논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
시각적 사고의 흐름 확산 모델(Visual Chain-of-Thought Diffusion Models)
William Harvey Frank Wood
초록(Abstract)
조건부 이미지 확산 모델(conditional image diffusion models)의 최근 진보는 놀라울 정도이며, 이는 텍스트 설명(text description), 장면 레이아웃(scene layout), 스케치(sketch)에 기반한 모델에 대해 말할 때도 마찬가지입니다. 비조건부 이미지 확산 모델(unconditional image diffusion models)도 개선되고 있지만 여전히 뒤처져 있으며, 클래스 레이블(class labels)과 같은 저차원 특징에 기반한 확산 모델도 마찬가지입니다. 우리는 두 단계 샘플링 절차를 사용하여 조건부와 비조건부 모델 사이의 격차를 줄이고자 합니다. 첫 번째 단계에서는 이미지의 의미적 내용을 설명하는 임베딩(embedding)을 샘플링합니다. 두 번째 단계에서는 이 임베딩에 기반한 이미지를 샘플링한 다음 임베딩을 버립니다. 이렇게 함으로써 우리는 조건부 확산 모델의 강력한 기능을 비조건부 생성 작업(unconditional generation task)에 활용할 수 있으며, 이것이 표준 비조건부 생성(standard unconditional generation)에 비해 FID를 향상시킨다는 것을 보여줍니다.
1. 서론(Introduction)
최근의 텍스트-이미지 확산 생성 모델(text-to-image diffusion generative models, DGMs)은 놀라운 샘플 품질을 보여주었으며(Saharia et al., 2022), 이제는 예술 작품을 만드는 데 사용되고 있습니다(Oppenlaender, 2022). 추가적인 연구에서는 장면 레이아웃(scene layouts)(Zhang & Agrawala, 2023), 분할 마스크(segmentation masks)(Zhang & Agrawala, 2023; Hu et al., 2022), 또는 특정 객체의 외형(appearance of a particular object)(Ma et al., 2023)에 기반한 조건 설정을 탐구했습니다. 우리는 이러한 방법들을 "조건부" DGMs로 묶어 텍스트나 다른 정보에 의존하지 않고 이미지를 샘플링하는 "비조건부" 이미지 DGMs와 대조합니다. 비조건부 DGMs에 비해 조건부 DGMs는 일반적으로 더 현실적인 샘플을 생성하며(Ho & Salimans, 2022; Bao et al., 2022; Hu et al., 2022), 적은 샘플링 단계에서 더 잘 작동합니다(Meng et al., 2022). 또한, 우리의 결과는 샘플의 현실성이 DGM이 조건부로 설정된 "얼마나 많은"[^0] 정보에 따라 증가한다는 것을 시사합니다. 그림 1에서 암시하듯이, "녹색 들판 사이의 도로에 대한 항공 사진"에 기반한 조건으로 설정된 이미지가 단순히 "항공 사진"에 기반한 조건으로 설정된 이미지보다 더 현실적일 가능성이 높습니다. 이러한 성능 격차는 문제가 됩니다. 컴퓨터 비전 시스템을 테스트하기 위한 합성 항공 사진 데이터셋을 생성하려는 연구자는 현재 (a) 각 데이터셋 이미지를 생성하기 전에 장면 설명을 만들고, 이들이 원하는 분포 전체를 커버하도록 해야 하거나, (b) 각 이미지가 "항공 사진"이라는 조건에만 의존하여 얻은 열등한 이미지 품질을 받아들여야 합니다.

이 격차를 메우기 위해, 우리는 대규모 언어 모델(LLMs)에서 "사고의 연쇄"(chain of thought) 추론(Wei et al., 2022)에서 영감을 받았습니다. LLM을 사용하여 퍼즐에 답하는 것을 고려해 보세요: 로저는 테니스 공 5개를 가지고 있습니다. 그는 테니스 공이 3개 들어 있는 캔을 2개 더 삽니다. 그는 지금 몇 개의 테니스 공을 가지고 있습니까? LLM이 직접 답을 말하도록 요청받으면, 모든 추론과 계산을 한 단계에서 수행해야 합니다. 대신 그것이 답을 계산하면서 그 이유를 설명하도록 요청받으면, 먼저 답이 이라는 표현식에 의해 주어진다는 결론을 내릴 수 있고, 그런 표현식에서 비롯된 답을 출력할 수 있습니다. 이 중간 단계에서 표현식을 출력하는 것은 정확도를 크게 향상시킵니다(Wei et al., 2022).

그림 2. AFHQ/FFHQ에서의 CLIP-조건부 샘플. 각 행은 동일한 CLIP 임베딩을 조건으로 하는 세 개의 샘플을 보여줍니다.
이러한 논리를 따라 이미지 생성 모델을 상상해 봅시다. "항공 사진"을 샘플링하라는 요청을 받았을 때, 모델은 더 자세한 설명으로 시작할 수 있습니다: "작은 녹색 들판의 패치워크가 있는 항공 사진 [...]". 이 자세한 설명이 주어지면, 조건부 DGM(Deep Generative Model)의 전체 파워를 활용하여 고품질의 이미지를 생성할 수 있습니다. 우리의 접근 방식은 이러한 논리를 따르지만, 언어를 다루는 대신, 우리의 중간 공간은 사전 훈련된 CLIP 임베더(Radford et al., 2021)에서 나온 의미 있는 임베딩으로 구성됩니다. 구체적으로 우리는 데이터셋의 이미지들의 CLIP 임베딩 분포를 모델링하기 위해 DGM을 훈련시킵니다. 이를 통해 우리는 먼저 CLIP 임베딩을 샘플링한 다음 이 CLIP 임베딩을 조건부 이미지 DGM에 입력하여 개선된 비조건부 이미지 생성을 달성합니다. 이 기술이 텍스트-조건부 이미지 생성과 관련이 있지만, 우리는 대신 개선된 비조건부 이미지 생성에 적용하고 있습니다. 우리는 이 모델을 Visual Chain-of-Thought Diffusion Model (VCDM)이라고 부르며, 코드를 https://github.com/plai-group/vcdm 에서 공개합니다.
2. 배경
조건부 DGMs 우리는 Karras et al. (2022)의 더 완전한 소개를 참조하면서, 우리의 기여를 이해하기에 충분한 조건부 DGMs에 대한 개요를 제공합니다. 조건부 이미지 DGM(Tashiro et al., 2021)은 조건 입력 가 주어진 상태에서 이미지 를 샘플링하는데, 여기서 는 예를 들어 클래스 레이블, 텍스트 설명 또는 이 둘의 튜플일 수 있습니다. 아래에서 를 null 변수로 설정함으로써 조건 없는 DGM을 복구할 수 있습니다. 에서 샘플링된 쌍의 데이터셋이 주어진 상태에서, 조건부 DGM 는 를 근사하도록 적합화됩니다. 이는 신경망 에 의해 매개변수화되며, 최적화를 위해 훈련됩니다.
여기서 는 표준 편차 를 가진 가우시안 노이즈로 손상된 의 복사본이며; 는 에 대한 넓은 분포이고; 는 가중치 함수입니다. 추론 중에는 에 의존하는 동역학을 가진 확률 미분 방정식을 통해 에서 샘플을 추출합니다.

그림 3. AFHQ(Choi et al., 2020)와 FFHQ(Karras et al., 2018)에서 의 차원성에 따른 FID. 작은 훈련 예산(갈색)으로는 가 너무 많은 정보를 담고 있을 때 해로울 수 있습니다. 더 큰 훈련 예산(보라색)으로는 를 고차원으로 만드는 것이 도움이 됩니다.
CLIP 임베딩 CLIP(대조적 언어-이미지 사전 학습)(Radford et al., 2021)은 큰 캡션 이미지 데이터셋에서 학습된 두 개의 신경망, 이미지 임베더 와 텍스트 임베더 로 구성됩니다. 이미지 와 캡션 가 주어졌을 때, 학습 목표는 와 가 일치하는 이미지-캡션 쌍이면 와 사이의 코사인 유사도(cosine similarity)가 크고, 그렇지 않으면 작게 유도합니다. 따라서 이미지 임베더는 이미지에서 캡션에 포함될 수 있는 모든 특징을 포착하는 의미론적으로 의미 있는 임베딩으로 매핑하는 방법을 학습합니다. 우리는 Radford et al. (2021)에 의해 공개된 ViT-B/32 아키텍처와 가중치를 가진 CLIP 이미지 임베더를 사용합니다. 우리는 단일 CLIP 임베딩에 대해 조건부 DGM이 생성한 이미지의 분포를 보여주는 것으로 CLIP 임베딩에 의해 포착된 정보를 시각화할 수 있습니다; 그림 2를 참조하세요.
3. 조건부 대 비조건부 DGMs
조건부 DGMs가 비조건부 DGMs를 능가한다는 것은 무슨 의미일까요? 비조건부 DGMs를 평가하는 표준 절차는 모델로부터 독립적으로 개의 이미지 집합을 샘플링하는 것으로 시작합니다: . 그런 다음 이 집합과 데이터셋 사이의 프레셰 인셉션 거리(Fréchet Inception distance, FID)(Heusel et al., 2017)를 계산할 수 있습니다. 생성 모델이 데이터 분포와 잘 일치하면 FID는 낮을 것입니다. 조건부 DGMs의 경우 표준 절차에 한 단계가 더 추가됩니다: 먼저 독립적으로 를 샘플링합니다. 그런 다음 각 이미지를 해당하는 에 대해 로 샘플링합니다. 그 다음, 비조건부 경우와 마찬가지로, 을 참조하지 않고 이미지 집합 과 데이터셋 사이의 FID를 계산합니다. 쌍 사이의 정렬을 측정하지 않음에도 불구하고, 조건부 DGMs는 많은 설정에서 비교할 수 있는 비조건부 DGMs보다 이 메트릭에서 더 우수한 성능을 보입니다: 클래스 조건부 CIFAR-10 생성(Karras et al., 2022), 세그멘테이션 조건부 생성(Hu et al., 2022), 또는 바운딩 박스 조건부 생성(Hu et al., 2022).
조건부 DGM이 비조건부 DGM을 왜 이기는가? 조건부 DGM은 업데이트가 다음을 포함하기 때문에 훈련 중에 비조건부 DGM보다 더 많은 데이터를 "보게" 됩니다.
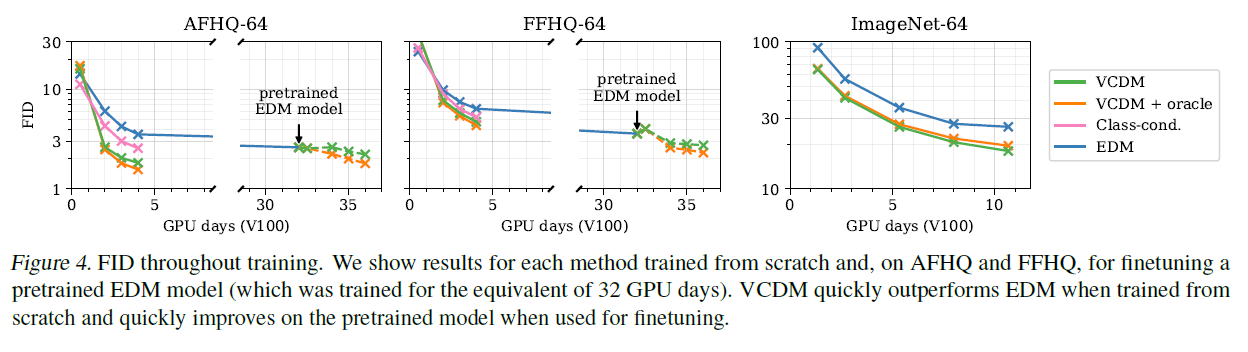
그림 4. 훈련 중 FID(Fréchet Inception Distance). 우리는 각 방법을 처음부터 훈련한 결과를 보여주고, AFHQ와 FFHQ에서는 사전 훈련된 EDM 모델을 미세 조정한 결과를 보여줍니다(32 GPU 일에 해당하는 기간 동안 훈련되었습니다). VCDM은 처음부터 훈련할 때 빠르게 EDM을 능가하고, 미세 조정을 위해 사용될 때 사전 훈련된 모델을 빠르게 개선합니다.
뿐만 아니라 도 포함합니다. Hu 등(2022)은 이것이 그들의 성공의 유일한 이유는 아니라고 보여주었는데, 이는 가 비조건부 데이터셋에서 자기 지도 학습을 통해 파생될 때에도 효과가 유지되기 때문입니다. 따라서 Bao 등(2022)은 조건부 분포가 일반적으로 "모드가 적고 원래 데이터 분포보다 적합하기 쉽다"고 가정합니다.
조건부 DGM이 비조건부 DGM을 이기는 경우는 언제인가?
이 질문에 답하기 위해 우리는 그림 3의 결과를 제시합니다. 우리는 다양한 정보 내용을 가진 임베딩에 조건을 부여하여 훈련된 조건부 DGM의 FID 점수를 보여줍니다. 우리는 데이터셋의 각 이미지에 대한 CLIP 임베딩에서 시작하여 를 생성하고, 주성분 분석을 사용하여 차원을 줄이거나(왼쪽 두 패널) K-평균 클러스터링을 사용하여 이산화합니다(오른쪽 두 패널)(Hu 등, 2022). 우리는 작은 훈련 예산이 주어졌을 때, 적은 정보에 조건을 부여하는 것이 가장 좋다는 것을 알 수 있습니다. 더 큰 훈련 예산으로, 의 차원이 확장됨에 따라 성능이 지속적으로 향상되는 것으로 보입니다. 우리는 (1) 더 높은 차원의 y에 조건을 부여하는 것이 훈련을 느리게 만든다고 가정합니다. 왜냐하면 이는 주어진 값에 가까운 점들이 덜 자주 보일 것이기 때문이고, (2) 충분히 큰 계산 예산이 주어지면, 와 상관관계가 있는 어떤 도 조건을 부여하는 데 유용할 것입니다. 이는 계산 예산이 증가함에 따라 비조건부 DGM의 성능을 조건부 DGM의 성능과 일치시키는 것이 점점 더 유용해질 것임을 시사합니다.
4. 방법
우리는 CLIP 임베딩에 조건을 부여하는 것이 DGM을 개선한다는 것을 확인했습니다. 이제 우리는 이 현상을 이용하여 비조건부 설정(사용자가 조건을 부여할 입력을 지정하고 싶지 않은 경우)과 "경미하게 조건부" 설정(입력이 저차원인 경우, 예를 들어 클래스 라벨)에서 이점을 얻기 위한 VCDM을 소개합니다. 우리는 이러한 추가 입력을 a라고 표시할 것입니다(비조건부 설정에서 a를 null 변수로 두고) 그리고 이제부터 항상 를 CLIP 임베딩을 참조하기 위해 사용할 것입니다. VCDM은 목표 분포 를 다음과 같이 근사합니다.
여기서 는 CLIP 임베딩을 모델링하는 두 번째 DGM(Deep Generative Model)입니다. 이 분포에서 샘플링하기 위해서는 를 샘플링한 다음 조건부 이미지 DGM을 활용하여 를 샘플링하고 는 버립니다. 이제부터 를 조건부 이미지 모델(conditional image model)이라고 하고 를 보조 모델(auxiliary model)이라고 부르겠습니다. 우리의 실험에서 보조 모델은 조건부 이미지 모델에 비해 상대적으로 작은 구조를 사용하기 때문에 추가 비용이 거의 들지 않습니다.
보조 모델(auxiliary model) 우리의 보조 모델은 가 512차원 CLIP 임베딩인 를 대상으로 하는 조건부 DGM입니다. 우리는 Ramesh 등(2022)의 구조적 선택을 따라 트랜스포머(transformer) 구조를 가진 DGM을 사용합니다. 이 모델은 512차원 입력 토큰의 시리즈를 입력으로 받습니다: 의 임베딩; 이것이 null이 아닌 경우 a의 임베딩; 의 임베딩; 그리고 학습된 쿼리(query). 이들은 여섯 개의 트랜스포머 레이어를 통과한 후 학습된 쿼리 토큰에 해당하는 출력을 최종 출력으로 사용합니다. Ramesh 등(2022)처럼, 우리는 더 흔한 확산 문헌에서와 같이 추가된 노이즈를 추정하는 대신, 노이즈가 제거된 a의 추정치를 출력하도록 DGM을 매개변수화합니다. AFHQ와 FFHQ에서 우리는 보조 모델이 과적합(overfitting)되는 것을 방지하기 위해 데이터 증강이 도움이 된다는 것을 발견했습니다. 우리는 이미지 공간에서 증강(회전, 뒤집기 및 색상 지터 포함)을 수행하고 증강된 이미지를 를 통해 전달하여 증강된 CLIP 임베딩을 얻습니다. Karras 등(2022)을 따라, 우리는 테스트 시에 증강이 없다는 조건을 설정할 수 있도록 변환기(transformer)에 추가 입력 토큰으로 증강을 설명하는 레이블을 전달합니다.
조건부 이미지 모델 우리의 확산 과정 하이퍼파라미터와 샘플러는 Karras et al. (2022)의 연구를 기반으로 합니다. AFHQ와 FFHQ에 대해서는 Song et al. (2020)에 의해 처음 제안된 U-Net 아키텍처를 사용합니다. ImageNet에 대해서는 Dhariwal Nichol (2021)에 의해 제안된 약간 더 큰 U-Net 아키텍처를 사용합니다. 데이터 증강 스키마는 각 데이터셋에 대해 Karras et al. (2022)의 것과 동일하게 맞춥니다. 두 아키텍처 모두 조건부 변형이 확립되어 있습니다[^2](Dhariwal \& Nichol, 2021; Karras et al., 2022), 이는 학습된 선형 투영을 통해 를 통합하며, 이 투영은 잡음 표준 편차 의 임베딩에 추가됩니다. 우리의 조건부 이미지 모델은 추가적으로 를 통합해야 합니다; 이는 에 를 단순히 연결하고 결과 벡터에 대한 투영을 학습함으로써 수행할 수 있습니다.
5. 실험
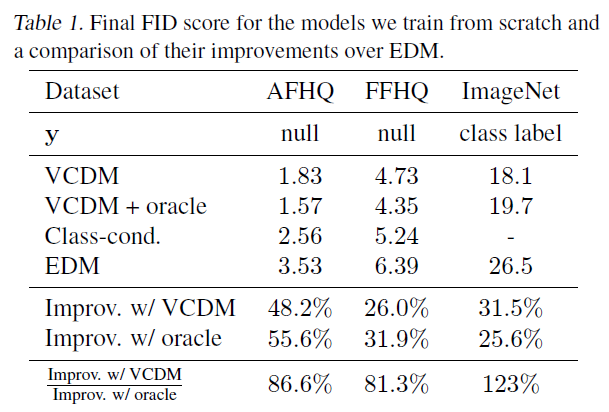
우리는 세 개의 데이터셋에서 실험을 진행합니다: AFHQ(Choi et al., 2020), FFHQ(Karras et al., 2018) 그리고 ImageNet(Deng et al., 2009), 모두 해상도입니다. 우리는 AFHQ와 FFHQ에 대해 무조건부 생성(unconditional generation)을, ImageNet에 대해서는 클래스 조건부 생성(class-conditional generation)을 목표로 합니다. 각 데이터셋에서 처음부터 네트워크를 훈련시키는 것뿐만 아니라, Karras et al. (2022)에 의해 공개된 모델 체크포인트를 AFHQ와 FFHQ에서 사용하고, 이를 CLIP 임베딩에 조건을 맞추어 미세 조정합니다. 이를 위해 CLIP 임베딩의 학습 가능한 선형 투영을 단순히 추가하고 그 가중치를 0으로 초기화합니다. 그림 4는 조건부 이미지 모델의 훈련 과정에서 각 설정과 데이터셋에 대한 FID를 보고합니다. 각 경우에 보조 모델은 하나의 V100 GPU에서 하루 동안 훈련됩니다. 우리는 VCDM을 세 가지 다른 접근법과 비교합니다: EDM(Karras et al., 2018)은 를 직접 모델링하는 표준 DGM입니다. 오라클을 사용한 VCDM은 우리의 조건부 이미지 모델을 사용하지만, 학습된 보조 모델에서 샘플링하는 대신 각 테스트 a에 대한 실제 를 사용합니다. 즉, 완벽한 보조 모델을 가졌을 때 VCDM이 달성할 수 있는 성능입니다. Class-cond는 가 null인 무조건부 작업에 적용되는 절제(ablation)입니다. 이는 이산 를 사용합니다(그림 3의 오른쪽과 같이) 그래서 는 우리가 정확히 샘플링할 수 있는 간단한 범주형 분포이지만, VCDM에 의해 성능이 능가됩니다.
VCDM은 1-2 GPU-일(GPU-days) 후에 무조건적 생성(unconditional generation)을 지속적으로 능가하며, 이 성능 격차는 네트워크를 훈련하는 동안 계속됩니다. 오라클(oracle)이 있는 VCDM과 없는 VCDM의 성능을 비교해보면 두 성능이 근접하다는 것을 알 수 있습니다. 처음부터 훈련된 네트워크의 경우, 5장에서 VCDM은 항상 EDM보다 적어도 이상의 개선을 보여주며, 이는 가 의 좋은 근사치임을 나타냅니다. 따라서 우리는 무조건적 샘플링(unconditional sampling)을 위해 조건부 DGMs(conditional DGMs)의 거의 모든 힘을 활용할 수 있습니다.
6. 관련 연구
여러 기존의 이미지 생성 모델들은 더 나은 텍스트 조건부 생성(text-conditional generation)을 위해 CLIP 임베딩을 활용합니다(Nichol et al., 2021; Ramesh et al., 2022). 우리는 다음과 같은 점에서 차별화됩니다[^3]
표 1. 처음부터 훈련한 모델들의 최종 FID 점수와 EDM에 대한 개선 비교.
CLIP 임베딩은 텍스트 조건부 생성(text-conditioning)에만 유용한 것이 아니라, 생성된 이미지의 사실성을 향상시키는 일반적인 도구로도 사용됩니다. 우리는 이를 무조건적(unconditional) 생성과 클래스 조건부(class-conditional) 생성에 대해 보여줍니다. 우리의 연구는 Weilbach et al. (2022)에서 영감을 받았으며, 그들은 관심 있는 변수와 관찰된 변수(a) 뿐만 아니라 문제에 특화된 보조 변수(예: )를 모델링함으로써 다양한 근사 추론 환경에서 성능을 향상시킨 것을 보여주었습니다. 우리는 이 기술들을 이미지 영역에 적용하고 사전 훈련된 CLIP 임베더를 사용하여 보조 변수를 얻습니다. VCDM은 또한 학습된 잠재 공간에서 확산을 수행하는 방법들과 관련이 있습니다(Rombach et al., 2022): 우리의 보조 모델 는 잠재 공간에서의 "사전(prior)"에 해당하고, 우리의 조건부 이미지 모델 는 "디코더(decoder)"에 해당합니다. 이러한 방법들은 일반적으로 거의 결정론적인 디코더를 사용하기 때문에, 그들의 잠재 변수는 이미지에 대한 모든 정보를 요약해야 합니다. 반면에, 우리의 조건부 DGM 디코더는 에 얼마나 적은 정보가 저장되어 있든 합리적으로 기능할 것이므로, VCDM은 무엇을 저장할지에 대한 추가적인 자유도를 제공합니다. 이것은 미래 탐색을 위한 흥미로운 설계 공간입니다. 분류기(Classifier)(Song et al., 2020)와 분류기 없는 안내(classifier-free guidance)(Ho & Salimans, 2022)는 DGM에서 조건부 샘플링을 위한 두 가지 대안적인 방법입니다. 두 방법 모두 에 대한 충실도와 와 사이의 정렬도를 조절하기 위한 "안내 강도(guidance strength)" 하이퍼파라미터를 가지고 있습니다. VCDM에 대한 가능한 확장은 를 이들 중 하나로 매개변수화하는 것일 수 있습니다.
7. 토론 및 결론
우리는 조건부 DGM의 인상적인 성능을 활용하는 무조건적 또는 경미한 조건부 이미지 생성을 위한 VCDM 방법을 제시했습니다. 방대한 미개척 설계 공간이 남아 있습니다: CLIP 임베딩 외에도 우리가 조건을 걸 수 있는 더 유용한 양들이 거의 확실히 더 있을 것입니다. 또한 여러 양에 조건을 걸거나, 일련의 조건부 DGM을 "연쇄(chain)"하는 것도 도움이 될 수 있습니다. 다른 방향은 예를 들어, 와 의 공동 공간에 대한 단일 확산 모델을 학습함으로써 VCDM의 아키텍처를 단순화하는 것입니다.
감사의 말
우리는 캐나다 자연과학공학연구위원회(Natural Sciences and Engineering Research Council of Canada, NSERC), 캐나다 CIFAR AI Chairs 프로그램, 그리고 인텔 병렬 컴퓨팅 센터(Intel Parallel Computing Centers) 프로그램의 지원에 감사를 표합니다. 이 자료는 미국 공군 연구소(United States Air Force Research Laboratory, AFRL)가 방위고등연구계획국(Defense Advanced Research Projects Agency, DARPA)의 데이터 주도 발견 모델(Data Driven Discovery Models, D3M) 프로그램(계약 번호 FA8750-19-2-0222)과 라벨이 적은 학습(Learning with Less Labels, LwLL) 프로그램(계약 번호 FA8750-19-C-0515)에 의해 지원된 작업을 기반으로 합니다. 추가적인 지원은 UBC의 복합재료 연구 네트워크(Composites Research Network, CRN), 데이터 과학 연구소(Data Science Institute, DSI) 및 팀의 상호학제 연구 진흥을 위한 지원(STAIR) 그랜트를 통해 제공되었습니다. 이 연구는 WestGrid(https://www.westgrid.ca/)와 Compute Canada(www.computecanada.ca)가 제공한 기술 지원과 컴퓨팅 자원에 의해 부분적으로 가능했습니다.
