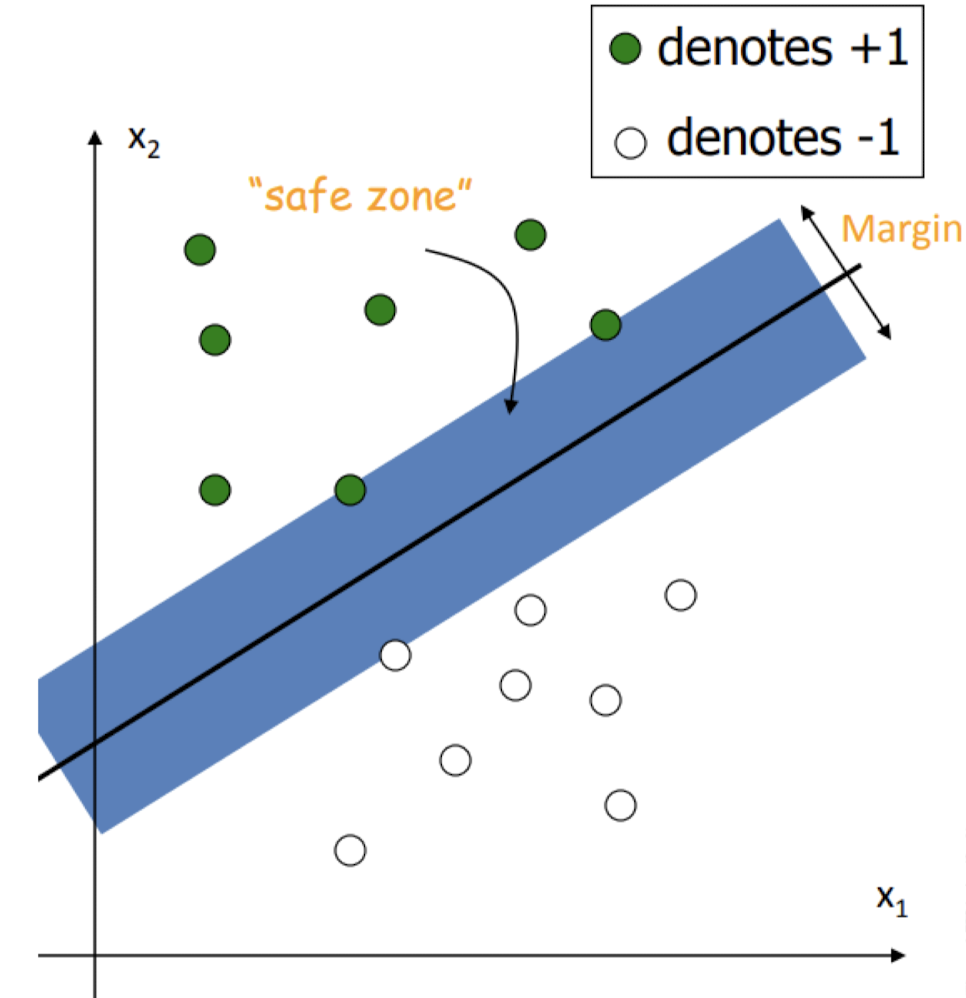
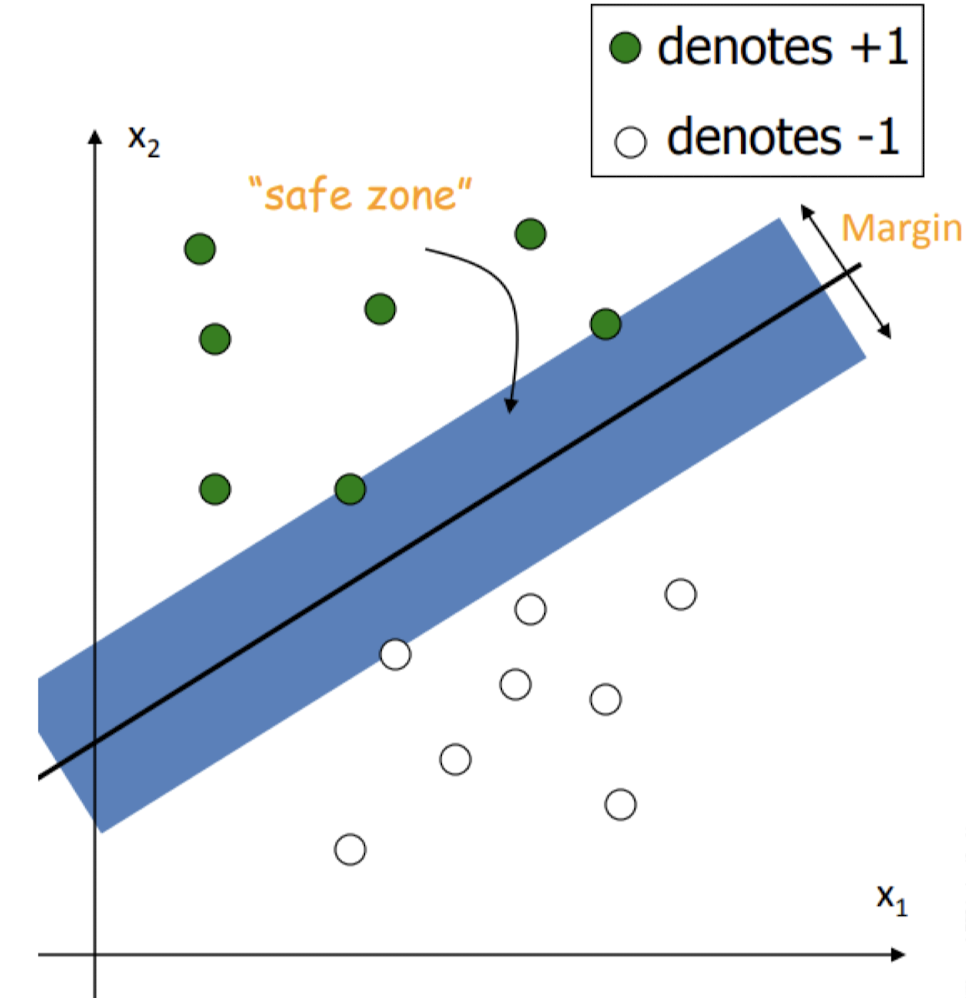
위의 점들을 구별하는 Classifier를 구할 때 가장 좋은 방법은 무엇일까?
Data Point를 만나기 전까지 늘어날 수 있는 경계선 사이의 폭을 Margin이라고 한다.
이 Margin이 최대가 되도록하는 직선을 구하면 가장 좋은 Classifier라고 가정한다. 평균에서 멀리 떨어진 Outliner들에 대한 구분 능력이 좋기 때문에 강력한 일반화 능력을 갖기 때문이다.
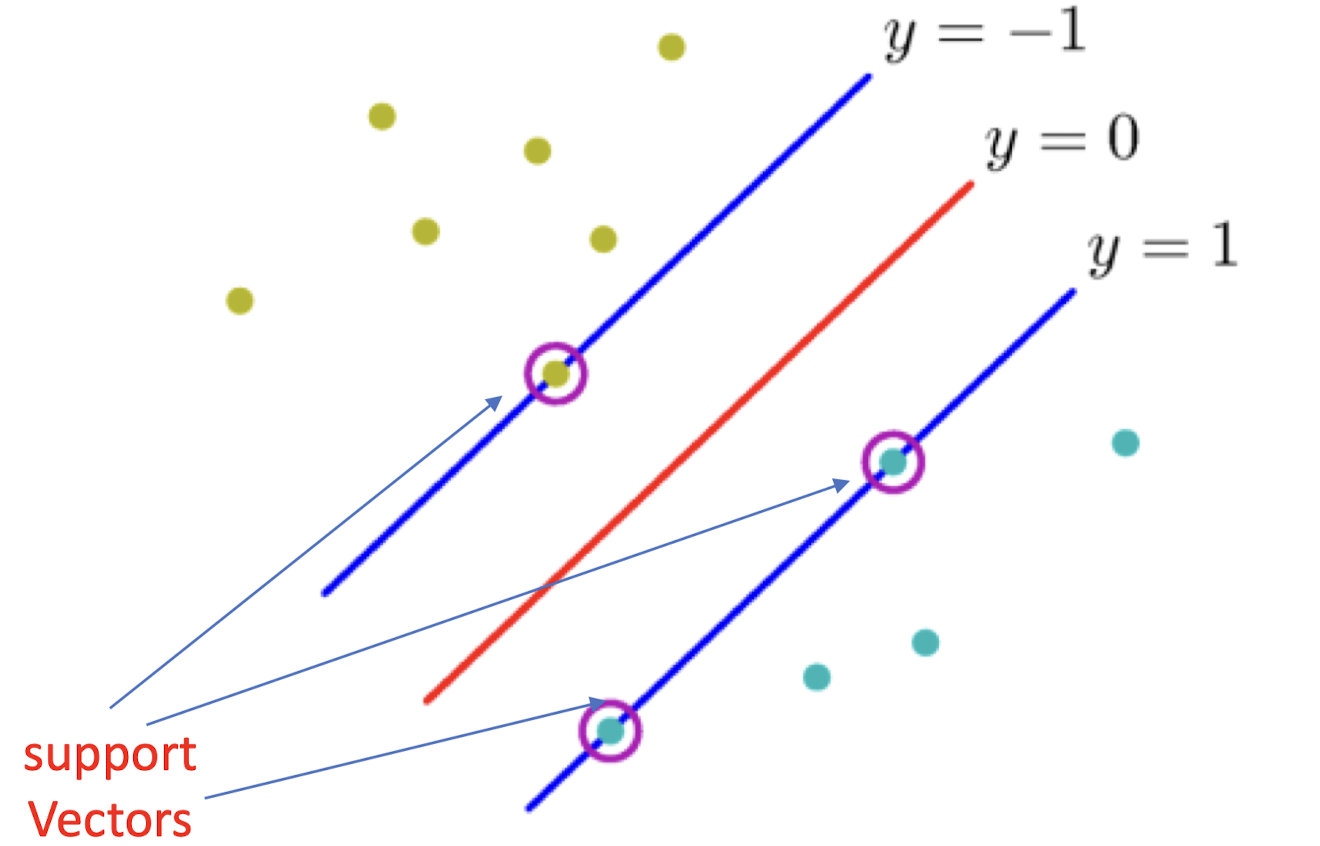
이때 Margin을 결정하는 두 직선을 Support Vector라고 부른다.
이 Support Vector만이 Decision Surface를 결정한다.

Margin이 최대가 되도록하는 직선을 구하는게 목표인데, 그렇다면 이걸 어떻게 구할 수 있을까? 두 Support Vector를 각각 wx - b = 1, wx - b = -1 이라고 하자.
이때 이 두 직선 사이의 거리가 최대가 되도록 하는 w와 b값을 구하면 된다.

평행한 두 직선 사이의 거리를 구하는 공식은 다음과 같다.
이에 따라 Support Vector 간의 거리를 계산해보면 2 / |w| 가 되고, 이를 최대로 만드는 것은 역수인 |w| / 2 를 최소로 만드는 것과 같다. 따라서 |w|를 최소로 만들면 되는 것이다.
Kernel Method
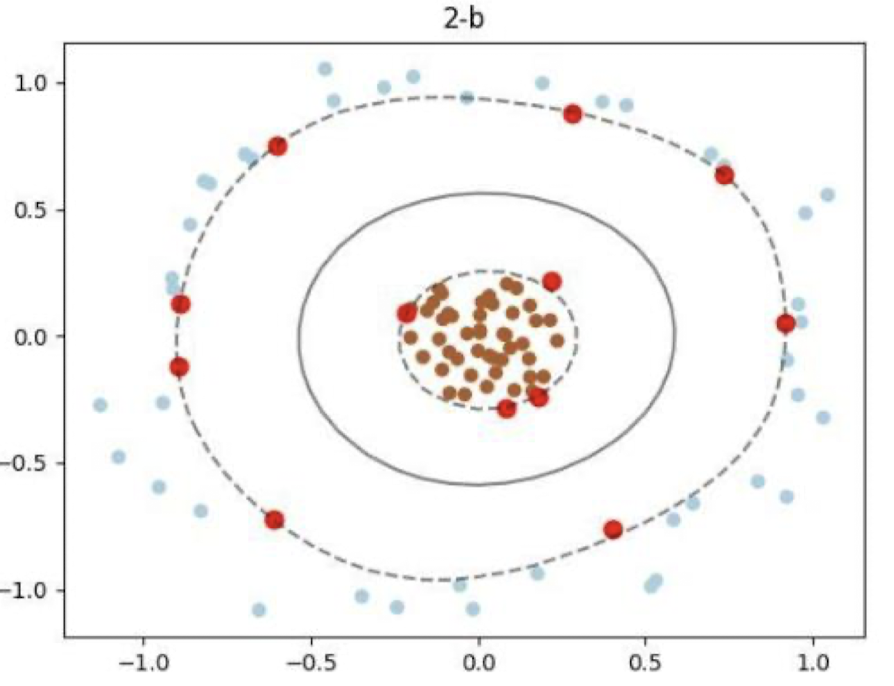
데이터 자체가 비선형(Nonlinear)으로 분포되어 있다면 SVM을 통한 Classification이 불가능할 수 있다. 이런 경우에는 Kernel Method를 사용해 Classification할 수 있다.
위의 사진은 RBF Kernel을 사용해 Classification한 결과이다.
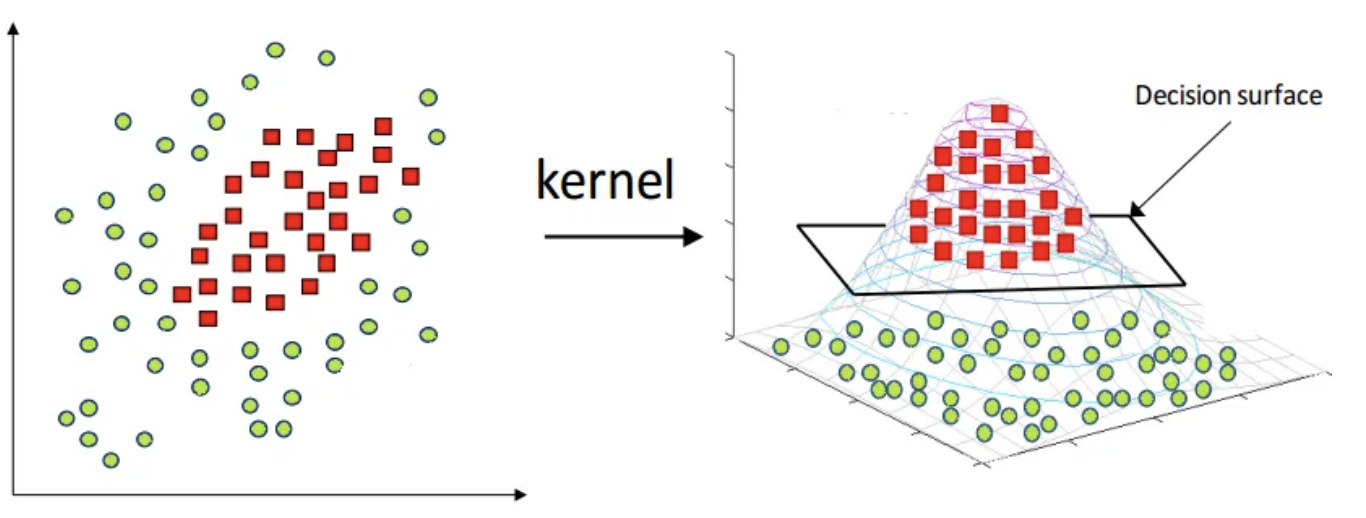
Kernel Method는 비선형 데이터를 고차원으로 세울 수 있게 도와준다.
위의 그림에서는 데이터를 3차원으로 옮겼더니 Decision Surface를 통해 Classification에 성공한 모습이다.
Norms
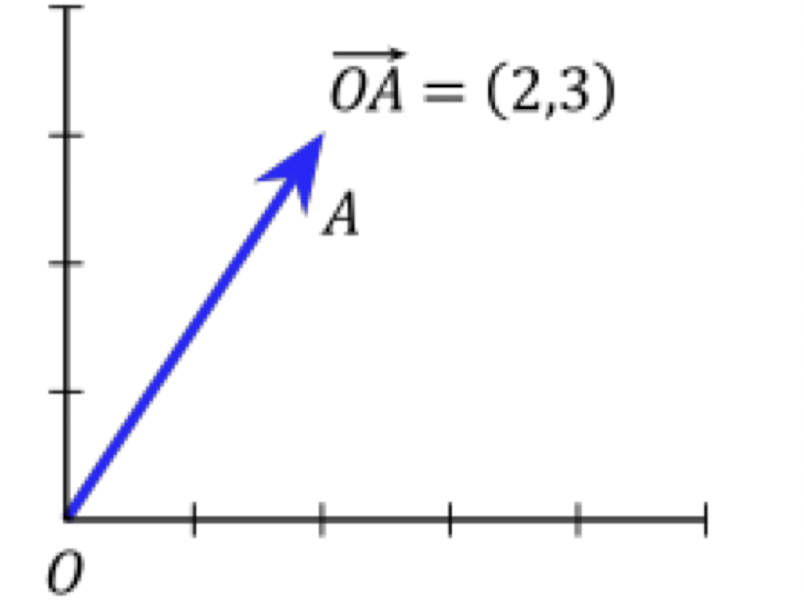
Norms란 벡터의 크기를 결정하는 방식이다.
위와 같은 벡터의 크기를 결정하는 방식은 여러가지가 있다.
Lp-norm
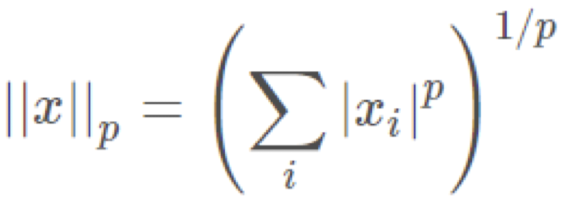
Lp-norm의 계산식은 위와 같다. 이때 p는 데이터의 차수이다.
예를 들어, p가 1일 때의 Lp-norm(L1-norm)은 다음과 같다.
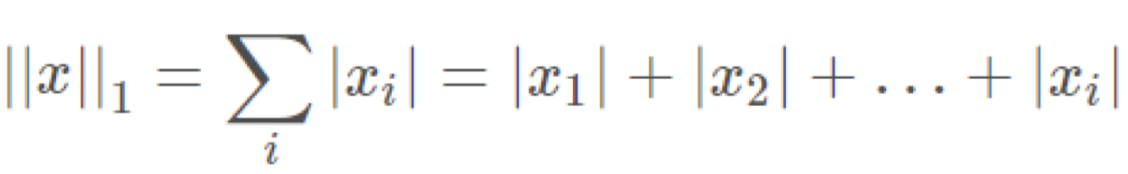
p가 2일 때의 Lp-norm(L2-norm)은 다음과 같다.
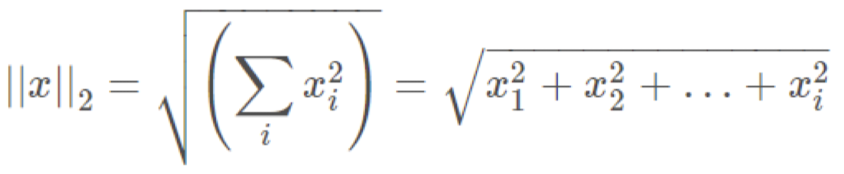
Loss
Loss란 Lp-norm을 통해 계산한 error의 크기이다.
지금까지 배운 Error 계산 공식과 L1-norm, L2-norm 계산 공식을 통해 Loss는 다음과 같다.