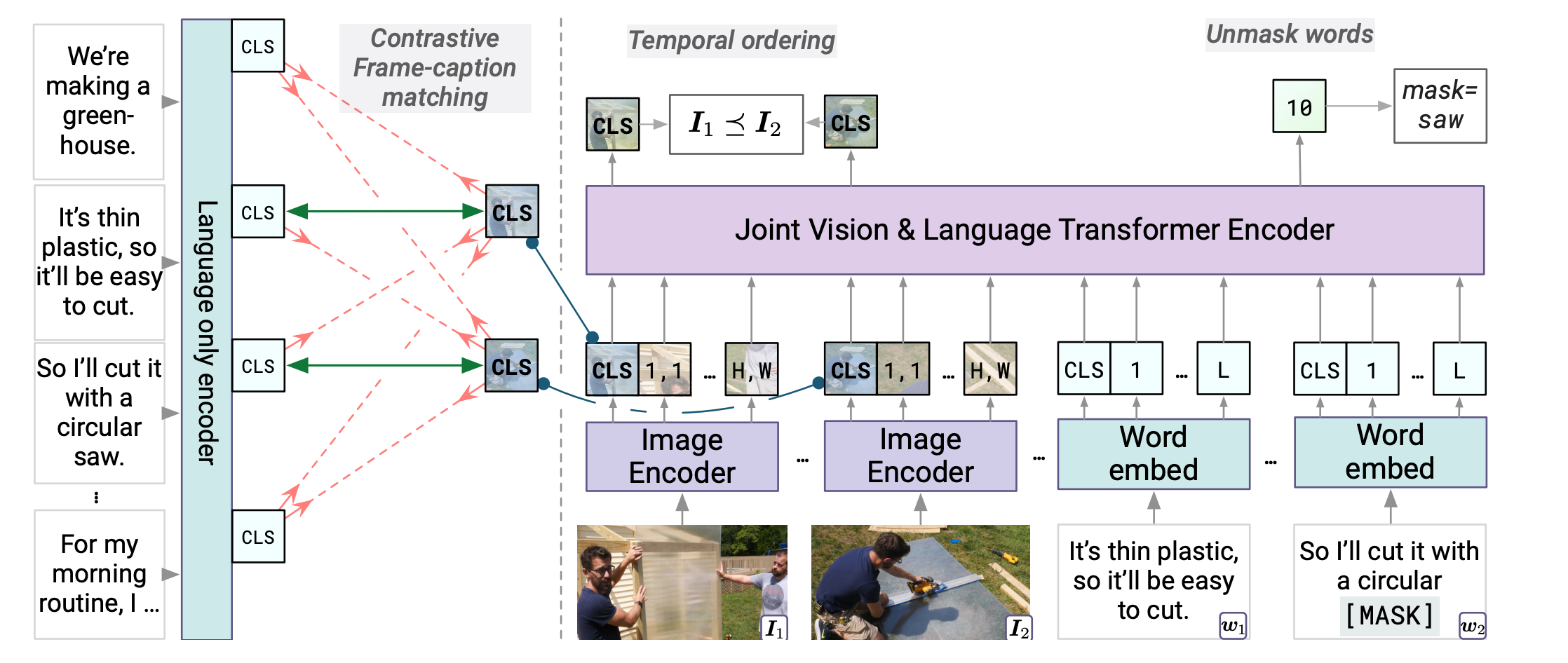
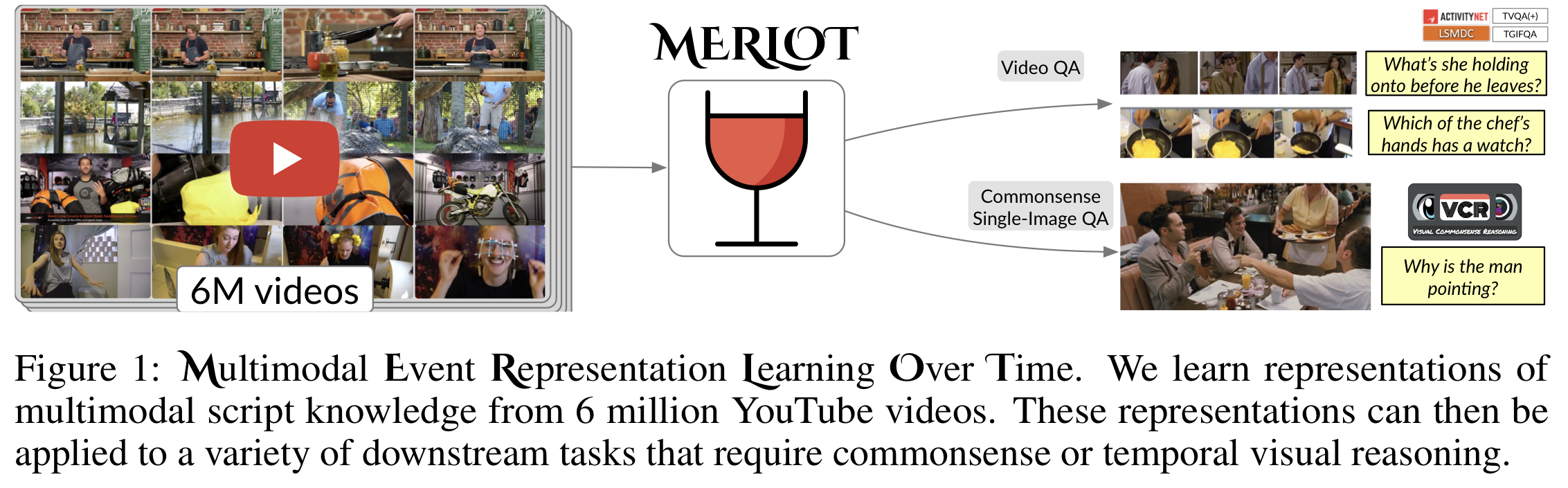
이번 게시물에서는 유튜브 영상으로 label 없이 multimodal script knowledge를 학습하는 self-supervised model인 MERLOT의 논문을 정리하고자 한다.
4 Questions to Answer
What did authors try to accomplish?
- the authors tried to build a model that has multimodal reasoning capacity beyond static images/literal captions.
- to do above, MERLOT is trained:
a) match individual video frames with contextualized representations of the associated transcripts, and to
b) contextualize those frame-level representations over time by “unmasking" distant word-level corruptions and reordering scrambled video frames.
What were the key elements of the approach?
1. YT-Temporal-180M
- intentionally spans many domains, datasets, and topics.
- diverse (video) data is important. compared to other datasets, a dataset that contains more diverse data had better results.
2. Contrastive frame-transcript matching
-
to ensure that the underlying image encoder produces helpful image representations:
- use the video transcript to compute a ‘language-only’ representation of each video segment
- use contrastive loss to maximize its similarity to corresponding representations from image encoder.
-
sometimes the words in each segment are not sufficient to describe an image frame-so video-level contextualization is required:
- entire transcript is passed on into the language-only encoder, which then extracts hidden states for each segment at segment-level CLS tokens.
-
According to table 4b, contrastive loss is crucial for model performance.
3. (Attention) Masked Language Modeling
- MERLOT must reconstruct the replaced word with the correct word using cross-entropy loss.
- Vanilla BERT-style often causes ungrounded fillers like 'umm', 'yea' to get masked, which penalizes the learning of multimodal representations.
- Attention masking solves the problem by masking the tokens preferentially that were highly attended-to by the contrastive language-only encoder
- text-only shortcuts become increasingly viable with length, but attention-masking approach counteracts them. So using 4 segments with attention masking has better results than using 4 segments without attention masking.
What can you use yourself?
- using contrastive loss for image representations.
What other references do you want to follow?
- ROBERTa : MERLOT's joint vision-language encoder mirrors ROBERTa's base architecture, and also initialized with ROBERTa's weights.
논문 읽기 전 - BERT 정리
논문을 이해하기 위해 알아야하는 BERT를 정리해보고자 한다.
BERT?
Transformer architecture을 중점적으로 사용한 BERT는 Bidirectional Encoder Representations from Transformers를 의미한다.
이름의 일부인 'bidirectional'에서 알 수 있듯이, BERT는 양방향성을 포함하여 문맥을 더욱 자연스럽게 파악할 수 있다. BERT 이전의 모델에서는 문장을 왼쪽에서 오른쪽으로만 읽어 문맥을 파악했다. 그러나 문맥을 완벽하게 이해하기 위해서는 오른쪽에서 왼쪽으로 읽는 것도 필요하다. 그래서 BERT에서는 단방향성이 아닌, 양방향성으로 앞뒤 단어를 모두 읽고 문맥을 파악한다.
BERT의 특징
전이학습 모델
BERT는 사전학습(pretrained)된 대용량의 라벨링이 되지 않은(unlabled) 데이터를 이용하여 언어 모델을 학습시키고, 이를 바탕으로 특정 작업( 문서 분류, 질의응답, 번역 등)을 위한 신경망을 추가하는 전이 학습 모델이다.
사전학습 모델
BERT는 기본적으로 대량의 단어 임베딩 등에 대해 사전 학습이 되어 있는 모델을 제공하기 때문에 상대적으로 적은 자원만으로도 충분히 자연어 처리의 여러 일을 수행할 수 있다.
BERT 모델 구조
BERT 는 BERT - base (L=12, H=768, A=12), Bert- large(L=24,H=1024,A=16) 이 두가지 버전이 존재하며 L(Transformer의 블록 숫자) , H(hidden size), A(Transformer의 Attention block 숫자) 를 의미한다. 각각 파라미터 값이 크다는 것은 표현하는 은닉층이 크며, Attention개수를 많이 사용하였다는 것이다. BERT - base 는 1.1억개의 학습 파라미터, BERT - large 는 3.3억개의 학습파라미터를 사용하였다.
BERT - Input Representation
BERT Input : Token Embedding + Segement Embedding + Position Embedding
BERT의 input representation은 세 가지 임베딩 값의 합으로 구성된다.
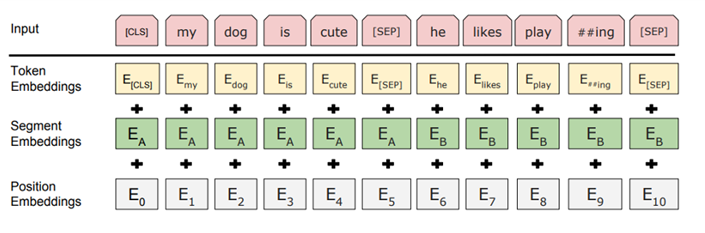
1. Token Embeddings
Token Embeddings는 WordPiece 임베딩 방식을 사용한다. WordPiece 임베딩이란, 등장 빈도가 높으면서 가장 긴 길이의 sub-word를 하나의 단위로 만드는 것이다. 즉, 자주 등장하는 단어(sub-word)는 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 더 작은 sub-word로 쪼개어진다. WordPiece 임베딩의 사용으로 자주 등장하지 않는 단어를 OOV(Out Of Vocabulary)로 분류하여 발생하는 성능 저하 문제가 해결되었다.
Token Embeddings에서는 두 가지 특수 토큰(CLS, SEP)을 사용하여 문장을 구별한다. Special Classification token(CLS)은 모든 문장의 가장 첫 번째(문장의 시작) 토큰으로 삽입된다. 이 토큰은 Classification task에서는 사용되며, 다른 경우에는 무시된다.
또, Special Separator token(SEP)을 사용하여 첫 번째 문장과 두 번째 문장을 구별한다. 여기에 Segment Embedding을 더해서 앞뒤 문장을 더욱 쉽게 구별할 수 있도록 돕는다. 이 토큰은 각 문장의 끝에 삽입된다.
2. Segment Embeddings
Segment Embeddings는 토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고, 단어가 첫번째 문장에 속하는지 두번째 문장에 속하는지 알려준다.
[ 0 0 0 0 0 1 1 1 1 ] 과 같이 표현하며 해당 Vector를 Token Embedding 차원수와 같게 맞추어 임베딩 해준다. BERT는 한 Segment를 512 sub-word 길이로 제한하며, 한국어는 보통 2- sub-word가 한 문장을 이룬다.
3. Position Embeddings
Position Embeddings는 토큰의 순서를 인코딩한다.
BERT는 transformer의 encoder를 사용하는데 Transformer는 Self-Attention 모델을 사용한다. Self-Attention은 입력의 위치에 대해 고려하지 못하므로 입력 토큰의 위치 정보를 주어야한다. 그래서 Transformer에서는 Sigsoid 함수를 이용한 Positional encoding을 사용하였고, BERT에서는 이를 변형하여 Position Encodings을 사용하는 것이다.
BERT - Transformer 기반
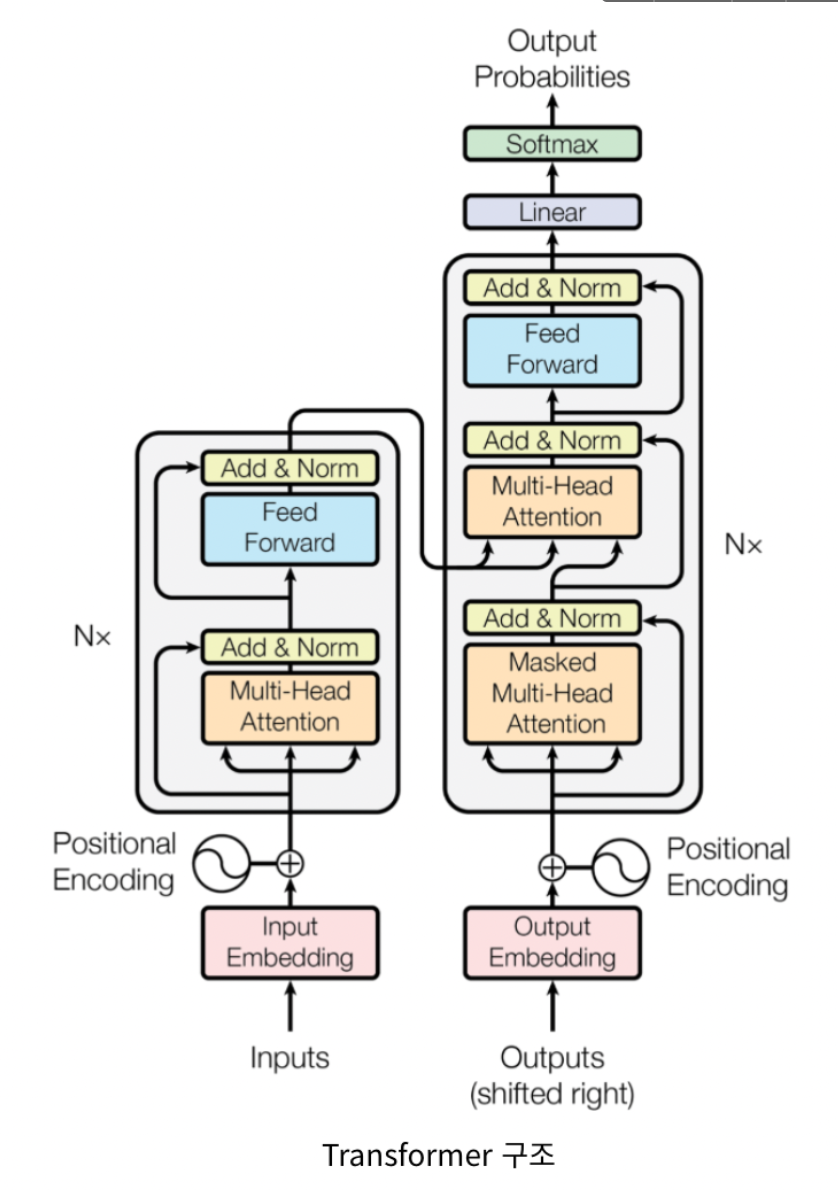
BERT 모델은 Transformer를 기반으로 하며, 이 중에서 위 이미지의 왼쪽 부분인 encoder만 사용한다.
BERT - MLM(Masked Language Model)
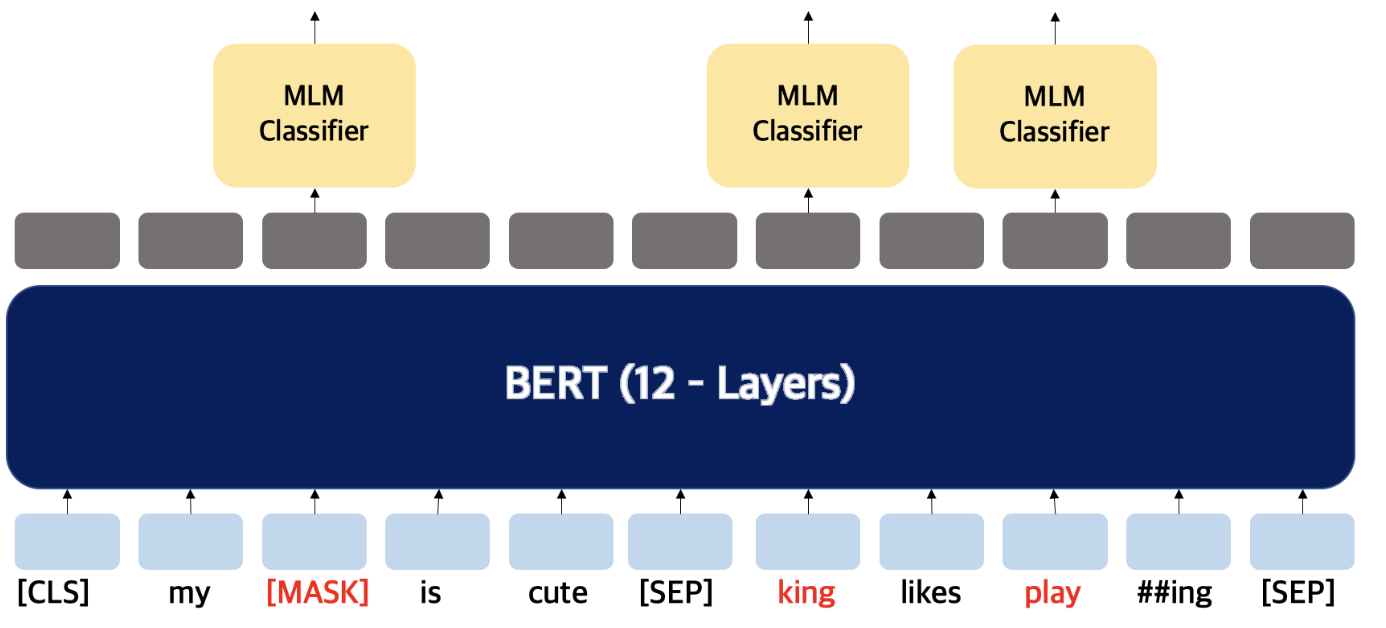
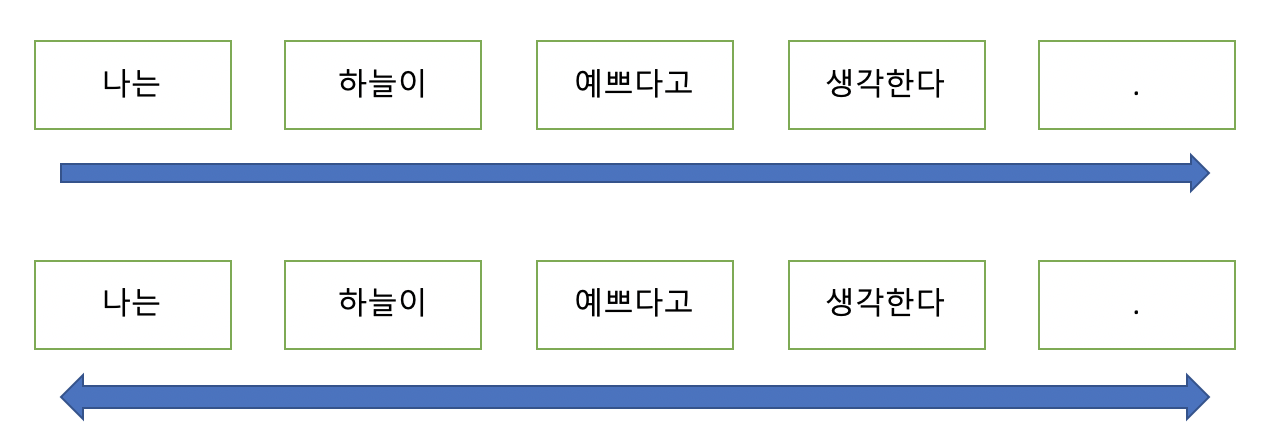
MLM(Masked Language Model)은 일련의 단어가 주어지면 그 단어를 예측하는 작업이다. 문장에서 단어 중의 일부를 [Mask] 토큰으로 바꾼 뒤, 가려진 단어를 예측하도록 학습한다. 이 과정에서 BERT는 문맥을 파악하는 능력을 기르게 된다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 [Mask] 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 흐리다고 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 예쁘다고 생각한다.
추가적으로, 더욱 다양한 표현을 학습할 수 있도록 80%는 [Mask] 토큰으로 바꾸어 학습하지만, 나머지 10%는 token을 random word로 바꾸고, 마지막 10%는 원본 word 그대로를 사용한다.
BERT - NSP(Next Sentence Prediction)

BERT는 Question Answering 에서도 사용되기 위해 두개의 문장을 제공하고 문장들이 이어지는 문장인지 분류하는 훈련도 거치게 된다. 이때 문장들은 50% 확률로 이어지는 문장이다.
각 문장이 다른 문장임을 보여주기 위해 문장과 문장 사이에 [SEP] 토큰을 넣게 되며 가장 앞에 있는 [CLS] 토큰에 이 문장이 이어지는 문장인지에 대한 예측을 한다.
참고/레퍼런스
https://happy-obok.tistory.com/23
https://velog.io/@jochedda/NLP-BERT-%EA%B0%9C%EB%85%90-%EC%A0%95%EB%A6%AC
https://hwiyong.tistory.com/392
https://vhrehfdl.tistory.com/15
논문 정리
0. Abstract
- MELOT은 label이 하나도 하나도 없는 유튜브의 영상들과 그 영상들의 음성을 전사한 것으로 multimodal script knowledge를 학습하는 모델이다.
- Frame-level(공간적), 그리고 video-level(시간적)의 objective function을 섞어 사전학습(pretrain)을 진행하여 MELOT은 단어와 이미지가 공간적으로 적절하게 매치되는 것뿐만 아니라 시간의 흐름에 따라 어떤 일이 발생하는지 문맥을 이해하게된다.
따라서 MERLOT은 뛰어난 시간적 상식(temporal commonsense)의 representation을 보여주며, fine-tuning이 된 MERLOT은 12개의 다른 Video QA 데이터셋에서 가장 좋은 성능을 보여준다. 이미지에서 어떤 일이 일어나고 있는지 추론할 수도 있다. 시각 상식(Visual Commonsense) 추론에서 MERLOT은 80.6%의 정확도로 질문에 올바르게 답하며 다른 비슷한 크기의 모델들보다 3% 이상의 높은 정확도를 보인다.
본 연구에서 모델의 성능을 파악하기 위해 진행하는 ablation analyses에서 아래와 같은 요소들의 상호보완적 중요성을 파악한다.
1) 영상으로 학습 V.S. 이미지로 학습
2) 사전학습 영상 데이터의 크기와 다양성 스케일링
3) recognition부터 cognition level까지 전체적으로 multimodal reasoning을 할 수 있도록 다양한 objective function 사용
1. Introduction
인간은 성장하면서 원인과 결과의 경험이 축적되며 상식 추론 능력이 형성된다. 위의 그림에서 오른쪽 아래에 있는 이미지의 경우 '사람들이 테이블에 않아 밥을 먹는다'라고 설명할 수 있다. 그러나 이 설명은 공간적으로는 맞으나, 해당 장면 이전에 '사람들이 만나서 어디에서 밥을 먹을 것인지 정했다'와 같은 시간적 정보는 담지 못한다.
모든 사실, 추론, 그리고 반사실을 열거하는 것이 불가능하기 때문에 기계에게 위와 같은 script knowledge를 학습시키는 것은 상당한 도전이다. 그래서 Visual Commonsense Reasoning(VCR)과 같은 visual-and-language 과제에서 가장 성능이 좋은 모델들은 문자 자막과 이미지 쌍들로만 시각 세계(정보)를 학습한다.
본 논문에서는 MERLOT을 소개한다. MERLOT은 multimodal event의 상식 추론을 self-supervised 사전훈련으로 6M개의 라벨링되지 않은 유튜브 비디오로 학습하는 모델이다. 이미지와 문자 자막으로 훈련하는 것보다 더 좋은 multimodal 추론 능력을 갖추는 것을 목표로 삼고 아래와 같은 2가지 방법으로 학습을 진행한다.
a) 각각의 video frame을 연관된 transcript의 문맥 표현에 맞게 연결한다.
b) 거리가 있는 word-level의 corruption을 'unmask'하고 순서가 섞인 video frame을 다시 재배치하여 frame-level의 representation을 시간이 지나면서 상황적 측면에서 설명할 수 있도록 한다.
본 연구에서는 MERLOT 모델을 인식(recognition)과 인지(cognition) 추론이 모두 요구되는 다양한 영상 과제로 성능을 확인하며, fine-tune이 MERLOT은 12가지 과제에서 가장 좋은 성능을 보인다. 추가적으로, script-knowledge representation은 이미지에서도 좋은 성능을 보인다. Visual Commonsense Reasoning(VCR, 시각 상식 추론)에서 MERLOT은 특히나 좋은 성능을 보인다.
본 논문에서는 정성적으로, 그리고 정량적으로 MERLOT이 매일매일의 사건과 상황을 잘 이해하는 것을 보여준다. 시간순서가 섞인 시각 정보가 주어졌을 때, MERLOT은 통일성이 있도록 자막에 따라 이미지를 배열한다. 영상말고 이미지와 자막을 일치시키는 과제에서도 해당 과제에서 우수한 baseline인 CLIP이나 UNITER보다 더 좋은 성적을 내는 등 MERLOT은 우수한 성적을 보인다. 해당 과제를 수행하기 위한 시간적 통일성은 pretraining을 할 때 나타나는데, MERLOT의 attention pattern을 보면 region(공간적)이 다른 시간의 caption에 참고를 하여 전체적인 상황을 하나로 엮는 cross-modal conference를 할 수 있게한다.
MERLOT의 ablation에서는 아래의 세가지를 파악할 수 있다.
1) 사전학습은 이미지로 학습을 진행했을 때보다 영상으로 학습을 진행했을 때 더 성능이 좋고, 그 이유는 Mask Language Modeling(MLM) 과제에서 highly visual word를 corrupt하는 전략 때문이다.
2) 여러 상황을 담고 있는 다양한 영상들을 학습에 사용하여 해결하고자 하는 과제에 대한 성능을 향상시켰다.
3) MERLOT의 성능은 MERLOT에 사용한 pretrain model을 많이 학습시켜도 줄어들지 않는다. 오히려 학습 epoch가 늘수록 성능이 향상한다.
본 연구를 요약하면 아래와 같다.
1) MELOT은 end-to-end vision and language 모델이며, label이 없는 영상과 영상의 필기록(transcript)로 multimodal world representation을 학습한다.
2) 6M개의 다양한 유튜브 영상과 영상의 ASR으로 구성된 YT-Temporal-180M은 모델의 성능 향상에 큰 도움을 준다.
3) 14가지 과제에 대한 모델의 우수한 성능을 여러 실험과 ablation을 통해 파악한다.
Related Work
2.1 Joint Representations of Written Text and Images
Other Papers
-
Visual Bert
- Trained on image captioning dataset eg) MSCOCO
- Features extracted using frozen object detector
-
Zhang et al : Revisiting visual representations in vision-language models
- Uses large object detector trained on a lot of labeled data
-
Kim et al : Vision-and-language transformer without
convolution or region supervision- Uses an ImageNet-pretrained backbone
-
Shen et al. : How much can clip benefit vision-and-language tasks?
- Studies CLIP backbone pretrained on web image-caption pairs
-
Overall
- all learns visual representations of static images.
- rely on significant human annotation in doing so.
MERLOT
- Learns dynamic visual representations purely from videos(frames of videos), and transcript of the videos.
- No human annotations
2.2 Learning from Videos, with Automatic Speech Recognition (ASR) Transcripts
Other Papers
- Prior Works
- used web videos with ASR to build weakly-supervised object detectors, action detectors/classifiers, instruction aligners, video captioners, and visual reference resolvers.
- Recent
- works have explored(sought) to learn multimodal representations transferable to many tasks from uncurated sets of videos(usually how-to videos)
- above works are usually applied to video understanding tasks(eg. activity recognition).
- Challenge of designing an appropriate objective for learning video-level representations
-
ClipBERT Model
Learns vision-language representations from image captions, which literally(글자로) describe image content.
Does not use ASR(using image caption instead). -
Tange et al. : Decembert
uses a pretrained dense image captioner to provide auxiliary labels(보조 label) for web how-to videos.
-
ClipBERT and Decembert
both uses supervised ResNets pretrained on ImageNet as their visual backbones.
-
MERLOT
- trained using a combination of objectives requiring no manual supervision.
- outperforms ClipBERT and Decembert on downstream tasks(해결하고자 하는 과제들).
2.3 Temporal Ordering and Forecasting
Past Work on analyzing "what happens next" focused on
- pixels, graphs, euclidean distance using sensors, studying cycle consistency across time
- studying deshuffling objectives in videos(mostly limited to visual modality)
Goal of MERLOT
- Learning multimodal script knowledge representations by using both language and vision as complementary views into the world, instead of just tracking what changes on-screen.
3. MERLOT: Multimodal Event Representation Learning Over Time
3.1 YT-Temporal-180M
- About YT-Temporal-180M
- a dataset for learning multimodal script knowledge, derived from 6 million public youtube videos.
- intentionally connects(spans) many domains, datasets, and topics to encourage the model to learn about a broad range of objects, actions and scenes.
- includes instructional videos from Howto100M, lifestyle vlogs of everyday events from the VLOG dataset, and YouTube's auto-suggested videos for popular topics(eg. science, home improvement).
- Videos were filtered by the YouTube API, their ASR track, and other metadata.
- discarded videos:
1) without English ASR track
2) over 20 minutes long
3) that belong to visually "ungrounded" categories(eg. video game commentary) - 영상의 특정 부분에 대해 묘사하지 않는 영상들
4) that have thumbnails unlikely to contain objects.
- discarded videos:
- punctuation added to the ASR by applying a sequence-to-sequence model trained to add punctuation to sentences/paragraphs from new articles.
- Video Segments
- Video V is represented as a sequence of consecutive video segments {S}.
- Each segment S consists of:
- a) an image frame I, extracted from the middle timestep of the segment.
- b) the words W spoken during the segment, with a total length of L tokens.
- Splitting Videos to Segments
- byte-pair-encode(BPE) each video transcript and align tokens with YouTube's word-level timestamps.
- Above enables to split the videos into segments of L=32 BPE tokens each.
- final dataset has 180 million segments of this form.
3.2 MERLOT Architecture
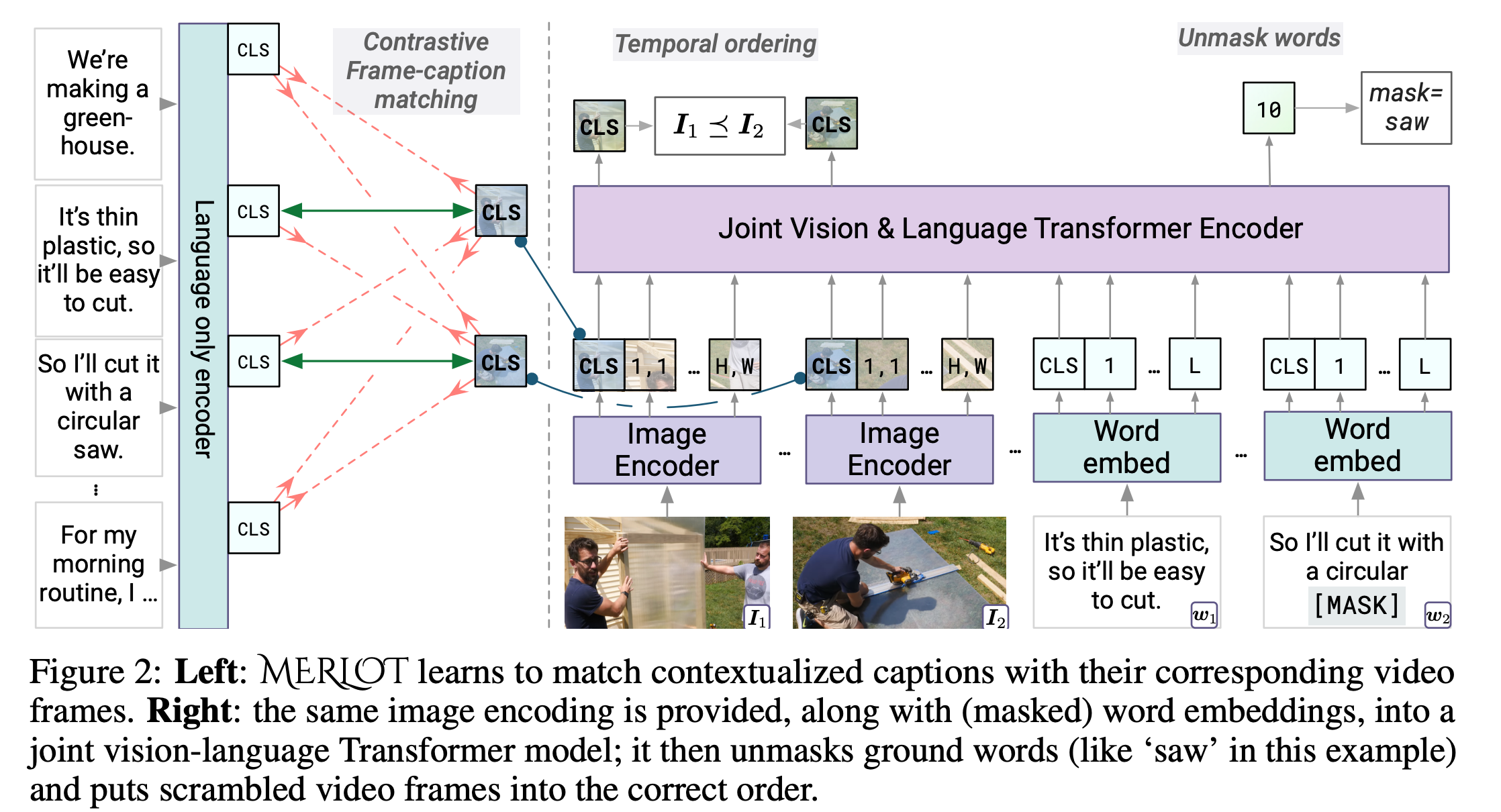
Abstract of MERLOT Architecture
- takes a sequence of video frames {S} as input.
- encode each frame I using an image encoder, embed the words W using a learned embedding, and jointly encode both using a Transformer.
- after pretraining, can be applied to a variety of vision-and-language tasks with minimal modification(최소한의 수정).
Image Encoder
- trained end-to-end
- random initialization(thus without learning from supervised data)
- unlike how other most performant vision-and-language models pre-extract features from a (supervised) object detector, uses a grid-based hybrid ResNet/Vision Transformer for the sake of pre-training efficiency(사전학습의 효율성을 목적으로).
- Specifically:
- ResNet-50 Backbone, followed by a 12-layer, 768-dimensional Vision Transformer.
- additional modifications that improve efficiency:
1) trained on smaller, widescreen images(192x352) using a patch size of 16x16 pixels
2) removes C5 block in ResNet-50
3) saves compute by average pooling the final-layer region cells using a kernel size of 2x2.
- requires 40gigaFLOPs for a forward pass(which is 2% of the 2 teraFLOPs required for the Faster-RCNN.
- Summary:
- given an image of size W x H, outputs W/32 x H/32 feature map and two CLS hidden states: one for pooling a global representation of the image, and another for pretraining. (Figure 2를 보면 pretrain에서 1개, pooling에서 1개인 것을 볼 수 있다.)
CLS hidden states?
contains the hidden representations for each token in each sequence of the batch.
Joint Vision-Language Encoder
- 12-layer, 768-dimensional Transformer, mirrors the RoBERa base architecture
- initialized with pretrained RoBERTa weights
- to compute joint representations:
- 1) embed the tokens {W} via lookup
- 2) add position embeddings to both language and vision components. This is to distinguish between images and captions at different timestamps because the position embeddings differ between different segments.
- 3) pass the independant visual and textual feature maps to the joint encoder.
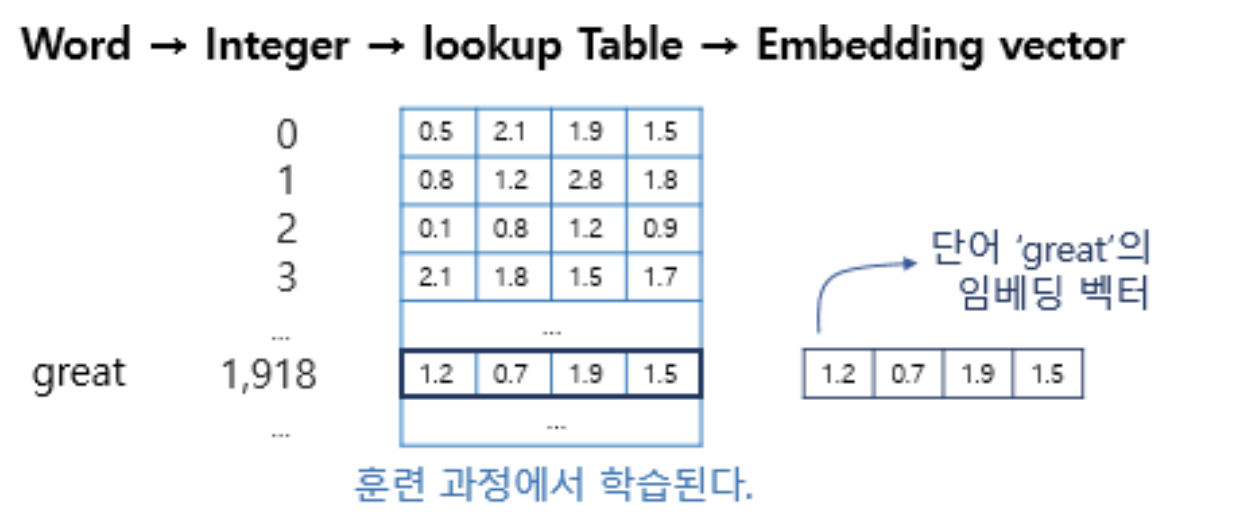
Embedding Lookup
어떤 단어 -> 단어에 부여된 고유한 정수값 -> 임베딩 층 통과 -> 밀집 벡터
고유 정수에 대해 밀집 벡터로 매핑하고, 이 밀집 벡터는 인공 신경망의 학습 과정에서 가중치가 학습되는 것과 같은 방식으로 훈련된다. 훈련 과정에서 단어는 모델이 풀고자하는 작업에 맞는 값으로 업데이트 된다.
- The feature maps for each frame I starts whith a CLS token(just like tokens W), and will later pool final-layer hidden-state representation for use in pretraining along with downstream tasks.
3.3 Pretraining Tasks and Objectives
- uses three objectives to pretrain MERLOT, which cover 'full-stack' visual reasoning(from frame-level to video-level).
1. Contrastive frame-transcript matching
-
uses video transcript to compute a 'language only' representation of each video segment(to ensure that the underlying image encoder produces helpful image representation)
-
uses a contrastive loss to maximize its similarity to corresponding representations from the image encoder.
Contrastive?
Contrastive Learning : 대상들의 차이를 더 명확하게 보여줄 수 있도록 학습하는 것.
Contrastive Loss : 서로 같은 클래스는 임베딩간 거리가 0, 다른 클래서는 margin 이상이 되도록 학습. -
the words W in each segment are often not sufficient to describe the gist(글,대화,문맥의 요지) of I or even what the objects might be - so video-level contesxtualization(맥락화) is often required.
-
To do above, passes the entire transcript into the language-only encoder, which then extracts hidden states for each segment at the segment-level CLS tokens.
-
positive representation = matching representations for each frame I and caption W
-
negative representation = comes from all other frame-caption pairs in the batch
-
projects above representations into a size-768 hidden state which is then unit-L2-normalized, then compute an all-pairs dot-product between all image and text representations.
-
above logits divided by a temperature of τ = 0.05, then applies a pairwise cross entropy loss to encourage matching captions and frames.
Dot-Product?
Dot Product: 내적. 유클리드 공간의 두 벡터로부터 실수 스칼라를 얻는 연산.
2. (Attention) Masked Language Modeling
-
words provided to the joint vision-and-language encoder:
- randomly replace 20% with a MASK token, a random word, or the same word.
-
MERLOT must then reconstruct the correct word with a cross-entropy loss.
-
Vanilla BERT-style masking : often causes ungrounded fillers(eg.umm, yea) to get masked, while important objects are often partially masked, penalizing the learning of multimodal representations. Not used for MERLOT.
-
Uses Attention Masking : uses attention weights from a language-only transformer as a heuristic(스스로 발견하게하는) for which words are grounded.
-
50% of the time, masks out a random token, the other 50% masks out one of the top 20% most-attended-to-tokens.
-
Then applies SpanBERT masking, randomly corrupting the following or preceding tokens with an average length of 0.5 tokens in each direction.
- above makes it harder for models to over-rely on BPE artifacts(산출물).
What does it mean by 'corrupting the following or preceding tokens with an average length of 0.5 tokens in each directions?'
BPE artifacts?
Token을 의미하는 듯 하다.
3. Temporal Reordering
- model have to order the image frames in a video, which means that the model has to learn temporal reasoning(시간적 추론).
- 40% of the time, the randomly scrambled i video frames(i개의 순서가 섞인 비디오 프레임) are given to the model by replacing the segment-level position embeddings.
- Above random position embeddings are learned, and seperate from the 'unshuffled' position embeddings.
- It allows the model to order each 'shuffled' frame conditioned on frames provided in the correct order.
- Reordering Loss:
- extracts hidden states from each frame at the CLS token position
- for each pair of frames, hidden states hti and htj are concatenated and the result is passed through a two-layer MLP predicting if ti < tj or ti > tj.
- optimized by using cross-entropy loss.
3.4 Pretraining MERLOT
- pretrain the model for 40 epochs over YT-Temporal-180M
- preprocess the dataset into examples with sequences of N=16 video segments each, containing up to L-32 BPE tokens.
- Language-only encoder computes contrastive representations given this entire sequence(total length=512 tokens)
- 4 groups of N=4 segements each provided to the joint vision-language encoder to save memory.
- joint model's sequence length = 396 tokens(at image resolution 192 x 352)
- combining losses:
- multiply contrastive loss by a coefficient of 0.25.
4. Experiments: Transferring MERLOT to Downstream Tasks
4.1 Image Tasks
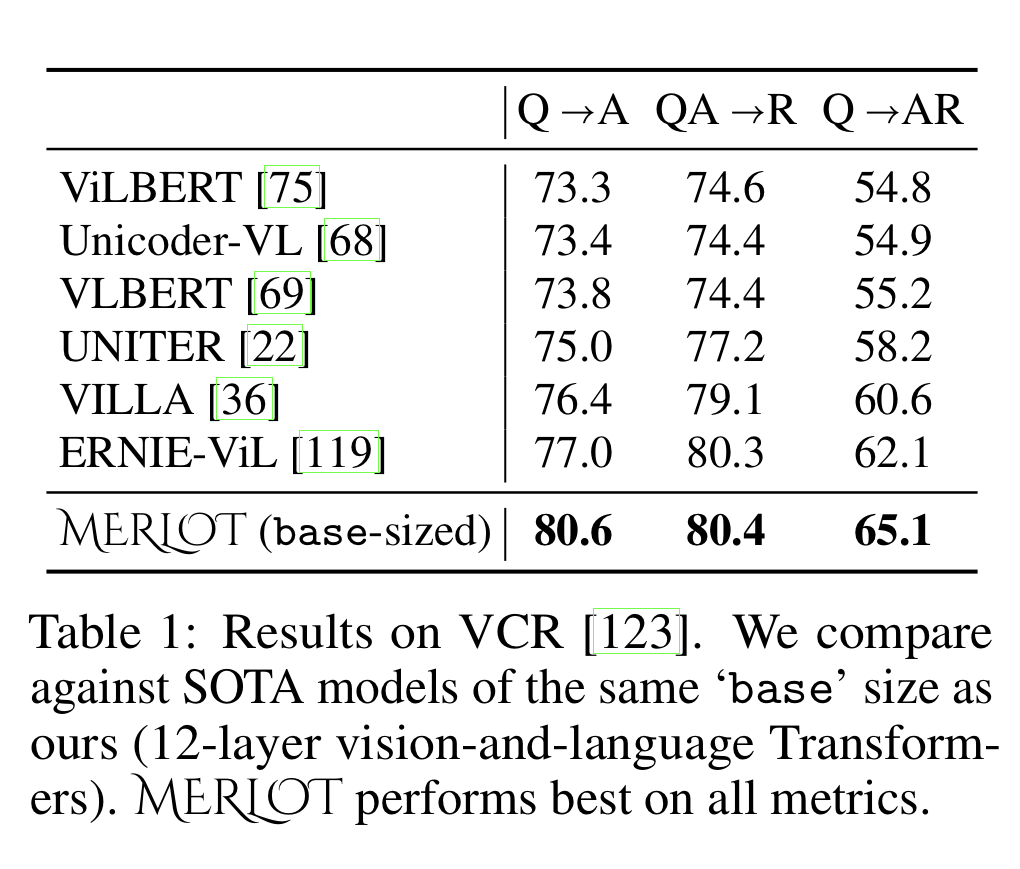
VCR
-
a task and dataset where models must answer commensense visual questions about images. (eg. 'what might happen next')
-
forces MERLOT to transfer video-level understanding to the world of single images.
-
provides additional 'referring expression(참조 대상/표현)' information to models in the form of bounding boxes around named entities. For example, if Person 1 is referenced in the question, the locantion of Person 1 is also given in the image. This information is provided to models by drawing a colored highlight around the referenced entity.
-
MERLOT outperforms other models, that all learn from exclusively static images(paired with captions and supervised object detections).
Unsupervised ordering of Visual Stories
- considers the Visual Storytelling dataset, so that the model can do out-of-th-box commensense reasoning over events in images.
- each story in the dataset contains five images and captions in a certain order. The order tells a joint narrative between the captions and images.
- unlike past works, models are given the captions in sorted order and must match frames to the captions. to avoid language-only biases.
- uses the temporal reordering loss to find the most probable ordering of the video frames.
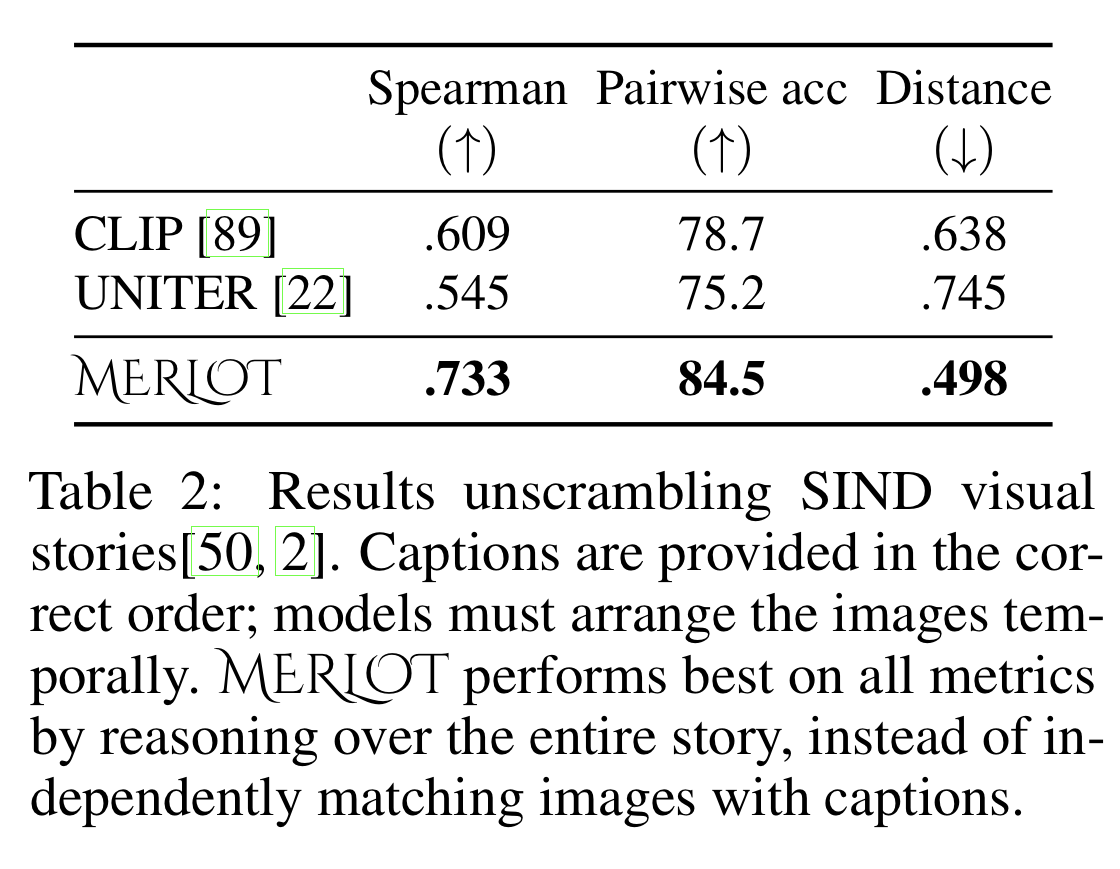
- results over 5K stories.
- no fine-tuning, MERLOT has strong capability about past and future events expressed in collections of temporal visual stories.
4.2 Video Reasoning
- results on 12 video reasoning :
- TVQA
- TVQA(+)
- VLEP
- MSRVTT-QA
- MSRVTT-Multichoice
- LSMDC-Multichoice
- LSMDC fill-in-the-blank QA
- ActivityNetQA
- TGIFQA
- DramaQA
- sample a sequence of 5 to 7 still frames from each video clip, initialize new parameters only to map the model's pooled CLS hidden state into the output labels
- finetune MERLOT with a softmax cross entropy loss.
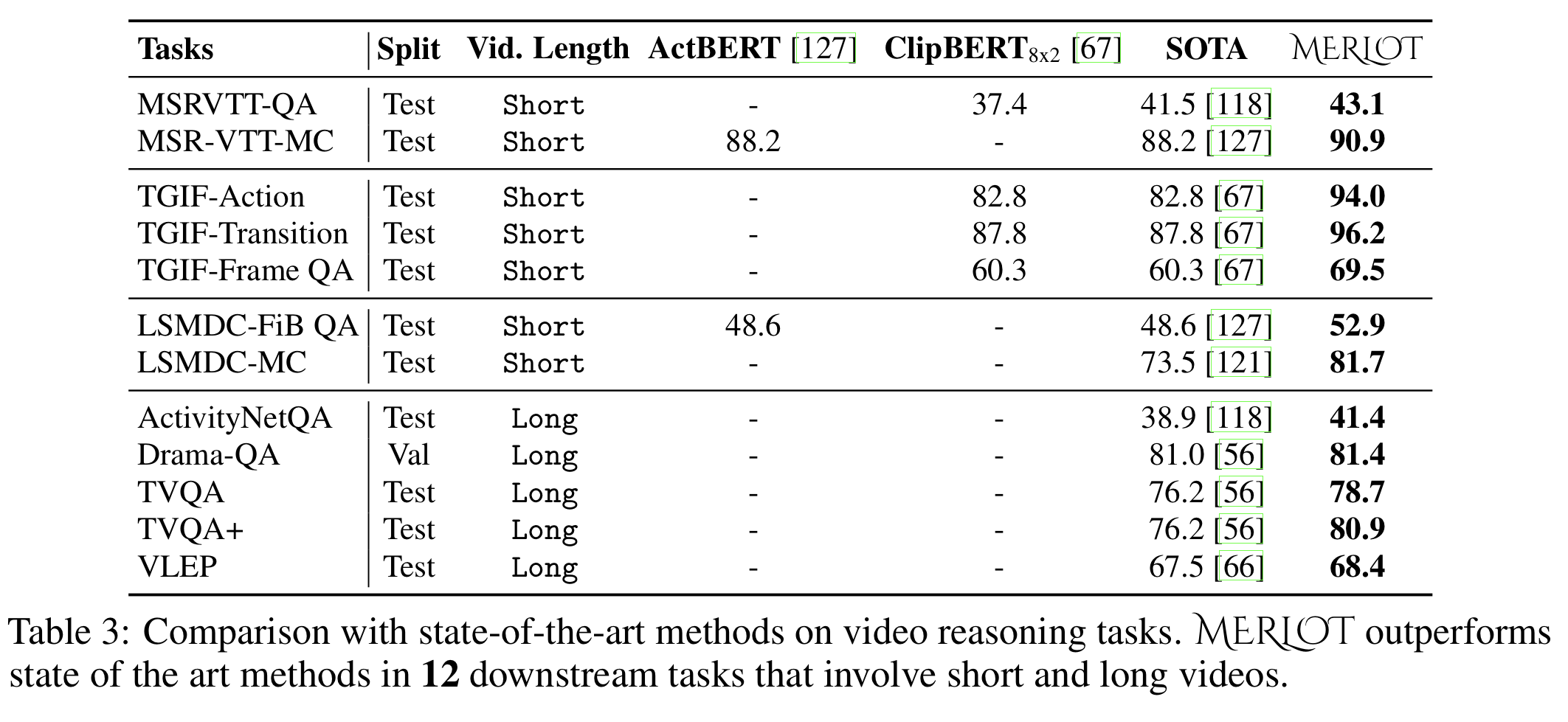
- for all the datasets listed above, MERLOT sets a new state-of-the-art.
- Above results provide strong evidence that MERLOT learned strong multimodal and temporal representations.
4.3 Ablations
- ablations over VCR and TVQA+
Context Size

- above table shows the effect of varying the number of segments N given to the joint vision-and-language encoder during pretraining.
- when the sequence length is expanded to N=4/128 tokens, attention masking becomes effective.
- supports hypothesis that text-only shortcuts become increasingly viable with length, so that attention-masking approach counteracts them.
recap:
SpanBERT masking [54], randomly corrupting the following or preceding tokens with an average length of 0.5 tokens in each direction; this makes it harder for models to over-rely on BPE artifacts.
Losses

- by ablating the losses, found that the contrastive frame-transcript matching loss is crucial to performance, which suggests that an explicit objective is critical for the image backbone to learn visual representation.
- Temporal ordering loss apprears less critical for downstream tasks.
Drawing bounding boxes

- performance drops 5% when the bounding boxes are removed, suggesting that they help.
Dataset Source

- investigate pretraining MERLOT on two other datasets
- 1) Conceptual Captions with MSCOCO
- model achieves 58.9% accuracy on VCR.
- Due to 1)a smaller context window, 2)overfitting.
- 2) HowTo100M
- using divers data(YT-Temporal-180M) improves VCR performance by 6.5 points.
- result suggests that the how-to domain is limited in terms of visual phenomena covered, and other domains provide helpful signal for tasks like VCR.
- 1) Conceptual Captions with MSCOCO
- using 'raw ASR' instead of the preprecessed ASR(adding punctuation etc.) reduces performance by 2.4 points.
Pretraining longer
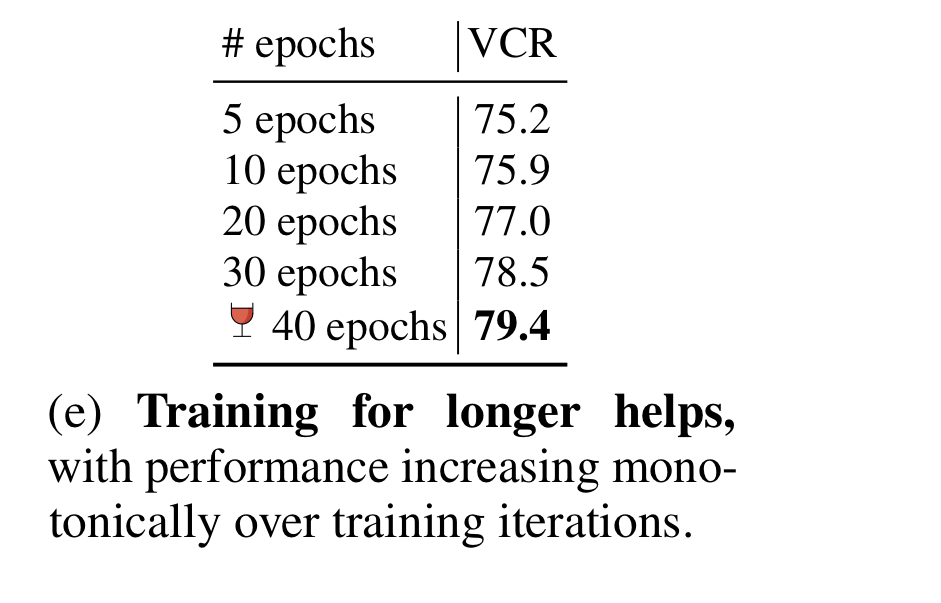
- the performance increases monotomically, and doesn't begin to plateau. -> could have pretrained MERLOT for even longer.
4.4 Qualitative examples

- two qualitative examples of MERLOT's zero-shot story ordering capability.
- In the first row, it orders the story correctly, performing vision-and-language coreference across several frames(e.g. frames and captions 2 and 3 use 'he' to refer to 'the old man' only mentioned in the first caption).
- MELOT gets the second row 'wrong', but for an interesting reason. It reverses the order of the frames (3) and (4), which groups the merry-go-round pictures together. This seems to capture the temporal commonsense intuition that people might ride a merry-go-round for a while.
