
📌2.1. 사이킷런 소개와 특징
- scikit-learn : 파이썬 머신러닝 라이브러리 중 하나. 파이썬 기반의 머신러닝을 위한 가장 쉽고 효율적 개발 라이브러리 제공
- 특징
- 가장 파이썬스러운 API 제공
- ML 위한 다양한 알고리즘 개발 위한 편리한 프레임워크, API 제공
- 오랜 기간 실전 검증, 많은 환경에서 사용되는 성숙한 라이브러리
- 임포트 :
import sklearn
🌷2.2. 붓꽃 품종 예측하기
붓꽃 품종 예측하기 문제
- 붓꽃 데이터 세트로 품종을 분류(classification)하기
- feature : 꽃잎(Sepal)의 길이(lenghth), 너비(width), 꽃받침(Petal) 길이, 너비
- label : Setosa, Vesicolor, Virginica
분류(classification)
- 대표적 지도학습(supervised learning) 방법의 하나
- 지도학습
- 학습을 위한 다양한 특징과 레이블(label, 분류 결정값) 데이터로 모델을 학습한 뒤, 별도의 데스트 데이터 세트에서 미지의 레이블을 예측
- 명확한 정답이 주어딘 데이터를 먼저 학습 -> 미지의 정답 예측
- 학습 데이터셋 = 학습을 위해 주어진 데이터셋
- 테스트 데이터셋 = 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터셋
사이킷런 패키지
sklearn.datasets내 모듈 : 사이킷런에서 자체적으로 제공하는 데이터셋을 생성하는 모듈의 모임sklearn.tree내 모듈 : 트리 기반 ML 알고리즘을 구현한 클래스의 모임sklearn.model_selection: 학습 데이터와 검증 데이터, 예측 데이터로 데이터를 분리, 또는 최적의 파리미터로 평가하기 위한 다양한 모듈의 모임- 하이퍼파라미터 : ML 알고리즘별로 최적 학습을 위해 직접 입력하는 파라미터로, ML 알고리즘의 성능을 튜닝할 수 있음
붓꽃 품종 예측하기 with 분류
from sklearn.datasets import load_iris #데이터셋 생성하는 함수
from sklearn.tree import DecisionTreeClassifier #사용할 ML 알고리즘 - 의사결정트리
from sklearn.model_selection import train_test_split #데이터셋을 학습/테스트로 분리하는 함수
import pandas as pd
iris = load_iris() #붓꽃 데이터셋 로딩
iris_data = iris.data #iris.data는 데이터셋에서 feature 만으로 이루어진 데이터를 numpy로 가지고 있음
iris_label = iris.target #iris.target은 데이서셋에서 레이블(결정값) 데이터를 numpy로 가지고 있음
print("iris target 값 : ", iris_label)
print("iris target 명 : ", iris.target_names) #0=setosa, 1=versicolor, 2=virginica
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names) #데이터셋을 자세히 보기 위해 DataFrame으로 변환함
iris_df['label'] = iris.target
### 학습용 데이터&테스트용 데이터 분리 : train_test_split()
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)
# 첫 번째 파라미터 = feature 데이터셋 / 두 번째 파라미터 = 레이블 데이터셋 /
# 세번째 파라미터 = 전체 데이터셋 중 테스트셋의 비율 /
# 네번째 파라미터 = 호출 시마다 같은 학습&테스트용 데이터셋을 생성하기 위해 주어지는 난수 발생값.
# random 값을 만드는 seed와 같은 의미. 숫자 자체는 어떤 값도 지정해도 상관 없음
### 머신러닝 분류 알고리즘 중 하나인 의사결정트리로 학습
dt_clf = DecisionTreeClassifier(random_state=11) #사이킷런 의사결정 트리 클래스를 객체로 생성
dt_clf.fit(x_train, y_train) #학습 수행. 학습용 featur 데이터 속성과 결정값 데이터셋을 입력
### 의사결정트리로 예측 수행
pred = dt_clf.predict(x_test) #학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터셋으로 예측 수행. 예측은 반드시 학습 데이터 아닌 것으로.
### 의사결정트리 기반의 예측 성능 평가 with 정확도(예측 결과가 실제 레이블 값과 얼마나 정확하게 맞는가를 평가하는 지표)
from sklearn.metrics import accuracy_score
print("예측 정도 : {0:.4f}".format(accuracy_score(y_test, pred)))분류 예측 프로세스 정리
- 데이터셋 분리 : 데이터를 학습 데이터와 테스트 테이터로 분리
- 모델 학습 : 학습된 데이터를 기반으로 ML 알고리즘을 적용해 모델 학습시킴
- 예측 수행 : 학습된 ML 모델을 이용해 테스트 데이터의 분류 예측
- 평가 : 에측 결과값과 테스트데이터의 실제 결과값을 비교해 ML 모델 성능을 평가함
💡2.3. 사이킷런의 기반 프레임워크 익히기
Estimator 이해 및 fit(), predict() 메서드
- ML 모델 학습엔
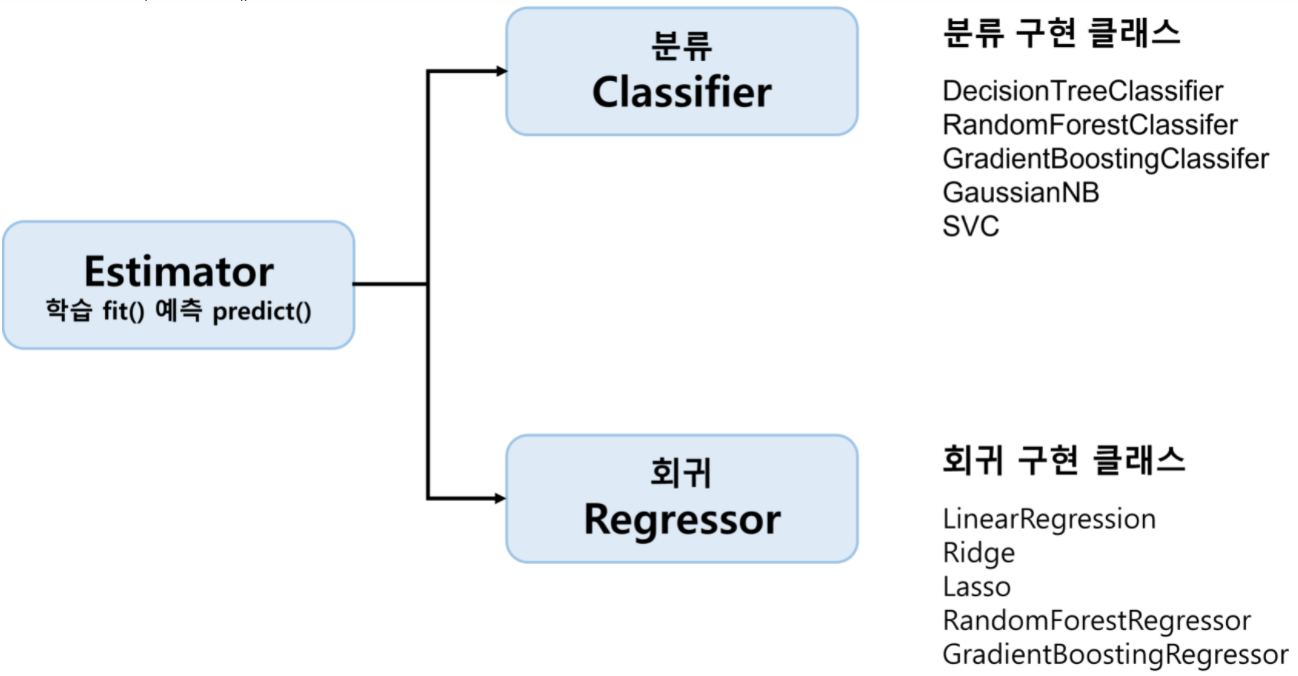
fit(), 학습된 모델 예측엔predict()메서드를 일괄적으로 사용 Estimator클래스 : 지도학습의 모든 알고리즘을 구현한 클래스
1) 분류 알고리즘은Classifier, 회귀 알고리즘은Regressor로 지칭. 이 둘은 Estimator로 통칭
2) evaluation 함수, 하이퍼파라미터 튜닝 지원 클래스 등은 Estimator를 인자로 받음- 비지도학습(예 : 차원축소, 클러스터링, 피처 추출) 클래스 역시 fit(), transform() 지원
1)fit(): 입력 데이터의 형태에 맞춰 데이터 변환하기 위한 사전 구조를 맞추는 작업
2)transform(): 사전 구조 맞춘 뒤, 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등 실제 작업을 수행
📊2.4. Model Selection 모듈 소개
Model Selection 모듈
- 학습 데이터와 테스트 데이터셋을 분리 혹은 교차검증 분할 및 평가, Estimator의 하이퍼파라미터를 튜닝하기 위한 함수&클래스 제공
학습/데이터셋 분리 - train_test_split()
- 전체 데이터를 학습/테스트 데이터셋으로 분리해줌
sklearn.model_selection모듈 >train_test_split()- 튜플 형태로 반환 :
(학습 데이터의 피처 데이터셋, 테스트 데이터의 피처 데이터셋, 학습 데이터의 레이블 데이터셋, 테스트 데이터의 레입르 데이터셋)
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
dt_clf = DecisionTreeClassifier()
iris_data = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.3, random_state=121)
dt_clf.fit(x_train, y_train) #학습데이터를 기반으로 DecisionTreeCLassifier을 학습하고, 이 모델로 예측 정확도 측정
pred = dt_clf.predict(x_test)
print('예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))교차 검증
- 필요성
- 과적합(Overfitting) : 모델이 학습 데이터에만 과도하게 최적화 되어, 실제 예측을 다른 데이터로 수행할 때 예측 성능이 과도하게 떨어지는 것
- 고정된 학습데이터 & 테스트 데이터로 평가할 시 테스트 데이터에만 최적의 성능을 발휘하도록 편항되게 모델을 유도하는 경우가 생김
- 이를 방지하기 위해 교차검증을 이용해 다양한 학습&평가 시행
- 교차 검증
- 테스트 데이터셋에 대해 평가하기 전, 많은 학습과 검증 세트에서 알고리즘 학습과 평가를 수행하는 것
- 각 세트에서 수행한 평가 결과에 따라 하이퍼 파라미터 튜닝 등의 모델 최적화를 쉽게 할 수 있음
- 대부분의 ML 모델의 성능 평가는 교차 검증을 기반으로 1차 평가 함 -> 최종적으로 테스트 데이터셋에 적용해 평가
- ML에 사용되는 데이터셋 : 학습 + 검증 + 테스트 데이터셋
- 학습 데이터 중 따로 할당을 해 별도의 검증 데이터셋을 두어 최종 평가 이전에 학습된 모델을 다양하게 평가하는 데 사용함
K 폴드 교차 검증
- 가장 보편적으로 사용되는 교차 검증 기법
- K개의 데이터 폴드 세트를 만들어 K번 만큼 각 폴드 세트에 학습&검증 평가를 반복적으로 수행
- 데이터셋을 K 등분함
- 1번째 반복에서1 ~ (K-1)번째 등분을 학습 데이터셋으로, 마지막 K번째 등분 하나를 검증 데이터셋으로 설정한 뒤, 학습 데이터에 대해서는 학습을, 검증 데이터셋에서는 평가를 수행
- 2번째 반복에서는 1 ~ (K-2)번째 등분과 K번째 등분을 학습 데이터셋으로, (K-1)번째 등분 하나를 검증 데이터셋으로 설정한 뒤, 같은 과정을 반복
- 학습 데이터셋과 검증 데이터셋을 점진적으로 변경하며 마지막 K번째까지 학습과 검증을 수행
- K개의 예측 평가를 구한 뒤, 이를 평균해 K 폴드 평가 결과로 반영
- K=5인 경우의 K폴드 교차 검증

- 사이킷런에서는 K폴드 교차 검증 프로세스 구현을 위해
KFold와StratifiedKFold클래스 제공KFold(n_splits=n)으로 KFold 객체 생성- KFold 객체의
split()호출 시 전체 데이터를 n개의 폴드 데이터셋으로 분리 split()호출 시 학습용/검증용 데이터로 분할할 수 있는 인덱스로 반환함- 학습용/검증용 데이터 추출은 반환된 인덱스를 기반으로 개발 코드에서 직접 수행해야 함
### KFold 객체의 split()을 호출해 교차 검증 수행 시마다 학습과 검증을 반복해 예측 정확도 측정
### split()이 어떤 값을 실제로 반환하는지 확인하기 위해 검증 데이터 셋의 인덱스도 추출
n_iter = 0
#KFold 객체의 split()를 호출 시 폴드 별 학습용 & 검증용 테스트의 로우 인덱스를 array로 반환
for train_index, test_index in kfold.split(features):
# kfold.split()으로 반환된 인덱스를 이용해 학습용, 검증용 데스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
n_iter += 1
#반복 시마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('#{0} 교차 검증 정확도 : {1}, 학습 데이터 크기 : {2}, 검증 데이터 크기 : {3}'.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스 : {1}\n'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
# 개별 iterator 별 정확도를 합해 평균 정확도 계산
print('\n#평균 검증 정확도 : ', np.mean(cv_accuracy))Stratified K 폴드
- 불균형한 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K폴드 방식
- 특정 레이블값이 특이하게 많거나 매우 적어 값의 분포가 한쪽으로 치우친 경우를 위함 -> 랜덤으로 테스트/학습 데이터셋 인덱스를 고를 경우, 불균형하게 배정될 가능성이 있음
- 원본 데이터 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분배함
- KFold로 분할된 레이블 데이터셋이 전체 레이블 값의 분포도를 반영하지 못하는 문제 해결
split()메서드에 인자로 피처 데이터셋 뿐만 아니라 레이블 데이터셋도 반드시 필요- 왜곡된 레이블 데이터셋에서 반드시 Straified K 폴드를 이용해 교차 검증해야 함
- 일반적으로 분류 문제에서 교차검증은 KFold가 아니라 Stratified K 폴드를 이용해 분할되어야 함
- 회귀 문제에서는 Stratified K 폴드 지원 안됨. 회귀는 결정값이 이산값 형태 레이블이 아닌 연속된 숫자 형태이므로 결정값변로 분포를 정할 의미 없기 때문
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import numpy as np
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skfold.split(features, label): #StratifiedKFold의 split()호출 시 반드시 레이블 데이터셋도 추가 입력해야 함
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{0} 교차 검증 정확도 : {1}, 학습 데이터 크기 : {2}, 검증 데이터 크기 : {3}'.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스 : {1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
print('\n#교차 검증별 정확도 : ', np.round(cv_accuracy, 4))
print('#평균 검증 정확도 : ', np.mean(cv_accuracy))사이킷런 cross_val_score() API
- 사이킷런은 교차 검증을 편리하게 수행할 API로
cross_val_score()제공 - 선언 형태 :
cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jogs')- estimator : 사이킷런의 분류 알고리즘 클래스 Classifier 또는 회귀 알고리즘 클래스 Regressor
- X : 피처 데이터 세트
- y : 레이블 데이터 세트
- scoring : 예측 성능 평가 지표 기술
- cv : 교차 검증 폴드 수
- scoring 파라미터로 지정된 성능 지표 측정값을 배열 형태로 반환
- classifier가 분류 클래스이면 Stratified K 폴드 방식으로, 회귀이면 K 폴드 방식으로 분할
- 즉, API 내부에서 Estimator을 학습(fit)-예측(predict)-평가(evaluation) 모두를 한번에 처리
corss_validate(): 비슷한 API로, 여러 개의 평가 지표를 반환할 수 있음. 학습 데이터에 대한 성능 평가 지표와 수행 시간도 같이 제공
scores = cross_val_score(dt_clf, data, label, scoring='accuracy', cv=3)
print('교차 검증별 정확도 : ', np.round(scores, 4))
print('평균 검증별 정확도 : ', np.round(np.mean(scores), 4))GridSearchCV
- 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에
- Classifier/Regressor 같은 알고리즘에 사용되는 하이퍼 파라미터를 교차 검증을 기반으로 순차적으로 입력하며 편리하게 최적의 파라미터를 도출하도록 함(for문으로 일일히 할 필요 없이)
- 데이터 셋을 cross-validation을 위한 학습/테스트 세트로 자동 분할 -> 하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용 -> 최적의 파라미터 찾음
- 수행시간이 상대적으로 오래 걸림
GridSearchCV의 클래스 생성자 파라미터estimator: classifier, regressor, pipelineparam_grid: 키 & 리스트 값 갖는 딕셔너리. estimator의 튜닝을 위해 파라미터명 & 사용될 파라미터 값들 지정scoring: 예측 성능을 측정할 평가 방법. 보통은 성능 평가 지표 지정할 문자열을 입력.(ex, 'accuracy') 혹은 별도 성능평가 지표 설정 가능cv: 교차 검증을 위해 분할되는 학습/테스트 세트 개수refit: 디폴트가 True. 가장 최적의 파라미터를 찾은 뒤 입력 estimator 객체를 해당 파라미터로 재학습 시킴
GridSearchCV.fit()을 시키면GridSearchCV.cv_result_에 반환값을 저장 -> pandas로 보기 쉽게 확인 가능params: 수행할 때마다 적용된 개별 파라미터값rank_test_score: 하이퍼 파라미터별로 성능이 좋은 score 순위. 1에 가까울 수록 높은 순위 & 최적 파라미터mean_test_score: 개별 하이퍼 파라미터별로 CV의 폴딩 테스트 세트에 대해 총 수행한 평가 평균값
best_params_,best_score_속성에 최고 성능을 내는 하이퍼 파라미터 값과 평가 결과값이 각각 저장best_estimator_속성에refit으로 이미 학습된 estimator을 반환
#파라미터를 딕셔너리로 설정 - 의사결정트리 알고리즘의 주요 파라미터인 max_depth와 min_sample_split을 변화
#하이퍼 파라미터의 명칭은 key, 하이퍼 파라미터 값은 리스트 형으로 설정
parameters = {'max_depth':[1, 2, 3], 'min_samples_split':[2, 3]}
#parm_grid의 하이퍼 파라미너틀 3개의 학습/테스트 데이터셋 폴드로 나누어 테스트 수행 설정 : fit()
#수행 결과를 cv_results_속성에 기록함. 이를 Pandas의 DataFrame으로 변환하면 쉽게 볼 수 있음
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True)
grid_dtree.fit(x_train, y_train)
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score', 'split0_test_score', 'split1_test_score', 'split2_test_score']]
print('GridSearchCV 최적 파라미터 : ', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도 : {0:.4f}'.format(grid_dtree.best_score_))
#GridSearchCV의 refit으로 이미 학습된 estimator 반환 -> 이미 최적 학습이 되었으므로 별도 학습 필요 없음
estimator = grid_dtree.best_estimator_
pred = estimator.predict(x_test)
print('테스트 데이터 세트 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))
🔪2.5. 데이터 전처리
데이터 전처리(Data Preprocessing)
- 필요성 : ML 알고리즘은 어떤 데이터를 입력하는지에 따라 결과가 크게 바뀔 수 있음(Garbage In, Garbage Out)
- 사이킷런의 ML 알고리즘 적용 전에 처리해야 할 사항
- 결손값(NaN, Null)을 허용하지 않음 -> 고정된 다른 값으로 변환해야 함
- Null 값이 얼마 되지 않는 경우 : feature의 평균값 등으로 간단 대체 가능
- Null 값이 대부분인 경우 : 해당 feature은 drop 하는 것이 좋음
- Null 값이 일정 수준 이상(기준은 없음)인 경우 : 해당 feature가 중요도가 높다면 단순 평균 등으로 대체한다면 예측 왜곡 심할 수 있음. 더 정밀한 대체값 선정 필요
- 문자열 값을 입력값으로 허용하지 않음 -> 모든 문자열 값은 인코딩 되어 숫자형으로 변환해야 함
- 카테고리형 feature : 코드 값
- 텍스트형 feature : 피처 벡터화(feature vectorization) 등으로 벡터화하거나 불필요한 feature일 경우 삭제(주민번호, 아이디 등은 단순히 데이터 row를 식별하는 용도이므로 중요 요소 아님. 알고리즘 복합하게 할 뿐)
- 결손값(NaN, Null)을 허용하지 않음 -> 고정된 다른 값으로 변환해야 함
데이터 인코딩
- 대표적 ML 데이터 인코딩 방식
- 레이블 인코딩(Label Encoding)
- 원-핫 인코딩(One-Hot Encoding)
레이블 인코딩
- 카테고리 피처를 코드형 숫자값으로 변환하는 것
- '01', '02'도 문자열이므로 1, 2와 같은 숫자형으로 변환해야 함
- 사이킷런의 LabelEncoder 클래스로 구현 ->
fit(),transform()호출해 레이블 인코딩 진행 - 데이터 수가 많아 어떤 문자열이 어떤 숫자로 인코딩 되었는지 확인 힘들 경우 LabelEncoder 객체의
classes_속성 이용 - 인코딩 값을 다시 디코딩하려면
inverse_transform()사용 - 일괄적인 숫자값으로 변환되며, 숫자값의 크고 작음, 순서나 중요도의 특성으로 작용할 수 있음 -> 특정 ML 알고리즘에서 가중치가 더 부여되는 등 문제를 일으킬 수 있음 -> 회귀 등에 쓰이지 않음. 트리 계열 ML 알고리즘은 괜찮음
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
encoder = LabelEncoder() #객체 생성
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값 : ', labels)
print('인코딩 클래스 : ', encoder.classes_)
print('디코딩 원본값 : ', encoder.inverse_transform([4, 5, 2, 0, 1, 1, 3, 3]))원-핫 인코딩
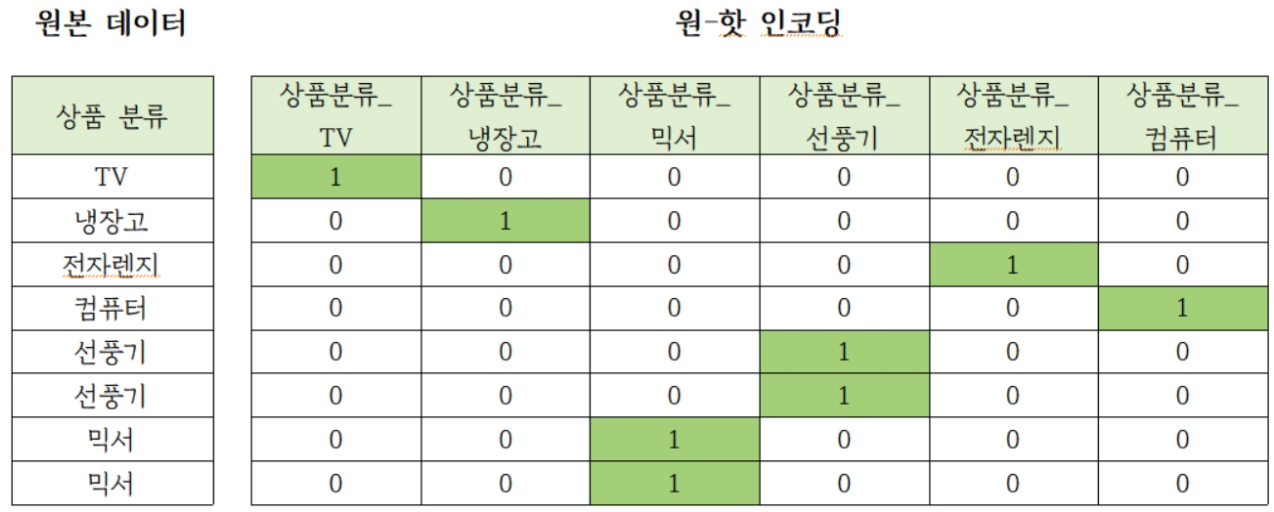
- 행 형태로 된 피처 고유 값을 열 형태로 차원 변환한 뒤, 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지는 0으로 표시
- 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 표시. 나머지는 0 표시(여러 개의 속성 중 단 한 개의 속성만 1로 표시)
- 사이킷런에서 OneHotEncoder 클래스 사용
- 변환 전 모든 문자열이 숫자형 값으로 변환되어야 함
- 변환 전 입력값으로 2차원 데이터가 필요함
from sklearn.preprocessing import OneHotEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
#숫자값으로 변환해야 하므로 LabelEncoder로 변환
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
#2차원 데이터로 변환
labels = labels.reshape(-1, 1)
#원핫인코딩 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)- Pandas의
get_dummies(): 원-핫인코딩을 쉽게 지원하는 API. 문자열 카테고리 값을 숫자형으로 변환할 필요 없이 바로 변환 가능
import pandas as pd
df = pd.DataFrame({'items':['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
pd.get_dummies(df)피처 스케일링과 정규화
- 피처 스케일링(Feature Scaling) : 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업. 표준화와 정규화가 대표적
- 표준화(Standardization) : 데이터 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것
- 표준화를 통해 변환될 피처 x의 새로운 i 번째 데이터는 (원래 값에서 피처 x의 평균을 뺀 값)을 (피처 x의 표준편차)로 나눈 값
- 정규화(Normalization) : 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 것
- 동일한 크기 단위로 비교하기 위해 값을 모두 0~1 값으로 변환 -> 개별 데이터의 크기를 모두 똑같은 단위로 변경
- 새로운 데이터는 (원래 값에서 피처 x의 최솟값을 뺀 값)을 (피처 x의 최댓값외 최솟값의 차이)로 나눈 값
- 사이킷런에서 Normalizer 모듈을 사용(일반적 정규화와 차이 약간 있음)
- 선형대수 정규화 개념 적용 : 개별 벡터의 크기를 맞추기 위해 변환('벡터 정규화')
- 개별 벡터를 모든 피처 벡터의 크기로 나눠줌
- 새로운 데이터는 (원래 값)에서 (모든 벡터의 i 번째 해당하는 크기를 합한 값)으로 나눔
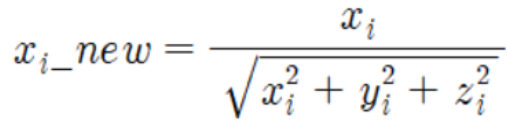
StandardScaler
- 표준화를 쉽게 지원하는 클래스 -> 개별 피처를 평균이 0이고 분산이 1이 되도록 함
- 사이킷런의 RBF 커널을 이용하는 서포트 벡터 머신(Support Vector Machine), 선형회귀(Linear Regression), 로지스틱 회귀(Logistic Regression)은 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됨 -> 표준화 한 뒤 적용해야 함
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() #StandardScaler 객체 생성
scaler.fit(iris_df) #StandardScaler로 데이터 세트 변환. fit() & trnasform() 호출
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names) #transform() 시 스케일 변환된 데이터가 Numpy 배열로 반환되므로 이를 다시 DataFrame으로 변환
print('피처들의 평균 값')
print(iris_df_scaled.mean())
print('\n피처들의 분산 값')
print(iris_df_scaled.var())MinMaxScaler
- 데이터값을 0과 1사이의 범위값으로 변환. 음수값이 있으면 -1에서 1값으로 변환
- 데이터 분포가 가우시간 분포가 아닐 경우 Min, Max Scale을 적용해볼 수 있음
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler() #객체 생성
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('피처들의 최소값')
print(iris_df_scaled.min())
print('\n피처들의 최대값')
print(iris_df_scaled.max())학습 데이터와 테스트 데이터의 스케일링 변환 시 유의점
- Scaler 객체 이용해 데이터 스케일링 변환 시
fit(),transform(),fit_transform()메소드 이용fit(): 데이터 변환을 위한 기준 정보 설정(예; 데이터셋의 최대/최소값 설정 등)transform(): 설정된 정보를 이용해 데이터 변환fit_transform(): 두 메소드를 한 번에 적용
- 학습 데이터로
fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 함 - 가능한 한, 전체 데이터의 스케일링 변환을 적용한 뒤, 학습과 테스트 데이터로 분리
- 그것이 여의치 않다면 테스트 데이터 변환 시에는 fit()이나 fit_transform()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform으로 변환할 것
- 이 주의사항은 사이킷런 기반의 PCA 등의 차원 축소 변환, 텍스트의 피처 벡터화 변환에도 동일 적용됨

🏫Inha Univ. Naval Architecture and Ocean Engineering & Computer Engineering (Undergraduate) / 🚢Autonomous Vehicles, 💡Machine Learning