
🚢사이킷런으로 수행하는 타이타닉 생존자 예측
- 캐글에서 제공하는 타이나틱 탑승자 데이터 기반으로 생존자 예측을 사이킷런으로 수행
- 데이터 내용
- Passerngerid : 탑승자 데이터 일련번호
- survived : 생존여부(0=사망 / 1=생존)
- pclass : 티켓의 선실 등급(1=일등석 / 2=이등석 / 3=삼등석)
- sex : 탑승자 성별
- name : 탑승자 이름
- Age : 탑승자 나이
- sibsp : 같이 탑승한 형재자매 또는 배우자 인원 수
- parch : 같이 탑승한 부모님 또는 어린이 인원 수
- ticket : 티켓 번호
- fare :요금
- cabin : 선실번호
- embarked : 중간 정착 항구 (C=Cherbourg, Q=Queenstown, S=Southampton)
✅0. 전체 라이브러리 및 모듈 로드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split, cross_val_score, KFold, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score💾1. 데이터 로드
titanic_df = pd.read_csv(r'./kaggle/titanic/titanic_train.csv')
titanic_df.head(3)
🔍2. Feature 확인 및 가공
# 데이터 칼럼 타입 확인
print(titanic_df.info())
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
df['Fare'].fillna(0, inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거
def drop_features(df):
df.drop(['PassengerId', 'Name', 'Ticket'], axis=1, inplace=True)
return df
# 레이블 인코딩 수행
def format_features(df):
df['Cabin']=df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 데이터 전처리 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df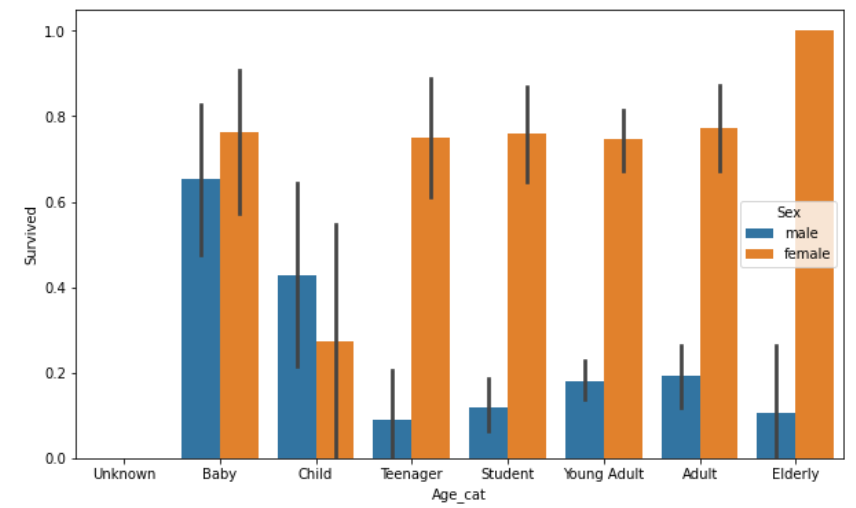
📝3. 학습&테스트 데이터셋 추출
# 원본 데이터 재로딩. 피처 데이터 세트와 레이블 데이터 세트 추출
titanic_df = pd.read_csv(r'./kaggle/titanic/titanic_train.csv')
y_titanic_df = titanic_df['Survived']
x_titanic_df = titanic_df.drop('Survived', axis=1)
x_titanic_df = transform_features(x_titanic_df)
# train_test_split() API를 이용해 별도의 테스트 데이터셋 추출
x_train, x_test, y_train, y_test = train_test_split(x_titanic_df, y_titanic_df, test_size=0.2, random_state=11)💡4. 머신러닝 알고리즘으로 생존자 예측
- 결정 트리(
DecisionTreeClassifier클래스), 랜덤 포레스트(RandomForestClassifier클래스), 로지스틱 회귀(LogisticRegrssion클래스) 이용 - 분리한 학습/테스트 데이터를 기반으로
fit(머신러닝 모델 학습),predict(예측)함 - 예측 성능 평가는 정확도 ->
accuracy_score()API 이용
#결정트리, 랜덤포레스트, 로지스틱 회귀 위한 사이킷런 classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression()
# 의사결정트리 학습, 예측, 평가
dt_clf.fit(x_train, y_train)
dt_pred = dt_clf.predict(x_test)
print('DecisionTreeClassifer 정확도 : {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
#DecisionTreeClassifer 정확도 : 0.7877
#랜덤포레스트 학습, 예측, 평가
rf_clf.fit(x_train, y_train)
rf_pred = rf_clf.predict(x_test)
print('RandomForestClassifier 정확도 : {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
#RandomForestClassifier 정확도 : 0.7877
# 로지스틱회귀 학습, 예측, 평가
lr_clf.fit(x_train, y_train)
lr_pred = lr_clf.predict(x_test)
print('LogisticRegression 정확도 : {0:.4f}'.format(accuracy_score(y_test, lr_pred)))
#LogisticRegression 정확도 : 0.8492💯5. 교차 검증으로 결정 트리 모델 평가
- KFold
def exec_kfold(clf, folds=5):
kfold = KFold(n_splits=folds) #폴드 세트를 5개인 KFold 객체 생성
scores = [] # 폴드 수만큼 예측 결과 저장을 위한 리스트 객체 생성
for iter_count, (train_index, test_index) in enumerate(kfold.split(x_titanic_df)):
x_train, x_test = x_titanic_df.values[train_index], x_titanic_df.values[test_index]
y_train, y_test = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
accuracy = accuracy_score(y_test, predictions)
scores.append(accuracy)
print('교차 검증 {0} 정확도 : {1:.4f}'.format(iter_count, accuracy))
mean_score = np.mean(scores)
print('평균 정확도 : {0:.4f}'.format(mean_score))
exec_kfold(dt_clf, folds=5)- cross_val_score() API
scores = cross_val_score(dt_clf, x_titanic_df, y_titanic_df, cv=5)
for iter_count, accuracy in enumerate(scores):
print('교차 검증 {0} 정확도 : {1:.4f}'.format(iter_count, accuracy))
print('평균 정확도 : {0:.4f}'.format(np.mean(scores)))- GridSearchCV
parameters = {'max_depth':[2, 3, 5, 10], 'min_samples_split':[2, 3, 5], 'min_samples_leaf':[1, 5, 8]}
grid_dclf = GridSearchCV(dt_clf, param_grid=parameters, scoring='accuracy', cv=5)
grid_dclf.fit(x_train, y_train)
print('GridSearchCV 최적 하이퍼 파라미터 : ', grid_dclf.best_params_)
print('GridSearchCV 최고 정확도 : {0:.4f}'.format(grid_dclf.best_score_))
best_dclf = grid_dclf.best_estimator_
dpredictions = best_dclf.predict(x_test)
accuracy = accuracy_score(y_test, dpredictions)
print('테스트 세트에서의 DecisionTreeClassifier 정확도 : {0:.4f}'.format(accuracy))
🏫Inha Univ. Naval Architecture and Ocean Engineering & Computer Engineering (Undergraduate) / 🚢Autonomous Vehicles, 💡Machine Learning