논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
CPT: 사전 훈련된 시각-언어 모델을 위한 컬러풀 프롬프트 튜닝
Yuan Yao , Ao Zhang , Zhengyan Zhang , Zhiyuan Liu , Tat-Seng Chua , Maosong Sun
컴퓨터 과학 및 기술 학과
인공지능 연구소, 청화대학교, 베이징, 중국
베이징 국가정보과학기술연구센터, 중국
Sea-NExT 공동 연구실, 싱가포르
컴퓨팅 학교, 싱가포르 국립대학교, 싱가포르
yuan-yaol8@mails.tsinghua.edu.cn, aozhang@u.nus.edu
초록
사전 훈련된 시각-언어 모델(Pre-Trained Vision-Language Models, VL-PTMs)은 자연어를 이미지 데이터에 결합하는 능력을 보여주며, 다양한 크로스모달(cross-modal) 작업을 용이하게 합니다. 그러나 모델의 사전 훈련과 미세 조정(fine-tuning)의 목표 형태 사이에 상당한 차이가 있음을 발견했으며, 이로 인해 다운스트림 작업(downstream tasks)에 대한 VL-PTMs의 시각적 결합 능력을 자극하기 위해 대량의 레이블이 붙은 데이터가 필요합니다. 이 도전을 해결하기 위해, 우리는 크로스모달 프롬프트 튜닝(Cross-modal Prompt Tuning, CPT, 또는 컬러풀 프롬프트 튜닝(Colorful Prompt Tuning))이라는 새로운 패러다임을 제시합니다. CPT는 이미지와 텍스트에서 색 기반 공동 참조 표시자(color-based co-referential markers)를 사용하여 시각적 결합을 빈칸 채우기 문제로 재구성함으로써, 이러한 차이를 최대한 줄입니다. 이 방식으로 CPT는 VL-PTMs의 강력한 소수샷(few-shot) 및 심지어 제로샷(zero-shot) 시각적 결합 능력을 가능하게 합니다. 종합적인 실험 결과는 프롬프트 튜닝된 VL-PTMs가 미세 조정된 대응물보다 큰 폭으로 우수한 성능을 보여준다는 것을 보여줍니다(예를 들어, RefCOCO 평가에서 한 번의 샷으로 평균 의 절대 정확도 향상과 의 상대 표준 편차 감소). 이 논문의 데이터와 코드는 https://github.com/thunlp/CPT 에서 공개적으로 이용할 수 있습니다.
1 서론
자연어를 세밀한 이미지 영역에 연결하는 것은 로봇 내비게이션(로봇 탐색)(Tellex et al., 2011; Anderson et al., 2018b), 시각적 질문 응답(Visual Question Answering)(Antol et al., 2015; Anderson et al., 2018a), 시각적 대화(Visual Dialogue)(Das et al., 2017), 그리고 시각적 상식 추론(Visual Commonsense Reasoning)(Zellers et al., 2019)과 같은 다양한 시각-언어 작업에 필수적입니다. 최근에는 사전 훈련된 시각-언어 모델(VL-PTMs)이 시각적 연결(visual grounding) 분야에서 유망한 능력을 보여주고 있습니다. 일반적으로, 범용적인 상호 모달 표현(cross-modal representations)이 대규모 이미지-캡션 데이터에서 자기 감독(self-supervised) 방식으로 먼저 사전 훈련되고, 그 다음에 하류 작업(downstream tasks)에 적응하도록 미세 조정(fine-tuned)됩니다(Lu et al., 2019; Su et al., 2019; Li et al., 2020, Radford et al., 2021). 이러한 VL-PTMs의 사전 훈련-그리고-미세 조정 패러다임은 많은 상호 모달 작업의 최신 기술을 크게 발전시켰습니다.
성공에도 불구하고, VL-PTMs의 사전 훈련과 미세 조정 목표 형태 사이에 상당한 격차가 존재한다는 점을 우리는 지적합니다. 그림 1에서 보여지듯이, 사전 훈련 중에 대부분의 VL-PTMs는 마스크된 언어 모델링(masked language modeling) 목표에 기반하여 최적화되며, 상호 모달 컨텍스트에서 마스크된 토큰을 복구하려고 시도합니다. 그러나 미세 조정 중에는 하류 작업이 일반적으로 마스크되지 않은 토큰 표현을 의미적 라벨로 분류하는 작업으로 수행되며, 여기서 작업 특정 매개변수가 일반적으로 도입됩니다. 이 격차는 VL-PTMs가 하류 작업에 효과적으로 적응하는 것을 방해합니다. 결과적으로, 하류 작업을 위한 VL-PTMs의 시각적 연결 능력을 자극하기 위해 일반적으로 많은 양의 라벨이 붙은 데이터가 필요합니다.
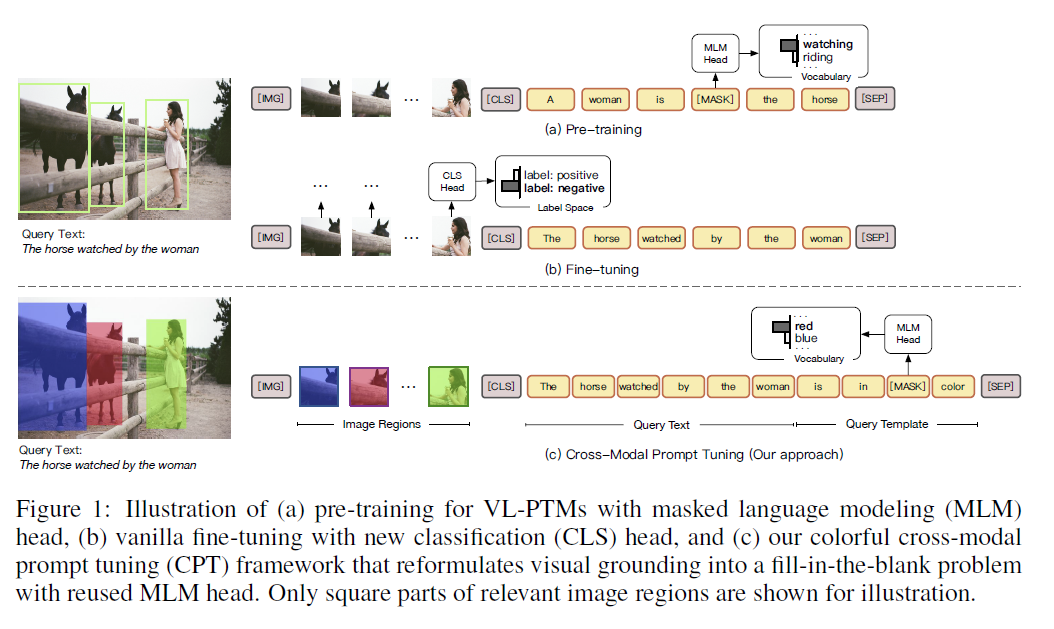
그림 1: (a) 마스크된 언어 모델링(Masked Language Modeling, MLM) 헤드를 사용한 VL-PTMs의 사전 훈련, (b) 새로운 분류(Classification, CLS) 헤드를 사용한 바닐라 미세 조정, 그리고 (c) 우리의 다채로운 상호 모달 프롬프트 튜닝(Colorful Cross-Modal Prompt Tuning, CPT) 프레임워크를 보여주는 그림으로, 시각적 연결을 재사용된 MLM 헤드를 사용한 빈칸 채우기 문제로 재구성합니다. 설명을 위해 관련 이미지 영역의 정사각형 부분만 보여집니다.
이 연구에서는 자연어 처리(natural language processing) 분야에서 사전 훈련된 언어 모델(pre-trained language models)의 최근 진보에 영감을 받아(Brown et al., 2020, Schick & Schütze, 2021a, Liu et al., 2021), 시각-언어 사전 훈련 모델(VLPTMs)을 조정하기 위한 새로운 패러다임인 Cross-modal Prompt Tuning(CPT, 또는 Colorful Prompt Tuning)을 제시합니다. 핵심 통찰은 이미지와 텍스트 양쪽에 색 기반의 공참조 표시자를 추가함으로써, 시각적 기반을 빈칸 채우기 문제로 재구성하여 사전 훈련과 미세 조정 사이의 격차를 최대한 완화할 수 있다는 것입니다. 그림 1에서 보여주듯이, 이미지 데이터에서 자연어 표현을 기반으로 하기 위해, CPT는 두 가지 구성 요소로 이루어집니다: (1) 색깔 블록이나 분할 마스크로 이미지 영역을 고유하게 표시하는 시각적 부 프롬프트(visual sub-prompt), 그리고 (2) 쿼리 텍스트를 색 기반의 쿼리 템플릿에 넣는 텍스트 부 프롬프트(textual sub-prompt). 그런 다음, 쿼리 템플릿에서 마스크된 토큰을 복구하여 해당 색 텍스트를 복원함으로써 목표 이미지 영역에 명시적으로 기반을 둘 수 있습니다. 또한, CPT를 위한 고품질의 크로스-모달 프롬프트 구성(즉, 색의 시각적 외관과 텍스트)을 찾기 위한 원칙적인 방법을 제시합니다.
사전 훈련에서의 격차를 완화함으로써, CPT는 VL-PTMs의 강력한 소수샷(few-shot) 및 심지어 제로샷(zero-shot) 시각적 기반 능력을 가능하게 합니다. 실험 결과에 따르면, 프롬프트 조정된 VL-PTMs는 미세 조정된 대응물보다 큰 차이로 우수한 성능을 보여줍니다. 예를 들어, 색깔 블록을 시각적 부 프롬프트로 사용할 때, CPT는 RefCOCO 평가에서 한 번의 샷으로 평균 의 절대 정확도 향상과 의 상대 표준 편차 감소를 달성합니다. 같은 설정에서, 색깔 분할 마스크를 시각적 부 프롬프트로 사용할 때, CPT는 바닐라(vanilla) 미세 조정 방법보다 의 절대 정확도 향상과 의 상대 표준 편차 감소를 더욱 달성할 수 있습니다. 시각적 기반과 같은 객체 위치 출력 작업뿐만 아니라, CPT는 시각적 관계 탐지와 같은 위치 입력 작업에 대해서도 강력한 제로- 및 소수샷 성능을 달성하기 위해 적용될 수 있음을 보여줍니다.
우리의 기여는 세 가지로 요약됩니다: (1) VL-PTMs를 위한 새로운 크로스-모달 프롬프트 조정 패러다임을 제시합니다. 우리가 알기로, 이것은 VL-PTMs를 위한 크로스-모달 프롬프트 조정과 객체 유형에 독립적인 제로- 및 소수샷 시각적 기반의 첫 시도입니다. (2) CPT를 위한 고품질 크로스-모달 프롬프트 구성을 찾기 위한 원칙적인 접근 방식을 제시합니다. (3) CPT의 효과를 입증하는 포괄적인 실험을 수행합니다.
2 PRELIMINARY
문헌에서 시각적 기반 확립(visual grounding)은 일반적으로 참조 표현 이해(referring expression comprehension, REC) 문제로 정의됩니다(Plummer et al., 2015, Mao et al., 2016). 이미지 와 참조 표현의 질의 텍스트 가 주어졌을 때, REC는 내에서 에 해당하는 대상 영역을 찾는 것을 목표로 합니다. 이 섹션에서는 VL-PTM(Vision-Language Pre-trained Models)에 대한 바닐라 미세조정(vanilla fine-tuning) 접근법을 소개합니다.
REC에 대한 일반적인 방법은 먼저 객체 탐지기를 통해 일련의 영역 제안 을 감지한 다음, 제안들을 분류하거나 순위를 매겨 대상 영역을 선택하는 것입니다(Lu et al., 2019, Chen et al. 2020). 구체적으로, 시각적 및 텍스트 입력은 입력 토큰의 시퀀스 , 으로 변환되며, 여기서 은 의 텍스트 토큰이고, [IMG], [CLS], [SEP]은 특수 토큰입니다. 입력 표현을 얻기 위해, 이미지 영역의 특징은 시각적 인코더에 의해 추출되고, 텍스트 및 특수 토큰의 임베딩은 조회 테이블을 통해 얻어집니다. 그런 다음 입력 표현은 사전 훈련된 트랜스포머(pre-trained transformers)에 입력되어 숨겨진 표현 을 생성합니다. 마지막으로 대상 영역의 숨겨진 표현은 분류 또는 순위 매기기 손실을 통해 부정적인 것들에 대해 최적화되며, 여기서 새로운 과제 특정 매개변수가 도입됩니다. 결과적으로, 미세조정된 VL-PTM은 시각적 기반 확립 능력을 자극하기 위해 많은 양의 레이블이 붙은 인스턴스가 필요합니다.
3 교차 모달 프롬프트 튜닝(CROSS-MOdAL Prompt Tuning, CPT)
이 섹션에서는 CPT의 프레임워크와 제로샷(zero-shot), 소수샷(few-shot), 완전 감독(fully supervised) 시각적 기반 확립에 CPT를 적용하는 방법을 소개합니다.
3.1 개요
시각적 연결(visual grounding)의 핵심은 이미지 영역과 텍스트 표현 사이의 세밀한 연결을 확립하는 것입니다. 따라서, 좋은 교차 모달 프롬프트 튜닝(cross-modal prompt tuning) 프레임워크는 이미지와 텍스트 양쪽에서 공동 참조 신호(co-referential signals)를 충분히 활용하고, 사전 학습(pre-training)과 튜닝(tuning) 사이의 격차를 최대한 줄여야 합니다. 이를 위해, CPT는 시각적 연결을 빈칸 채우기 문제로 재구성합니다. 그림 1에서 보여주듯이, CPT 프레임워크는 두 가지 구성 요소로 이루어져 있습니다: (1) 이미지 영역을 색깔 블록이나 분할 마스크(segmentation masks)로 고유하게 표시하는 시각적 부 프롬프트(visual sub-prompt)와 (2) 쿼리 텍스트를 색 기반 쿼리 템플릿에 넣는 텍스트 부 프롬프트(textual sub-prompt)입니다. CPT를 갖추면, VL-PTM들은 목표 이미지 영역의 색 텍스트로 마스크된 토큰을 채워 넣음으로써 쿼리 텍스트를 연결하는 것이 간단해집니다. 여기서 목표 형식은 사전 학습과 동일합니다.
3.2 시각적 부 프롬프트(Visual Sub-Prompt)
이미지 와 그 영역 제안 이 주어졌을 때, 시각적 부 프롬프트는 자연스러운 시각적 표시자(visual makers)로 이미지 영역을 고유하게 표시하는 것을 목표로 합니다. 흥미롭게도, 문헌에서는 이미지 내 객체를 시각화하기 위해 색상이 있는 경계 상자(bounding boxes)를 널리 사용한다는 것을 알 수 있습니다. 이에 영감을 받아, 우리는 색상 집합 를 통해 이미지 영역과 쿼리 텍스트를 연결합니다. 여기서 각 색상 는 시각적 외관 (예: RGB )과 색 텍스트 (예: 빨간색)에 의해 정의됩니다. 그런 다음 우리는 각 영역 제안 를 연결을 위한 고유한 색 로 표시하여, 색상이 있는 이미지 제안 집합 을 만들어냅니다. 여기서 는 시각적 부 프롬프트를 나타냅니다.
시각적 부 프롬프트의 형태에 있어서, 원칙적으로 영역을 색으로 표시하는 여러 타당한 선택이 있습니다. 여기에는 색상이 있는 경계 상자, 단색 블록, 또는 단색 객체 분할 마스크가 포함됩니다. 우리의 실험에서는 객체를 단색 블록과 분할 마스크로 색칠하는 것이 경계 상자보다 더 나은 결과를 가져온다는 것을 발견했습니다. 실제 이미지에서 객체의 윤곽에 맞는 단색(예: 빨간 셔츠, 파란 자동차)이 더 흔하기 때문입니다. 시각적 부 프롬프트를 원본 이미지에 추가한다고 해서 VL-PTM의 구조나 매개변수가 변경되는 것은 아닙니다.
3.3 텍스트 부 프롬프트(Textual Sub-Prompt)
텍스트 부 프롬프트(textual sub-prompt)는 질의 텍스트와 시각적 부 프롬프트(visual sub-prompt)에 의해 표시된 이미지 영역 사이의 연결을 설정하도록 VL-PTM(시각-언어 사전 훈련 모델)을 유도하는 것을 목표로 합니다. 구체적으로, 질의 텍스트 (예: "여자가 바라보는 말")는 템플릿 을 사용하여 빈칸 채우기 질의로 변환됩니다:
이 방식으로 VL-PTM은 마스크를 채우기 위해 어떤 영역의 색깔이 더 적절한지(예: 빨간색 또는 파란색) 결정하도록 유도됩니다:

그림 2: 재사용된 MLM 헤드를 사용하여 빈칸을 채워 시각적 관계 검출을 위한 CPT.
여기서 는 대상 영역이고, 는 사전 훈련된 MLM 헤드에서 의 임베딩입니다. 이 절차는 새로운 파라미터를 도입하지 않으며, 사전 훈련과 튜닝 사이의 격차를 완화시키고, 따라서 VL-PTM의 튜닝을 위한 데이터 효율성을 향상시킨다는 점에 유의해야 합니다.
3.4 훈련 및 추론(Training and Inference)
CPT(Cross-Modal Prompt Tuning)를 갖춘 VL-PTMs(Visual-Language Pre-trained Models)는 레이블이 지정된 데이터 없이도 제로샷(zero-shot) 시각적 그라운딩(visual grounding)을 쉽게 수행할 수 있습니다. 왜냐하면 색상의 교차 모달 표현(cross-modal representations)과 다른 개념들(예: 객체, 속성 및 관계)과의 결합이 사전 학습(pre-training) 동안 VL-PTMs에 의해 잘 학습되었기 때문입니다. 몇 개 또는 모든 레이블이 지정된 인스턴스가 사용 가능할 때, VL-PTMs는 엔트로피 기반 목표(entropybased objective)를 사용하여 CPT를 통해 더욱 조정될 수 있습니다: , 여기서 은 훈련 세트입니다.
색상 기반 프롬프트(color-based prompt)를 통해 이미지와 텍스트를 연결하는 것은 매력적이지만, 그 설계에서 두 가지 주요 도전 과제를 확인했습니다: (1) 의 구성을 어떻게 결정할 것인가, 그리고 (2) 제한된 사전 학습된 색상으로 많은 수의 이미지 영역을 어떻게 처리할 것인가.
교차 모달 프롬프트 검색(Cross-Modal Prompt Search). 텍스트 프롬프트 튜닝(textual prompt tuning)에 대한 이전 연구들은 프롬프트 구성(예: 텍스트 템플릿)이 성능에 상당한 영향을 미친다는 것을 보여줍니다(Jiang et al. 2020). 이 연구에서는 교차 모달 프롬프트 구성(즉, 색상 세트 )을 검색하는 첫 번째 조사를 수행합니다. 직관적으로, 는 VL-PTMs가 가장 민감한 색상들로 구성되어야 합니다. 색상 를 얻기 위한 단순한 접근 방식은 사전 학습 텍스트에서 가장 빈번한 색상 텍스트를 로 채택하고, 그 표준 RGB를 로 사용하는 것입니다(예: , red ). 그러나 이 솔루션은 최적이 아닙니다. 왜냐하면 그것은 시각적 외관을 고려하지 않고 색상 텍스트를 결정하며, 실제 이미지에서 색상의 시각적 외관은 종종 그 표준 RGB와 다르기 때문입니다.
이 도전과제를 해결하기 위해, 우리는 실제 세계의 크로스모달(cross-modal) 데이터에서 시각적 및 텍스트 의미론을 함께 고려하는 원칙적인 크로스모달 프롬프트 검색(CPS) 알고리즘을 CPT에 제시합니다. 구체적으로, 우리는 먼저 후보 색상 텍스트 집합 와 시각적 외관 집합 를 식별합니다. 각 시각적 외관 후보 에 대해, 우리는 순수한 색상 블록 과 텍스트: "[CLS] a photo in [MASK] color [SEP]"로 구성된 가짜 데이터 인스턴스를 VL-PTMs에 입력합니다. 그런 다음 우리는 방정식 1에서와 같이 각 색상 텍스트 후보 에 대한 디코딩 점수 를 계산합니다. 여기서 더 큰 디코딩 점수는 와 사이의 더 높은 상관관계를 나타냅니다. VL-PTMs에 의해 민감하게 반응하는 색상 텍스트를 선택하기 위해, 우리는 시각적 외관 후보에 대해 가장 큰 디코딩 점수를 달성하는 색상 텍스트를 유지합니다: . 마찬가지로, 우리는 가장 큰 디코딩 점수에 따라 시각적 외관을 얻을 수 있으며, 이로 인해 색상 세트가 생성됩니다: . 알고리즘의 의사 코드에 대해서는 섹션 를 참조하십시오. 실험에서, 우리는 결과적인 색상이 순진한 색상보다 더 나은 결과를 낳는 것을 발견했습니다. 색칠된 이미지 영역의 원본 내용을 VL-PTMs에 사용할 수 있도록 하기 위해, 투명도 하이퍼파라미터 가 실제로 색상 시각적 외관에 적용됩니다.
이미지 영역 배치. 시각적 연결(visual grounding)에서는 이미지 내의 영역 제안(region proposals)의 수가 의 크기를 보통 초과합니다. 또한, 서로 많이 겹치는 색상 블록들이 시각적 연결을 방해할 수 있다는 점을 관찰했습니다. 따라서, 우리는 이미지 영역들을 배치로 나누고, 각 배치에는 적당히 겹치는 소수의 이미지 영역들을 포함시키며, 각 배치에 각각 시각적 부-프롬프트(visual sub-prompt)를 표시합니다. 대상 영역을 포함하지 않는 배치들을 처리하기 위해, 우리는 디코딩 어휘에 새로운 후보 텍스트 'none'을 도입하여, 해당 배치에 대상 영역이 없음을 나타냅니다.
3.5 시각적 관계 탐지를 위한 CPT
이전 섹션에서 우리는 시각적 연결을 위한 CPT를 소개했습니다. 사실, CPT는 시각적 관계 탐지(visual relation detection)와 같은 다른 크로스-모달(cross-modal) 작업에도 쉽게 적용될 수 있습니다. 이미지 내의 객체 쌍(카테고리와 경계 상자 포함)을 주어진 상태에서, 시각적 관계 탐지는 관계를 관계 집합 로 분류하는 것을 목표로 하며, 이는 많은 크로스-모달 작업을 용이하게 하는 구조화된 이미지 표현을 제공합니다(Johnson et al., 2015; Hudson & Manning, 2019; Shi et al., 2019). 문헌에서, 평가 중에는 ground-truth 관계들이 완전히 주석 처리될 수 없기 때문에, 거짓 음성(false negatives)을 피하기 위해, 이전 작업들은 일반적으로 트리플렛(triplets)을 점수 매기고 상위-N 트리플렛의 리콜(recall)을 평가합니다(Xu et al. 2017. Zellers et al., 2018, Chen et al., 2019: Tang et al., 2019).
시각적 및 텍스트 부-프롬프트. 그림 2에서 보여지듯이, 시각적 관계 탐지를 수행하기 위해 CPT는 먼저 섹션 3.2에서와 같이 이미지 영역에 시각적 부-프롬프트를 표시하고, 다음과 같이 객체 쌍을 쿼리 템플릿에 넣습니다:
여기서 는 주체 텍스트(subject text), 는 객체 텍스트(object text)이며, 와 는 해당 색깔 텍스트(color texts)입니다. 그런 다음 VL-PTMs(시각-언어 사전 훈련 모델)은 템플릿에서 마스킹된 토큰을 복구하여 관계 텍스트(relation texts)를 추출하도록 요청받습니다. 관계 텍스트의 토큰 수가 다양할 수 있음을 고려하여(예: wearing, walking on, 일반적으로 토큰), 관계 텍스트의 토큰 수를 나타내는 변수 을 도입합니다(예: walking on의 경우 ). 템플릿 은 관계 예측을 위해 개의 연속된 마스킹된 토큰을 가집니다. 각 템플릿 에 대해, 토큰으로 구성된 특별한 NA 관계를 도입하는데, 이는 엔티티 쌍(entity pair) 사이에 하에서 관계가 없음을 나타냅니다. 구체적으로, 우리의 실험에서 NA 관계는 각각 에 대해 관련 없음(irrelevant), 관계 없음(no relation), 관계 없음(no relation with)으로 설정됩니다.
훈련. 관계 삼중항(relational triplet) 이 주어지면, 입력 이미지 영역과 객체 쌍을 시각적 및 텍스트 부 프롬프트(sub-prompts)로 꾸민 후, VL-PTMs는 MLM 손실(masked language modeling loss)을 사용하여 관계 토큰을 복구하도록 최적화됩니다. 구체적으로, 의 토큰 수를 로 표시합니다. (1) 템플릿에서 인 경우, 모델은 MLM 헤드를 사용하여 의 번째 마스킹된 토큰을 번째 관계 토큰 로 재구성하도록 요청받습니다. (2) 템플릿에서 인 경우, 사이에 하에서 관계가 없으므로, 모델은 NA 관계를 재구성하도록 요청받습니다. 이미지에서 사이에 어떠한 관계도 없는 경우, 모델은 모든 에 대해 NA 관계를 재구성하도록 요청받습니다.
추론. 추론 과정에서, 객체 쌍 이 주어지면, 우리는 프롬프트 맥락에 적합한 관계들을 점수화합니다. 구체적으로, 각 관계 의 점수는 해당 템플릿 아래에서 구성 토큰들의 집계된 MLM(Masked Language Model) 점수를 통해 얻어집니다: , 여기서 입니다. 직관적으로, 이 크다는 것은 관계 이 프롬프트 맥락에 더 잘 맞는다는 것을 나타냅니다. 마지막으로, 삼중항 은 관계 점수 에 따라 순위가 매겨지며, 여기서 입니다.
시각적 그라운딩(visual grounding)은 무근거 텍스트에 대한 이미지 영역을 찾는 것을 목표로 하는 반면, 시각적 관계 탐지(visual relation detection)는 시각적 상식 추론(Zellers et al., 2019), 객체 분류(Zhao et al., 2017), 장면 그래프 분류(Xu et al., 2017)와 같은 근거된 입력에 기반한 의미 인식을 수행하는 다른 시리즈의 크로스모달(cross-modal) 작업을 나타냅니다. 더 나은 데이터 효율성 외에도, CPT를 사용하는 중요한 장점은 고정된 레이블 세트 대신 개방형 어휘에서 의미 레이블을 생성할 수 있다는 것입니다.
4 실험
이 섹션에서는, 우리는 다양한 설정에서 시각적 그라운딩을 위한 VL-PTM(Visual-Language Pre-trained Models) 프롬프팅에 CPT를 경험적으로 평가합니다. 여기에는 제로샷(zero-shot), 퓨샷(few-shot) 및 완전 감독(fully supervised) 설정이 포함됩니다. 구현 세부 사항은 섹션 C를 참조하십시오.
4.1 실험 설정
우리는 시각적 그라운딩 작업의 실험 설정을 소개합니다. 여기에는 데이터셋, 훈련 설정, 평가 프로토콜 및 실험에서 사용한 기준 모델이 포함됩니다.
데이터셋. 이전 연구들(Rohrbach et al., 2016, Zhang et al., 2018)을 따라, 우리는 MSCOCO 이미지(Lin et al., 2014)에서 수집된 세 가지 널리 사용되는 시각적 그라운딩 데이터셋을 채택합니다. 여기에는 RefCOCO(Yu et al., 2016), RefCOCO+(Yu et al., 2016) 및 RefCOCOg(Mao et al., 2016)가 포함됩니다. 데이터셋에 대한 더 자세한 정보는 섹션 D.2를 참조하십시오.
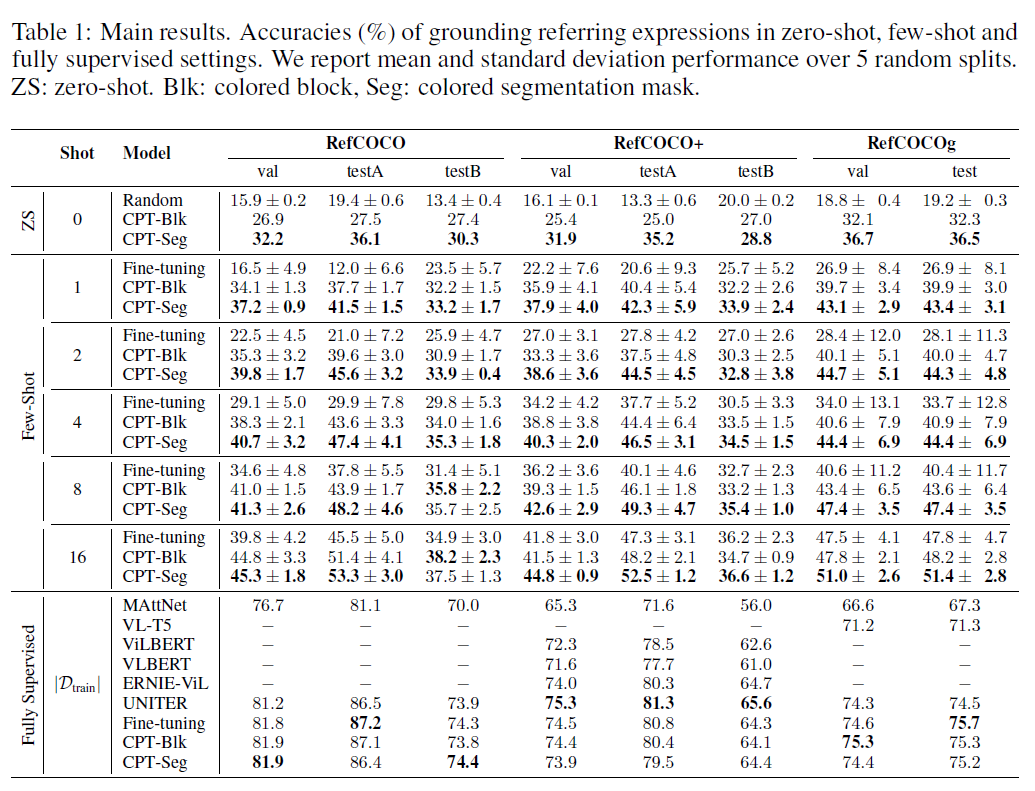
표 1: 주요 결과. 제로샷(zero-shot), 퓨샷(few-shot) 및 완전 감독(fully supervised) 설정에서 참조 표현을 그라운딩하는 정확도(%)입니다. 우리는 5개의 무작위 분할에 대한 평균 및 표준 편차 성능을 보고합니다. ZS: 제로샷(zero-shot). Blk: 색깔이 있는 블록, Seg: 색깔이 있는 분할 마스크.
훈련 설정. 우리는 다양한 훈련 설정에 대한 실험 결과를 보고합니다. 여기에는 (1) 제로샷(zeroshot) 설정, 훈련 데이터가 전혀 없는 경우, (2) 퓨샷(few-shot) 설정, 개의 훈련 인스턴스가 사용 가능한 경우 (), 그리고 (3) 완전 감독(fully supervised) 설정, 전체 훈련 세트가 사용 가능한 경우가 포함됩니다.
평가 프로토콜. (1) 평가 지표. Zhang et al. (2018); Lu et al. (2019)를 따라, 우리는 그라운딩(grounding) 결과의 정확도를 평가 지표로 채택합니다. 표현식이 올바르게 그라운딩되었다고 간주되는 것은 상위 예측 영역과 실제 값의 IoU(Intersection over Union)가 0.5보다 큰 경우입니다. (2) 모델 검증. 몇 개의 레이블이 지정된 인스턴스만 사용 가능한 퓨샷 시나리오를 더 잘 근사하기 위해, Gao et al. (2021)에 영감을 받아, 우리는 퓨샷 및 제로샷 실험에 대해 16개 인스턴스로 구성된 퓨샷 검증 세트를 사용하고, 완전 감독 실험에는 전체 검증 세트를 사용합니다. (3) 강건한 평가. 이전 연구들은 제한된 데이터에 대한 모델 훈련이 불안정성을 겪을 수 있다는 것을 보여주었습니다(Dodge et al., 2020; Gao et al., 2021). 강건하고 포괄적인 평가를 위해, 우리는 5개의 무작위 훈련 세트 분할에 대한 평균 결과와 표준 편차를 보고합니다. 공정한 비교를 위해, 훈련 및 검증 세트는 우리의 베이스라인과 CPT에 대해 동일합니다.
베이스라인. 우리는 CPT의 두 가지 변형을 평가합니다. 여기에는 색깔 블록을 사용하는 CPT(CPT-Blk)와 색깔 분할 마스크를 사용하는 CPT(CPT-Seg)가 포함됩니다. 우리는 널리 사용되는 VinVL(Zhang et al. 2021)을 CPT의 백본으로 채택합니다. 우리는 검출된 제안을 활용하는 일련의 강력한 베이스라인과 CPT를 비교합니다. 여기에는 VinVL의 바닐라(vanilla) 미세 조정과 다른 VL-PTM들이 포함됩니다(더 자세한 베이스라인 정보는 D.1절을 참조하세요). 공정한 비교를 위해, 우리는 모든 VL-PTM에 대해 베이스 크기를 채택합니다. 대형 크기 VL-PTM의 결과는 A.1절을 참조하시기 바랍니다.
4.2 주요 결과
주요 결과는 표 11에서 보고되며, 여기서 우리는 다음과 같은 사실을 관찰할 수 있습니다: (1) CPT는 제로샷(zero-shot)과 퓨샷(few-shot) 설정에서 무작위 기준(random baseline)과 강력한 파인튜닝(fine-tuning) 기준을 큰 차이로 능가합니다. 예를 들어, 시각적 부 프롬프트(visual sub-prompts)로 색칠된 블록을 사용할 때, CPT는 RefCOCO 평가에서 원샷(one shot)으로 평균 의 절대 정확도 향상을 달성합니다. 이는 CPT가 VL-PTM(Visual-Language Pre-trained Models)의 샘플 효율성을 효과적으로 개선할 수 있음을 나타냅니다. (2) 시각적 부 프롬프트에서 분할 마스크(segmentation masks)로 객체를 색칠하는 CPT-Seg는 블록(CPT-Blk)보다 더 좋은 결과를 달성합니다. 그 이유는 객체의 윤곽에 맞는 단색이 실제 이미지에서 더 흔하기 때문에, CPT-Seg가 더 자연스러운 시각적 부 프롬프트가 되기 때문입니다(분할 도구를 훈련시키기 위한 더 강력한 주석이 필요함에도 불구하고). (3) 주목할 만한 것은, CPT가 파인튜닝보다 훨씬 더 작은 표준 편차를 달성한다는 것입니다. 예를 들어, CPT-Blk는 RefCOCO 평가에서 원샷으로 평균 의 상대 표준 편차 감소를 달성합니다. 이는 사전 훈련(pre-training)에서 일관된 튜닝 접근 방식이 훨씬 더 안정적인 퓨샷 훈련을 이끌 수 있음을 보여주며, 이는 퓨샷 학습 모델을 평가하는 데 있어 중요한 요소입니다(Gao et al., 2021). (4) 우리는 CPT-Blk가 RefCOCO+ 평가에서 16샷(16 shots)으로 파인튜닝을 약간 못 미치는 성능을 보인다는 것을 지적합니다. 그 이유는 RefCOCO+에 색상 기반 표현(colorbased expressions)이 더 많이 포함되어 있어서(예: 빨간 셔츠와 파란 모자를 쓴 사람), 우리의 색상 기반 CPT를 방해할 수 있기 때문입니다. 그러나, 완전 감독(fully supervised) 시나리오에서 더 많은 튜닝 인스턴스를 사용하면 모델이 질의 텍스트와 프롬프트 템플릿에서 색상을 더 잘 구별하도록 학습할 수 있어 이 문제를 완화할 수 있습니다. (5) CPT 모델은 완전 감독 설정에서 강력한 파인튜닝된 VL-PTM과 비슷한 성능을 달성합니다. 이는 CPT가 완전 감독 시나리오에서도 VL-PTM에 대한 경쟁력 있는 튜닝 접근 방식임을 보여줍니다. 우리는 CPT-Blk가 완전 감독 설정에서 CPT-Seg보다 약간 더 나은 성능을 보인다는 것을 지적하며, 자세한 분석은 A.3 절을 참조하시기 바랍니다. 요약하자면, 바닐라 파인튜닝(vanilla fine-tuning) 접근 방식과 비교하여, CPT는 제로샷, 퓨샷, 완전 감독 시각적 그라운딩(visual grounding)에서 우수하거나 비슷하며, 더 안정적인 성능을 달성합니다.
4.3 CPT의 시각적 그라운딩에서 색상의 영향
우리의 분석에서, 우리는 먼저 CPT의 시각적 기반 성능에 영향을 미치는 핵심 요소인 색상의 영향을 조사합니다. 구체적으로, 빈도 기반 베이스라인(Freq) (3.4절 참조)에서 얻은 색상과 우리의 교차 모달 프롬프트 검색 방법 CPS(Ours)를 포함하여 전체적인 상위-N 색상 평가와 개별 색상에 대한 세부적인 연구의 두 가지 차원에서 비교합니다. 별도로 명시하지 않는 한, 다음의 모든 실험은 RefCOCO 검증 세트에서 CPT-Blk를 기반으로 샷 설정에서 수행됩니다.
표 2: 빈도 기반 베이스라인과 우리의 CPS에서 상위-6 색상. 시각적 외관과 색상 텍스트가 보고됩니다. 색상에서 가장 잘 보입니다.

상위-N 색상의 전체 평가. 우리는 먼저 표 2에서 각 접근법에 의해 추천된 상위-6 색상을 보여줍니다. 다른 모델들의 상위 색상의 전체 성능을 평가하기 위해, 우리는 각각 상위-6 색상에서 CPT를 장착하여 평가하고, 다른 색상에 대한 평균 정확도와 표준 편차를 보고합니다. 그림 3a의 실험 결과에서, 우리는 CPS가 생성한 상위 색상이 다른 샷 설정에서 베이스라인 방법보다 더 높은 평균 정확도와 더 낮은 표준 편차를 달성한다는 것을 관찰합니다. 그 이유는 CPS가 시각적 및 텍스트 의미론을 함께 고려하여 교차 모달 프롬프트를 검색하므로, 더 정확하고 안정적인 시각적 기반을 위해 색상을 효과적으로 조정하고 순위를 매길 수 있기 때문입니다.
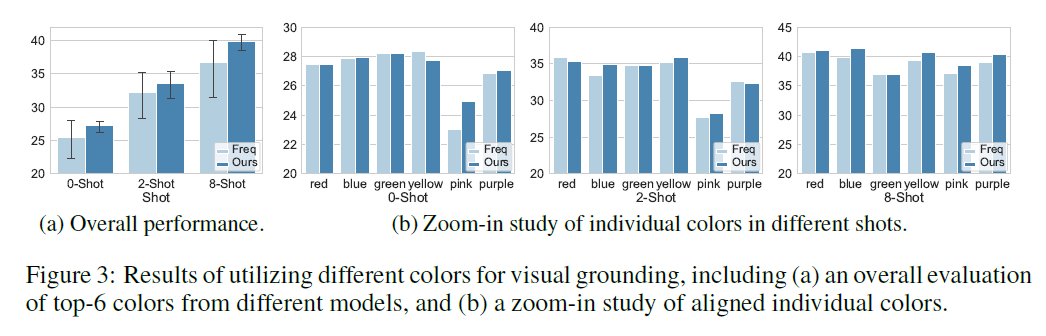
그림 3: 시각적 기반(visual grounding)을 위해 다양한 색상을 활용한 결과, 여기에는 (a) 다양한 모델에서 상위 6가지 색상의 전체 평가와 (b) 정렬된 개별 색상의 확대 연구가 포함됩니다.
개별 색상의 확대 연구. CPT의 시각적 기반에서 특정 색상의 세밀한 영향을 조사하기 위해, 우리는 개별 색상에 대한 확대 연구를 추가로 수행합니다. 비교를 위해 색상을 정렬하기 위해, 우리는 기준선(baseline)과 CPS에서 상위 6가지 색상을 합치고, 모델의 완전한 색상 세트에 포함되지 않은 색상들을 제거합니다(예: CPS에서 검정 ). 우리는 정확도를 보고합니다.
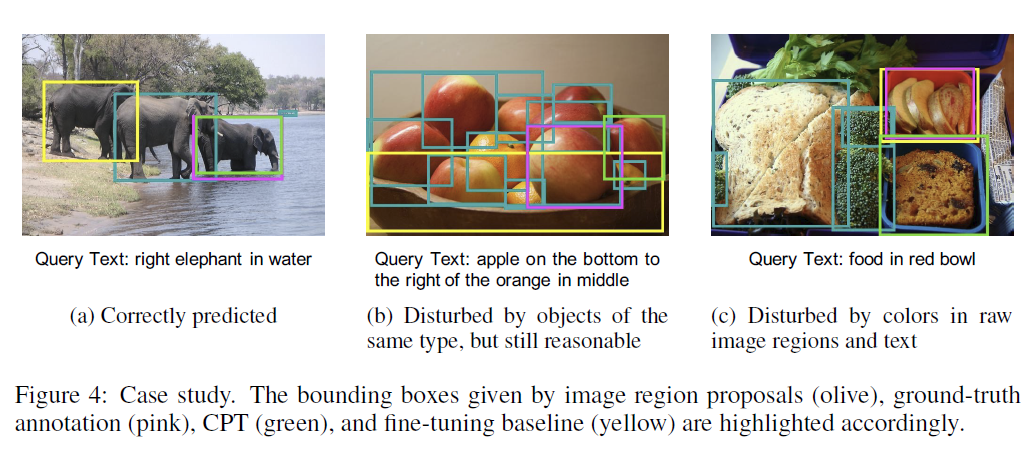
그림 3b에서 우리는 다음과 같은 점을 관찰합니다: (1) 같은 샷 설정(shot-settings)에서 VL-PTM을 프롬프트하는 데 있어 다양한 색상의 성능이 크게 다르며, 최적의 색상은 샷 설정에 따라 다릅니다. 이 결과는 교차 모달 프롬프트 설정(cross-modal prompt configurations)의 큰 영향을 나타내며, 최근의 텍스트 프롬프트 튜닝(textual prompt tuning) 연구(Jiang et al., 2020; Gao et al., 2021)에서의 발견과 일치합니다. (2) CPS에 의해 생성된 색상은 개별 색상의 기준선(baseline)과 비교하여 비슷하거나 우수한 성능을 보입니다. 이 결과는 색상 텍스트가 주어졌을 때, CPS가 색상 시각적 외관(예: RGB)을 적절히 조정하여 시각적 근거(visual grounding) 성능을 향상시킬 수 있음을 보여줍니다. (3) 일부 경우에서 CPS에 의해 생성된 색상이 기준선보다 약간 낮은 성능을 보이는 것을 우리는 주목합니다. 우리는 이유가 CPS가 색상 조정을 위해 단일 텍스트 템플릿을 사용하여 디코딩 점수를 계산하는데, 이것이 편향될 수 있다고 가설을 세웁니다. 이 문제는 Qin & Eisner (2021)에서처럼 템플릿을 앙상블하는 방법으로 해결될 수 있으며, 이는 미래의 연구로 남겨둡니다.
4.4 사례 연구(CASE STUDY)
CPT에 대한 보다 직관적인 이해를 제공하기 위해, 우리는 RefCOCO 검증 세트에서 8-샷 설정(8-shot setting)으로 사례 연구를 수행합니다. 그림 4의 결과에서 우리는 다음과 같은 관찰을 합니다: (1) CPT는 몇 개의 학습 인스턴스만을 사용하여 동일한 유형의 객체에 의해 방해받는 대상 객체를 구별할 수 있게 해주는 반면, 미세 조정(fine-tuning) 방법은 성공하는 데 어려움을 겪습니다(그림 4a). (2) CPT는 어려운 후보(예: 복잡한 추론이 필요한 대상과 동일한 유형의 객체)에 의해 방해받을 수 있지만, 일반적으로 합리적인 예측을 생성합니다. 예를 들어, 그림 4b에서 CPT는 인접한 사과를 예측하는 반면 미세 조정 기준선은 그릇을 예측합니다. 이유는 CPT가 VL-PTM의 사전 훈련된 매개변수를 최대한 재사용하기 때문이며, 이는 몇 샷 미세 조정에서 일반적으로 발생하는 터무니없는 예측을 방지하는 데 도움이 될 수 있습니다. (3) 그러나 우리는 CPT가 원본 이미지 영역과 텍스트의 색상에 의해 방해받을 수 있다는 것을 발견했습니다. 예를 들어, 후보 영역이 빨간색 블록으로 색칠되어 있을 때 모델이 빨간색 그릇을 식별하기 어려울 수 있습니다(그림 4c).
4.5 시각 관계 탐지(Visual RELATION DETECTION)에 대한 실험
CPT의 일반화 능력을 보여주기 위해, 우리는 시각 관계 탐지(visual relation detection)에서 CPT를 추가로 평가합니다.
실험 설정. (1) 데이터셋. 우리는 인기 있는 Visual Genome 데이터셋(Krishna et al., 2017)을 사용합니다. 이 데이터셋에는 50개의 시각적 관계가 포함되어 있습니다. 데이터셋 세부사항은 D.2 절에서 확인하실 수 있습니다. (2) 평가 프로토콜. 이전 연구들(Xu et al. 2017, Chen et al., 2019)을 따라, 우리는 recall@N(R@N)과 mean recall@N(mR@N)을 평가 지표로 사용합니다. 훈련 중에는 각 관계에 대해 K개의 레이블이 붙은 인스턴스가 제공됩니다. (3) 베이스라인. 우리는 VinVL의 파인튜닝(fine-tuning)을 가장 직접적인 베이스라인 모델로 채택합니다. 구체적으로, 우리는 이미지 영역과 그 카테고리를 모델에 입력하고, 주체와 객체의 시각적 숨겨진 표현을 연결합니다. 그런 다음 객체 쌍 표현을 소프트맥스 분류기(softmax classifier)에 입력합니다. 모든 VL-PTM은 베이스 크기(base size)입니다. 우리는 또한 이 작업에 맞춤화된 강력한 베이스라인의 결과를 보고합니다. 이들은 315,642개의 레이블이 붙은 트리플릿으로 완전히 감독되며, 여기에는 Neural Motif(Zellers et al. 2018), BGNN(Li et al., 2021a), PCPL(Yan et al. 2020) 및 DT2-ACBS(Desai et al., 2021)가 포함됩니다.
표 3: Visual Genome에서의 시각적 관계 탐지 결과. ZS: 제로샷(zero-shot), FS: 완전 감독(fully supervised). 우리는 2개의 무작위 분할에 대한 평균 및 표준 편차 성능을 보고합니다.
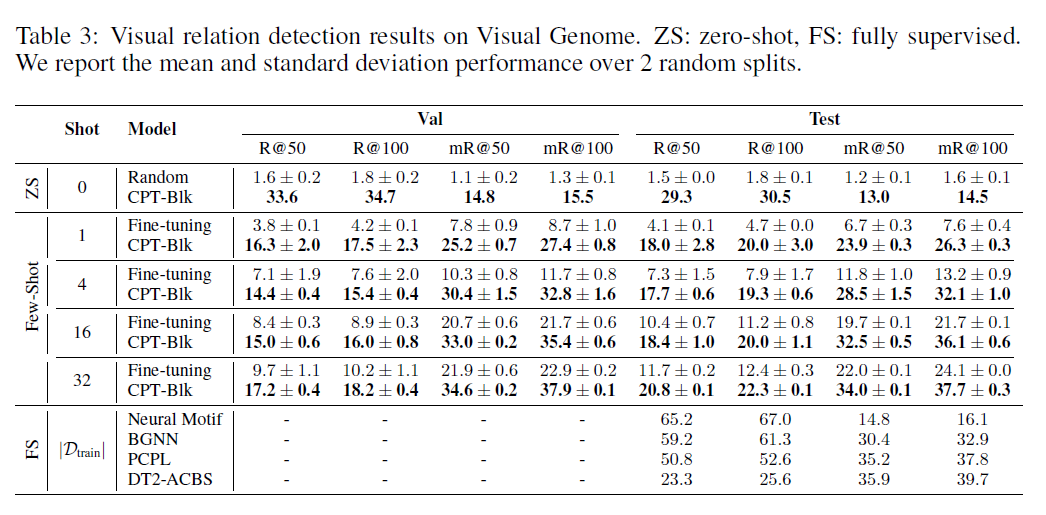
결과. 표 3의 결과에서 우리는 다음과 같은 사실을 관찰할 수 있습니다: (1) CPT(Cross-modal Prompt Tuning)는 제로샷(zero-shot)과 퓨샷(few-shot) 설정에서 무작위 기준선(random baseline)과 강력한 파인튜닝(fine-tuning) 기준선을 크게 뛰어넘습니다. 예를 들어, 32샷(shot)을 사용할 때 CPT는 강력한 를 달성하여 파인튜닝을 절대적으로 포인트 뛰어넘고, 최첨단 완전 감독 DT2-ACBS에 근접합니다. 이는 CPT가 VL-PTM(Vision-language Pre-trained Models)의 샘플 효율성을 향상시킬 수 있음을 나타냅니다. (2) CPT의 매크로(macro) 성능은 샷(shot) 수가 증가함에 따라 단조롭게 증가하지만, 1샷과 4샷 설정에서 마이크로(micro) 성능은 먼저 떨어집니다. 이는 균형 잡힌 훈련 세트(즉, 각 관계에 대한 샷)와 롱테일(long-tail) 테스트 세트 간의 분포 격차 때문입니다. 사전 훈련 코퍼스(pre-training corpora)의 관계도 롱테일 분포를 따르기 때문에, CPT는 마이크로 성능에 대한 높은 출발점을 달성할 수 있습니다.
5 관련 연구
사전 훈련된 시각-언어 모델. 기존의 VL-PTM은 사전 훈련 목표와 아키텍처에 따라 대략 세 가지 범주로 나눌 수 있습니다: (1) 마스크된 언어 모델링(masked language modeling) 기반 VL-PTM은 주로 마스크된 토큰을 복구하는 데 사전 훈련됩니다(Lu et al., 2019: Su et al., 2019. Tan & Bansal, 2019, Li et al., 2020; Yu et al. 2021); (2) 자동 회귀 언어 모델링(auto-regressive language modeling) 기반 VL-PTM은 이미지와 텍스트 토큰을 트랜스포머 디코더(Transformer decoders)로 자동 회귀적으로 모델링합니다(Ramesh et al. 2021; Wang et al. 2021); (3) 대조 학습(contrastive learning) 기반 VL-PTM은 이미지-텍스트 쌍을 전체적으로 매칭하기 위해 사전 훈련됩니다(Radford et al., 2021; Li et al., 2021b). 우리의 CPT 프레임워크는 VL-PTM 설계와 직교합니다. 이 연구에서는 일반성을 잃지 않고, 그들의 보편성과 우수한 성능 때문에 마스크된 언어 모델링 기반 VL-PTM에 대한 프롬프팅(prompting)에 초점을 맞추지만, CPT를 다른 VL-PTM에 적용하는 것도 가능합니다.
NLP를 위한 프롬프트 튜닝. 사전 훈련된 언어 모델을 위한 프롬프트 튜닝은 NLP(Natural Language Processing, 자연어 처리) 분야에서 빠르게 부상하고 있는 연구 분야입니다(Raffel et al. 2019, Brown et al. 2020; Liu et al., 2021). 처음에는 사전 훈련된 언어 모델에서 지식을 탐구하기 위해 설계된 프롬프트 튜닝은 이제 언어 이해(Schick & Schütze, 2021a b)와 생성(Li & Liang, 2021)을 포함한 다양한 NLP 작업을 처리하기 위해 확장되었습니다. 프롬프트 엔지니어링을 용이하게 하기 위해 Shin et al. (2020)은 기울기 기반 검색을 통해 자동으로 프롬프트 템플릿을 생성하는 방법을 제안했습니다. 우리의 연구와 가장 관련이 있는 것은 Tsimpoukelli et al. (2021); Zhou et al. (2021); Wang et al. (2021)로, VL-PTM(비전-언어 사전 훈련된 모델)을 위한 텍스트 프롬프트 튜닝을 제시하며, 일부 비전-언어 작업에서 유망한 결과를 달성했습니다. 그러나 NLP 분야의 기존 연구와 마찬가지로, 그들은 텍스트에서의 프롬프트 엔지니어링에 초점을 맞추고 이미지는 그대로 두었으며, 따라서 전체적인 암시적 시각적 그라운딩만 수행할 수 있습니다. 비교해보면, 저희가 아는 한, CPT는 이미지와 텍스트 모두를 위해 맞춤화된 최초의 크로스-모달 프롬프트 튜닝 프레임워크이며, 자연어를 세밀한 이미지 영역에 명시적으로 그라운딩할 수 있는 능력을 가지고 있습니다.
시각적 그라운딩. 시각적 그라운딩이 비전-언어 작업을 해결하는 데 필수적인 역할을 한다는 데 일반적인 합의가 있습니다(Karpathy & Fei-Fei, 2015; Plummer et al., 2015; Goodfellow et al. 2016; Krishna et al. 2017; Lu et al. 2019). Mao et al. (2016)은 시각적 그라운딩 능력을 명시적으로 평가하기 위해 참조 표현 이해 작업을 제안했습니다. 이 작업을 해결하기 위해 대부분의 모델들은 완전한 감독 하에 표현식을 기반으로 이미지 영역 후보를 분류하거나 순위를 매기는 방법을 학습합니다(Mao et al., 2016; Zhang et al., 2018; Lu et al. 2019, Chen et al., 2020), 이는 많은 양의 비용이 많이 드는 인간 주석 데이터를 필요로 합니다. 인간 주석에 대한 의존도를 줄이기 위해, 일부 연구들은 새로운 객체 유형에 대한 제로/퓨샷 그라운딩을 조사했습니다(Sadhu et al., 2019; Blukis et al. 2020), 그러나 기존 객체 유형에 대해서는 여전히 훈련 데이터가 필요합니다. 비교해보면, 우리는 특정 객체 유형에 독립적인 새로운 채워넣기(fill-in-the-blank) 패러다임을 개혁하여 제로 및 퓨샷 시각적 그라운딩을 위해 일반 VL-PTM을 프롬프트합니다.
6 결론 및 향후 작업
이 연구에서는 VL-PTM(시각-언어 사전 훈련 모델)을 위한 첫 번째 Cross-modal Prompt Tuning(CPT) 프레임워크를 제시합니다. 프롬프트 엔지니어링을 용이하게 하기 위해, 우리는 크로스모달 프롬프트 구성을 검색하기 위한 원칙적인 접근 방식을 제시합니다. 종합적인 실험 결과는 CPT가 제로샷(zeroshot), 퓨샷(few-shot) 및 완전 감독된 시각적 그라운딩(visual grounding)에서의 효과를 입증합니다. 향후에는 CPT의 색상 교란(color disturbance) 문제를 해결하고 계산 효율성을 향상시키며, 다른 시각-언어 작업에서의 CPT 효과를 조사할 계획입니다. 크로스모달 프롬프트 튜닝의 첫 시도로서, 우리는 색상 기반 프레임워크를 가능한 프롬프트 튜닝 솔루션 중 하나로 제안합니다. VL-PTM의 다른 타당한 프롬프트 튜닝 접근 방식을 탐구하는 것은 미래의 연구로 남겨둡니다.
7 윤리 성명(ETHICS STATEMENT)
이 섹션에서는 CPT의 주요 윤리적 고려 사항을 논의합니다: (1) 지적 재산권 보호. 이전 작업에서 가져온 코드와 데이터는 연구 목적으로 사용될 수 있도록 허가되었습니다. (2) 개인 정보 보호. 이 연구에서 사용된 데이터(즉, 사전 훈련 데이터와 튜닝 데이터)는 연구 목적으로 인간 주석자에 의해 생성되었으며, 개인 정보 문제를 일으키지 않아야 합니다. (3) 잠재적 문제. VL-PTM은 일부 객체와 속성에 대해 편향될 수 있습니다. 이 문제를 해결하기 위한 노력이 커뮤니티에서 증가하고 있습니다(Ross et al., 2021; Zhao et al., 2021).
8 재현성 성명(REPRODUCIBILITY STATEMENT)
재현성을 극대화하기 위해, 우리는 섹션 3에서 방법론에 대한 명확한 설명, 섹션 B에서 모델의 의사 코드(pseudo-code), 섹션 C에서 구현 세부 사항, 그리고 섹션 4.1에서 상세한 데이터 특성 및 평가 프로토콜을 제공합니다. 모든 데이터와 코드는 미래 연구를 용이하게 하기 위해 공개될 예정입니다.
A 부록 실험
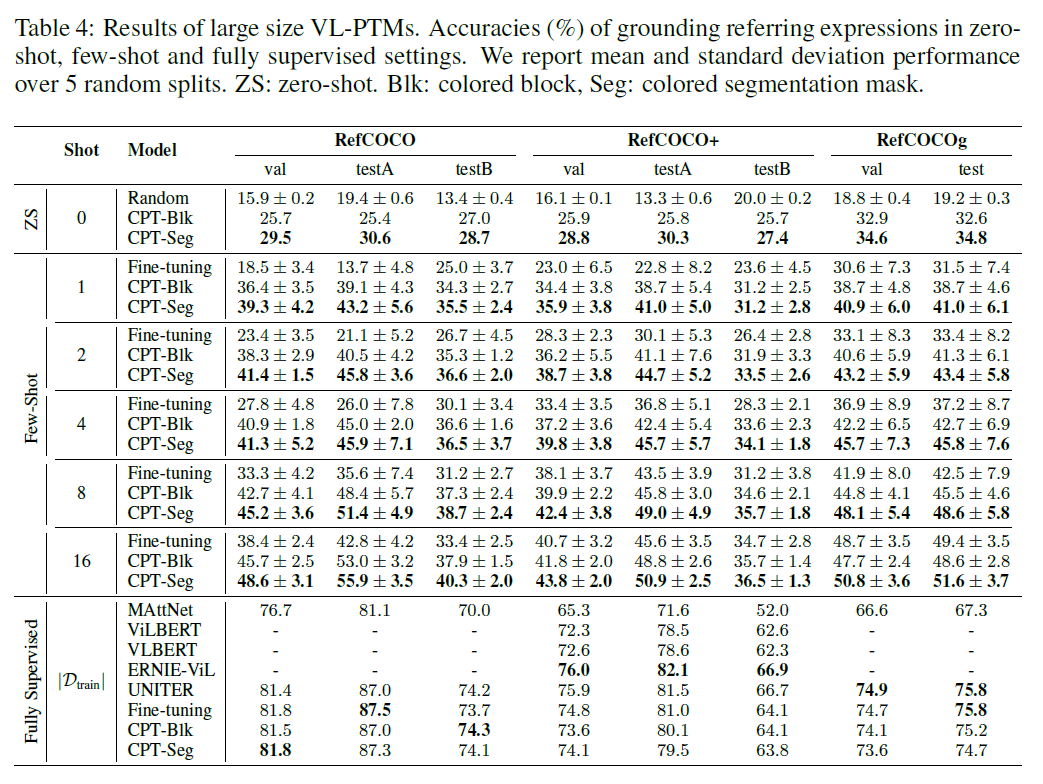
A.1 대형 VL-PTM의 결과
이 섹션에서는 대형 VL-PTM(Vision-Language Pre-trained Models)의 실험 결과를 보고합니다. 여기에는 기본 VL-PTM의 바닐라 미세조정(vanilla finetuning), 대형 백본(large size backbone)을 가진 CPT-Blk와 CPT-Seg(즉, 1,024 차원의 은닉 표현과 24개의 레이어)이 포함됩니다. 표 4의 실험 결과에서 우리는 바닐라 미세조정에 비해 CPT가 제로샷(zero-shot)과 퓨샷(few-shot) 설정에서 현저히 더 나은 그리고 더 안정적인 성능을 달성하며, 완전 감독(fully supervised) 설정에서는 비슷한 결과를 보인다는 것을 관찰합니다. 이는 4.2절의 주요 실험 결론과 일치합니다. 요약하자면, 결과는 CPT가 다양한 크기의 VL-PTM에 일반화될 수 있음을 보여줍니다.
표 4: 대형 VL-PTM의 결과. 제로샷(zeroshot), 퓨샷(few-shot) 및 완전 감독(fully supervised) 설정에서 참조 표현을 지상화하는 정확도(%)입니다. 우리는 5개의 무작위 분할에 대한 평균 및 표준 편차 성능을 보고합니다. ZS: 제로샷(zero-shot). Blk: 색깔 블록, Seg: 색깔 분할 마스크.
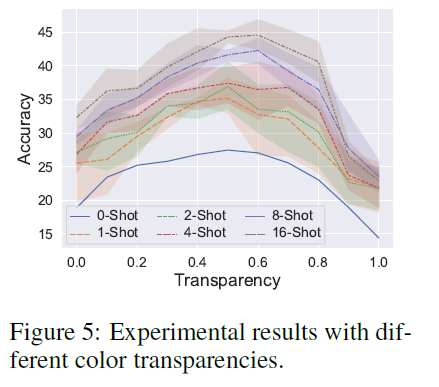
A.2 색상 투명도의 효과
실제로, 색상 투명도는 CPT에서 중요한 하이퍼파라미터입니다. 본질적으로, 투명도의 선택은 두 가지 요소 사이의 절충입니다: 낮은 투명도는 색상 텍스트와 시각적 외관 사이의 강한 연결을 설정할 수 있지만, 원본 이미지 영역의 가시성을 저하시킬 수 있고, 그 반대의 경우도 마찬가지입니다. 색상 투명도의 효과를 조사하기 위해, 우리는 기본 색상(즉, (240, , 빨간색)의 다른 투명도로 CPT를 평가하며, 그리드 탐색에서 0.1의 단계 크기를 사용합니다. 그림 5의 결과에서 우리는 다음과 같이 관찰합니다: (1) 다양한 샷 설정에서 성능이 중간 정도의 투명도에서 최고점에 도달하는데, 이는 우리의 절충 분석과 일치합니다. (2) 흥미롭게도, 최적의 투명도는 훈련 샷의 수가 증가함에 따라 증가합니다. 이유는 낮은 샷 설정에서 시각적 기반을 확립하는 병목 현상이 CPT에서 뚜렷한 색상을 활용하여 대략적인 연결을

그림 7: 그라운딩 결과 시각화. 첫 번째 행: 제로샷(zero-shot) 설정. 두 번째 행: 완전 감독(fully supervised) 설정. FT: 파인튜닝(fine-tuning). 이미지 영역 제안(올리브색), 정답 주석(핑크색), CPT(녹색), 파인튜닝 베이스라인(노란색)에 의해 제공된 바운딩 박스가 각각 강조되어 있습니다. 더 나은 시각적 효과를 위해 일부 이미지는 잘라냈습니다.
이미지와 텍스트에 비해, 많은 샷 설정에서는 색상에 대한 더 나은 이해, 세밀한 읽기 및 이미지 영역 이해가 복잡한 추론(예: 속성과 관계의 구성)이 필요한 어려운 인스턴스를 처리하는 데 더 중요해집니다.
A.3 ViSUAL SUB-PROMPT SHAPE 분석
표 1의 주요 실험 결과에서, CPT-Seg가 제로샷(zero-shot)과 퓨샷(few-shot) 설정에서 CPT-Blk를 크게 앞선다는 것을 알 수 있지만, 완전 감독(fully supervised) 설정에서는 CPT-Blk에 약간 못 미친다는 것을 알 수 있습니다. 이유를 조사하기 위해, 우리는 RefCOCOg 검증 세트의 대상 객체를 바운딩 박스의 면적에 따라 서로 겹치지 않는 구간으로 나누고, 각 구간에 동일한 수의 대상 객체가 포함되도록 하여(따라서 전체 결과에 동일하게 기여), 완전 감독 설정에서 각 구간의 평균 성능을 보고합니다. 그림 6의 결과에서, 우리는 CPT-Seg가 큰 객체에서는 CPT-Blk를 능가하지만, 작은 객체에서는 그라운딩이 떨어진다는 것을 발견했습니다. 우리는 CPT-Seg가 완벽하지 않은 색상 분할 마스크로 객체 윤곽을 변경하여 어느 정도 객체의 이해와 추론을 방해한다고 가설을 세웠습니다. 이 문제는 작은 객체에서 더욱 심화되는데, 큰 객체와 비교할 때 작은 객체의 분할 오류는 객체 특징 맵이 트랜스포머(Transformers)의 입력 특징으로 풀링될 때 본질적으로 확대되기 때문입니다.
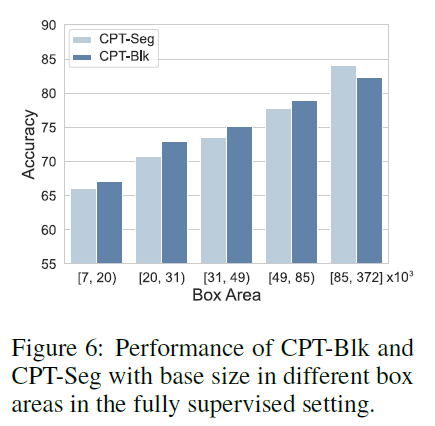
그림 6: 완전 감독 설정에서 다른 박스 영역의 기본 크기에 따른 CPT-Blk와 CPT-Seg의 성능.
A.4 시각화
퓨샷(few-shot) 그라운딩 결과는 그림 4에서 시각화되었습니다. 이 섹션에서는 그림 7에 표시된 것처럼 제로샷(zero-shot)과 완전 감독(fully supervised) 설정에서의 그라운딩 결과를 더 시각화합니다. 우리는 발견합니다.
CPT는 합리적인 제로샷 예측을 할 수 있습니다. 더욱이, 완전 감독 설정(즉, CPT가 원본 이미지와 텍스트의 색상에 의해 덜 방해받는 설정)에서 색상 교란 문제가 크게 완화되는 것을 관찰할 수 있습니다. 그 이유는 능력 있는 VL-PTM(시각-언어 사전 훈련 모델)이 다양한 객체와 사전 정의된 메이커 블록의 색상을 상당히 구별하는 법을 배울 수 있기 때문입니다.
B 크로스모달 프롬프트 탐색의 의사 코드
여기서는 크로스모달 프롬프트 탐색의 의사 코드를 제공합니다. 이 알고리즘은 실제 세계의 크로스모달 데이터에서 시각적 및 텍스트 의미를 공동으로 고려하여 CPT에서 색상 세트 를 탐색하는 것을 목표로 합니다. 알고리즘은 설계가 단순하며, 더 발전된 크로스모달 프롬프트 탐색 방법을 미래의 연구로 남겨둡니다.

C 구현 세부 사항
이 섹션에서는 모델 훈련 및 추론, 객체 탐지 및 세분화, 그리고 크로스모달 프롬프트 탐색에 대한 구현 세부 사항을 제공합니다.
백본. 우리는 많은 시각-언어 작업에서 강력한 성능을 보이는 널리 사용되는 VinVL(Zhang et al., 2021)을 백본으로 채택합니다. 주요 실험에서는 768 차원의 숨겨진 표현과 12개의 인코딩 레이어를 가진 VinVL 모델을 사용합니다.
객체 탐지 및 세분화. 훈련 및 추론 중에는 MAttNet(Yu et al. 2018)에서 제공하는 Faster-RCNN(Ren et al. . 2015)에 의해 예측된 영역 제안과 Mask-RCNN(He et al., 2017)에 의해 예측된 객체 분할 마스크를 사용합니다. Faster-RCNN과 Mask-RCNN 모두 ResNet101(He et al. 2016)을 기반으로 하며, 영역 제안 네트워크와 객체 탐지를 위한 완전 연결 분류기를 가지고 있습니다. Mask-RCNN의 경우, 멀티태스크 학습을 수행하기 위한 추가 마스크 분기가 추가됩니다. MAttNet(Yu et al. 2018)에서 제공하는 Faster-RCNN과 Mask-RCNN은 각각 COCO 테스트 세트에서 34.1과 30.7의 평균 정밀도를 달성합니다.
시각적 정합(Visual Grounding). 학습 중에, 이미지 영역은 그라운드-트루스(ground-truth) 영역과의 교차-합집합(IoU)이 0.5보다 크면 대상으로 간주됩니다. 추론 중에는 가장 높은 디코딩 점수를 가진 대상 영역을 선택합니다. 모든 하이퍼파라미터와 모델은 few-shot/전체 검증 세트에서의 성능을 기반으로 그리드 탐색(grid search)을 통해 선택됩니다. 학습률은 이며, 학습의 끝(각각 few-shot은 500단계, 완전 감독 학습은 20,000단계)에 0으로 선형적으로 감소합니다. 배치 크기는 32이며, 완전 감독 및 few-shot 설정에서 샷 크기와 동일합니다. 이미지 영역 배치의 크기는 1입니다.
시각적 관계 검출(Visual Relation Detection). 하이퍼파라미터와 모델은 검증 세트에서 그리드 탐색을 통해 선택됩니다. 학습률은 이며, 학습의 끝(200단계)에 0으로 선형적으로 감소합니다. 배치 크기는 샷 크기와 동일합니다.
표 5: 비주얼 지놈 데이터셋(Visual Genome dataset)의 관계(Krishna et al. 2017). 일부 관계는 쿼리 템플릿에 더 잘 맞도록 이름이 변경되었습니다(괄호 안에 표시).
크로스모달 프롬프트 검색. 색상 텍스트 후보 집합 는 [en.wikipedia.org/wiki/Lists_of_colors] 에서 위키피디아(Wikipedia)를 통해 얻어집니다. 색상 외관 후보 집합 는 의 색상 텍스트 표준 RGB 주변에서 RGB 후보들을 그리드 탐색(grid searching)하여 얻어집니다. RGB 후보들을 그리드 탐색할 때, 각 채널에서 표준 RGB 주변으로 \pm 30 범위 내에서 5 단위로 탐색합니다. 디코딩 점수가 0.8 미만인 색상 후보들은 제외됩니다. 에서 특정 색상 선택은 few-shot/전체 검증 세트에서의 성능에 기반하여 결정됩니다. 우리 실험에서 사용된 최적의 색상은 제로샷(zero-shot)과 퓨샷(few-shot) 설정에서 투명도 값 0.5를 가진 , 레드(red)와 완전 감독 설정에서 투명도 값 0.45를 가진 , 핑크(pink)입니다.
D 실험 세부 사항
D.1 베이스라인 세부 사항
시각적 정착(visual grounding)을 위한 베이스라인 세부 사항을 제공합니다. (1) VinVL(Zhang et al. 2021)에 대한 바닐라(vanilla) 미세조정(fine-tuning). 이 모델은 CPT와 동일한 백본(backbone)을 채택하며, few-shot과 완전 감독 실험에서 가장 직접적인 베이스라인으로 작용합니다. Chen et al. (2020)을 따라, 모든 영역의 로짓(logits)은 소프트맥스(softmax) 층으로 입력되고, 대상 영역의 점수는 교차 엔트로피(cross-entropy) 목적 함수를 사용하여 최적화됩니다. (2) 다른 VL-PTM들에 대한 바닐라 미세조정. 완전 감독 실험에서, 우리는 ViLBERT(Lu et al. . 2019), VLBERT(Su et al. 2019), UNITER(Chen et al., 2020), ERNIE-ViL(Yu et al., 2021) 및 VL-T5(Cho et al., 2021)를 포함한 다른 VL-PTM들의 이전 미세조정 결과도 보고합니다. (3) 시각적 정착 모델. MAttNet(Yu et al. 2018)은 시각적 정착에 특화된 강력한 모델이며, 완전 감독 설정에서 비교됩니다. (4) 랜덤 베이스라인. 제로샷 실험에서, 우리는 대상 영역을 무작위로 추측하는 랜덤 베이스라인과 비교합니다. 공정한 비교를 위해, 우리는 모든 베이스라인과 CPT-Blk에 대해 MAttNet(Yu et al. 2018)에 의해 감지된 객체 제안들을 사용합니다.
D.2 데이터셋 세부 사항
시각적 기반 데이터셋. (1) RefCOCO (Yu et al., 2016)는 두 플레이어가 참여하는 참조 게임(Kazemzadeh et al. 2014)을 통해 수집되었으며, 19,994개의 이미지에서 50,000개의 객체 인스턴스에 대한 142,210개의 참조 표현을 포함하고 있습니다. 이 데이터셋은 훈련, 검증, 테스트 및 테스트B 세트로 나뉘며, 각각 120,624, 10,834, 5,657 및 5,095개의 표현-객체 쌍을 가지고 있습니다. 테스트A 세트는 대상 객체로 사람만 포함하는 반면, 테스트B 세트는 다른 모든 유형의 객체를 대상으로 합니다. (2) RefCOCO+ (Yu et al., 2016) 역시 상호작용적인 방식으로 수집되었으며, 19,992개의 이미지에서 49,856개의 객체 인스턴스에 대한 141,564개의 참조 표현을 포함하고 있습니다. RefCOCO와의 차이점은 RefCOCO+가 외모 기반 표현을 사용하여 객체를 구별하는 데 중점을 두고 위치 기반 표현은 제외한다는 것입니다. 이 데이터셋은 훈련, 검증, 테스트A 및 테스트B 세트로 나뉘며, 각각 120,191, 10,758, 5,726 및 4,889개의 표현-객체 쌍을 가지고 있습니다. (3) RefCOCOg (Mao et al. 2016)는 비상호작용적인 방식으로 수집되었으며, 25,799개의 이미지에서 49,822개의 객체 인스턴스에 대한 95,010개의 참조 표현을 포함하고 있습니다. RefCOCOg의 참조 표현은 일반적으로 더 길고 복잡합니다. 훈련, 검증 및 테스트 세트는 각각 80,512, 4,896 및 9,602개의 표현-객체 쌍을 포함하고 있습니다.
시각적 관계 탐지 데이터셋. 우리는 표 5에서 Visual Genome 데이터셋의 관계를 제공합니다. 이 데이터셋은 훈련, 검증 및 테스트 세트에서 각각 65,651, 5,000 및 32,422개의 이미지를 포함하고 있으며, 각 이미지는 평균적으로 10.3개의 객체와 4.8개의 라벨이 붙은 관계 인스턴스를 포함하고 있습니다. 데이터셋에는 150개의 독특한 객체 카테고리와 50개의 관계 카테고리가 있습니다.
E 토론 및 전망
이 섹션에서는 CPT의 한계와 미래 연구를 위한 유망한 방향에 대해 논의합니다.
제한 사항. 시각적 연결(visual grounding) 작업에서 유망한 성능을 보이는 CPT에도 불구하고 몇 가지 제한 사항이 있습니다: (1) 색상 교란(color disturbance). CPT는 이미지와 텍스트 모두에 색상 기반의 부가적인 프롬프트(sub-prompts)를 추가함으로써 색상을 이용해 시각적 및 텍스트 의미론을 연결하는 이점을 가집니다. 4.4절에서 보여주듯이, 색상 기반 프롬프트는 원본 이미지와 텍스트의 색상에 의해 교란될 수 있습니다. (2) 계산 효율성(computation efficiency). 실험에서 색상 교란을 최대한 피하고 색상 후보의 제한된 수를 고려하기 위해 작은 이미지 영역 배치 크기를 채택했습니다. 이는 데이터 인스턴스를 결과를 얻기 위해 여러 번 모델에 입력해야 함을 의미합니다. 이러한 도전 과제를 해결하는 것은 CPT를 개선하기 위한 유망한 방향이라고 생각합니다.
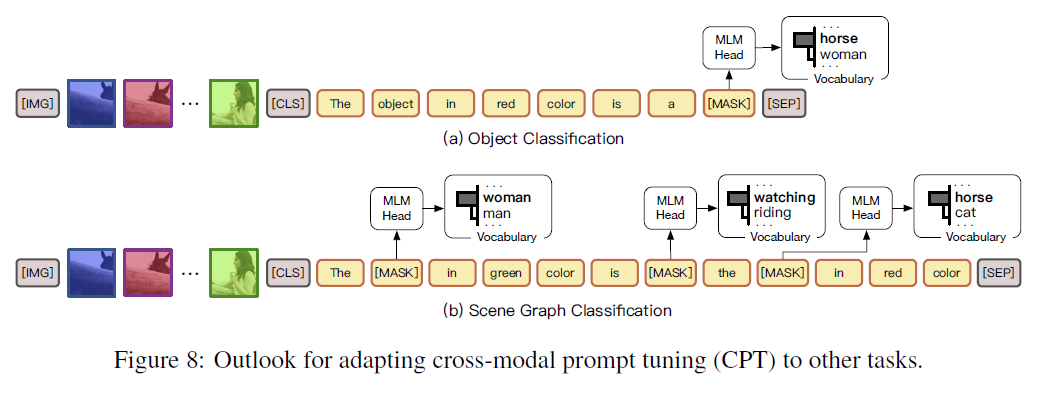
전망. 이 연구에서는 CPT의 효과를 보여주기 위해 시각적 연결을 대표적인 예로 들었습니다. 사실, CPT는 다른 시각-언어 작업(vision-language tasks)에 쉽게 적용될 수 있습니다. 여기서는 그림 8에 나와 있는 것처럼 유망한 방향을 논의합니다. CPT의 시각적 및 텍스트 부가적인 프롬프트는 객체 수준의 미세한 의미론을 잘 포착할 수 있어, 객체 수준 작업에 적합합니다. 예를 들어: (1) 객체 분류(Object classification). 시각적 부가적인 프롬프트로 객체 제안을 색칠함으로써, VL-PTMs(시각-언어 사전 훈련 모델)은 객체 분류를 위한 객체 레이블을 생성하도록 유도할 수 있습니다. (2) 장면 그래프 분류(Scene graph classification). 또한, 텍스트 부가적인 프롬프트를 더 분해함으로써, 다양한 하위 작업을 포함하는 복잡한 작업을 통합된 교차 모달 프롬프트 튜닝 프레임워크에서 해결할 수 있습니다. 예를 들어, VL-PTMs는 도전적인 장면 그래프 분류를 위해 객체와 술어 레이블을 함께 생성하도록 유도할 수 있습니다. 데이터 효율성 외에도, CPT를 사용하는 중요한 장점은 객체/술어 레이블을 고정된 레이블 세트가 아닌 개방형 세계 어휘(open-world vocabularies)에서 생성할 수 있다는 것입니다.