논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
- 당분간 기술 trend를 따라잡기 위해 survey논문에 집중 할 예정입니다.
시각-언어 사전 훈련 모델에 관한 조사
Yifan Du , Zikang Liu , Junyi Li and Wayne Xin Zhao
가오링(Gaoling) 인공지능 학교, 중국 인민대학교
DIRO, 몬트리올 대학교
베이징 빅데이터 관리 및 분석 방법 키 랩(Beijing Key Laboratory of Big Data Management and Analysis Methods)
{yifandu1999, jasonlaw8121, batmanfly}@gmail.com, junyi.li@umontreal.ca
초록
트랜스포머(transformer)의 발전과 함께, 사전 훈련 모델(pre-trained models)은 최근 몇 년 동안 눈부신 속도로 발전해왔습니다. 이들은 자연어 처리(NLP)와 컴퓨터 비전(CV) 분야의 주류 기술을 지배하고 있습니다. 시각-언어(Vision-and-Language, V-L) 학습 분야에 사전 훈련을 어떻게 적용하고 하류 작업(downstream task)의 성능을 향상시킬 것인지가 다모달 학습(multimodal learning)의 중심 주제가 되었습니다. 본 논문에서는 시각-언어 사전 훈련 모델(Vision-Language PreTrained Models, VL-PTMs)의 최근 진전에 대해 검토합니다. 핵심 내용으로, 우리는 사전 훈련 전에 원시 이미지와 텍스트를 단일 모달 임베딩(single-modal embeddings)으로 인코딩하는 몇 가지 방법을 간략하게 소개합니다. 그 다음, 텍스트와 이미지 표현 간의 상호작용을 모델링하는 VL-PTMs의 주류 아키텍처에 대해 자세히 살펴봅니다. 또한 널리 사용되는 사전 훈련 작업을 소개하고, 몇 가지 일반적인 하류 작업에 대해서도 소개합니다. 마지막으로 이 논문을 결론짓고 몇 가지 유망한 연구 방향을 제시합니다. 우리의 조사는 연구자들에게 관련 연구에 대한 종합적인 정보와 지침을 제공하는 것을 목표로 합니다.
1 서론
우리는 현재 다양한 모달리티(음성, 시각, 냄새 등)가 있는 세계에 살고 있으며, 그 중 시각과 언어는 두 가지 중요한 모달리티입니다. 학계에서는 V-L 작업에 초점을 맞춘 방대한 연구가 이루어지고 있습니다. 이러한 작업들은 에이전트가 이 두 모달리티로부터 정보를 함께 처리하고 복잡한 질문에 답하는 데 사용해야 합니다. 예를 들어, 시각적 질문 응답(Visual Question Answering, VQA) [Antol et al., 2015]은 이미지와 해당 질문을 입력으로 받아 올바른 답을 제공하며, 이미지 캡셔닝(Image Captioning) [Lin et al., 2014]은 주어진 이미지에 대한 설명을 생성합니다.
딥 러닝(deep learning)은 인공지능 분야에 혁명을 가져왔습니다. 다양한 딥 모델들이 V-L 작업을 해결하기 위해 적용되었는데, 여기에는 순환 신경망(Recurrent Neural Network, RNN) [Arevalo et al., 2017], 합성곱 신경망(Convolutional Neural Network, CNN) [Huang et al., 2020] 및 트랜스포머(Transformer) [Vaswani et al., 2017]가 포함됩니다. 그럼에도 불구하고[^0]
딥 러닝(deep learning)의 성공에도 불구하고, 대부분의 모델들은 특정 작업에 맞게 설계되어 이전성(transferability)이 떨어집니다. 대규모 일반 데이터셋에서 거대한 모델을 사전 학습(pre-training)한 후 특정 하류 작업(downstream tasks)에 미세 조정(fine-tuning)하는 것은 이전성을 높이는 한 가지 방법입니다. 사전 학습이 효과적이라는 것은 처음에 컴퓨터 비전(CV) 분야에서 발견되었습니다 [Simonyan and Zisserman, 2014]. 트랜스포머(transformer) [Vaswani et al., 2017]와 BERT [Devlin et al., 2018]가 제안된 이후, 사전 학습과 미세 조정의 패러다임은 자연어 처리(NLP) 분야에서 널리 퍼졌습니다. 장거리 의존성(long-range dependency)을 모델링하는 강력한 능력을 가진 트랜스포머는 대부분의 사전 학습된 언어 모델(Pretrained Language Models, PLMs)의 기반이 되었습니다. BERT와 GPT-3 [Brown et al., 2020]은 전통적인 방법들을 크게 뛰어넘고 다양한 하류 작업에서 새로운 최고 성능(state-of-the-art) 결과를 달성하는 전형적인 PLMs입니다.
CV와 NLP 분야에서 사전 학습된 모델의 성공으로 인해, 많은 연구들이 시각과 언어 모달리티(visual and language modalities) 모두에서 대규모 모델을 사전 학습하려고 시도했습니다. 이를 비전-언어 사전 학습 모델(Vision-Language Pre-Trained Models, VL-PTMs)이라고 합니다. 대규모 이미지-텍스트 코퍼스(image-text corpora)에서 사전 학습함으로써, VL-PTMs는 범용적인 교차 모달 표현(cross-modal representations)을 학습할 수 있으며, 이는 하류 V-L 작업에서 강력한 성능을 달성하는 데 유리합니다 [Zellers et al., 2019; Tan and Bansal, 2019]. 예를 들어, LXMERT [Tan and Bansal, 2019]는 이중 스트림 융합 인코더(dual-stream fusion encoder)를 사용하여 V-L 표현을 학습하고, 918만 개의 이미지-텍스트 쌍(image-text pairs)에 대한 사전 학습을 통해 VQA [Antol et al., 2015], [Suhr et al., 2018] 작업에서 전통적인 모델들을 크게 능가합니다. 또한, VL-PTMs는 시각적 상식 추론(visual commonsense reasoning) [Zellers et al., 2019]과 이미지 캡셔닝(image captioning) [Lin et al., 2014]과 같은 많은 다른 V-L 작업에서 강력한 결과를 달성합니다. 이러한 VL-PTMs는 다양한 단일 모달 인코더(single-modal encoders), 정교한 V-L 상호 작용 체계(V-L interaction schemes), 그리고 다양한 사전 학습 작업(pre-training tasks)을 활용합니다.
그러나 이 분야의 최근 진전을 요약하는 종합적인 조사(survey)가 부족합니다. Mogadala et al. [2021]은 주로 기존의 V-L 작업, 데이터셋, 그리고 전통적인 해결책들을 리뷰하지만 V-L 사전 학습 방법에 대해서는 거의 소개하지 않습니다. Ruan과 Jin [2022]은 비전-언어 PTMs가 아닌 비디오-언어 PTMs에 초점을 맞춥니다. 그들과는 달리, 우리의 조사는 VL-PTMs에 대한 철저한 리뷰를 제시하는 것을 목표로 하며, 최근의 연구 진전을 요약하고 관련 연구로의 지침을 제공합니다. 우리는 표 1에서 최근의 주류 VL-PTMs를 제시합니다.
VL-PTM을 사전 훈련하는 것은 기본적으로 세 단계로 이루어집니다: 1) 이미지와 텍스트를 그들의 의미를 보존하면서 잠재 표현으로 인코딩하기(섹션 2); 2) 두 모달리티 간의 상호작용을 모델링하기 위한 성능이 좋은 아키텍처 설계하기(섹션 3); 그리고 3) VL-PTM을 훈련시키기 위한 효과적인 사전 훈련 작업 고안하기(섹션 4). 범용적인 시각 및 언어 특징을 학습한 후, VL-PTM은 다양한 하류 V-L 작업에 미세 조정될 수 있습니다(섹션 5). 마지막으로, 이 서베이를 마무리하며 섹션 6에서 몇 가지 유망한 연구 방향을 제시합니다.
2 시각-언어 표현 학습
섹션 1에서 논의한 바와 같이, 이미지와 텍스트를 입력 의미를 보존하는 임베딩으로 인코딩하는 것은 VL-PTM을 사전 훈련하는 첫 번째 단계입니다. 이미지와 텍스트를 인코딩하는 방법은 두 모달리티 간의 차이로 인해 상당히 다릅니다. 거의 모든 VL-PTM은 텍스트 인코더로 트랜스포머 기반 PTM을 사용하지만, 시각적 내용에 기반한 시각적 표현을 학습하는 방법은 여전히 열린 문제입니다. 이어서, 이미지와 텍스트를 교차 모달 트랜스포머에 입력하기 전에 단일 모달 임베딩으로 인코딩하는 여러 방법을 소개합니다.
사전 훈련 데이터셋. VLPTM을 사전 훈련하는 초기 단계는 대규모 이미지-텍스트 쌍을 구성하는 것입니다. 우리는 사전 훈련 데이터셋을 로 정의합니다. 여기서 와 는 각각 텍스트와 이미지를 나타내며, 은 이미지-텍스트 쌍의 수입니다. 구체적으로, 각 텍스트는 토큰의 시퀀스 로 토큰화됩니다. 마찬가지로, 각 이미지도 객체 특징(또는 그리드 특징, 패치 특징)의 시퀀스로 변환되며, 로 표시됩니다. 표 2에서는 널리 사용되거나 최근에 제안된 사전 훈련 데이터셋을 여러 개 나열하고 있습니다.
텍스트 표현. VLPTM에 대한 기존 연구 대부분은 BERT [Devlin et al., 2018]를 따라 원시 텍스트를 전처리합니다. 텍스트 시퀀스는 먼저 토큰으로 분할되고 "[CLS]"와 "[SEP]" 토큰과 연결되며, 로 표시됩니다. 각 토큰 는 단어 임베딩으로 매핑됩니다. 또한, 위치를 나타내는 위치 임베딩과 모달리티 유형을 나타내는 세그먼트 임베딩이 단어 임베딩과 함께 추가되어 의 최종 임베딩을 얻습니다.
이미지 표현. 텍스트와 짝을 이루는 임베딩(embedding) 시퀀스와 일치하도록, 이미지 역시 임베딩 벡터의 시퀀스로 표현될 것입니다. 이 방식을 통해, 우리는 두 모달리티(modality) 모두에 대해 임베딩 시퀀스로 입력 표현을 통일할 수 있습니다. 텍스트 내 단어들 간의 관계와 달리, 이미지 내 시각적 개념들 간의 관계는 시각-언어(V-L) 작업에 있어 중요하지만 포착하기 어렵습니다. 예를 들어, 이미지의 설명을 생성하기 위해 모델은 이미지 내 다양한 객체들 간의 복잡한 관계를 추론할 것으로 기대됩니다. 따라서, 많은 연구들은 이러한 관계와 객체의 속성을 모델링하기 위해 다양한 비전 인코더(vision encoder)를 고안합니다. 초기 작업들인 ViLBERT [Lu et al., 2019]와 LXMERT [Tan and Bansal, 2019]는 먼저 Faster RCNN [Ren et al., 2015]을 사용하여 이미지에서 객체 영역의 시퀀스를 감지한 다음 이를 관심 영역(Region-Of-Interest, ROI) 특징의 시퀀스로 인코딩합니다. 또한, 일부 VLPTMs(Visual-Language Pre-trained Models)은 바운딩 박스(bounding box)를 제거하고 이미지를 픽셀 수준 그리드 특징으로 인코딩합니다. 예를 들어, pixel-BERT [Huang et al., 2020]와 SOHO [Huang et al., 2021]는 Faster 을 버리고 ResNet을 선호하여 비전 인코더가 이미지를 전체로 볼 수 있게 하여, 중요한 영역을 놓칠 위험을 피합니다. 이러한 방법들 외에도, 많은 연구들이 ViT [Dosovitskiy et al., 2020]의 성공을 따라 이미지에서 비전 특징을 추출하기 위해 트랜스포머(transformer)를 사용하려고 합니다. 이 시나리오에서, VL-PTMs 내의 트랜스포머는 이미지 내 객체 관계를 모델링하는 목표를 가지고 있습니다. 이미지는 먼저 여러 개의 평평한 2D 패치로 나뉩니다. 그런 다음 이미지 패치의 임베딩이 시퀀스로 배열되어 원본 이미지를 표현합니다. ALBEF [Li et al., 2021a]와 SimVLM [Wang et al., 2021b]은 패치를 ViT 인코더에 입력하여 비전 특징을 추출하며, 이는 전체 트랜스포머 VL-PTM으로의 길을 제시합니다.
3 시각-언어 상호작용 모델링
이미지와 텍스트를 단일 모달 임베딩으로 인코딩한 후, 다음 단계는 시각과 언어 모달리티로부터 정보를 통합하는 인코더를 설계하는 것입니다. 예를 들어, 이미지에 대한 질문에 답하기 위해, 모델은 질문과 답변 양쪽에서 언어 정보를 결합한 다음, 짝을 이루는 이미지에서 해당 영역을 찾아내고, 마지막으로 언어적 의미를 시각적 단서와 맞추어야 합니다. 다른 모달리티로부터 정보를 집약하는 방식에 따라, 우리는 인코더를 융합 인코더(fusion encoder), 이중 인코더(dual encoder) 및 두 가지의 조합으로 분류합니다.
3.1 융합 인코더(Fusion Encoder)
퓨전 인코더(fusion encoder)는 텍스트 임베딩(text embeddings)과 이미지 특징(image features)을 입력으로 받아 V-L 상호작용을 모델링하기 위한 여러 퓨전 접근법을 설계합니다. 자기 주의(self-attention) 또는 교차 주의(cross-attention) 연산 후, 마지막 계층의 은닉 상태(hidden states)는 다양한 모달리티의 융합된 표현으로 취급됩니다. 크로스 모달 상호작용을 모델링하기 위한 퓨전 방식에는 주로 단일 스트림(single stream)과 이중 스트림(dual stream) 두 가지 유형이 있습니다.
단일 스트림 아키텍처(Single-stream Architecture). 단일 스트림 아키텍처는 두 모달리티 간의 잠재적인 상관관계와 정렬이 단순하다고 가정하며, 이는 단일 트랜스포머 인코더(transformer encoder)에 의해 학습될 수 있습니다. 따라서 텍스트 임베딩과 이미지 특징은 함께 연결되고, 위치와 모달리티를 나타내는 특별한 임베딩을 추가한 후, 트랜스포머 기반 인코더에 입력됩니다.
다양한 V-L 작업은 다른 입력 형식을 요구하지만(예: 이미지 캡셔닝(image captioning)의 경우 〈캡션, 이미지 , VQA의 경우 〈질문, 답변, 이미지 ), 단일 스트림 아키텍처는 트랜스포머 주의의 순서에 구애받지 않는 표현 방식 덕분에 이를 통합된 프레임워크에서 처리할 수 있습니다. VisualBERT [Li et al., 2019]과 V-L BERT [Su et al., 2019]는 세그먼트 임베딩(segment embedding)을 사용하여 다른 출처에서 온 입력 요소를 나타냅니다. 단순한 이미지-텍스트 쌍 대신, OSCAR [Li et al., 2020c]는 이미지에서 감지된 객체 태그(object tags)를 추가하고 이미지-텍스트 쌍을 단어, 태그, 이미지 삼중항으로 표현하여 퓨전 인코더가 다양한 모달리티를 더 잘 정렬할 수 있도록 돕습니다. 단일 스트림 아키텍처는 두 모달리티에 직접 자기 주의를 수행하기 때문에, 모달리티 내부의 상호작용을 간과할 수 있습니다. 따라서 일부 연구에서는 V-L 상호작용을 모델링하기 위해 이중 스트림 아키텍처를 사용할 것을 제안합니다
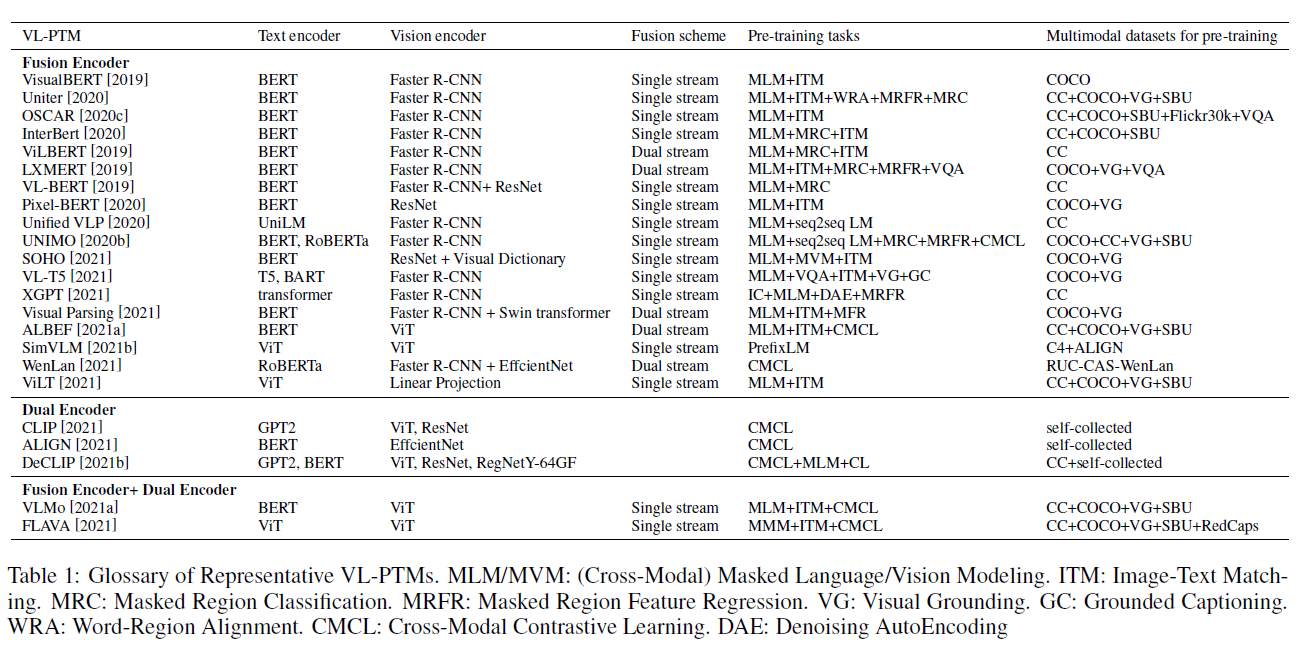
표 1: 대표적인 VL-PTM(Visual-Language Pre-Training Models) 용어집. MLM/MVM: (교차 모달) 마스크된 언어/비전 모델링(Masked Language/Vision Modeling). ITM: 이미지-텍스트 매칭(Image-Text Matching). MRC: 마스크된 영역 분류(Masked Region Classification). MRFR: 마스크된 영역 특징 회귀(Masked Region Feature Regression). VG: 시각적 연결(Visual Grounding). GC: 연결된 캡셔닝(Grounded Captioning). WRA: 단어-영역 정렬(Word-Region Alignment). CMCL: 교차 모달 대조 학습(Cross-Modal Contrastive Learning). DAE: 노이즈 제거 오토인코딩(Denoising AutoEncoding)
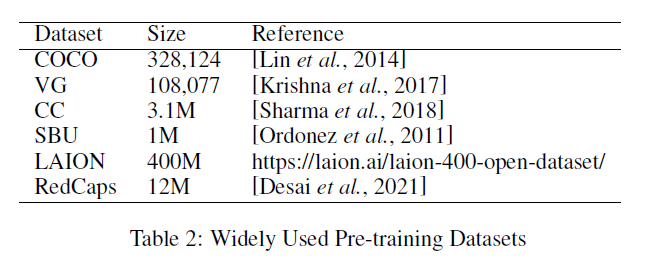
표 2: 널리 사용되는 사전 학습 데이터셋(Pre-training Datasets)
이중 스트림 구조(Dual-stream Architecture). 단일 스트림 구조(single-stream architectures)에서의 자기 주의(self-attention) 연산과 달리, 이중 스트림 구조는 V-L(비전-언어) 상호작용을 모델링하기 위해 교차 주의(cross-attention) 메커니즘을 채택합니다. 여기서 쿼리 벡터(query vectors)는 한 모달리티에서 오고, 키(key)와 값(value) 벡터는 다른 모달리티에서 옵니다. 교차 주의 층(crossattention layer)은 보통 두 개의 단방향 교차 주의 부층(unidirectional crossattention sub-layers)을 포함합니다: 하나는 언어에서 비전으로, 다른 하나는 비전에서 언어로입니다. 이들은 두 모달리티 간의 정보 교환과 의미 정렬을 담당합니다.
이중 스트림 구조는 내부 모달 상호작용(intra-modal interaction)과 교차 모달 상호작용(cross-modal interaction)을 분리해야 더 나은 다중 모달 표현(multimodal representations)을 얻을 수 있다고 가정합니다. ViLBERT [Lu et al., 2019]는 교차 모달 모듈 이후에 내부 모달 상호작용을 더 모델링하기 위해 두 개의 트랜스포머(transformers)를 사용합니다. LXMERT [Tan and Bansal, 2019]는 추가적인 트랜스포머를 사용하지 않고 교차 주의 부층 뒤에 자기 주의 부층(self-attention sub-layer)을 추가하여 내부 연결을 더 구축합니다. 교차 모달 부층에서는 두 스트림 간에 주의 모듈(attention module)의 매개변수가 공유됩니다. 이 경우, 모델은 이미지와 텍스트 임베딩을 문맥화하는 단일 함수를 학습합니다. ALBEF [Li et al., 2021a]는 이미지와 텍스트를 위해 교차 주의 이전에 두 개의 별도의 트랜스포머를 사용하여 내부 모달 상호작용과 교차 모달 상호작용을 더 잘 분리합니다. 이러한 유형의 구조는 입력을 더 포괄적으로 인코딩하는 데 도움이 됩니다. 그러나 추가적인 특징 인코더(feature encoder)는 매개변수 효율성을 떨어뜨립니다.
3.2 이중 인코더(Dual Encoder)
퓨전 인코더(fusion encoder)는 다양한 수준에서 교차 모달 상호작용(cross-modal interaction)을 모델링할 수 있으며 많은 V-L(시각-언어) 작업에서 최신 기술(state-of-the-art) 결과를 달성하지만, V-L 상호작용을 모델링하기 위해 무거운 트랜스포머 네트워크(transformer network)에 의존합니다. 이미지-텍스트 검색(Image-Text Retrieval)과 같은 교차 모달 매칭 작업을 수행할 때, 퓨전 인코더는 모든 가능한 이미지 텍스트 쌍을 함께 인코딩해야 하므로 추론 속도가 상당히 느립니다.
반면에, 듀얼 인코더(dual encoder)는 두 가지 모달리티를 별도로 인코딩하기 위해 두 개의 단일 모달 인코더(single-modal encoders)를 사용합니다. 그런 다음, 얕은 주의 층(shallow attention layer) [Lee et al., 2018]이나 점곱(dot product) [Radford et al., 2021; Jia et al., ]과 같은 간단한 방법을 채택하여 이미지 임베딩과 텍스트 임베딩을 동일한 의미 공간으로 투영하여 V-L 유사도 점수를 계산합니다. 트랜스포머의 복잡한 교차 주의(cross-attention) 없이, 듀얼 인코더에서의 VL 상호작용 모델링 전략은 훨씬 더 효율적입니다. 따라서 이미지와 텍스트의 특징 벡터는 사전에 계산되어 저장될 수 있으며, 이는 검색 작업에 있어 퓨전 인코더보다 더 효과적입니다. CLIP [Radford et al., 2021]과 같은 듀얼 인코더 모델들이 이미지-텍스트 검색 작업에서 놀라운 성능을 보여주었지만, NLVR [Suhr et al., 2018]와 같은 어려운 V-L 이해 작업에서는 실패합니다. 이는 두 모달리티 간의 상호작용이 얕기 때문입니다.
3.3 퓨전 인코더와 듀얼 인코더의 결합
퓨전 인코더가 V-L 이해 작업에서 더 나은 성능을 보이고 듀얼 인코더가 검색 작업에서 더 나은 성능을 보인다는 관찰에 기반하여, 두 가지 유형의 아키텍처의 장점을 결합하는 것은 자연스러운 일입니다. FLAVA [Singh et al., 2021]는 처음으로 듀얼 인코더를 사용하여 단일 모달 표현을 얻습니다. 그런 다음 단일 모달 임베딩을 퓨전 인코더로 보내 교차 모달 표현을 얻습니다. 모델 디자인 외에도, FLAVA는 단일 모달 표현의 품질을 향상시키기 위해 여러 단일 모달 사전 훈련 작업을 수행합니다. VLMo [Wang et al., 2021 a]는 Mixtureof-Modality-Expert (MoME)를 도입하고 듀얼 인코더와 퓨전 인코더를 단일 프레임워크로 통합합니다. 단계별로 이미지, 텍스트, 이미지-텍스트 쌍에 대한 사전 훈련을 거친 후, VLMo는 V-L 이해 작업에 미세 조정(fine-tuned)될 수 있을 뿐만 아니라 효율적인 이미지-텍스트 검색에도 적용될 수 있습니다.
4 교차 모달 사전 훈련 작업
섹션 1에 따르면, 입력 이미지와 텍스트가 벡터로 인코딩되고 완전히 상호 작용한 후, 다음 단계는 VL-PTM을 위한 사전 훈련 작업을 설계하는 것입니다. 설계된 사전 훈련 작업은 VL-PTM이 데이터로부터 배울 수 있는 것에 큰 영향을 미칩니다. 이 섹션에서는 널리 사용되는 사전 훈련 작업을 소개합니다.
4.1 교차 모달 마스크 언어 모델링(MLM)
크로스모달 MLM은 BERT 모델의 MLM과 유사합니다. 크로스모달 MLM에서는 VL-PTM(시각-언어 사전 훈련 모델)이 마스킹된 토큰을 예측할 때 마스킹되지 않은 토큰뿐만 아니라 시각적 특징도 고려합니다. 시각 모달리티에 대한 의존성은 크로스모달 MLM을 NLP의 MLM과 구별짓습니다. 이 작업은 이미지와 텍스트 사이의 관계를 고려하여 시각과 텍스트를 정렬하는 데 도움이 되기 때문에 VL-PTM 사전 훈련에 매우 효과적임이 입증되었습니다. 공식적으로, 목표는 다음과 같이 정의될 수 있습니다:
여기서 은 각각 마스킹된 토큰과 마스킹되지 않은 토큰을 나타내며, 는 데이터셋 에서 샘플링된 텍스트 와 이미지 를 나타냅니다.
크로스모달 MLM과 NLP의 MLM 사이의 차이점으로 인해, 크로스모달 MLM에는 효과적인 마스킹 전략이 필요합니다. 방법이 너무 단순하면 모델이 주변 토큰만을 기반으로 마스킹된 토큰을 예측할 수 있습니다. 이미지에 의존하는 일부 토큰을 마스킹함으로써 VL-PTM은 이미지 특징을 고려하게 되고, 따라서 토큰과 이미지 속 해당 객체를 정렬하게 됩니다. ViLT [Kim et al., 2021]는 Whole Word Masking 전략을 사용하여 모델이 단어의 공존만으로 토큰을 예측하는 것을 방지합니다; InterBERT [Lin et al., 2020]는 이 사전 훈련 작업을 더 어렵게 만들기 위해 여러 연속된 텍스트 세그먼트를 마스킹하고, 하류 작업에서의 성능을 더욱 향상시킵니다.
4.2 크로스모달 마스크 영역 예측(MRP)
크로스모달 MLM(cross-modal MLM)과 유사하게, 크로스모달 MRP(cross-modal MRP)는 일부 RoI(Region of Interest) 특징을 0으로 마스킹하고 다른 이미지 특징을 바탕으로 예측합니다. 모델은 다른 마스킹되지 않은 영역으로부터 추론함으로써 객체 간의 관계를 학습하고, 텍스트로부터 추론함으로써 V-L(Visual-Linguistic) 정렬을 학습합니다. 두 가지 종류의 학습 목표가 있습니다: 마스킹된 영역 분류(Masked Region Classification, MRC)와 마스킹된 영역 특징 회귀(Masked Region Feature Regression, MRFR).
마스킹된 영역 분류(MRC). MRC는 각 마스킹된 영역의 의미론적 클래스를 예측하는 것을 학습합니다. 이 작업은 VL-PTM(Visual-Linguistic Pre-trained Models)이 언어 측면에서 이미지의 고차원 의미를 학습하는 것이지 원시 픽셀을 학습하지 않는다는 관찰에 의해 동기를 얻었습니다. 영역 클래스를 예측하기 위해, VL-PTM의 마스킹된 영역 에 대한 은닉 상태 를 완전연결층(Fully-Connected, FC)에 입력한 후, softmax 함수를 거쳐 객체 클래스에 대한 예측 분포를 형성합니다. 최종 목표는 예측 분포와 감지된 객체 카테고리 간의 교차 엔트로피(CE) 손실을 최소화하는 것으로, 공식적으로 다음과 같이 정의됩니다:
여기서 은 마스킹된 영역의 수이며, 는 마스킹된 영역의 실제 레이블을 나타냅니다. 예를 들어 객체 감지 출력이나 (미리 정의된) 시각적 토큰들입니다.
VL-PTM의 크로스모달 주의(cross-modal attention)를 통해, 은닉 상태 는 시각과 언어 모두의 정보를 포함하고 있어, 텍스트로부터 시각적 의미론적 클래스를 예측할 수 있게 합니다. 실제 레이블 에 대해서는, 객체 감지기에서 감지된 객체 태그(가장 높은 신뢰 점수를 가진)를 실제 레이블로 간주하는 것이 직관적인 방법입니다[Tan and Bansal, 2019; Su et al., 2019]. 그러나 이러한 레이블은 가짜이며, 사전 훈련된 객체 감지기의 품질에 크게 의존하기 때문에, 이 작업의 몇 가지 변형이 있습니다. ViLBERT [Lu et al., 2019]와 UNITER [Chen et al., 2020]는 감지기의 원시 출력을 소프트 레이블로 간주할 것을 제안합니다. 이는 객체 클래스의 분포입니다. 이 시나리오에서 목표는 두 분포 간의 KL-발산(KL-divergence)이 됩니다. SOHO [Huang et al., 2021]는 먼저 CNN 기반 그리드 특징을 시각적 토큰으로 매핑한 다음, 주변 토큰을 바탕으로 마스킹된 시각적 토큰을 예측합니다.
마스크된 영역 특징 회귀(Masked Region Feature Regression, MRFR). MRFR은 마스크된 영역 특징 를 해당 원본 영역 특징 에 회귀시키는 것을 학습하며, 이는 다음과 같이 쓸 수 있습니다:
이 공식에서, 영역 특징 는 마스크되지 않은 이미지를 기반으로 계산되며, 은 마스크된 영역의 수를 나타냅니다. MRFR은 모델이 의미론적 클래스(semantic class) 대신 고차원 벡터를 재구성하도록 요구합니다. 이미지가 빠른 R-CNN(faster R-CNN)에 의해 영역 특징의 시퀀스로 표현될 때, 무작위 마스킹(random masking)과 같은 간단한 마스킹 전략은 만족스러운 성능을 낼 수 있습니다 [Tan and Bansal, 2019; Chen et al., 2020; Li et al., 2020b]. 그러나 이미지가 그리드 특징(grid features)이나 패치 특징(patch features)으로 변환될 때 무작위 마스킹은 효과적이지 않을 수 있습니다. 왜냐하면 모델이 이웃 특징을 예측 특징으로 직접 복제하기 때문입니다. 시각적 파싱(Visual parsing) [Xue et al., 2021]은 이미지를 패치 특징으로 표현하고 높은 주의력 가중치를 가진 시각적 토큰(visual tokens, 영역 특징)이 유사한 의미를 가진다고 가정합니다. 이는 먼저 시각적 토큰을 피벗 토큰으로 무작위로 마스킹하고, 상위 주의력 가중치를 가진 개의 토큰을 계속해서 마스킹합니다. SOHO[Huang et al., 2021]는 시각 사전(vision dictionary)을 사전 훈련하고 정보 유출을 방지하기 위해 동일한 시각적 인덱스를 공유하는 모든 특징을 마스킹합니다.
4.3 이미지-텍스트 매칭(Image-Text Matching, ITM)
교차 모달 MLM과 MRP는 VL-PTM들이 이미지와 텍스트 사이의 세밀한 상관관계를 학습하도록 돕는 반면, ITM은 VL-PTM에게 이미지와 텍스트를 거친 수준에서 정렬할 수 있는 능력을 부여합니다. ITM은 NLP에서의 다음 문장 예측(Next Sentence Prediction, NSP) 작업과 유사하며, 모델이 이미지와 텍스트가 매칭되는지를 판단하도록 요구합니다. 이미지-텍스트 쌍이 주어지면, 점수 함수 는 이미지와 텍스트 사이의 정렬 확률을 측정합니다. 목적 함수는:
여기서 는 와 가 서로 매치되었는지 여부를 나타내며, 와 는 각각 와 의 표현(representation)입니다.
이 작업의 핵심은 이미지-텍스트 쌍을 단일 벡터로 어떻게 표현하는지에 있어서, 점수 함수 가 확률을 출력할 수 있도록 하는 것입니다. UNITER [Chen et al., 2020], Unicoder [Li et al., 2020a] 및 SOHO [Huang et al., 2021]는 단어 시퀀스 와 객체 시퀀스 를 연결하고 "[CLS]" 토큰의 최종 숨겨진 상태를 융합된 표현으로 사용합니다. 이를 완전 연결 계층(fully-connected layer)에 입력하여 차원을 줄여 정렬 확률을 예측할 수 있습니다. 반면, ViLBERT [Lu et al., 2019]는 "[IMG]"와 "[CLS]" 토큰의 표현을 각각 이미지와 텍스트를 나타내는 데 사용하며, 융합된 표현은 두 토큰 간의 요소별 곱(element-wise product)으로 계산됩니다.
4.4 크로스-모달 대조 학습(Cross-Modal Contrastive Learning, CMCL)
CMCL은 매치된 이미지-텍스트 쌍의 임베딩을 가깝게 하고 매치되지 않은 쌍을 멀어지게 함으로써 동일한 의미 공간에서 범용적인 시각 및 언어 표현을 학습하는 것을 목표로 합니다. 이미지-텍스트 대조 손실은 다음과 같이 정의될 수 있습니다:
여기서 는 의 부정적인 샘플 집합에 속하고, , 및 는 각각 및 의 표현이며, 는 주어진 이미지-텍스트 쌍이 얼마나 유사한지를 판단하는 점수 함수입니다. CMCL에서 대조 손실(contrastive loss)이 대칭적이라는 점을 주목할 가치가 있으며, 텍스트에서 이미지로의 대조 손실도 유사하게 구성됩니다.
CLIP [Radford et al., 2021]과 ALIGN [Jia et al., 2021]은 대규모 이미지-텍스트 쌍을 활용하여 전이 가능한 시각적 표현을 학습하고 이미지 분류 작업에 놀라운 제로샷 전이(zero-shot transfer)를 보여줍니다. ALBEF [Li et al., 2021a]은 대규모의 잡음이 많은 이미지-텍스트 쌍에서 대조 학습을 용이하게 하기 위해 모멘텀 증류(momentum distillation)를 채택할 것을 제안합니다. WenLan [Huo et al., 2021]은 MoCo [He et al., 2020]를 사용하고 부정적인 샘플을 저장하기 위한 큐(queue)를 유지하는데, 이는 대조 학습에 효과적임이 입증되었습니다. UNIMO [ et al., 2020b]는 대조 학습 중에 대량의 단일 모달 데이터(unimodal data)를 통합하여 시각과 언어가 서로를 강화할 수 있도록 합니다. 이는 멀티모달(multimodal) 및 단일 모달(unimodal) 하류 작업(downstream tasks) 모두에서 이전 작업들을 능가하는 성능을 보여줍니다. [Yang et al., 2022]는 CMCL이 동일한 모달리티에서 비슷한 입력이 가까이 있도록 보장하지 않는다고 주장하므로, 표현 학습에 도움이 되는 모달 내 대조 학습(intra-modal contrastive learning)을 도입합니다.
5 시각-언어 하류 작업에 VL-PTMs 적용하기
사전 훈련(pre-training) 작업은 VL-PTMs(시각-언어 사전 훈련 모델)이 일반적인 시각적 및 언어적 특징을 학습하도록 도와주며, 이는 다양한 하류(downstream) 작업에 적용될 수 있습니다. 이 섹션에서는 몇 가지 일반적인 시각-언어 통합 작업과 VL-PTMs가 이에 어떻게 적응하는지 소개합니다. 기본적으로, 우리는 이러한 하류 작업을 크로스모달 매칭(cross-modal matching), 크로스모달 추론(cross-modal reasoning) 및 시각과 언어 생성(vision and language generation)으로 분류했습니다.
5.1 크로스모달 매칭
크로스모달 매칭은 VL-PTMs가 서로 다른 모달리티 간의 상호 연관성을 학습하도록 요구합니다. 우리는 두 가지 일반적으로 사용되는 크로스모달 매칭 작업을 소개합니다: 이미지 텍스트 검색(image text retrieval)과 시각적 참조 표현(visual referring expression).
이미지 텍스트 검색(ITR). ITR은 전형적인 크로스모달 매칭 작업입니다. 이 작업은 주어진 문장과 가장 일치하는 이미지를 검색하고 그 반대의 경우도 마찬가지로 요구합니다. 융합 인코더(fusion-encoder) 구조를 사용하는 초기 VLPTMs는 융합된 벡터 표현을 얻은 다음 유사도 점수로 투영합니다 [Lu et al., 2019; Li et al., 2019; Li et al., 2020c]. CLIP [Radford et al., 2021]과 ALBEF [Li et al., 2021a]와 같은 듀얼 인코더(dual-encoder) 구조는 이미지와 텍스트의 임베딩을 검색 전에 미리 계산하고 저장할 수 있기 때문에 ITR에 더 효율적입니다.
시각적 참조 표현(VRE). VRE는 NLP에서 참조 표현 작업을 확장한 것입니다. 목표는 특정 텍스트 설명에 해당하는 이미지 내의 영역을 지역화하는 것입니다. 대부분의 VL-PTMs(예: [Lu et al., 2019])은 추출된 영역 제안의 최종 표현을 입력으로 받아 선형 투영을 학습하여 매칭 점수를 예측하는데, 이는 미세 조정(fine-tuning) 중 ITR과 동일한 전략입니다.
5.2 크로스모달 추론
크로스모달 추론은 VL-PTMs가 시각 정보에 기반한 언어 추론을 수행하도록 요구합니다. 어떤 모달리티도 무시하면 성능이 떨어집니다. 여기서 우리는 두 가지 일반적으로 사용되는 크로스모달 추론 작업을 소개합니다.
시각적 질문 응답(VQA). VQA는 널리 사용되는 크로스모달 추론 작업입니다. 텍스트 기반 QA와 달리, VQA는 이미지에 대한 질문에 답하는 것을 요구합니다. 대부분의 연구자들은 VQA를 분류 작업으로 간주하고 모델이 답변 풀에서 올바른 답을 선택하도록 요구합니다. 융합 인코더 구조를 가진 VL-PTMs는 일반적으로 최종 크로스모달 표현(보통 입력 [CLS] 토큰에 해당)을 답변 레이블의 분포로 매핑합니다. 그러나 듀얼 인코더 구조를 가진 VL-PTMs는 두 모달리티 간의 상호작용이 크로스모달 추론을 수행하기에는 너무 얕기 때문에 VQA 작업에 그다지 효과적이지 않습니다. 또한 VQA를 생성 작업으로 모델링하는 몇몇 연구들도 있으며 [Cho et al., 2021; Wang et al., 2021b], 이는 실제 세계의 개방형 시나리오에 더 잘 일반화할 수 있습니다.
시각적 추론을 위한 자연어(NLVR). NLVR은 이미지 쌍과 텍스트 문장을 입력으로 제공하고, 모델이 그 문장이 이미지 쌍에 대해 참인지를 결정해야 하므로, 이진 분류 작업으로 간주될 수 있습니다. 대부분의 시각-언어 사전 훈련 모델(VL-PTMs)은 주어진 두 이미지-텍스트 쌍을 별도로 인코딩한 다음, 두 임베딩의 연결을 통해 분류기를 훈련시켜 예측을 합니다 [Tan and Bansal, 2019; Chen et al., 2020].
시각적 상식 추론(VCR). VCR은 VQA 작업의 또 다른 종류로 간주됩니다. VCR과 VQA의 주된 차이점은 VCR의 질문이 시각적 상식에 더 많은 주의를 기울인다는 것입니다. VQA와 달리, VCR 작업은 두 개의 다중 선택 부작업으로 분해될 수 있습니다: 질문 응답 과 답변 정당화 . 대부분의 VL-PTMs는 이 두 부작업을 해결하기 위해 VQA에서와 같은 접근 방식을 사용합니다. 질문 응답 부작업의 경우, 절차는 VQA와 동일합니다. 답변 정당화 부작업의 경우, 질문과 답변의 연결은 새로운 질문으로 취급되고, 근거는 옵션이 됩니다. 각 가능한 옵션에 대한 점수를 예측하기 위해 선형 층이 훈련됩니다 [Lu et al., 2019].
5.3 시각과 언어 생성
원본 모달과 대상 모달에 기반하여, 생성 작업은 텍스트-이미지 생성과 이미지-텍스트 생성(다중 모달 텍스트 생성)으로 나눌 수 있습니다.
텍스트-이미지 생성. 텍스트-이미지 생성은 서술적 텍스트로부터 해당 이미지를 생성하는 작업입니다. X-LXMERT [Cho et al., 2020]는 먼저 연속적인 시각적 표현을 이산적인 클러스터 중심으로 변환한 다음, 모델에게 가려진 영역의 클러스터 ID를 예측하도록 요청합니다. DALL-E [Ramesh et al., 2021]는 이미지를 토큰화하기 위한 코드북을 훈련시키고 텍스트-이미지 생성 작업을 자기회귀 생성 작업으로 정의합니다. 이는 제로샷 설정에서 MS-COCO [Lin et al., 2014]에 대한 새로운 최고 성능을 달성했습니다.
다중모달 텍스트 생성. 다중모달 텍스트 생성은 조건에 텍스트뿐만 아니라 이미지도 포함하는 특별한 유형의 조건부 텍스트 생성으로 간주될 수 있습니다. 보통 생성 과정에는 디코더가 필요합니다. 이미지 캡셔닝은 모델이 이미지의 설명을 생성해야 하는 전형적인 이미지-텍스트 생성 작업입니다. XGPT [Xia et al., 2021]과 VL-T5 [Cho et al., 2021]는 먼저 이미지를 인코딩한 다음 디코더를 사용하여 자동회귀적으로 캡션을 생성합니다. 다중모달 기계 번역은 이미지를 도입하여 번역 품질을 향상시키는 또 다른 생성 작업입니다. VL-T5 [Cho et al., 2021]는 이미지 캡셔닝과 동일한 전략을 사용하여 이 작업에 대처합니다.
VL-PTMs(Vision-Language Pre-trained Models) 구조와 하류 작업 간의 연결에 대해, 교차 모달 추론 작업에서는 상호작용을 모델링하는 강력한 능력 때문에 이중 인코더보다 융합 인코더가 더 적합합니다. 이중 인코더는 융합 인코더와 비슷한 성능을 유지하면서 더 효율적이기 때문에 교차 모달 검색 작업에 더 적합합니다.
6 결론 및 향후 방향
이 논문에서는 VL-PTMs에 대한 개요를 제시합니다. 우리는 일반적으로 사용되는 구조를 검토하고 그 장단점을 논의합니다. 또한 VL-PTM을 사전 훈련하고 하류 작업에 적용하는 몇 가지 주류 접근법을 소개합니다. VL-PTMs는 전통적인 방법에 비해 V-L(비전-언어) 작업에서 상당한 진전을 이루었지만, 향후 연구 방향이 될 수 있는 몇 가지 도전 과제가 여전히 있습니다.
통합 모델 구조. 트랜스포머 기반 모델은 NLP(자연어 처리), CV(컴퓨터 비전), 그리고 다중모달 작업에서 놀라운 성능을 보여주었습니다. 다양한 영역에서 트랜스포머 기반 모델의 성공은 단일 트랜스포머 모델을 사용하여 다른 모달리티의 표현을 학습하고 다양한 영역의 작업을 처리하는 일반 에이전트를 구축할 가능성을 시사합니다. UNIMO [Li et al., 2020b]와 FLAVA [Singh et al., 2021]는 이 방향으로 몇 가지 영감을 주는 시도를 했지만, 일부 작업에서는 작업 특정 기준보다 훨씬 나쁜 성능을 보입니다. Data2vec [Baevski et al., 2022]은 자기지도 학습을 채택하여 비전, 음성, 언어를 통합합니다. 이 모델은 몇 가지 작업에서 우세한 방법들과 경쟁력 있는 결과를 달성하여 강력한 통합 모델로 가는 길을 열었습니다.
모델 압축 및 가속화. 다양한 분야에서 VL-PTM(시각-언어 사전 훈련 모델)이 큰 성공을 거두었지만, 이렇게 거대한 모델을 실제 상황에 배치하기는 어렵습니다. 이로 인해 VL-PTM의 압축 및 가속화 방향이 생겨났습니다. 지식 증류(knowledge distillation)는 VL-PTM을 압축하는 데 사용되었습니다 [Fang et al., 2021], 하지만 양자화(quantization)나 가지치기(pruning)와 같은 전통적인 압축 방법들은 VL-PTM에 대해 아직 탐구되지 않았습니다. 모델 가속화 측면에서, Li et al. [2021b]은 데이터 효율적인 V-L 사전 훈련 패러다임을 구축했습니다. 이 모든 성과에도 불구하고, VL-PTM의 추론 속도를 향상시키는 데 집중하는 노력은 많지 않습니다.
고급 사전 훈련 방법. 현재의 사전 훈련 방법이 상당히 효과적인 것으로 보이지만, 고급 사전 훈련 방법의 잠재력은 아직 탐구되지 않았습니다. 적대적 샘플(adversarial samples)을 사용하여 사전 훈련을 강화하는 것이 효과적임이 입증되었으며 [Gan et al., 2020], 이는 VL-PTM이 과적합(overfitting) 문제를 극복하는 데 도움을 줍니다. 단계별 사전 훈련(stage-wise pre-training) [Wang et al., 2021a]이 단일 모달(single-modal) 표현을 개선하기 위해 제안되었습니다. 이러한 진전에도 불구하고, 사전 훈련 방법의 잠재력은 완전히 개발되지 않았으며, 이는 추가적인 연구가 필요한 가치가 있습니다.
VL-PTM의 한계 도달. 현재, NLP에서 대규모 PLM(사전 훈련 모델)의 성공으로 많은 연구자들이 더 깊은 모델을 구축하거나 V-L 사전 훈련을 위해 더 큰 데이터셋을 사용하려고 시도하고 있습니다. ALIGN [Jia et al., 2021]은 6억 7540만 개의 매개변수를 가지고 있으며, 사전 훈련을 위해 18억 개의 이미지-텍스트 쌍으로 구성된 거대한 데이터셋을 수집했습니다. 거의 모든 하류 작업(downstream tasks)에서 최신 기술(state-of-the-art) 결과를 달성했습니다. Wenlan [Fei et al., 2021]은 데이터셋을 6억 5000만 이미지-텍스트 쌍으로 확장하고, 시각-언어 이해 및 생성 작업 모두에서 놀라운 성능을 보여주었습니다. 미래에는 VL-PTM이 더 높은 인식 수준에 도달하기 위해 더 많은 고품질 데이터와 더 많은 매개변수가 필요할 것입니다.
[^0]: 동등한 기여.
${ }^{*}$ 교신 저자.