A Joint Sequence Fusion Model for Video Question Answering and Retrieval - 논문 정리
Paper Review
이번 게시물에서는 어떤 multimodal sequence가 주어졌을 때 의미론적 유사성을 측정할 수 있는 JSFusion이라는 접근법과 관련된 논문을 정리하고자 한다.
Abstract
본 논문에서는 두 개의 multimodal sequence 데이터 사이의 의미론적 유사성을 측정할 수 있는 JSFusion(Joint Sequence Fusion)이라는 접근법을 제시한다. 본 논문의 multimodal matching 네트워크는 2개의 주요 요소들을 지니는데,
1) Joint Semantic Tensor
- 한 쌍의 dense한 sequence data의 표현을 3차원 벡터로 구성한다.
2) Convolutional Hierarchical Decoder
- 두 sequence modality간의 숨겨져있는 계층적 일치를 찾아 유사성 점수를 계산한다.
두 주요 요소 모두 데이터를 기반으로 잘못 정렬된 것들을 잘라내면서 잘 정렬된 표현 패턴을 학습하는 hierarchical attention 메커니즘을 활용한다.
JSFusion은 모든 multimodal sequence data에 적용 가능한 보편적 모델이지만, 본 연구는 multimodal retrieval과 VQA를 포함한 영상-언어 과제에 초점을 맞춘다.
1. Introduction
최근, 다양한 영상-언어 과제가 컴퓨터 비전 연구에 관심을 가지게 되었으며, 이와 같은 어려운 과제를 해결하기 위해서는 단어 sequence와 frame sequence 사이의 hidden join representation을 학습하여 올바르게 그들의 의미론적 유사성을 측정하는 것이 중요하다. 영상 분류가 해결 후보가 될 수 있지만, 몇 개의 레이블만 영상에 붙이는 것으로는 영상 내의 잠재적인 사건들과 언어 묘사를 완전히 연관 짓기에는 불충분하다. 딥러닝 표현 학습의 발전으로 여러 multimodal semantic embedding 방식이 제안되었지만, 존재하는 대부분의 방식들은 시각 정보와 언어 정보를 각각 하나의 벡터로 embedding하여 영상과 자연어 문장이 불충분한 문제를 발생시킨다.두 modality 각각의 벡터로는 데이터들의 부분들 간의 여러 관계들을 비교하는 것이 어렵다. 이로 인해 계층적 matching이 더 적합하다.
본 논문에서는 attention 메커니즘을 활용하여 데이터 기반으로 반복적으로 match를 학습하여 어떠한 multimodal sequence data 쌍에서도 의미론적 유사성을 계산할 수 있는 접근법을 제안한다.
2가지의 주요 요소를 포함하는데.
1) Joint Semantic Tensor(JST):
- frame과 word 사이 Hadamard products(elementwise products)를 수행하고 2개의 sequence data의 embedding들을 3차원 tensor으로 encoding한다.
- 학습한 attention으로 3차원 matching tensor을 정제한다.
2) Convolutional Hierarchical Decoder(CHD):
- conv layer과 gate로 구성된 attention 기반의 decoding module을 사용하여 tensor에서 국소 정렬을 찾아낸다.
위의 두 attenchion 메커니즘은 잘 맞는 표현 패턴을 증진하고, 잘못 이어진 것들을 잘라낸다. 마지막으로, CHD는 sequence pair간 계층적 합성을 얻고, sequence pair의 의미론적 유사성 점수를 계산한다.
본 연구의 기여를 요약하면 아래와 같다.
1) JST와 CHD를 주요 요소로 가지는 Joint Sequence Fusion(JSFusion) 모델을 제안한다. Multimodal sequence data간의 의미론적 유사성 점수를 측정하기위해 반복적으로 학습가능한 attention module의 사용을 시도하는 것은 처음이다. 구체적으로, JST의 soft attention과 CHD의 Conv-layer과 Conv-gates가 포함된 다른 두 가지 attention model을 제안한다.
2) JSFusion 모델의 적용성을 확인하기 위해(특히 VQA와 retrieval에서), LSMDC의 3개의 과제에 참여하고 가장 높은 점수를 얻는다. 본 연구에서는 MSR-VTT 기반의 새로운 video retrieval과 QA 표준 데이터셋을 만들었으며, 해당 데이터셋에서 JSFusion이 다른 최신 VQA 모델보다 더 좋은 성능을 보인다.
2. Related Work
본 연구는 video retrieval과 video question answering, 두 최근 연구 문맥에 포함된다.
Video Retrieval with Natural Language Sentences
영상은 단지 여러 이미지가 합쳐진 것이 아니기 때문에 영상에서 frame sequence와 서술어 sequence 간의 잠재적인 관계를 학습하기가 어렵다. 최근 이와 관련해서 많은 연구를 통해 여러 방법이 제안되었다. 현재 존재하는 여러 방법들과 본 연구의 모델을 비교했을 때, 본 연구의 모델은 먼저 두 sequence간의 dense pairwise embedding을 찾고, 그 후에 hierarchical attention 메커니즘을 활용하여 bottom-up 방식으로 higher-level의 유사성 일치를 구성한다. 이 방식은 특히 국소 부분의 일치에서 모델의 로버스트성을 높여주는데, 이것이 다른 이전 연구보다 더 독특한 점이다.
Video Question Answering
영상 기반 VQA는 시공간적 추론을 학습해야 질문에 옳은 대답을 할 수 있는데, 이를 위해 큰 annotation이 있는 데이터가 필요하다. 이로 인해 주로 영상 기반 VQA가 이미지 기반 VQA보다 어렵다고 인식된다.
다행히도, 큰 Video QA 데이터셋이 최근에 마련되었다.
Video QA에서 객관식 문제에서는 영상 query와 5개의 정답 후보 서술문들이 주어지고, 그들 중 가장 옳은 답을 선택해야한다. 이 문제를 해결을 위해 deep representation에서 ranking loss를 사용하거나 joint space에서 nearest neighbor search를 하는 것이 활용된다. Torabi et al.의 Learning Language-Visual Embedding for Movie Understanding with Natural-Language에서는 공간적 attention을 query video와 정답 문장 사이의 joint representation에 적용한다. Yu et al.의 End-to-End Concept Word Detection for Video Captioning, Retrieval, and Question Answering에서는 LSTM을 사용하여 탐지된 concept word에 query와 embedding된 정답을 sequential하게 전달한다.
Fill in the blank 과제에서는 MergingLSTMs와 LR/RL LSTMs가 query 문장을 영상 문맥에 맞게 encoding될 수 있도록 활용되었다. 그러나, 대부분의 본 연구 이전의 접근법들은 문장 정보에 지나치게 집중하고 시각적 신호를 쉽게 무시하는 경향이 있다.
반대로, 본 논문에서의 모델은 영상과 문장들 사이의 multi-level에서의 의미론적 유사성을 학습하는 것에 집중하고, Video QA와 Fill in the blank 과제에서 최고 점수를 지속적으로 받는 것을 확인할 수 있다.
3. The Joint Sequence Fusion Model
3.1 Preprocessing
Sentence Representation
본 연구에서는 각 문장을 단어 단위로 encoding한다. 데이터셋에서 3회 이상 등장하는 단어를 모아 단어 모음(vocabulary dictionary) V를 정의하고, 단어 모임에 없는 단어는 무시한다. 그 후, pretrained glove.42B.300d를 사용하여 word embedding dimension이 300(d=300)인 word embedding matrix를 얻는다. 각 문장은 Wm으로 나타내며, 여기에서 m은 문장 내의 단어 수를 의미한다. 각 문장은 최대로 40 단어를 가질 수 있으며, 만약 40단어를 넘는 문장이 전체 데이터의 0.07%밖에 차지하지 않기 때문에 이 경우 40번째 단어까지만 사용한다. 본 논문에서 단어 index는 m으로 나타낸다.
Wm = Sentence
m = Word IndexVideo Representation
정보 손실을 줄이는 동시에 불필요한 반복을 피하기 위해 5 fps마다 하나의 frame을 sampling했다. 영상의 시각과 청각 정보 모두 CNN으로 encoding한다.
시각 정보의 경우, 각 frame마다 ImageNet으로 pretrained된 ResNet-152의 pool5 layer의 feature map을 추출한다.
청각 정보의 경우, VGGish를 사용하여 feature map을 추출하고, PCA로 차원 축소를 진행한다.
그 후, 두 feature을 video descriptor Vn으로 concatenate하는데, 여기서 n은 영상의 frame 수이다. 본 연구에서는 영상마다 최대 frame 수를 40으로 제한한다. 40 frame이 넘어가는 영상에서 성능 향상이 이루어지지 않는 것을 확인했기 때문에 frame이 40을 초과하면 40개의 등거리의 frame을 선택한다. 본 논문에서 영상 frame index는 n으로 나타낸다.
Vn = Video Descriptor(Visual + Audio)
n = Frame Index3.2 The Joint Semantic Tensor
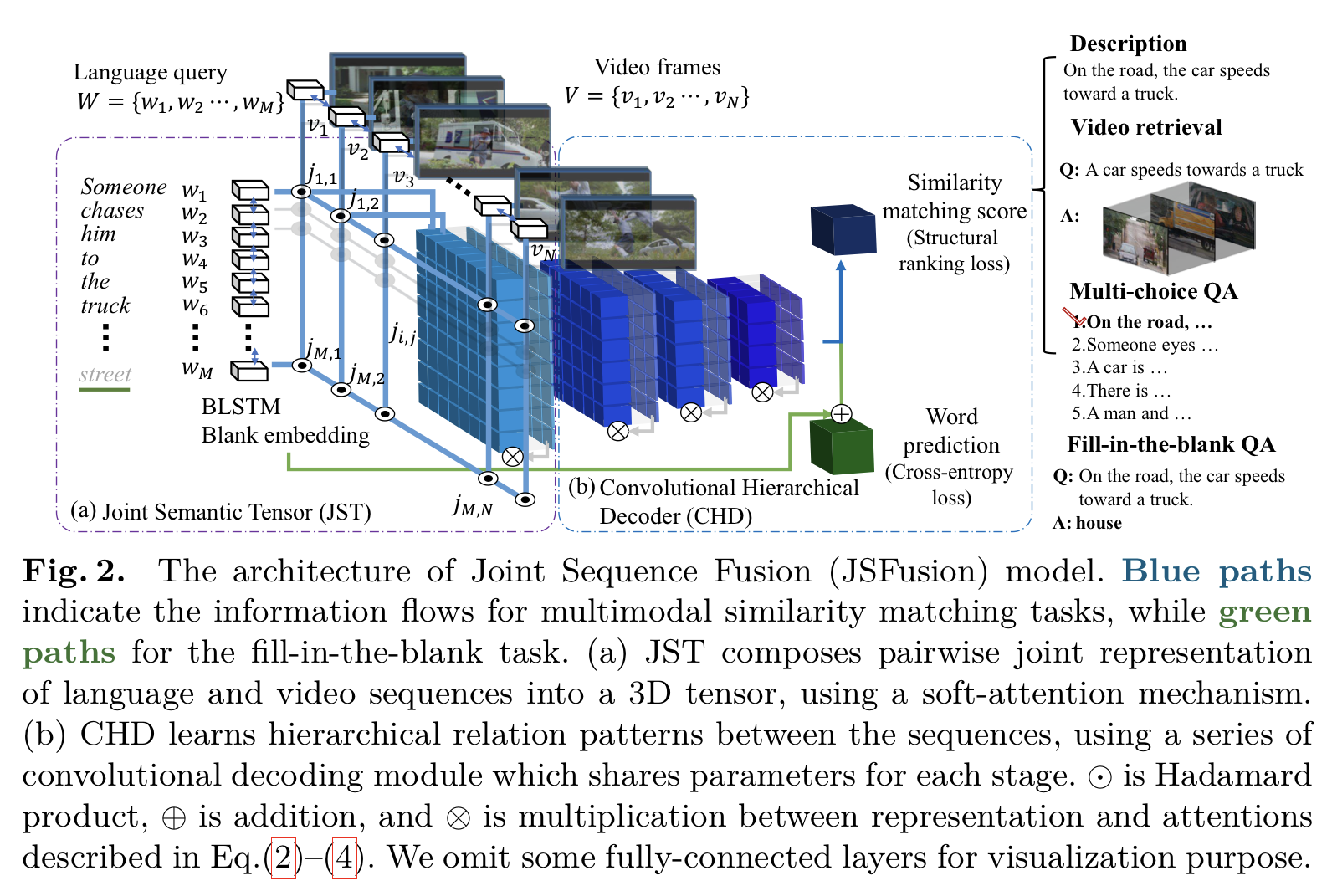
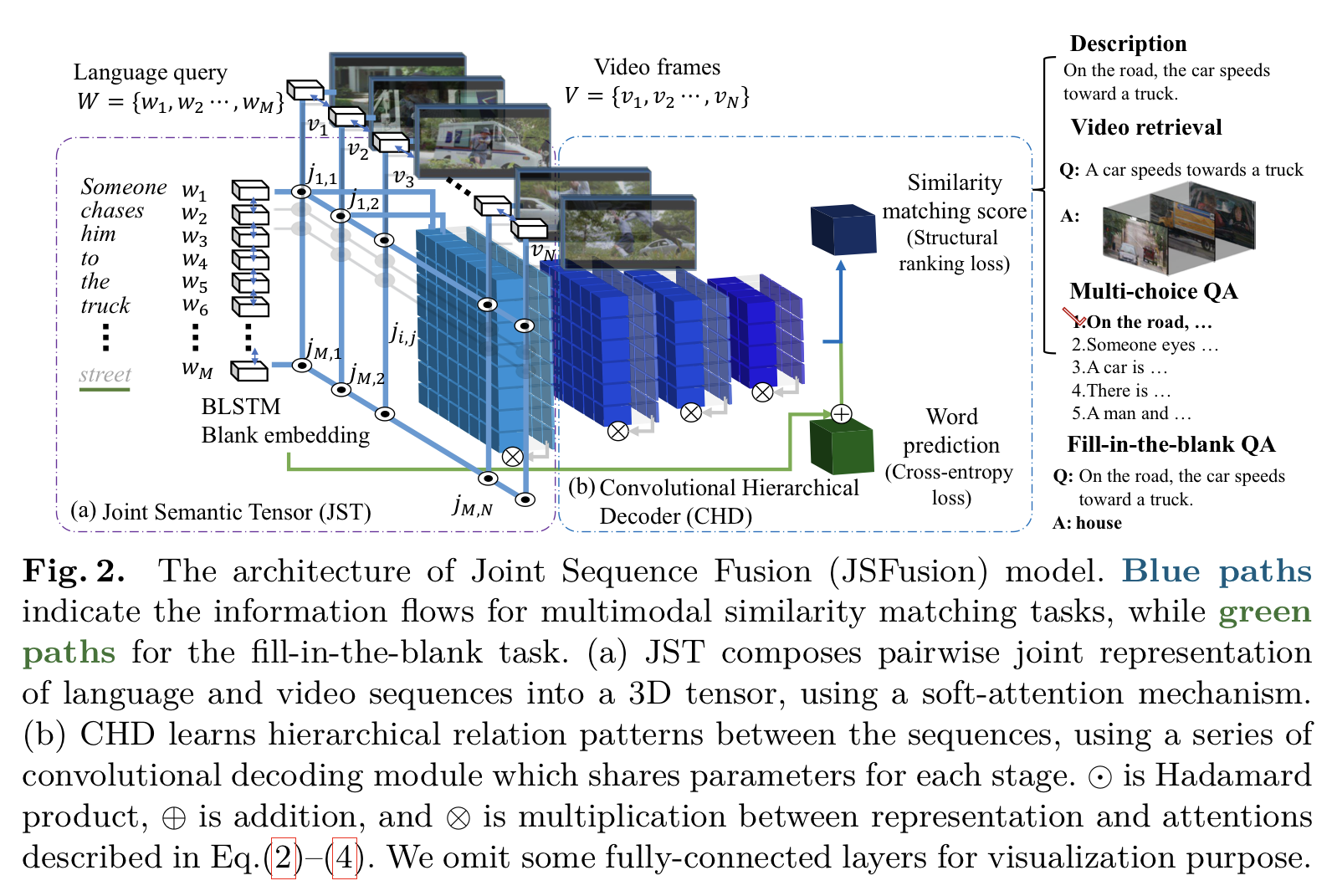
Joint Semantic Tensor (JST)는 한 쌍으로 이루어진 두 multimodal sequence를 3차원 tensor으로 변환시킨다. 그 후, JST는 3차원 tensor에 self-gating 메커니즘을 적용해서 attention map으로 정제시키는데, 이것은 일치하지 않는 joint representation은 잘라내는 동시에 세밀하게 일치하는 모든 두 multimodal의 pairwise embedding을 찾아낸다.
Sequence Encoders
한 쌍의 multimodal sequence가 주어지면, encoder을 이용해 표현한다. Word sequence는 bidirectional LSTM networks(BLSTM) encoder을 사용하고, video frames는 CNN encoder을 사용한다. Sequence는 말 그대로 연속적이기 때문에 과거와 미래 문맥을 모두 고려하는 것이 sequence의 요소들을 표현하는 것에 유리하고, 이 이유로 BLSTM encoder을 사용한다.
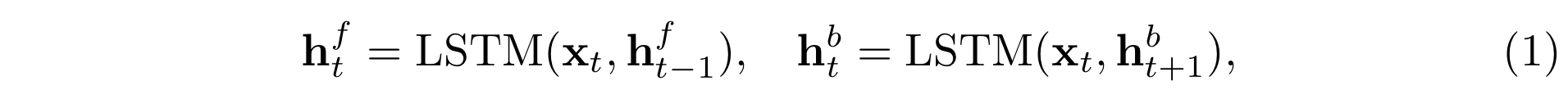
왼쪽의 h는 BLSTM의 forward hidden state이고, 오른쪽의 h는 backward hidden state인데, 아래와 같이 두 h 모두 0으로 초기화된다.

마지막으로, 단어의 경우 아래와 같이 forward/backward hidden state와 입력 feature을 concatenate하여 매 step마다 각각의 modality마다 표현을 얻는다.

영상의 경우, 아래와 같이 1-d CNN encoder representation을 사용한다.
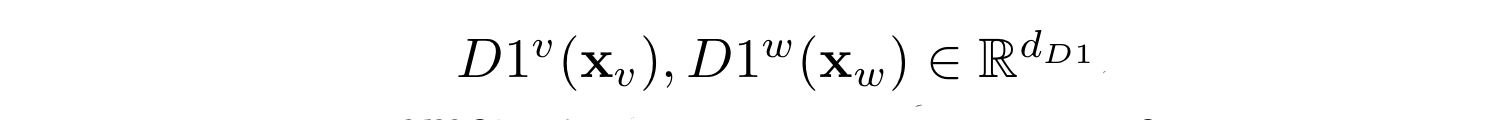
Attention-based joint embedding
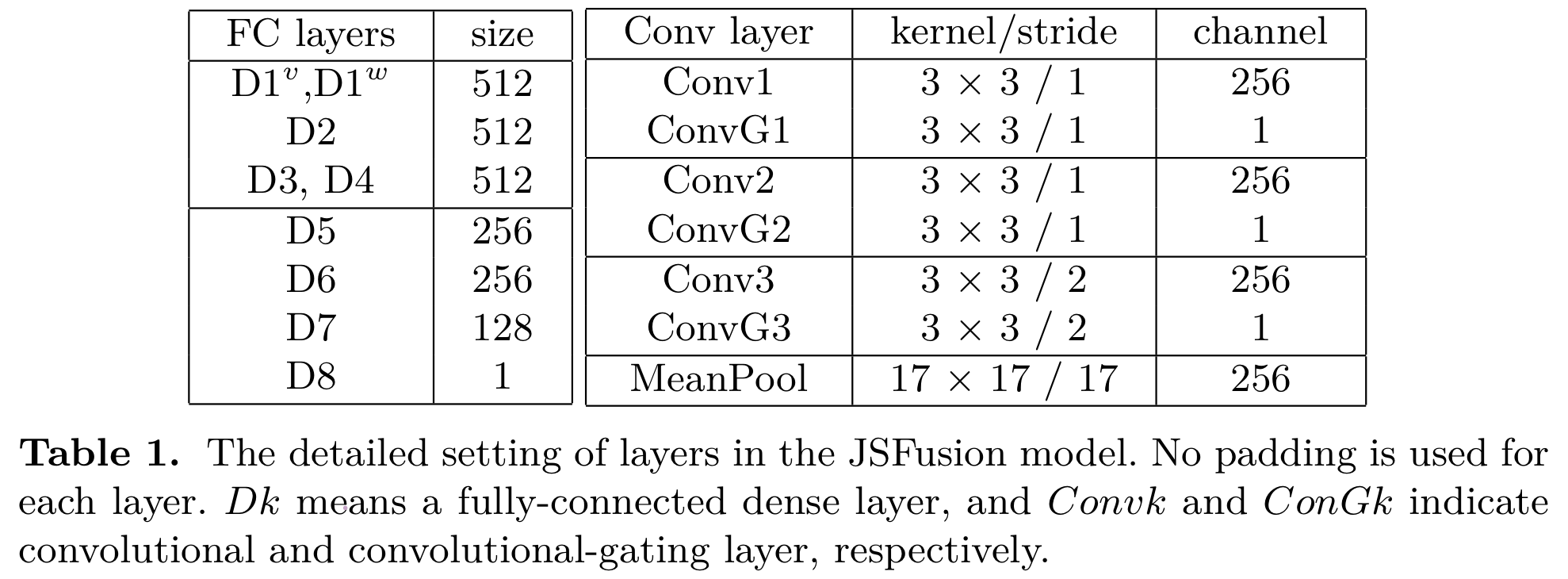
본 논문에서는 fully-connected layer을 Dk로, convolutional layer을 Convk로 표현한다.
Sequence encoder의 출력값을 각 modality마다 분리하여 fully-connected(dense layer)인 [D1]으로 전달하여 아래와 같은 결과값이 나온다.
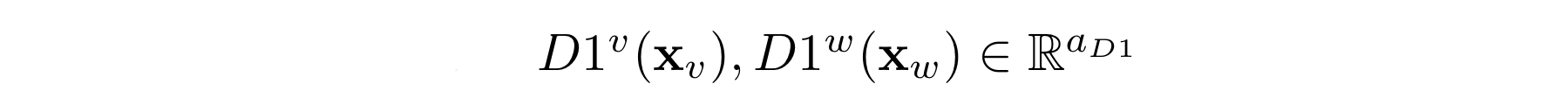
여기에서 d는 [D1]의 hidden 차원이다.
다음으로, attention weight인 a와 representation r을 계산하고, 이로부터 모든 sequential feature 쌍 사이의 joint embedding인 JST를 얻는다.
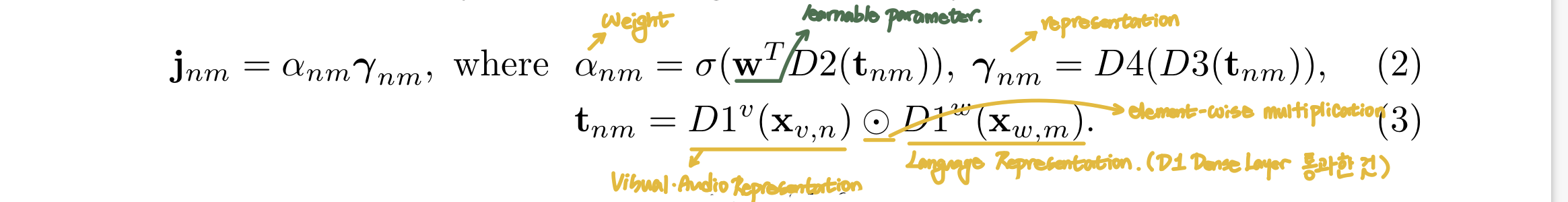
Sequence encoder의 출력값은 각 프레임마다 인접 영상의 영향을 받았기 때문에(또는 각 단어가 전체 문장의 영향을 받았기 때문에), attention a는 모든 가능한 짝들 중 어떤 짝의 joint embedding 가중치가 더 높아야할지 찾아낸다.
(2)와 (3) 수식으로부터 3차원 형식의 JST 얻는다.
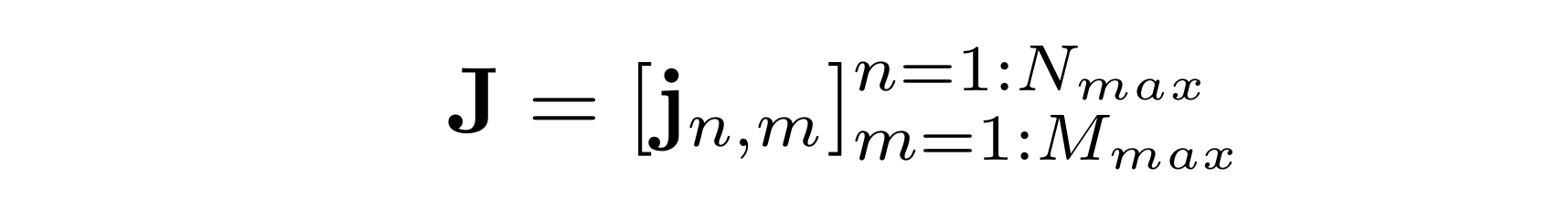
3.3 Convolutional Hierarchcal Decoder
Convolutional Hierarchical Decoder(CHD)는 JST의 joint vector space의 구성을 이용하여 multimodal sequence 쌍들의 적합성(compatibility) 점수를 계산한다.
JST tensor은 여러 convolutional layer과 하나의 conv-gating block을 지나는데, 학습가능한 커널들이 직전 layer으로부터 일치하는 embedding을 찾아낸다. CHD가 잘못 매치된 pair들보다 옳게 매치된 pair들의 가중치를 반복적으로 활성화시키는 것이다.
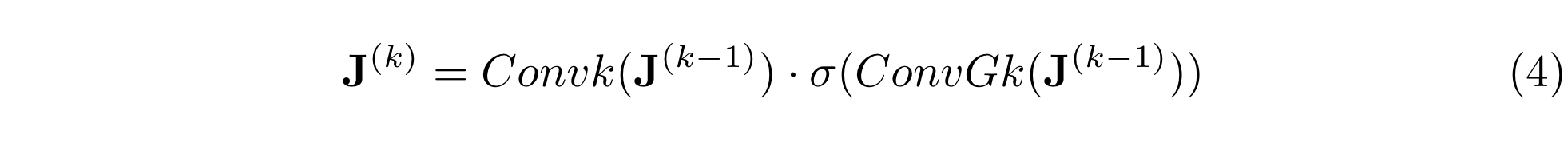
위와 같은 set를 총 3회 반복한다. k는 1, 2, 3이다. J(0)은 JST의 J로 초기화시키고, [convk]는 joint representation의 k번째 Conv layer이고, [convGk]는 일치하는 filter의 k번째 Conv-gating layer이다. J(3)에 mean pooling을 적용하여 단일 video-sentence vector representation인 Jout을 얻는다. 마지막으로, Jout을 [D5, D6, D7, D8] 총 4개의 dense layer으로 전달하여 매치의 유사성 점수를 계산한다. [D8] dense layer을 제외하고는 모든 dense layer에서 tanh 활성화함수를 사용한다.
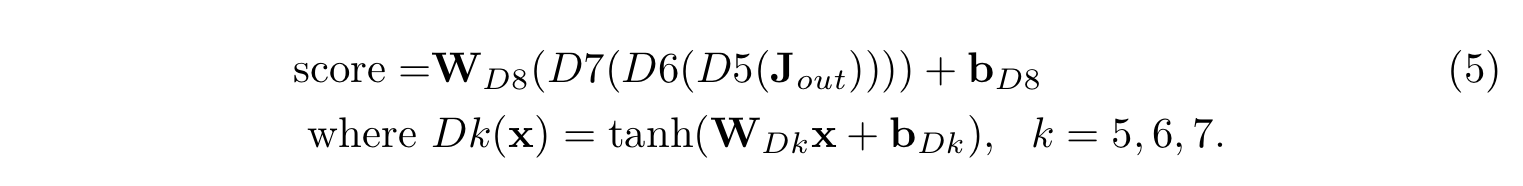
3.4 An Illustrative Example of How the JSFusion Model Works

Figure 3는 JST와 CHD의 attention이 실제로 어떻게 작동하는지 보여준다.
Figure 3(a)는 영상의 frame과 긍정/부정 문장의 단어들의 모든 짝을 수식(2)에서 학습하여 얻어진 attention weight a를 시각화한 것이다. 단어들이 video frame의 내용과 잘 일치할 때 attention이 더욱 진해진다(hightlited with higher values).
Figure 3(b)는 각각의 Conv layer과 Conv-gating block의 output인 J(k)를 보여준다. 학습을 진행하면서 각각의 Conv layer은 lower layer에서 학습한 것으로 joint embedding 구성을 학습하고, Conv-gating layer은 영상과 문장 간의 빈번하게 발생하는 일치하는 패턴을 학습한다. test 데이터를 가지고 유사성 점수를 계산할 때, Conv-gating layer은 잘못 연결된 패턴들을 제거한다. Figure 3(b)의 오른쪽 이미지를 통해 알 수 있듯이, 만약 짝이 올바르게 연결되지 못했다면, 대부분의 J(k)가 낮은 value를 가진다.
결과적으로, CHD는 final-layer representation으로 전달되는 lower-level의 정보를 선택적으로 고를 수 있으며, CHD의 마지막 layer은 sequence data간 패턴의 일치가 강할 때만 좊은 점수를 부여한다.
본 연구의 접근법에서는 JST가 먼저 multimodal sequence data를 dense pairwise 3차원 tensor representation으로 구성하고, 그 이후 convolutional gated layer을 사용하여 multi-stage 유사성 매치를 학습하여 짧은 문장과 부분 데이터 간의 부분적 매칭을 탐지할 때 더욱 로버스트하다.
3.5 Training
본 연구에서는 JSFusion 모델을 ranking loss를 사용하여 학습을 진행한다. 각 training batch는 한 개의 옳게 연결된 pair과 L-1개의 옳지 않게 연결된 pair, 총 L개의 video-sentence pair으로 구성된다. 매 epoch마다 batch shuffling을 진행한다. JSFusion 모델은 아래와 같은 loss objective로 학습을 진행한다. 이 loss objective는 ∆로 옳게 연결된 video-sentence pair이 잘못 연결된 pair보다 더 높은 점수를 받을 수 있도록한다. 본 연구에서는 λ = 0.0005, ∆ = 10로 설정하였다. Adam Optimizer과 초기 learning rate로 10의 -4승으로 학습을 진행한다. 또한, 매 dense layer마다 batch normalization을 적용한다.
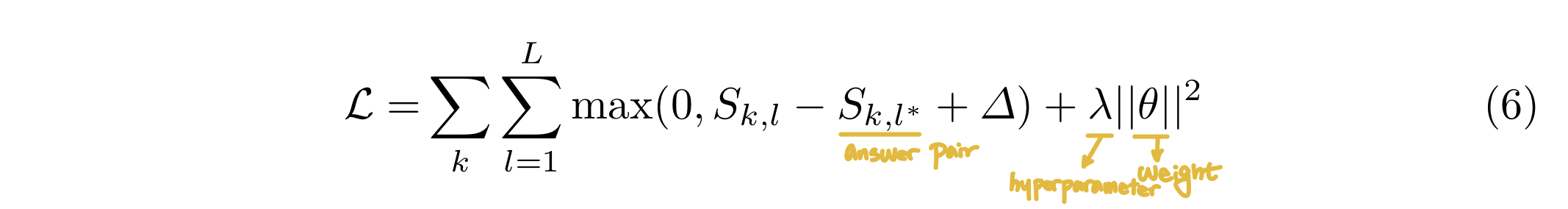
3.6 Implementation of Video-Language Models
본 연구에서는 video retrieval과 객관식 질문에 동일한 JSFusion 모델을 적용하지만 하이퍼파라미터 설정은 약간 다르게 설정했다. 빈칸 채우기의 경우, 모델이 빈칸에 대한 단어를 예측하게 하기 위해 모델을 약간 조정했다.
For Retrieval
Retrieval model은 query 문장을 입력받고, 1000개의 test 영상을 query와 video의 관계에 따라 정렬한다. 학습에서 각 배치마다 L을 10으로 정한다. Test에서는 각 query 문장 k마다 영상 l에 대한 점수 {S}를 계산한다. 점수 matrix를 기반으로 query를 정렬할 수 있게된다. JSFusion은 복잡한 자연어 query와 음성이 있는 영상 frame간의 계층적으로 일치하는 패턴을 찾는 것을 성공적으로 하였다.
For Multiple-Choice Test
객관식 질문 모델은 영상과 4개의 오답 문장과 1개의 정답 문장을 입력받는다. JSFusion은 query video와 각 문장 사이의 호환성(compatibility) 점수를 계산할 수 있기 때문에 retrieval 과제와 동일한 모델을 사용한다. 5개의 정답 후보들 중 가장 높은 점수를 가진 정답 후보를 정답으로 지정한다. 학습에서는 L을 10으로 설정하여 batch마다 10개의 video와 sentences 쌍이 학습에 사용되도록 하였다.
For Fill in the Blank
빈칸 채우기 과제를 위한 모델은 영상과 하나의 빈칸이 있는 문장이 입력되며, 그 빈칸에 들어갈 적합한 단어를 예측해야한다. 이 과제는 더욱 추론이 어렵기 때문에, 모델에 두 부분을 수정한다.
1) layer의 차원 수를 늘린다.
[D1, D5, D6, D7]이 1,024로 늘어나고,[D2, D3, D4]가 2,048으로, [D8]은 vocabulary size로, [Conv1_1, Conv2_1, Conv3_1]은 1,024로 차원 수가 변경된다.
2) Figure 2의 초록색 선처럼 JSFusion 모델에 skip-connection을 추가한다.
Query 문장에서 빈칸을 b로 두었고, b를 BLANK 토큰으로 만들어 BLSTM에서 사용하려 sequential context에서 빈 칸을 표현하도록 하였다.
[D7]의 출력값과 sequential context인 t를 더한 값을 [D8]에 입력값으로 전달하여 단어를 예측하도록 한다. 학습에서는 batch 크기를 32로 설정하였다(L=32). 이 과제는 ranking보다 classification에 가깝기 때문에 cross-entropy loss를 사용한다.
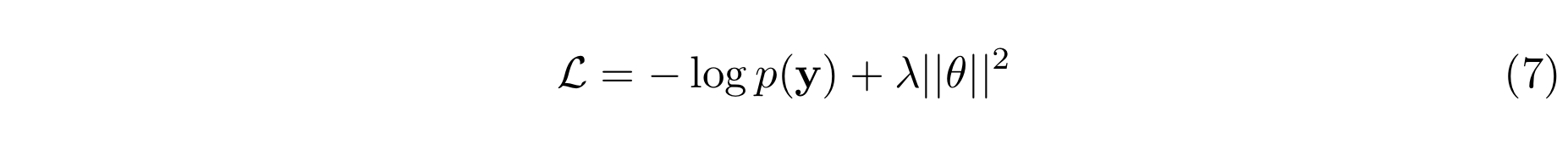
θ는 가중치 파라미터를 의미하고, λ는 0.0005로 설정된다. Dropout rate는 0.2로 설정된다.
