[Paper Review] MuKEA:Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
MultimodalKnowledgeGraph
MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
Source
Paper
Code
Implementation for Linux
.. 제가 했는데요 .. 아무튼 안 됩니다
시작합니다 멀티모달 그래프 논문 ...
~~진짜 너무 어려워서 엉엉 울고 싷ㅍ음 ~~
Motivation
KB-VQA(Visual Question Answering based on external Knowledge Bases)는 이미지, 텍스트를 넘어서 이 세상에 존재하는 여러 타입의 지식을 통합하여 질문에 답변해야한다. KB-VQA의 핵심 이슈는 크로스 모델 시나리오에서 지식을 적절하게 표현하고 활용하는 방법이다.
Knowledge-based VQA를 위해선 Multimodal data에 대한 이해가 필요하다. 기존 솔루션은 텍스트 전용 KG에서 관련 지식을 추출하였기 때문에 first-order 서술어나 언어적인 설명으로 표현된 지식만 포함하여 멀티모달 지식을 포괄하는데 한계가 있다.
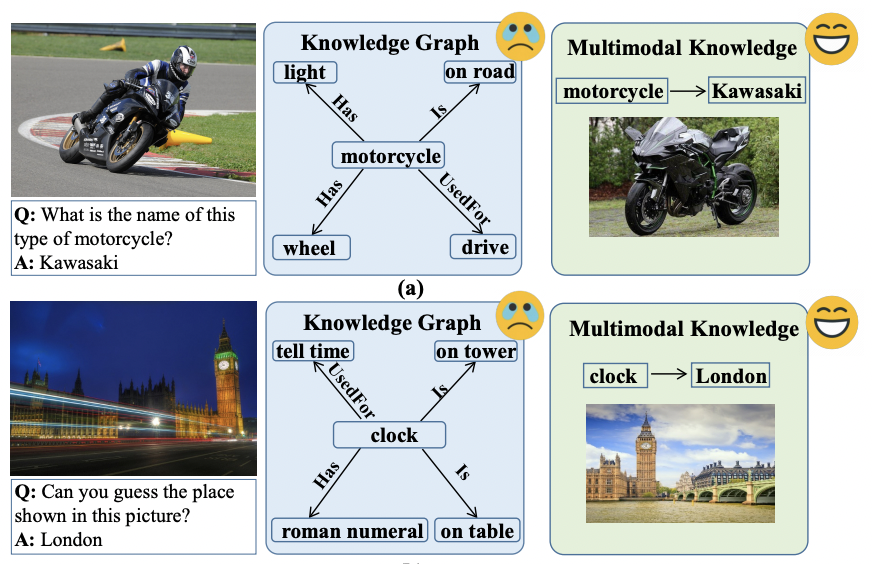
위 그림의 (a)에서 주어진 오토바이를 식별하기 위해 각 브랜드의 오토바이에 대한 시각적인 지식이 필요하지만 기존의 지식그래프에는 이와 관련된 instantiated information이 부족하다. 대부분 rigid fact로 구성되어 있기 때문에 복잡한 멀티모달 지식을 표현하고 축적하는 방법이 요구된다.
최근 멀티모달 지식 그래프에 대한 연구는 시각적인 컨텐츠를 텍스트 fact와 연관시켜 augumented knowledge graph를 형성하는 것을 목표로 한다. 일반적으로 구조화된 표현에 대한 이미지와 텍스트를 분석하여 event-entity를 접지시키거나 기존 지식 그래프의 entity를 관련된 이미지와 간다닣 정렬하는 두가지 방법이 있지만 위 두 방법 역시 first-order predicate를 통해 지식을 나타내기 때문에 위 그림의 clock-london과 같은 복잡한 관계를 모델링 하는데에 한계가 있다.
따라서 본 논문은 explicit tripletd으로 멀티모달 knowledge를 나타내 visual object와 Fact answers를 암시적 관계와 상관시키는 MuKEA를 제안한다. MuKEA의 핵심 매커니즘은 VAQ 샘플을 관찰해 복잡한 관계를 가진 멀티모달 지식을 축적하고 이를 기반으로 설명 가능한 추론을 수행하는 것이다. 이를 위해
- 질문에 의해 refer된 visual object가 head entity에 내장
- fact answer이 tail entity에 내장
- head-tail 사이 암시적 관계가 relation
이렇게 새로운 triplelet으로 표현된다.
Contribution
1. End-to-End multimodal knowledge 표현 학습 프레임워크 제안
- 명시적인 triplelet에 의해 표현할 수 없는 multimodal fact를 모델링하고 기존 지식 그래프와 unstructured 지식그래프를 기반으로 완전한 지식 제공
2. Neural multimodal knowledge base 형성
- pretraining, fine tuning을 사용해 도메인 외부 및 도메인 내부 지식 축적
- 기존 지식 검색, 읽기 파이프라인에서 cascading error 제거하는 automatic knowledge association/ answer prediction 지원
Method
Image I와 question Q가 주어졌을때 KB-VQA의 task는 데이터 타입에 구애 받지 않는 외부 지식을 활용하여 answer A를 예측하는 것이다. 본 논문은 triplet 형태의 멀티모달 지식을 축적하여 외부 지식을 처리하고 end-to-end 상황에서 직접적으로 답변을 추론한다.
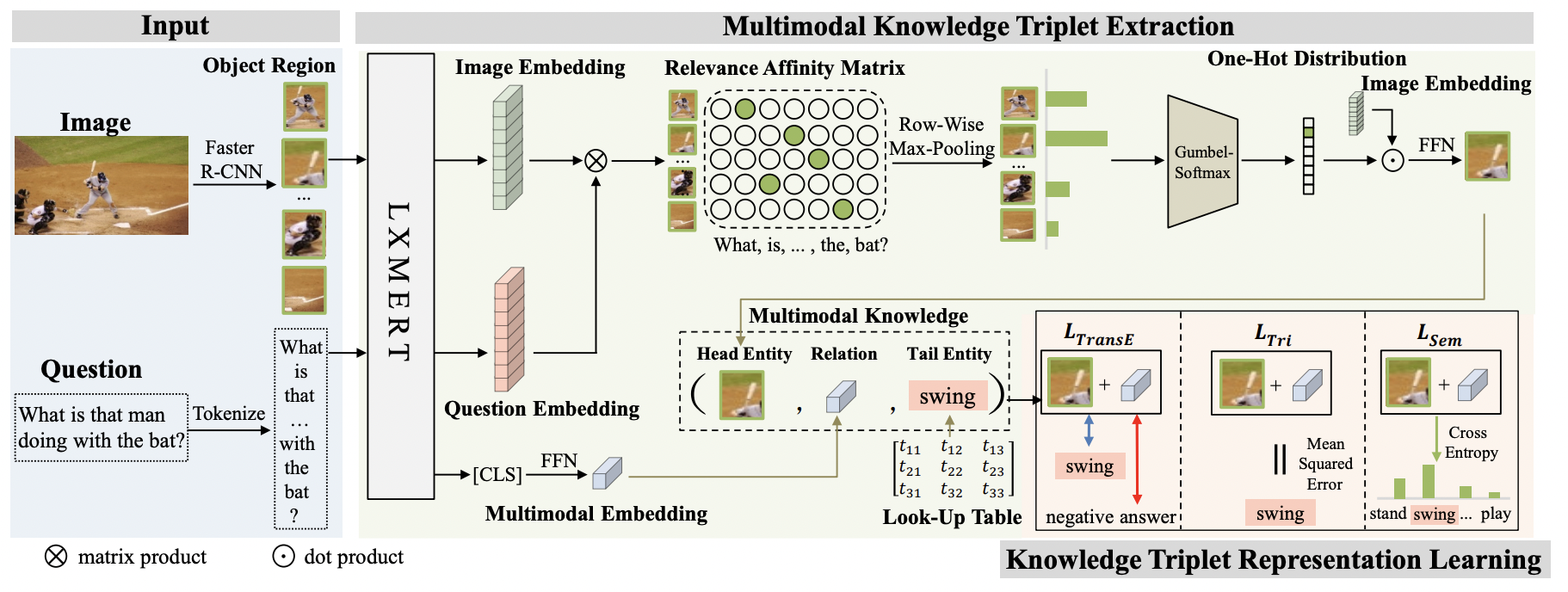
논문에서 제안한 모델의 스키마는 이와 같다. 위 모델은 사전 훈련된 vision-language model을 기반으로 구조화되지 않은 image-question-answer 샘플에서 multimodal knowledge triplet을 추출한다.
이후 question-attended visual content(head embedding), question-desired fact answer(tail embedding), implicit relation(relation embedding)으로 구성된 triplet을 학습하기 위해 세가지 objective losses을 제안한다.
Multimodal Knowledge Triplet Extraction
multimodal knowledge를 (h, r, t) 의 triplet 형태로 표현한다. 이때 h는 질문에 의해 초점이 맞춰진 이미지의 visual content, t는 question-image pair가 주어진 답변의 representation, 마지막으로 r은 multimodal information을 포함하고 있는 h와 t 사이 명시적인 관계를 나타낸다. triplet 생성 과정은 이와 같다.
Image/Question Encoding
Image/Question Encoding

사전학습된 언어 intra-modal과 cross-modal의 암시적인 상관 관계를 표현하는데 적합하다. 따라서 사전 학습된 모델인 LXMERT를 추가적인 멀티모달 지식 triplet 추출을 위한 question-image encoding에 사용한다.
이때 Faster R-CNN으로 object의 집합을 탐지하고, WordPiece를 사용하여 질문 Q를 tokenize한다.
이휴 visual feature와 question tokens을 사전훈련된 LXMERT에 넣어 visual embedding을 얻고 이를 tokenize한다.
Head Entity Extraction
Head Entity를 질문과 가장 관련성 높은 이미지의 visual object와 context로 정의한다.
이를 위해 질문 유도 object-question 관련성 선호도 행렬(relevance affinity matrix)를 계산하여 우선 이미지의 각 object들과 question의 token 사이의 관계성을 평가한다.
Relevance affinity matrix를 기반으로 질문과 가장 관련 있는 object를 선택한다.
LXMERT모델은 모든 객체 간의 암시적인 상관 관계를 모델링하기 때문에 이미 선택된 question-centric object에 contextual 정보가 포함되어있다. 따라서 여러 객체와 관련된 질문에 대한 대답으로 필수적인 단서를 제공할 수 있다.
Relation Extraction
본 논문에서는 multimodal knowledge의 관계를 observed instantiated object와 그에 따른 답변 사이의 복잡한 implicit relation으로 정의한다.
LxMERT는 hierarchical transformer에서 self-attention mechanism을 통해 이미지와 질문 사이 implicit correlation을 포착하기 때문에 CLS 토큰에서 cross-modal representation을 추출하고 이를 FFN 레이어에 공급하여 관계 임베딩을 얻는다.
Tail Entity Extraction
여기선 Tail entity를 image-question-answer 샘플의 answer로 정의하는데 이떄 answer는 question에 의해 참조된 시각적 객체와, 관련 fact의 특정한 측면을 나타낸다. 트레이닝 단계에서 gt answer를 tail entity로 설정해 그것의 representation을 처음부터 학습한다.
추론 단계에서는 KB-VQA의 task를 multimodal knowledge graph 완성으로 정의하고 neural multimodal knowledge base의 knowledge를 전역적으로 평가하여 최적의 tail entity를 answer로 예측한다.
Knowledge Tiplet Representation Learning
multimodal knowledge graph에서 triplet은 내부 구성 요소의 양식이 다양할 뿐만 아니라 semantic-specific 정보를 포함하기 때문에 semantic gap과 heterogeneous gap을 해소하기 위해 triplet representation을 통합적으로 학습하는 세가지 loss function을 제안한다.
세가지의 loss function은 공통적으로 보완적인 관점에서 triplet representation에 제한을 두는데, Triplet consistency loss, Semantic consistency loss, Triplet TransE loss가 있다.
Triplet TransE Loss
기존 지식 그래프의 TransE방식과 유사하게 multimodal 환경에서 constraint를 보존하는 구조로 objective loss를 적용한다. 주어진 image-question 쌍에서,
와 를 positive(correct), nevative(incorrect) 답변 쌍이라고 했을때, 추출된 head+relation와 각 positive tail인 $ t^+$ 사이의 거리가 추출된 head+relation와 각 negative tail인 사이의 거리보다 짧아야한다.
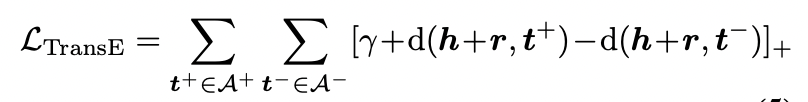
Triplet Consistency Loss
위의 TransE loss 는 일단 positive pair과의 거리가 negative pair의 거리보다 작으면 모델은 triplet으로부터 학습하는 것을 멈춘다. 엄격한 topological 관계를 충족시키기 위해선 추가적인 임베딩이 필요한데, MSE criterion을 적용해 각 positive triplet의 representation을 이와 같이 제한한다.
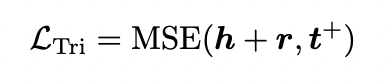
Semantic Consistency Loss
랜덤하게 tail entity의 look-up table을 초기화하고 head/relation과 함께 해당 representation을 학습한다. look-up table의 각 tail entity는 training VQA sample의 고유한 answer에 해당하는데, 이때 text형태의 tail entity와 multimodal 형태의 head-relation 사이의 heterogeneous gap을 줄이는 동안 tail representation에서 답변의 semantic을 도입하기 위해서 tail vocabulary에 걸쳐서 triplet을 분류하고 negative log likelihood loss를 기반으로 모델이 gt tail(answer)을 선택하도록한다
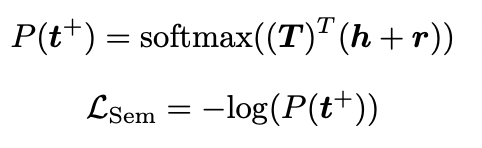
: predicated probability of GT tail
Final loss function
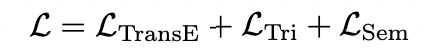
Knowledge Accumulation and Prediction
multimodal knowledge 축적을 위해 두 단계의 훈련 기법을 채택한다.
1. Pre-training on the VQA 2.0 dataset
: 기본적인 visual dominant knowledge 축적
VQA 2.0의 모든 질문들은 yes/no, Number, Other 3가지 카테고리로 나뉘어져있다. yes/no, number 카테고리의 경우 fact knowledge로 작용할 수 없기 때문에 other 카테고리만 사전 훈련때 사용한다.
2. Fine-tuning on the training data of downstream KB-VQA task
: 더 복잡한 도메인 특정적인 multimodal knowledge 축적
추론 단계에서 answer predication을 multimodal knowledge graph의 completion 문제로 간주하기 때문에 주어진 이미지와 질문을 네트워크에 feeding하고 head entity와 relation의 embedding을 얻는다. 이후 look-up table의 head+relation embedding과 각 tail entity 사이의 거리를 계산하고 최소 거리를 가진 tail entity를 predicted answer로 간주한다.
Dataset
OK_VQA(Outside Knowledge VQA)
14,000개 이상의 question들은 10개의 knowledge categori들을 cover한다. OK-VQA는 고정된 question templet이나 knowledge base 없이 모든 질문에 사람이 annotation을 달아야한다. 따라서 광범위한 개방형 knowledge resource 탐색이 요구되기 때문에 데이터셋 자체가 다양해진다.
KRVQA(Knowledge-Routed VQA)
가장 큰 knowledge based VQA dataset.
외부 지식을 기반으로 모델의 multi-step 추론 능력을 평가함
Implementation
- training set의 모든 annotated answer를 사용해 knowledge triplet 구성
- triplet ranking loss의 경우 positive sample과 다른 답변을 가진 모든 샘플을 negative sample로 간주함.
- batch size: 256, epoch: 200 Training model: AdamW
Future work
- 결국 이 논문도 human-annotated dataset을 기반으로 훈련하는 모델인데 인간의 개입이 최소화된 방법이 없을까?
- question과 그에 맞는 answer이 할당된 데이터셋이 아니라 일반 multi-modal 데이터로부터 바로 triple을 추출할 수 있는 방법은?
