논문 번역
- 이 글은 제가 읽는 논문을 번역해서 올려놓는 공간입니다.
- 번역은 LLM(현재는 GPT-4)를 통해 번역하고 있습니다.
- 대략의 pipeline은 mathpix를 통해 ocr후 gpt-4로 대략 1000토큰 단위로 나누어 번역하고 있습니다. 논문->ocr을 통한 markdown으로 변경 -> markdown로 작성된 논문을 gpt-4 api로 번역 및 markdown으로 작성
- 현재까지 완성된 파이프라인은 https://github.com/aeolian83/paper_translator 입니다
- 원문 링크는 다음과 같습니다.
언어 모델 서비스를 위한 블랙박스 튜닝
Tianxiang Sun Yunfan Shao Hong Qian Xuanjing Huang Xipeng Qiu
초록(Abstract)
GPT-3과 같은 매우 큰 사전 훈련된 언어 모델(PTMs)은 보통 서비스로 제공됩니다. 이를 통해 사용자들은 특정 작업에 맞는 프롬프트를 설계하여 어떤 블랙박스 API를 통해 PTMs에 질의할 수 있습니다. 이러한 시나리오를 언어 모델 서비스(Language-Model-as-a-Service, LMaaS)라고 부릅니다. LMaaS에서는 PTMs의 그래디언트(gradient)가 일반적으로 사용할 수 없습니다. 모델 추론 API에만 접근하여 작업 프롬프트를 최적화할 수 있을까요? 이 논문은 미분이 필요 없는 최적화(derivative-free optimization)를 통해 입력 텍스트 앞에 추가된 연속적인 프롬프트를 최적화하기 위한 블랙박스 튜닝 프레임워크를 제안합니다. 전통적인 미분이 필요 없는 최적화에는 다루기 어려운 원래의 고차원 프롬프트 공간에서 최적화를 수행하는 대신, 큰 PTMs의 낮은 본질 차원성 때문에 무작위로 생성된 부분 공간에서 최적화를 수행합니다. 실험 결과는 RoBERTa를 사용한 블랙박스 튜닝이 몇 개의 레이블이 붙은 샘플에서만 수행되었음에도 불구하고 수동 프롬프트와 GPT3의 문맥 내 학습(in-context learning)을 크게 능가할 뿐만 아니라 그래디언트 기반 대응물, 즉 프롬프트 튜닝(prompt tuning)과 전체 모델 튜닝(full model tuning)까지도 능가한다는 것을 보여줍니다.
1. 서론(Introduction)
사전 훈련된 언어 모델(PTMs)의 확장은 NLP 작업의 광범위한 범위에서 점점 더 강력한 성능을 보여주고 있습니다(Devlin et al., 2019; Raffel et al., 2020; Brown et al., 2020; Fedus et al., 2021; Zhang et al., 2020; 2021b; Zeng et al., 2021; Sun et al., 2021; Qiu et al., 2020). 매우 큰 PTMs는 몇 개의 레이블이 붙은 샘플로 다양한 하류 작업(downstream tasks)에 쉽게 일반화할 수 있습니다(Brown et al., 2020). 그러나 이러한 큰 PTMs를 모두에게 유익하게 만드는 것은 도전적인 일입니다. 한편으로, 이러한 모델을 실행하는 것은 대부분의 사용자에게 매우 비싸거나 실현 불가능할 수 있습니다. 다른 한편으로, 모델 매개변수는 종종 상업적이유로 공개되지 않습니다.
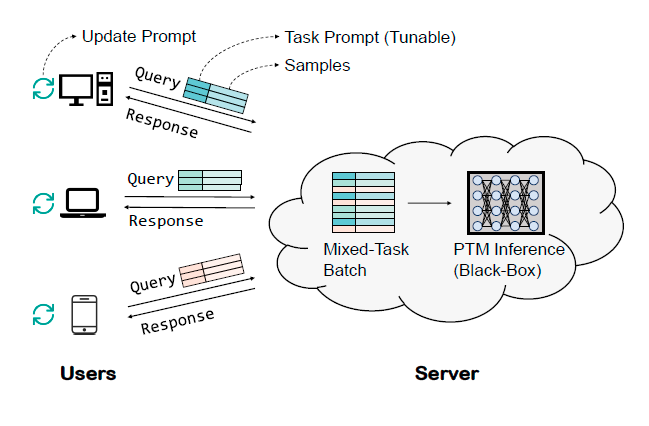
그림 1. 언어 모델 서비스(Language-Model-as-a-Service, LMaaS)의 개념도. 사용자는 블랙박스 API를 통해 서버에 배포된 PTM(Pre-trained Model)에 쿼리를 할 수 있습니다. 각 쿼리에서 사용자는 작업 프롬프트와 일련의 텍스트를 입력할 수 있습니다. 서버 측에서는 샘플을 큰 배치로 혼합하여 PTM에 공급할 수 있습니다. 블랙박스 API를 통해 PTM에 반복적으로 쿼리함으로써 사용자는 최적화를 거쳐 관심 있는 언어 작업을 해결하기 위한 좋은 프롬프트를 얻을 수 있습니다.
고려 사항과 오용의 잠재적 위험. 따라서 GPT-3(Brown et al., 2020), ERNIE 3.0(Sun et al., 2021), Yuan 1.0(Wu et al., 2021)과 같은 대형 PTM은 서비스로 출시되어 사용자가 블랙박스 API를 통해 이러한 강력한 모델에 접근할 수 있게 합니다.
이 시나리오에서는 언어 모델 서비스(LMaaS)라고 하며, 사용자는 블랙박스 API를 사용하여 작업 특정 텍스트 프롬프트를 만들거나 입력 텍스트에 학습 샘플을 포함시킴으로써(일명 인컨텍스트 학습(incontext learning) (Brown et al., 2020)) 관심 있는 언어 작업을 해결할 수 있습니다. API를 기반으로 하는 일반 목적의 PTM의 큰 힘 덕분에 이러한 접근 방식은 간단한 언어 작업에서 상당한 성능을 달성할 수 있으며, 따라서 많은 흥미로운 응용 프로그램을 구동하는 데 기여합니다 . 그러나 수작업으로 만든 텍스트 프롬프트를 통해 대형 PTM을 쿼리하는 것은 레이블이 지정된 데이터를 완전히 활용하지 못하여 많은 사용 사례에서 만족스럽지 못한 성능을 초래합니다.
이산 텍스트 프롬프트를 설계하는 대신, 최근에는 연속적인 프롬프트 튜닝(continuous prompt tuning) ( & Liang, 2021; Hambardzumyan et al., 2021; Liu et al.,[^1]2021b)에 많은 노력이 기울여졌습니다. 이는 PTM 매개변수를 고정한 상태에서 텍스트에 주입된 연속적인 프롬프트를 최적화하는 것입니다. 이러한 방법은 각 작업에 대해 작은 연속적인 프롬프트만 저장하면 되므로 배포 효율성이 매우 높습니다. 또한, PTM이 커질 때 연속적인 프롬프트를 튜닝하는 것은 모델 전체를 미세 조정하는 것만큼 효과적일 수 있습니다(Lester et al., 2021). 그러나 이전의 모든 방법에서 연속적인 프롬프트는 역전파(backpropagation)를 통해 학습되는데, 이는 LMaaS 시나리오에서는 사용할 수 없습니다.
PTM(Pre-trained Model) 추론 API에만 접근할 수 있을 때, 특정 작업에 맞는 연속적인 프롬프트(continuous prompts)를 최적화할 수 있을까요? 기울기(gradient)를 사용할 수 없기 때문에, 우리는 도함수가 없는 최적화(Derivative-Free Optimization, DFO) (Kolda et al., 2003; Conn et al., 2009; Rios & Sahinidis, 2013)를 호출할 수밖에 없습니다. DFO는 기울기에 의존하지 않고 샘플링된 해의 함수 값(또는 적합도 값)에만 의존하는 최적화 알고리즘의 한 종류입니다. 그러나 DFO 알고리즘은 검색 공간의 차원이 높을 때 느린 수렴 속도로 인해 알려져 있습니다. 따라서 수만 개의 매개변수를 가질 수 있는 연속적인 프롬프트조차도 DFO 알고리즘을 사용하여 최적화하는 것은 실현 불가능합니다.
다행히도, 최근의 연구에서는 많은 매개변수를 가진 일반적인 PTM들이 매우 낮은 본질적 차원수(Intrinsic Dimensionality)를 가지고 있다는 것을 발견했습니다 (Aghajanyan et al., 2021; Qin et al., 2021). 즉, 전체 매개변수 공간만큼 효과적인 저차원 재매개변수화(reparameterization)가 존재한다는 의미입니다. 수백 개(Aghajanyan et al., 2021) 또는 심지어 수십 개(Qin et al., 2021)의 매개변수만 최적화해도 비소미한(non-trivial) 성능을 달성할 수 있다는 것이 입증되었습니다. 목적 함수(우리의 경우 PTM의 전방 계산)의 본질적 차원수가 낮다면, 무작위 임베딩(random embedding)을 사용한 DFO 알고리즘을 통해 효과적으로 최적화 문제를 해결할 수 있습니다 (Wang et al., 2016; Qian et al., 2016; Letham et al., 2020).
이러한 통찰을 바탕으로, 본 논문은 PTM 추론 API에만 접근하여 다양한 언어 이해 작업을 해결하기 위한 BlackBox Tuning(BBT)을 제안합니다. 특히, 우리는 입력 텍스트에 앞서 붙는 연속적인 프롬프트를 PTM 추론 API를 반복적으로 쿼리하여 최적화하는 방법을 관리합니다. 이는 그림 1에서 간략하게 묘사되었습니다. 연속적인 프롬프트의 높은 차원성을 처리하기 위해, 우리는 원래의 프롬프트 공간을 무작위 선형 투영(random linear projection)을 사용하여 훨씬 더 작은 부공간(subspace)으로 투영하고, 그 작은 부공간에서 도함수가 없는 최적화기를 사용하여 이 최적화 문제를 해결합니다. 서비스 측에서만 수행할 수 있는 기존의 파인튜닝(finetuning) 방법과 달리, 블랙박스 튜닝(black-box tuning)은 사용자가 자원이 제한된 장치(심지어 GPU가 없는 경우에도)에서 특정 작업의 프롬프트를 로컬로 최적화할 수 있게 합니다. 우리의 실험 결과는 RoBERTaLARGE(Liu et al., 2019)를 BBT를 사용하여 프롬프트하는 것이 수동 프롬프트(manual prompt)와 인-컨텍스트 학습(in-context learning) (Brown et al., 2020)뿐만 아니라 그래디언트 기반의 대응물, 즉 프롬프트 튜닝(prompt tuning) (Lester et al., 2021)과 전체 모델 튜닝(full model tuning)보다도 뛰어난 성능을 보여준다는 것을 입증합니다.
이 논문의 기여는 세 가지로 요약됩니다:
- 이 논문은 추론 API만을 사용하여 사전 훈련된 모델(PTMs)에 프롬프트를 학습해야 하는 새로운 시나리오(LMaaS)를 제안합니다.
- 이 논문은 모델 매개변수와 그래디언트에 접근할 수 없는 상황에서 일반 언어 이해 작업을 수행하기 위한 해결책(BBT)을 제공하여 대규모 PTMs가 사용자에게 더 큰 혜택을 줄 수 있도록 합니다.
- 실증적 결과는 DFO가 수백만 개의 매개변수를 가진 대규모 PTMs에 프롬프트를 학습함으로써 실제 언어 작업을 성공적으로 처리할 수 있음을 보여줍니다. 따라서 이 연구는 DFO 방법을 통해 대규모 PTMs를 최적화하는 작업을 선도합니다.
2. Background
대규모 PTMs를 API로서. 대규모 PTMs를 일반 목적의 API를 제공함으로써 하류(downstream) 애플리케이션에 서비스하는 것은 유망한 방법입니다. 서비스 측면에서, PTM의 계산을 쉽게 사용할 수 있는 API로 래핑하는 것은 일반적인 관행이 되었습니다(Brown et al., 2020; Sun et al., 2021; Wu et al., 2021). 훈련과는 대조적으로, 대규모 PTMs의 추론 속도는 ORT와 TensorRT와 같은 가속 기술을 사용하여 크게 최적화될 수 있습니다. 또한, 대규모 PTMs는 상업적 이유와 오용의 잠재적 위험으로 인해 종종 오픈소스로 공개되지 않습니다. 사용자 측면에서, 대규모 PTMs가 사용 가능하더라도 이를 로컬에서 실행하는 것은 비용이 많이 들거나 실현 불가능할 수 있습니다. 따라서 PTM 추론 API를 활용하여 전통적인 언어 작업을 해결하는 방법은 유망한 방향입니다.
PTM의 본질적 차원성. 목적 함수의 본질적 차원성(intrinsic dimensionality)은 만족스러운 해결책을 얻기 위해 필요한 최소한의 매개변수 수를 의미합니다( et al., 2018). 특히, 본질적 차원성은 전체 매개변수 공간만큼 효과적인 최저 차원의 재매개변수화(reparameterization)를 나타냅니다. Li et al. (2018)은 신경망의 본질적 차원성을 측정하기 위해 전체 학습 가능한 매개변수에서 무작위로 투영된 부분공간의 최소 차원성을 찾는 방법을 제안합니다. 이 부분공간에서 신경망을 최적화하여 만족스러운 해결책을 얻을 수 있습니다. Aghajanyan et al. (2021)은 대규모 사전 학습(pre-training)이 자연어 처리(NLP) 하위 작업의 본질적 차원성을 암묵적으로 압축한다는 것을 경험적으로 보여줍니다. RoBERTa의 전체 매개변수 공간에 무작위로 투영된 수백 개의 매개변수만 조정하여 전체 모델 튜닝에 비해 의 성능을 달성할 수 있습니다. Qin et al. (2021)은 다중 작업 감독(multi-task supervision)을 통해 다양한 작업에서 본질적 부분공간을 100 차원 미만으로 압축할 수 있다는 것을 보여줍니다. 이 연구 분야는 매개변수 효율적 튜닝(parameter-efficient tuning)의 연구(Houlsby et al., 2019; Li & Liang, 2021; Lester et al., 2021; Sun et al., 2022; Hu et al., 2021a; He et al., 2021)와 함께, PTM이 매우 적은 비율의 매개변수를 조정함으로써 하위 작업에 잘 적응할 수 있음을 보여주며, 이는 대규모 PTM을 미분 없는 알고리즘(derivative-free algorithms)으로 최적화할 수 있는 가능성을 시사합니다.
프롬프트 기반 학습(Prompt-Based Learning). 프롬프트 기반 학습은 하위 작업을 (마스크된) 언어 모델링 작업으로 구성하여 PTM의 사전 학습과 미세 조정(fine-tuning) 사이의 격차를 줄이는 것입니다(Brown et al., 2020; Schick & Schütze, 2021a;b; Gao et al., 2021; Sun et al., 2022). 예를 들어, BERT(Devlin et al., 2019)를 사용하여 "This is a fantastic movie"라는 문장이 긍정적인지 부정적인지를 예측하기 위해 "It was [MASK]"라는 프롬프트를 추가하고 BERT가 마스크된 위치에서 "great" 또는 "terrible"을 예측하는지 확인할 수 있습니다. 프롬프트는 반드시 이산적일 필요는 없으며, 경사 하강법(gradient descent)을 사용하여 연속 공간에서도 효율적으로 최적화할 수 있습니다(Li & Liang, 2021; Hambardzumyan et al., 2021; Qin & Eisner, 2021; Liu et al., 2021b; Zhong et al., 2021). 대규모 PTM의 매개변수는 그대로 두고 연속적인 프롬프트만 조정하는 경우, 전체 모델 튜닝의 성능을 맞추면서도 효율적인 서비스 이점을 유지할 수 있습니다(Lester et al., 2021). 우리의 연구도 PTM 매개변수를 변경하지 않고 연속적인 프롬프트를 최적화하는 것을 제안하지만, 경사 하강법 없이 이루어집니다.
미분 없는 최적화(Derivative-Free Optimization, DFO). 미분 없는 최적화(DFO)는 샘플링된 해 에 대한 함수 값 만을 통해 최적화를 실현합니다. 대부분의 DFO 알고리즘은 해의 품질을 향상시키기 위해 샘플링과 업데이트라는 공통된 구조를 가지고 있습니다. 대표적인 DFO 알고리즘으로는 진화 알고리즘(Evolutionary Algorithms, Hansen et al., 2003), 베이지안 최적화(Bayesian Optimization, Shahriari et al., 2016) 등이 있습니다. 복잡한 최적화 작업을 다룰 수 있는 능력 덕분에, DFO 알고리즘은 자동 기계 학습(Automatic Machine Learning, Snoek et al., 2012), 강화 학습(Reinforcement Learning, Salimans et al., 2017; Hu et al., 2017), 목표 탐지(Objective Detection, Zhang et al., 2015b) 등에서 많은 인상적인 응용을 달성했습니다.
3. 접근 방법
3.1. 문제 정의
일반적인 언어 이해 과제는 분류 작업으로 정의될 수 있으며, 이는 일련의 입력 텍스트 에 대한 레이블 를 예측하는 것입니다. 일반 목적의 사전 훈련 모델(Pre-trained Model, PTM)을 사용하여 대상 언어 이해 과제를 해결하기 위해서는 를 어떤 템플릿(예: BERT와 같은 PTM을 위한 트리거 단어와 특수 토큰 [MASK] 추가)으로 수정하고 레이블 를 PTM 어휘 중 일부 단어에 매핑해야 합니다(예: 감정 레이블 "positive"를 "great"에 매핑). 수정된 입력과 레이블은 와 로 표시됩니다. BERT와 같은 PTM 추론 API 는 연속적인 프롬프트 와 일련의 수정된 텍스트 를 입력으로 받아, 마스크된 위치에 대한 로짓(logits)을 출력합니다. 즉, 입니다. 출력된 로짓을 사용하여 이 데이터 배치에 대한 손실을 계산할 수 있으며, 이는 반드시 미분 가능할 필요는 없습니다. 우리의 목표는 최적의 프롬프트 를 찾는 것이며, 여기서 는 관심 있는 어떤 검색 공간이고 은 음의 정확도와 같은 손실 함수입니다. 블랙박스 함수 는 최적화기에게 폐쇄형으로는 제공되지 않지만, 쿼리 포인트 에서 평가될 수 있습니다.
3.2. 블랙박스 튜닝
Lester et al. (2021)에 의해 입증된 바와 같이, 연속적인 프롬프트(continuous prompts)만을 조정할 때 경쟁력 있는 성능을 얻기 위해서는 수십 개의 프롬프트 토큰이 필요합니다. 대규모 사전 훈련 모델(PTMs)의 임베딩 차원이 보통 천 개 이상인 경우가 많습니다(예를 들어, RoBERTa LARGE의 단어 임베딩은 1024차원입니다), 우리가 최적화하고자 하는 연속적인 프롬프트 의 차원은 수만 개에 이를 수 있으며, 이는 미분 없는 최적화(derivative-free optimization)를 다루기 어렵게 만듭니다. 이러한 고차원 최적화를 처리하기 위해, 대규모 PTMs가 낮은 본질적 차원을 가지고 있다는 점(Aghajanyan et al., 2021; Qin et al., 2021)을 활용하여, 훨씬 작은 부분 공간(subspace) 에서 를 최적화하고, 무작위 투영 행렬(random projection matrix) 을 사용하여 를 원래의 프롬프트 공간 에 투영합니다.
PTM과 호환되는 프롬프트 공간에 를 직접 투영하는 것은 사소한 문제가 아닙니다. 최적화를 용이하게 하기 위해, 우리는 어떤 초기 프롬프트 의 증가분을 최적화합니다. 간단히 하기 위해, PTM 어휘에서 무작위로 개의 토큰을 초기화로 샘플링합니다. 따라서, 우리의 목표는 다음과 같습니다.
여기서 는 탐색 공간입니다. 이전 연구(Wang et al., 2016; Qian et al., 2016; Letham et al., 2020)에서 미분 없는 최적화는 보통 무작위 행렬 의 각 항목을 어떤 정규 분포에서 샘플링하여 설정합니다. 그러나 이 샘플링 전략은 우리 시나리오에서 잘 작동하지 않습니다. 대신, 우리는 et al. (2015)에서 채택된 균등 분포(uniform distribution)에서 샘플링하여 무작위 행렬 의 값을 설정합니다(비교는 부록 A 참조). 우리는 탐색 공간을 로 제한합니다.
손실 함수 에 대해서는, 직관적인 대안으로 부정확도(negative accuracy)를 사용하는 것입니다. 그러나 정확도의 보상은
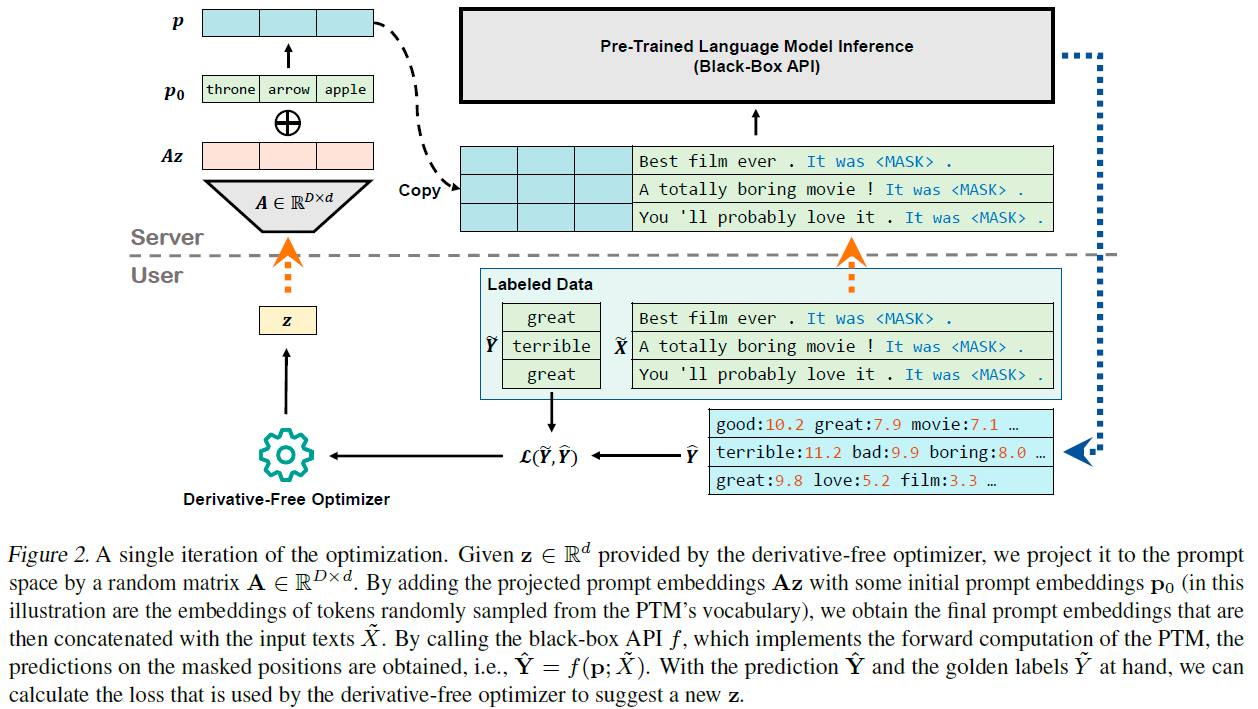
그림 2. 최적화의 단일 반복(iteration). 미분이 필요 없는 최적화기(derivative-free optimizer)에 의해 제공된 를 무작위 행렬 을 사용하여 프롬프트 공간으로 투영합니다. 투영된 프롬프트 임베딩 를 어떤 초기 프롬프트 임베딩 (이 예시에서는 PTM의 어휘에서 무작위로 샘플링된 토큰들의 임베딩)과 더함으로써, 최종 프롬프트 임베딩을 얻게 되며, 이는 입력 텍스트 와 연결됩니다. 블랙박스 API 를 호출하여, PTM의 전방 계산(forward computation)을 구현하고, 마스킹된 위치에 대한 예측을 얻게 됩니다. 즉, . 예측 와 정답 라벨 를 가지고 있으면, 미분이 필요 없는 최적화기가 새로운 를 제안하는 데 사용되는 손실을 계산할 수 있습니다.
훈련 데이터가 제한적일 때 특히, 희소하고 정보가 적은 경우가 많습니다. 따라서, 예측에 더 민감한 두 가지 손실 함수, 즉, 교차 엔트로피(cross entropy)와 힌지 손실(hinge loss)도 고려합니다. 후보 라벨 단어 집합에 대한 출력 로짓 과 특정 샘플의 정답 라벨 단어 가 주어졌을 때, 교차 엔트로피는 다음과 같이 정의됩니다.
힌지 손실의 경우, 다중 클래스 확장(multi-class extension)을 채택합니다 (Weston & Watkins, 1999),
이 연구에서는 마진 로 설정합니다. 교차 엔트로피, 힌지 손실, 그리고 부정확도(negative accuracy)를 사용한 성능은 그림 3에서 비교됩니다.
3.3. CMA 진화 전략(CMA Evolution Strategy)
Aghajanyan et al. (2021)에서 보여준 것처럼, RoBERTa 와 같은 사전 훈련된 모델(PTMs)의 다양한 작업에 대한 본질적 차원은 수백에 이를 수 있습니다. 이러한 규모의 최적화를 처리하기 위해, 우리는 연속 도메인에서 비볼록 블랙박스 최적화에 널리 사용되는 진화 알고리즘인 CMA-ES(공분산 행렬 적응 진화 전략)(Hansen & Ostermeier, 2001; Hansen et al., 2003)를 채택합니다.
특히, CMA-ES는 매개변수화된 탐색 분포 모델, 즉 다변량 정규 분포를 유지합니다. 각 반복에서, CMA-ES는 다변량 정규 분포 모델에서 새로운 쿼리 솔루션(개체 또는 자손으로도 불림)의 집단을 샘플링합니다.
여기서 이고 는 집단 크기입니다. 는 반복 단계 에서 탐색 분포의 평균 벡터이고, 는 단계 길이를 제어하는 전체 표준 편차이며, 는 분포 타원체의 형태를 결정하는 공분산 행렬입니다. 성공적인 단계의 가능성을 극대화함으로써, , 는 업데이트됩니다(Hansen (2016)을 참조하십시오).
3.4. 사전 훈련된 프롬프트 임베딩
문장 쌍 작업이 같은 템플릿과 레이블 단어를 공유할 수 있다는 점을 고려하여, 표 1에서 보여주듯이, 우리는 공개적으로 이용 가능한 NLI 작업(우리의 실험에서는 MNLI (Williams et al., 2018) 훈련 세트를 사용)에서 프롬프트 임베딩 을 사전 훈련하여 더 나은 초기화를 할 수 있습니다. 다른 분류 작업의 경우, 우리는 을 RoBERTa LARGE의 어휘에서 무작위로 추출된 단어 임베딩으로 설정합니다.
4. 실험
4.1. 설정
데이터셋. 우리는 감정 분석, 주제 분류, 자연어 추론(NLI)을 포함한 여러 공통 언어 이해 작업에서 실험을 수행합니다.
표 1. 우리 실험에서 사용된 통계, 수동 템플릿, 그리고 레이블 단어들. : 클래스의 수.
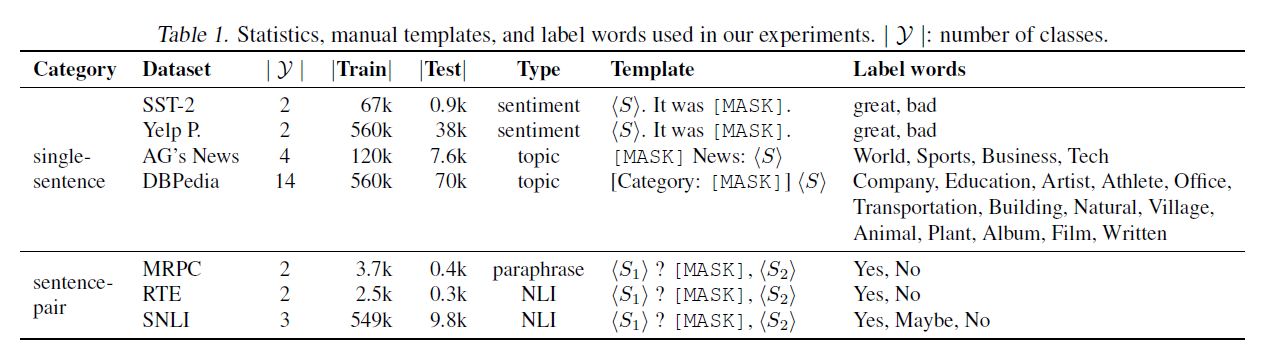
감정 분석(sentiment analysis)을 위해, 우리는 SST2(Socher 외, 2013)와 Yelp 극성(Yelp polarity)(Zhang 외, 2015a)을 선택했습니다. 주제 분류(topic classification)를 위해, 우리는 AG's News와 DBPedia(Zhang 외, 2015a)를 선택했습니다. 자연어 추론(NLI, Natural Language Inference)을 위해, 우리는 SNLI(Bowman 외, 2015)와 RTE(Wang 외, 2019)를 선택했습니다. 문장 재구성(paraphrase)을 위해, 우리는 MRPC(Dolan & Brockett, 2005)를 선택했습니다. 이 데이터셋들의 통계, 수동 템플릿, 그리고 레이블 단어는 표 1에 나타나 있습니다.
소수샷 설정(Few-Shot Setting). 많은 사용자들에게 레이블이 붙은 데이터의 양은 제한적일 수 있으며, 이 경우 그들은 소수샷 학습(few-shot learning)의 큰 능력 때문에 배포된 대형 사전 훈련 모델(PTMs, Pre-trained Models)에 의존할 수 있습니다(Brown 외, 2020). 따라서, 이 논문에서는 소수샷 설정에서 실험을 진행합니다. 우리는 각 클래스별로 개의 샘플을 무작위로 선택하여 -샷 훈련 세트 을 구성하고, 원래 훈련 세트에서 또 다른 개의 샘플을 무작위로 뽑아 개발 세트 를 구성하며, 를 보장하여 진정한 소수샷 학습 설정을 모방합니다(Perez 외, 2021). Zhang 외(2021a), Gao 외(2021), 그리고 Gu 외(2021)를 따라, 우리는 원래의 개발 세트를 테스트 세트로 사용합니다. 개발 세트가 없는 데이터셋의 경우, 원래의 테스트 세트를 사용합니다. 따라서, 우리의 실험에서 입니다.
백본 모델(Backbone Model). 우리는 다음과 같은 이유로 RoBERTa (Liu 외, 2019)를 백본 모델로 선택했습니다: (1) 우리는 주로 언어 이해 작업(language understanding tasks)에 초점을 맞추고 있습니다; (2) Aghajanyan 외(2021)는 RoBERTa LARGE 가 많은 작업에서 매우 작은 본질적 차원성(intrinsic dimensionality)(약 수백)을 가지고 있음을 보여주었습니다. 생성적 PTMs(Generative PTMs)인 GPT(Brown 외, 2020), T5(Raffel 외, 2020), 그리고 BART(Lewis 외, 2020)도 하류 작업(downstream tasks)을 통일된 텍스트-투-텍스트 형식(text-to-text format)으로 변환한다면 우리의 프레임워크와 호환될 수 있다는 점을 지적하는 것이 가치가 있습니다. 생성적 PTMs의 응용은 미래의 작업으로 남겨두겠습니다.
기준선. 우리는 제안하는 블랙박스 튜닝(black-box tuning)을 두 가지 방법과 비교합니다: 기울기 기반 방법(gradient-based methods)과 기울기 없는 방법(gradient-free methods). 기울기 기반 방법에 대해, 우리는 세 가지 기준선을 고려합니다: (1) 프롬프트 튜닝(Prompt Tuning): Lester et al. (2021)을 따라, 우리는 연속적인 프롬프트만을 훈련합니다.
표 2. 하이퍼파라미터의 기본 설정.

입력 텍스트에 연속적인 프롬프트를 추가하면서 PTM(Pre-trained Model)은 고정된 상태로 유지합니다. 우리는 학습률이 이고 배치 크기가 16인 Adam 최적화기(Kingma & Ba, 2015)를 사용하여 1000 에포크(epoch) 동안 학습합니다. 공정한 비교를 위해, 우리는 문장 쌍 작업에 대한 블랙박스 튜닝(black-box tuning)과 동일한 프롬프트 길이, 수동 템플릿, 레이블 단어, 그리고 사전 훈련된 프롬프트 임베딩을 초기화에 사용합니다. (2) P-Tuning v2 (Liu et al., 2021a)는 프롬프트 튜닝(prompt tuning)의 개선된 변형입니다. 입력 레이어에 연속적인 프롬프트를 단순히 삽입하는 대신, P-Tuning v2는 PTM의 모든 레이어에 연속적인 프롬프트를 추가하고 최적화합니다. 우리는 각 레이어에서 길이가 128인 프롬프트를 학습률이 이고 배치 크기가 32인 Adam 최적화기로 2000 에포크 동안 최적화합니다. (3) 모델 튜닝(Model Tuning): 우리는 각 작업에 대해 전체 PTM을 학습률이 이고 배치 크기가 16인 Adam 최적화기로 200 에포크 동안 미세 조정(fine-tune)합니다. 경사 기반 방법이 아닌 경우, 우리는 세 가지 기준선을 고려합니다: (1) 수동 프롬프트(Manual Prompt): 우리는 표 1의 템플릿과 레이블 단어를 직접 사용하여 제로샷 평가(zero-shot evaluation)를 수행합니다. 수동 프롬프트의 결과는 우리 방법의 초기 지점으로 볼 수 있습니다. (2) 인컨텍스트 학습(In-context Learning): Brown et al. (2020)을 따라, 우리는 최대 32개의 훈련 샘플을 무작위로 선택하고 입력 텍스트와 연결합니다. (3) 특징 기반 방법(Feature-based Methods): 특징 기반 방법(Peters et al., 2019)도 LMaaS(Large Model as a Service)에 대한 경쟁력 있는 기준선으로, 여기서는 대규모 PTM에 의해 인코딩된 특징을 요청하고 로컬로 분류기를 학습하여 관심 있는 작업을 수행할 수 있습니다. 여기서 우리는 두 가지 구현을 고려합니다: (a) 특징-MLP(Feature-MLP): 우리는 PTM의 [CLS] 표현에 대해 두 층의 MLP 분류기를 학습합니다. (b) 특징-BiLSTM(Feature-BiLSTM): 우리는 토큰의 시퀀스 표현에 대해 양방향 LSTM(Hochreiter & Schmidhuber, 1997)을 학습한 다음, 그 위에 선형 분류기를 학습합니다. 특징 기반 방법의 두 구현 모두, 우리는 학습률이 이고 배치 크기가 16인 Adam 최적화기를 사용하여 1000 에포크 동안 붙어 있는 분류기를 학습합니다. 블랙박스 튜닝에 대해, 우리는 표 2에서 우리 실험에서 사용된 하이퍼파라미터의 기본 구성을 제공합니다. 각 하이퍼파라미터의 효과는 에서 탐구됩니다.
4.2. 결과
전체 비교. 우리는 먼저 표 3에서 7개 데이터셋에 걸친 블랙박스 튜닝(black-box tuning)과 기준선(baselines)의 실험 결과를 보여줍니다. 제안된 블랙박스 튜닝은 다른 네 가지 기울기 없는 방법(gradient-free methods)보다 현저하게 뛰어난 성능을 보입니다. 우리는 인컨텍스트 학습(in-context learning)이 일부 작업에서는 수동 프롬프트(manual prompt)보다도 더 나쁜 성능을 보이며, 높은 변동성(variance)을 겪는다는 것을 관찰했습니다. 이는 인컨텍스트 학습이 컨텍스트에 포함된 레이블이 붙은 샘플들을 효과적으로 활용하지 못한다는 것을 의미합니다. 특징 기반 방법(feature-based methods)은 수동 프롬프트와 인컨텍스트 학습보다 약간 더 나은 성능을 보입니다. 한편, Feature-BiLSTM은 더 유익한 특징들을 사용하는 이점 때문에 Feature-MLP보다 뛰어납니다. 놀랍게도, 블랙박스 튜닝은 그것의 기울기 기반 대응물(gradient-based counterparts), 즉 프롬프트 튜닝(prompt tuning), p-튜닝 v2(p-tuning v2), 그리고 모델 튜닝(model tuning)을 평균적으로 7개 작업의 성능에서도 능가합니다. 프롬프트 튜닝과 블랙박스 튜닝 사이의 유일한 차이점은 기울기 하강(gradient descent, 즉 Adam 최적화기(optimizer))을 사용하는지 아니면 DFO 알고리즘(DFO algorithm, 즉 CMA-ES)을 사용하는지 여부입니다. 실험 결과를 바탕으로, 우리는 기울기 기반 최적화가 작은 훈련 데이터에 과적합(overfit)하는 경향이 있는 반면, DFO는 탐색 메커니즘(exploration mechanism) 덕분에 더 나은 해결책을 찾는 경향이 있다고 의심합니다. 또한, 클래스 수가 많을 때(예: DBPedia), 모델 튜닝이 프롬프트 튜닝과 블랙박스 튜닝보다 훨씬 더 나은 성능을 보인다는 것을 발견했습니다. NLI 작업(즉, SNLI와 RTE)에서 사전 훈련된 프롬프트 임베딩( )을 사용할 때, 프롬프트 튜닝과 블랙박스 튜닝은 모델 튜닝을 크게 능가하는데, 이는 블랙박스 튜닝의 맥락에서 프롬프트 사전 훈련(Gu et al., 2021)의 효과를 또한 확인시켜 줍니다.
자세한 비교. LMaaS(Language Model as a Service) 시나리오에서는 고려해야 할 많은 다른 요소들이 있습니다. 표 4에서는 배포 효율성, 서비스로서의 실행 가능성, 학습 시간, 사용자 측과 서버 측의 메모리 사용량, 그리고 업로드 및 다운로드해야 하는 데이터의 양 측면에서 블랙박스 튜닝(black-box tuning)과 기준 방법들을 비교합니다. 모델 튜닝(model tuning)은 각 사용자마다 전체 모델의 복사본을 유지해야 하기 때문에 배포 효율성이 떨어집니다. 그래디언트 기반 방법(gradient-based methods)은 그래디언트의 요구로 인해 PTM(Pre-trained Model)을 서비스로 제공할 수 없습니다. 특징 기반 방법(feature-based methods)과 블랙박스 튜닝은 LMaaS에 적합합니다. 그러나 특징 기반 방법은 레이블이 지정된 데이터가 제한적일 때 경쟁력 있는 결과를 달성할 수 없습니다. 따라서 고려된 모든 방법 중에서 블랙박스 튜닝만이 합리적인 학습 시간, 메모리 사용량, 그리고 네트워크 부하를 유지하면서 만족스러운 성능을 달성할 수 있습니다. 그래디언트 기반 방법과 달리, PTM의 크기에 비례하는 최적화 비용을 가지는 것이 아니라, 블랙박스 튜닝의 최적화 비용은 PTM의 규모와 분리되어 있으며, 오직 부공간 차원(subspace dimensionality)에만 의존합니다. 학습 시간의 공정한 비교를 위해, 비교되는 모든 방법들에 대해 조기 종료(early stopping)를 수행합니다. 즉, 개발 정확도(development accuracy)가 1000단계 후에 증가하지 않으면 학습을 중단합니다. 모든 방법들은 PyTorch(Paszke et al., 2019)로 구현되었으며 단일 NVIDIA GTX 3090 GPU에서 실험되었습니다. 모델 추론 과정은 더 나은 구현(예: ONNX와 TensorRT 사용)을 통해 더욱 가속화될 수 있습니다. 표 4에서는 ONNX Runtime을 사용한 블랙박스 튜닝의 학습 시간도 보고합니다. 업로드/다운로드해야 하는 데이터의 양에 대한 자세한 계산은 부록 C에서 찾을 수 있습니다.
4.3. 소거 연구(Ablation Study)
이 섹션에서는 다양한 하이퍼파라미터(hyper-parameters)에 대한 소거 실험을 수행합니다. 실험 변수를 통제하기 위해, 표 2에 나열된 기본값으로 다른 하이퍼파라미터들을 유지하면서 각 하이퍼파라미터의 영향을 탐구합니다. 실험 결과의 안정성을 높이고 다른 실행 간의 변동성을 줄이기 위해, 64샷(64-shot) 설정에서 소거 실험을 수행합니다. 각 실행은 다른 랜덤 시드(random seeds)를 사용하여 동일한 데이터 분할에서 수행됩니다. 손실 함수 , 부공간 차원 , 그리고 프롬프트 길이 에 대한 소거 실험 결과는 그림 3에서 보여집니다. 랜덤 프로젝션 의 영향, 인구 크기 의 영향, 그리고 16샷(16-shot) 설정에서의 추가적인 소거 연구는 부록 A에서 확인할 수 있습니다.
각각의 제거 실험(ablation)에 대해, 우리는 PTM(Pre-trained Models) 추론 API 호출 횟수로 측정되는 다양한 예산 하에서의 결과를 보여줍니다. 각 API 호출에서, 연속적인 프롬프트(p)를 제공하고 훈련 데이터 배치에 대한 PTM의 순방향 계산 결과를 요청할 수 있습니다. 우리의 소수샷(few-shot) 설정에서는 모든 훈련 데이터를 하나의 배치로 넣을 수 있으므로, 최적화할 목표 함수는 확률적이 아닌 결정론적입니다.
CMA-ES 대 Adam. 우리는 사용한 무도함수 최적화기(derivative-free optimizer), CMA-ES를 경쟁력 있는 일차 최적화기(first-order optimizer), Adam(Kingma & Ba, 2015)과 비교합니다. 공정한 비교를 위해, 우리는 전체 훈련 데이터에 대한 그래디언트(gradients)를 사용하여 Adam으로 연속 프롬프트를 업데이트합니다(즉, 배치 크기는 와 같습니다). Adam 최적화기(optimizer)에 대해 의 학습률(learning rate)을 사용합니다. 그림 3의 상단 행에서 보여지듯이, Adam 최적화기는 사용된 그래디언트 덕분에 SST-2와 AG's News 모두에서 더 빠른 수렴을 달성합니다. 개발 세트(development sets)에서, Adam은 SST-2에서는 CMA-ES와 교차 엔트로피(cross entropy)를 사용할 때 약간 떨어지는 성능을 보이지만 AG's News에서는 더 좋은 성능을 보입니다. 그러나 표 3에서 보여지듯이, Adam 최적화기를 사용하는 것은 일곱 가지 작업 테스트 세트들(test sets)에 걸친 평균 성능에서 CMA-ES보다 나쁜 성능을 보입니다.
표 3. 다양한 언어 이해 작업(language understanding tasks)에 대한 전반적인 비교. 우리는 3개의 다른 분할(splits)에 대한 성능의 평균과 표준 편차를 보고합니다( . 모든 결과는 클래스 당 16샷(16-shot) 설정에서 사전 훈련된 RoBERTa 를 사용하여 얻은 것입니다.
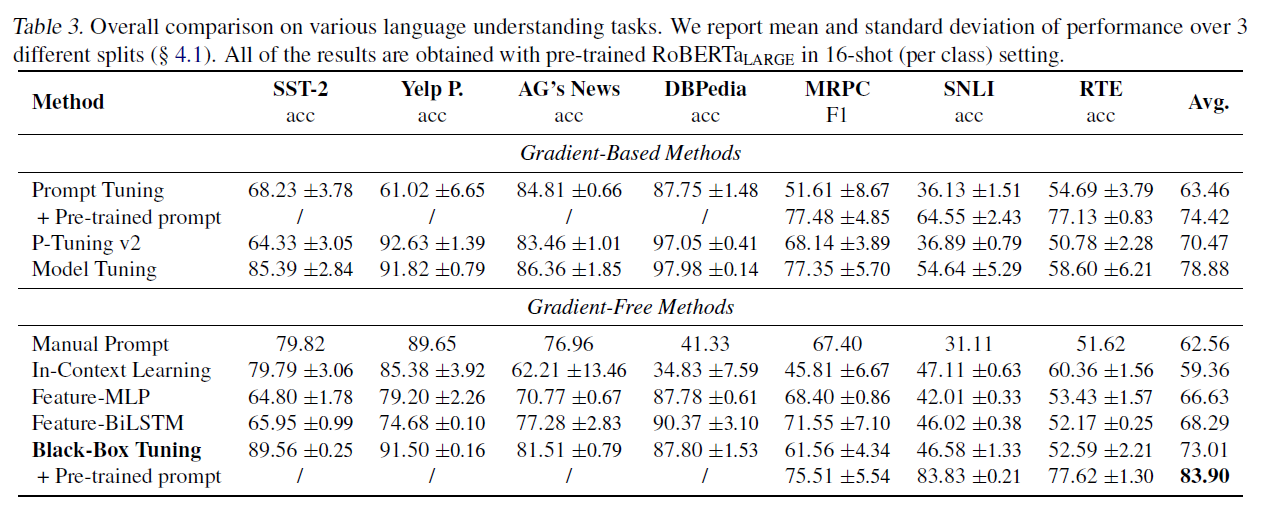
표 4. 배포 효율성, 서비스로서의 가능성(as-a-service viability), 테스트 정확도(test accuracy), 학습 시간(training time), 메모리 사용량(memory footprint), 그리고 업로드/다운로드해야 하는 데이터 양의 비교입니다. 는 ONNX Runtime을 사용한 구현의 학습 시간을 나타냅니다. 비교된 모든 방법들은 SST-2와 AG's News의 동일한 16-shot 분할에서 수행되었습니다.
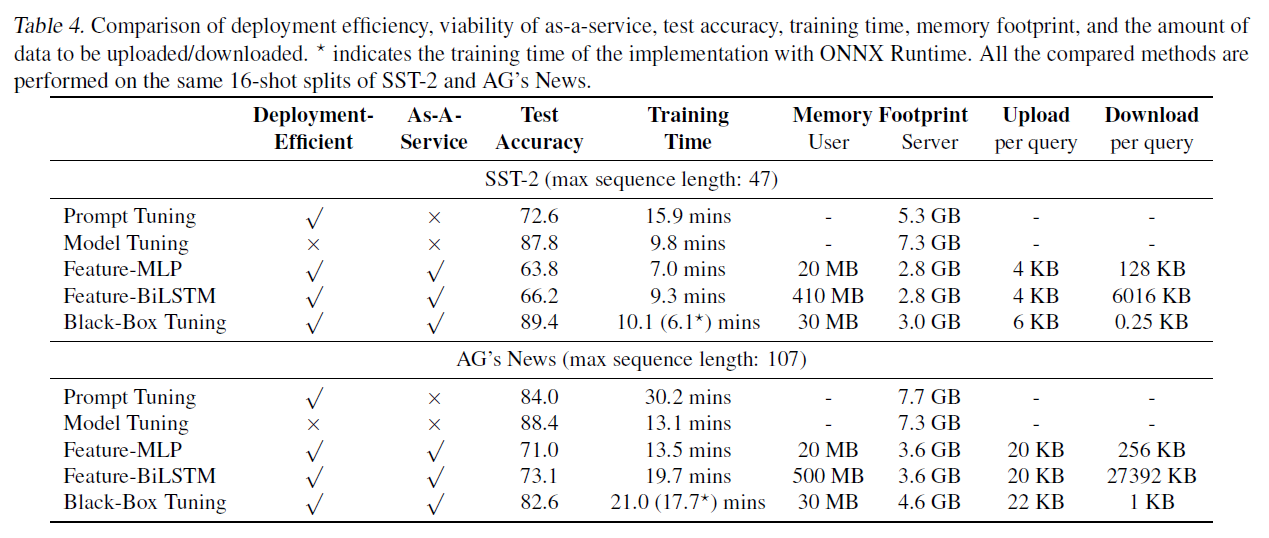
손실 함수. 우리는 교차 엔트로피(cross entropy), 힌지 손실(hinge loss), 그리고 부정확도(negative accuracy) 세 가지 손실 함수를 고려합니다. 그림 3의 상단 행에 나타난 바와 같이, 교차 엔트로피와 힌지 손실은 부정확도보다 훨씬 뛰어난 성능을 보입니다. 소수샷 학습(few-shot setting)에서 정확도를 보상으로 사용하는 것은 희소할 수 있으며, 최적화를 위한 유익한 방향을 제공하지 못할 수 있습니다. SST2와 AG's News에서, 교차 엔트로피가 힌지 손실보다 약간 더 나은 성능을 보인다는 것을 확인했습니다.
부공간 차원성(Subspace Dimensionality). 차원 의 부공간은 실제로 최적화가 수행되는 공간입니다. Aghajanyan et al. (2021)에서 발견된 본질적 차원성(intrinsic dimensionality)에 따라, 우리는 의 예산 내에서 의 부공간 차원성을 탐색합니다. 따라서, 우리는 인구 크기 를 설정합니다. 그림 3의 중간 행에 나타난 바와 같이, 최적의 부공간 차원성은 다른 작업에 따라 다를 수 있습니다(이 SST-2 개발 세트에서 가장 좋은 성능을 보이고, 이 AG's News 개발 세트에서 가장 좋은 성능을 보임), 이는 다양한 작업에서 본질적 차원성이 다르다는 관찰과 관련이 있습니다(Aghajanyan et al., 2021). 일반적으로, 작은 부공간(예: )은 좋은 해결책을 찾기 어렵고, 큰 부공간(예: )은 일반화 성능이 떨어질 수 있습니다.
프롬프트 길이(Prompt Length). 프롬프트 길이 은 원래 매개변수 공간의 차원성을 결정합니다(우리의 경우 ). 우리는 의 각 예산 하에서 프롬프트 길이를 으로 변화시키며 블랙박스 튜닝(black-box tuning)을 평가합니다. 그림 3의 하단 행에 나타난 바와 같이, 짧은 프롬프트는 훈련 세트에서 빠른 수렴을 가져오지만 개발 세트에서 더 나은 일반화를 제공하지는 않습니다. 은 SST-2와 AG's News 개발 세트 모두에서 최고의 정확도를 달성합니다.
그림 3. 손실 함수, 부공간 차원성, 프롬프트 길이에 대한 연구. 우리는 다른 랜덤 시드로 3번 실행한 성능의 평균과 표준 편차를 보여줍니다. 랜덤 투영과 인구 크기에 대한 연구는 부록 A에서 찾을 수 있습니다.
5. 토론 및 미래의 연구
이 섹션에서는 (1) 미분 없는 최적화(derivative-free optimization)와 (2) 프롬프트 기반 학습(prompt-based learning)의 맥락에서 제안하는 방법에 대해 논의합니다. 이 두 연구 분야와의 비교를 통해, 향후 이 작업을 개선할 수 있는 몇 가지 방향을 강조합니다.
이전 미분 없는 접근법과의 비교. 우리가 제안하는 방법은 고차원 미분 없는 최적화 문제를 랜덤 임베딩(random embedding)을 통해 해결하는 이전 연구들의 틀 안에 있습니다(Wang et al., 2016). 반면에, 우리는 정규 분포(normal distributions) 대신 균등 분포(uniform distribution)에서 샘플링하여 랜덤 임베딩 를 설정하고, 생성된 부공간(subspace)에서 최적화를 수행하기 위해 CMA-ES를 사용합니다. 이전 연구에서는 대상 블랙박스 함수(blackbox functions)가 주로 몇 개의 차원만이 함수 값에 영향을 미칠 수 있는 합성 함수(synthetic functions)이며, 따라서 대부분의 차원은 엄격하게 비효과적(non-effective)입니다. 우리의 실제 시나리오에서는 본질적인 차원(intrinsic dimension)이 대략적일 수 있습니다. PTM(Pre-trained Models)의 맥락에서 본질적인 차원성(intrinsic dimensionality)에 대한 더 적절한 대체 용어는 -효과적 차원성(-effective dimensionality)일 수 있습니다(Qian et al., 2016). PTM의 본질적인 차원성에 대한 완화를 고려할 때, 순차적 랜덤 임베딩(sequential random embedding)(Qian et al., 2016)과 랜덤 투영 행렬(random projection matrix)을 구성하는 다른 더 진보된 방법들(Letham et al., 2020)이 향후 연구에서 탐색되어야 합니다. 또한, 랜덤 투영에 의해 생성된 부공간은 최적이 아닐 수 있습니다. Qin et al. (2021)에서 보여준 것처럼, 다중 과제 감독(multitask supervision)으로 투영 A를 훈련시키면 더 나은 그리고 더 작은 부공간을 얻을 수 있습니다. 또한, 일반적으로 더 큰 PTM은 더 낮은 본질적 차원성을 가지고 있습니다(Aghajanyan et al., 2021), 결과적으로, 우리는 더 큰 PTM에서 더 작은 부공간과 더 효율적인 DFO 알고리즘들, 예를 들어 베이지안 최적화(Bayesian optimization)를 사용할 수 있습니다.
이전 프롬프트 기반 학습과의 비교
프롬프트 기반 학습(prompt-based learning)의 관점에서 볼 때, 우리의 방법은 프롬프트 튜닝(prompt-tuning) (Lester et al., 2021)과 유사합니다. 여기서는 입력 텍스트에 앞서 붙는 연속적인 프롬프트만을 조정하므로, 우리의 방법 또한 효율적인 서빙과 혼합 작업 추론의 이점을 유지합니다. 연속적인 프롬프트 외에도, 우리는 입력 텍스트에 몇 가지 하드 프롬프트 토큰들(예: "It was [MASK]")을 삽입하는데, 이는 이전 연구(Gu et al., 2021)에서 하이브리드 프롬프트 튜닝(hybrid prompt tuning)이라는 이름으로 효과가 있음이 입증되었습니다. 이전의 프롬프트 기반 학습 접근법들과 다르게, 우리의 프롬프트 튜닝은 역전파(backpropagation)와 경사 하강법(gradient descent)을 요구하지 않습니다. 우리가 사용한 템플릿과 레이블 단어들이 시행착오 없이 수작업으로 만들어졌기 때문에, 이 논문에서 보고된 성능은 단지 하한선(lower bound)입니다. 프롬프트 엔지니어링(prompt engineering) (Gao et al., 2021), 레이블 단어 엔지니어링(label words engineering) (Schick et al., 2020; Shin et al., 2020; Hu et al., 2021b), 프롬프트 사전 훈련(prompt pre-training) (Gu et al., 2021), 그리고 프롬프트 앙상블(prompt ensembling) (Lester et al., 2021)과 같은 더 발전된 기술들은 이 연구와 직교(orthogonal)하므로 성능을 더욱 향상시킬 수 있습니다. 단순함을 위해, 우리는 이러한 방법들을 통합하지 않고 미래의 연구로 남겨둡니다.
감사의 글
저자들은 이 방법과 논문의 발표에 대한 귀중한 제안을 해준 Yang Yu에게 감사를 표하며, 건설적인 코멘트를 해준 익명의 리뷰어들에게도 감사드립니다. 이 연구는 중국 국가 중점 연구 개발 프로그램(National Key Research and Development Program of China) (번호 2020AAA0108702), 중국 국가 자연 과학 재단(National Natural Science Foundation of China) (번호 62022027), PCL의 주요 중점 프로젝트(major key project of PCL) (번호 PCL2021A12), 그리고 상하이 자연 과학 재단(Natural Science Foundation of Shanghai) (번호 21ZR1420300)에 의해 지원받았습니다.
A. 추가 실험 결과(Additional Experimental Results)
랜덤 투영(Random Projection). 랜덤 투영 행렬 는 생성된 부공간(subspace)에서 좋은 해를 찾는 것이 가능한지, 그리고 얼마나 어려운지를 결정하는 핵심 요소입니다. 여기서 우리는 A를 설정하는 두 가지 설계 선택을 비교합니다: 첫 번째 선택은 이전의 고차원 무도함수 최적화(derivative-free optimization) 연구(Wang et al., 2016; Qian et al., 2016)에서 흔히 사용되며, 의 각 항목을 정규 분포(normal distribution)에서 샘플링하여 설정하는 것입니다. Qian et al. (2016)을 따라, 우리는 부공간 차원 에 대해 를 사용합니다. 두 번째 선택은 의 각 항목을 균등 분포(uniform distribution)에서 샘플링하여 설정하는 것으로, 현대 신경망의 선형 층을 초기화하는 데 널리 사용됩니다. 여기서 우리는 He et al. (2015)에서 제안한 균등 분포를 사용합니다. 그림 4에서 보여지듯이, 두 랜덤 투영 모두 SST-2와 AG's News에서 합리적인 예산 내에서 상당한 교차 엔트로피 손실(cross entropy loss)을 달성할 수 있지만, 균등 분포를 사용할 때 더 빠른 수렴을 얻을 수 있습니다.
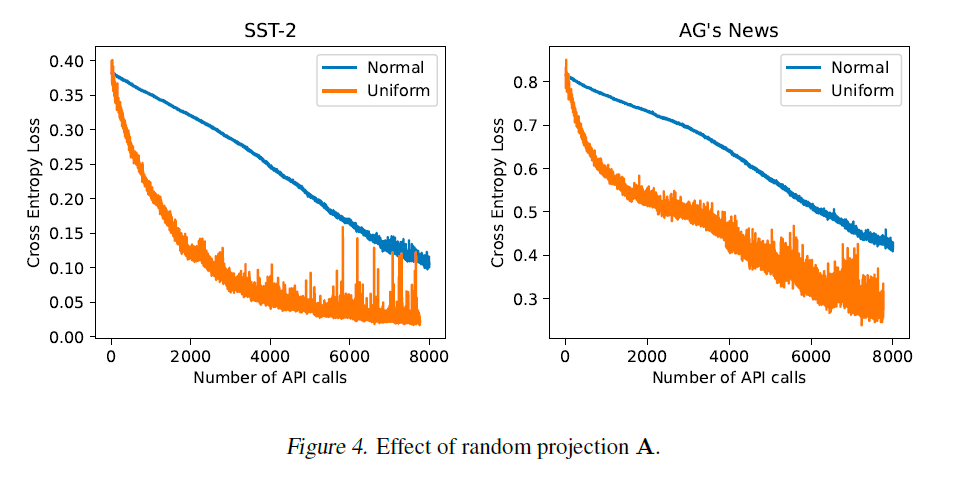
그림 4. 랜덤 투영 A의 효과.
인구 크기(Population Size). CMA-ES의 각 반복에서, 해결책들의 집단(population)은 다변량 정규 분포 모델(multivariate normal distribution model)에서 샘플링됩니다. 그런 다음 집단의 평가를 사용하여 다변량 정규 분포 모델의 매개변수를 업데이트합니다. 여기서 우리는 SST-2에서 인구 크기의 효과를 연구합니다. 우리의 실험에서, 우리는 집단 내의 각 해결책을 순차적으로 평가하므로, 더 큰 인구 크기는 동일한 CMA-ES 반복을 가진 상태에서 더 많은 API 호출을 초래할 것입니다. 그림 5에서 보여지듯이, 더 작은 인구 크기는 API 호출 수 측면에서 더 빠른 수렴을 제공합니다. 우리는 또한 CMA-ES 반복 측면에서의 비교를 보여주며, 이는 다음 섹션에서 찾을 수 있습니다.
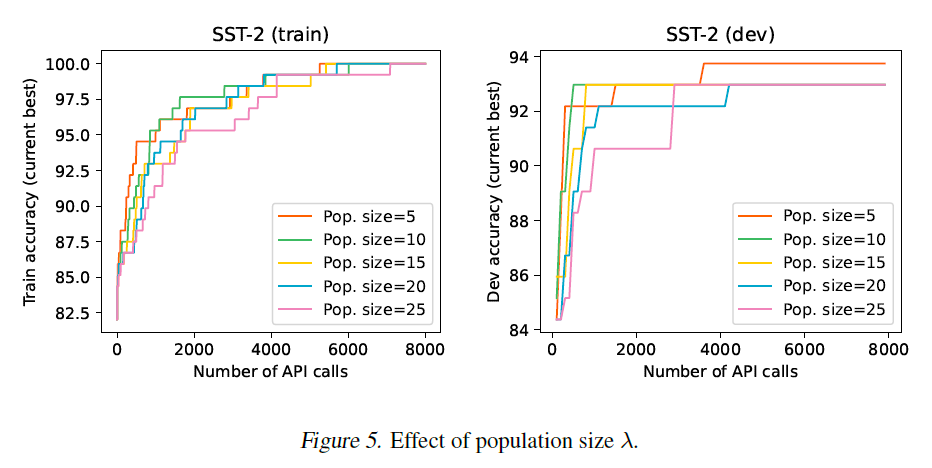
그림 5. 인구 크기 의 효과.
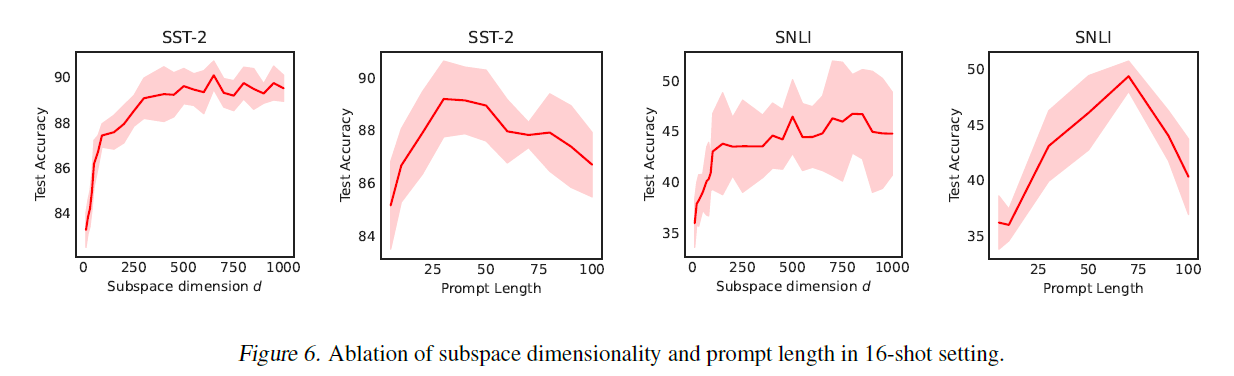
그림 6. 16샷 설정에서 부공간 차원과 프롬프트 길이의 소거 연구.
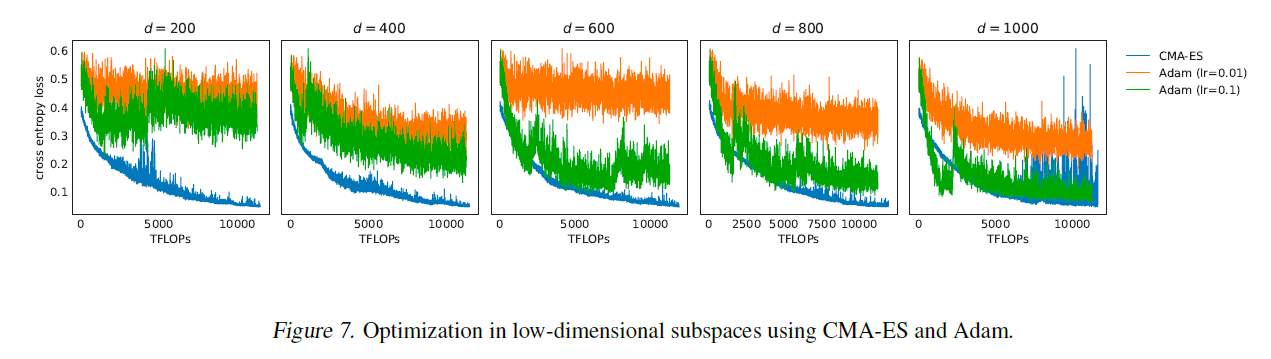
그림 7. CMA-ES와 Adam을 사용한 저차원 부공간에서의 최적화.
초록(Abstract)
16샷 설정에서 부공간 차원과 프롬프트 길이의 소거 연구. 에서는 다양한 실행에서의 변동성을 줄이기 위해 64샷 설정에서 소거 실험을 수행합니다. 표 3의 실험 설정과 일관성을 유지하기 위해, 그림 6에서는 16샷 설정에서 부공간 차원과 프롬프트 길이에 대한 소거 결과를 보여줍니다.
부공간에서의 CMA-ES 대 Adam. 그림 3에서는 프롬프트 튜닝(Adam 최적화기 사용)과 블랙박스 튜닝(CMA-ES 사용)의 수렴을 비교합니다. 여기서 Adam은 원래 프롬프트 공간 에서 최적화를 수행하는 반면, CMA-ES는 생성된 부공간 에서 수행합니다. 여기서 우리는 또한 부공간에서 Adam과 CMA-ES의 효과와 효율성을 비교합니다. 그림 7에서 보듯이, CMA-ES는 저차원 부공간에서 Adam보다 더 효율적이고 안정적입니다. 부공간의 차원이 크게 될 때(예: ), 적절한 학습률을 가진 Adam은 CMA-ES와 동등한 성능을 낼 수 있습니다. CMA-ES는 역전파(back-propagation)를 요구하지 않으므로, CMA-ES와 Adam의 한 번의 반복에 대한 계산 비용은 매우 다를 수 있습니다. 공정한 비교를 위해, 우리는 반복 횟수를 FLOPs로 변환합니다. Adam의 한 번의 반복에 대한 FLOPs는 CMA-ES보다 세 배 더 많다고 추정됩니다.
B. 병렬 평가(Parallel Evaluation)
학습 데이터가 작거나 서버가 더 큰 배치를 허용하는 경우, 학습 효율성을 향상시키는 유망한 방법은 병렬 평가를 사용하는 것입니다. 즉, 그림 8(a)에 나타난 것처럼 전체 집단을 병렬로 평가할 수 있습니다. 그림 8(b)에서 보여주듯이, 우리는 300번의 반복(API 호출)으로 인구 크기가 20과 25일 때 SST-2 학습 세트에서 100% 정확도를 달성할 수 있습니다. API 호출 당 배치 크기가 제한된 경우, 비동기 쿼리를 사용하여 병렬 평가를 시뮬레이션할 수도 있습니다.
C. 업로드/다운로드 데이터 크기 추정(Estimation of Uploaded/Downloaded Data Size)
이 섹션에서는 업로드 및 다운로드할 데이터의 양을 추정하는 방법을 설명합니다(표 4).
블랙박스 튜닝(black-box tuning)을 위해 업로드해야 할 데이터는 두 가지 종류가 있습니다: (1) 학습 샘플(training samples)과 (2) 연속적인 프롬프트(continuous prompt). 학습 샘플은 input_ids와 attention_mask 두 부분으로 구성됩니다. input_ids에는 부호 없는 짧은 정수(unsigned short, 표현 범위: $0 \sim 65535, 값당 2바이트)를 사용할 수 있고, attention_mask에는 불리언(bool, 값당 1바이트) 타입을 사용할 수 있습니다. 수백 개의 값을 포함하는 연속적인 프롬프트의 경우, 표현을 위해 부동 소수점(float, 값당 4바이트) 타입을 사용할 수 있습니다.
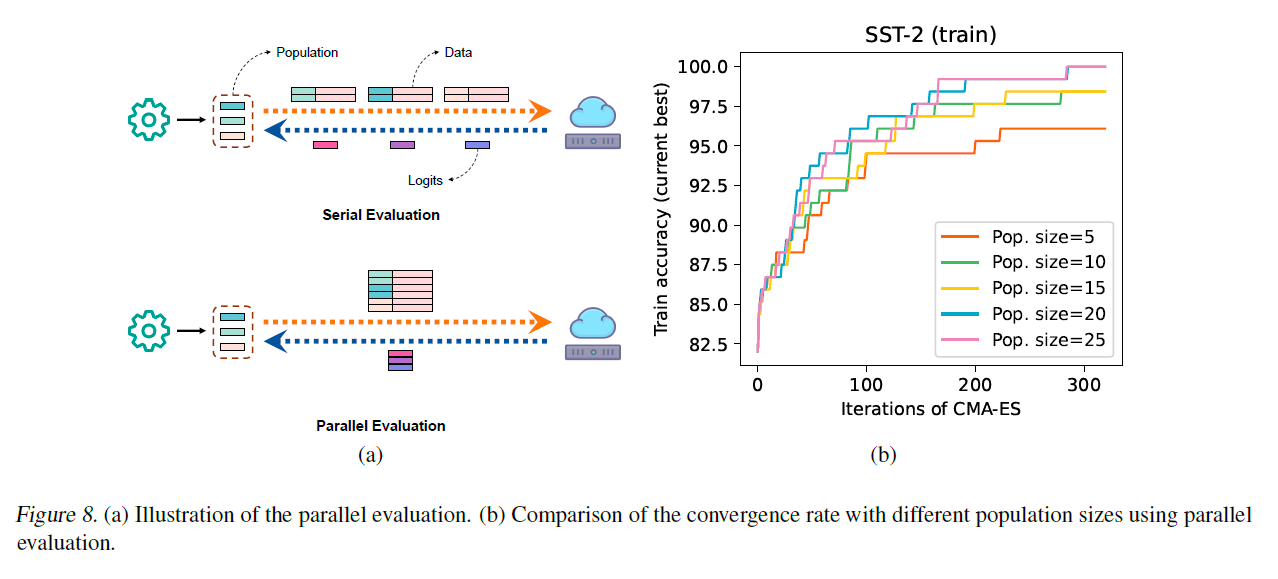
그림 8. (a) 병렬 평가(parallel evaluation)의 일러스트레이션. (b) 병렬 평가를 사용하여 다른 인구 크기로 수렴 속도를 비교.
SST-2 16-shot 분할을 예로 들면, input_ids와 attention_mask는 의 형태를 가지고 있으며, 여기서 32는 배치 크기(batch size)이고 47은 최대 시퀀스 길이(maximum sequence length)입니다. 따라서 input_ids에 대한 데이터는 약 이고 attention_mask에 대한 데이터는 약 입니다. 프롬프트가 500차원이라고 가정하면, 프롬프트에 대해 추가로 약 의 데이터를 업로드해야 합니다. 다운로드해야 할 데이터는 후보 단어들의 출력 로짓(output logits)으로, 개의 부동 소수점 값이 포함된 사전(dictionary)입니다. SST-2 16-shot 분할을 예로 들면, 다운로드해야 할 데이터의 크기는 바이트 입니다.
특징 기반 방법(feature-based methods)에서는 비슷한 추정 방법을 사용합니다. 업로드해야 할 데이터 크기는 Feature-MLP와 Feature-BiLSTM에 대해 동일합니다. Feature-MLP에 대해 다운로드해야 할 데이터는 [CLS] 토큰의 표현이고, Feature-BiLSTM에 대해 다운로드해야 할 데이터는 모든 토큰의 표현입니다. 이 추정은 어떠한 데이터 압축도 없이, 실제 시나리오의 상한선(upper bound)입니다.
