TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering
CMU MMML 강의 수강을 시작하면서 multimodal의 활용 분야들을 알게 되었는데, 이 논문은 여러 분야들 중 Visual Question Answering, 특히 영상에서 VQA를 수행할 때 고려해야하는 새로운 시각을 제안한다.
4 Questions to Answer
What did authors try to accomplish?
- 영상 VQA를 위해 시공간적 추론이 요구되는 task가 포함된 학습 데이터셋 제작(TGIF-QA)하여 시공간적 추론을 할 수 있는 모델 build.
What were the key elements of the approach?
1. dual-layer LSTM
- 이거로 영상과 QA 문장간의 영상-문자 관계를 파악한다.
- Spatio-level이랑 Temporal-level을 위해 ResNet이랑 C3D를 concat한 것을 visual encoder LSTM의 입력으로 받음.
2. TGIF-QA Dataset
- 고유한 objective(task)와 고유한 영상-문자의 원천.
이전 연구들에서 사용된 3가지의 task에 시공간적 추론이 요구되는 task 하나가 추가됨. 또한, 이전 연구들과는 다르게 Tumblr의 GIF를 데이터셋으로 사용함(이전에는 영화 영상을 데이터셋으로 사용함.) - 다른 데이터셋들보다 answer에서 dynamic verb(motion과 contact 카테고리의 동사들: kiss, touch, walk)를 더 많이 포함하고 있어 전체 맥락을 이해하기 위해서는 시공간적 추론을 해야하도록 함.
3. Spatio Attention, Temporal Attention
- spatio와 temporal을 위해 attention을 각각 사용함.
- spatio는 각 frame과 자막의 match를 위한거니까 모델의 앞 부분에 위치하고, temporal은 영상 전체의 흐름(sequence)를 이해하기 위한거니까 모델의 마지막 부분에 위치하였다고 생각.
- 특히 논문의 Figure 5에서 결과를 보면, temporal attention의 중요성을 알 수 있다. spatial attention만을 사용했을 때보다 temporal attention을 사용했을 때가 더 성능이 좋다.
What can you use yourself?
- 영상 VQA를 위해 spatio level뿐만 아니라 temporal level도 고려해야한다는 사실을 사용할 수 있을 것 같다. spatio-temporal 추론이 요구되는 task뿐만 아니라 다른 task에서도 ST-VQA의 성능이 다른 모델들에 비해 성능이 좋았다.
What other references do you want to follow?
- C3D. 이 모델을 처음 보는데, 왜 이 모델을 sequence feature을 얻기 위해 사용하는지 궁금하다.
- stacked LSTM. dual LSTM이 왜 사용되는지, dual LSTM을 사용했을 때의 이점이 무엇인지 공부해보고싶다.
0. Abstract (초록)
VQA는 모델이 시각 매체를 region-level에서 이해하고, 이해한 것과 자연어로 이루어져있는 <질문-정답>의 연관성을 찾는 것을 목표로 하는데, 이 분야는 여러 딥러닝 연구 분야들 중 가장 성공적인 분야들 중 하나이다.
지난 몇년간 빠른 속도의 발전에도 불구하고 대부분의 VQA 연구는 이미지에 초점을 맞추었다. 본 논문에서는 VQA를 영상으로 확장시키고, 모델의 문해력을 높이기 위해 3가지 방법을 제안한다.
1) 영상 VQA를 위한 3가지의 새로운 질문들을 추가한다. 추가된 질문들에 대해 옳은 대답을 하기 위해서는 영상으로부터 spatio-temporal reasoning(시공간적 추론)이 요구된다.
2) 영상 VQA를 위해 새로운 큰 데이터셋인 TGIF-QA를 사용한다.
3) 시간과 공간 각각의 attention이 사용되는 dual-LSTM을 기반의 접근법을 제시하고, 이 접근법의 영향력을 실증적인 평가를 통해 보여준다.
1. Introduction (서론)
VQA는 여러 딥러닝 연구 분야들 중 가장 성공적인 연구 분야들 중 하나인데, VQA의 성공 요인들 중 하나가 여러개의 잘 정의된 과제와 평가방법으로 구성된 여러개의 큰 데이터셋이 있다는 것이다. 이것은 VQA를 연구하는 사람들에게 common ground를 제공하여 통제된 설정에서 그들의 방법들을 비교할 수 있게 해주었다.
영상 분석에서 빠른 성장세를 보이고 있지만, VQA 연구 대부분은 이미지 중심이다. 본 논문 저자들은 영상 VQA 연구의 진행을 막는 것은 모델이 수행해야하는 과제가 잘 정의된 큰 데이터셋의 부족이기 때문이라고 지적한다.
따라서 본 논문에서는 초록에서 말한 3가지의 방법으로 VQA의 문해력을 높인다.

본 논문의 영상 VQA 과제는 repetition counting과 같은 video understanding 분야를 참고하여 만들었다. 3가지의 과제를 정의하는데,
( 1 ) 주어진 행동이 몇번 반복되는지 세기
( 2 ) 주어진 횟수와 일치하는 행동 찾기
( 3 ) 행동 변화 인지하기
위의 3가지 과제 이외에도 원래 VQA의 과제들도 수행하도록 구성했다.
본 논문에서는 영상 자막 생성을 위한 데이터셋인 TGIF(Tumblr GIF) 데이터셋을 바탕으로 새로운 데이터셋을 소개한다. TGIF 데이터셋은 애니메이션 GIF를 시각 자료로 사용하는데, 애니메이션 GIF는 형식이 간결하고 내용이 결합력이 있기 때문에 최근 컴퓨터 비전 분야의 매력적인 데이터 원천으로 떠올랐다. TGIF-QA 데이터셋은 57K개의 애니메이션 GIF와 이를 바탕으로 한 104K개의 QA pair으로 구성된 영상 VQA 분야의 데이터셋이다.
현재 최신 VQA 연구에서는 공간적 attention 메커니즘을 사용하여 "이미지 내에서 어디를 볼 것인지" 학습을 진행하여 이미지를 중점으로 visual-textual 연관성을 찾는 것에 집중하고 있다. 현재 존재하는 기법들은 이미지 VQA에서 좋은 성능을 보여주었지만, 영상 VQA로는 적합하지 않다. 영상은 공간과 시간 차원 모두에서 시각적 정보를 가지기 때문에 적절한 시공간적 추론 메커니즘을 사용해야한다. 본 논문에서는 LSTM을 QA pair뿐만 아니라 영상 input에서 적용하여 영상으로부터 얻을 수 있는 시공간적 정보를 활용한다. 공간과 시간 attention 메커니즘을 평가하여 선택적으로 영상의 특정 부분들을 attend할 수 있게한다.
요약:
-
영상 VQA를 위한 3가지의 새로운 질문(과제)들을 제안하며, 이 질문들에 올바르게 답하기 위해서는 시공간적 추론이 필요하다.
-
새로운 데이터셋인 TGIF-QA를 소개하며, 이 데이터셋은 104K개의 QA pair과 57K개의 애니메이션 GIF로 구성된다.
-
영상 VQA 과제를 수행하기 위해 attention 메커니즘과 dual-LSTM기반 접근법을 제안한다.
2. Related Works (관련 연구)
Datasets
대부분의 VQA 데이터셋은 이미지 중심적이어서 이미지 기반의 VQA에서 다뤄진다. 본 논문은 짧은 영상 클립들로부터 QA pair을 만들어 VQA를 영상 영역으로 넓힌다.
최근에 영화를 기반으로 영상 VQA 데이터셋을 만든 사례들이 있다. 그러나 본 연구에서는 영상의 범위를 영화로 한정짓지 않고 형식이 간결하고 내용이 통일성이 있는 인터넷의 애니메이션 GIF를 활용한다.
Tasks
현재 존재하고 있는 VQA에서의 QA pair들은 open-ended(빈칸채우기도 해당)이거나 multiple choice이다.
Open-Ended question: 완성 또는 미완성 문장을 제공하고, 옳은 단어를 추론해야한다.
Multiple Choice questions: 문자 또는 바운딩 박스로 여러개의 정답 후보를 제공하며, 옳은 정답을 골라야한다.
본 연구에서 사용되는 QA pair들은 open-ended와 multiple choice가 함께 섞여있다.
또한, 현재 존재하는 VQA 질문(과제)들은 이미지 중심적이기 때문에 이미지에 드러나있는 시각적인 질문만 물어본다. 본 연구에서의 질문들은 frame-level에서 시공간적 추론이 요구된다(반복 횟수 세기, 행동 변화 암기)
본 연구에서 사용되는 데이터셋은 문맥 이해보다 시공간 추론에 더 초점을 맞추고, 문자적 신호(영화 스크립트)보다 시각적 신호를 이해하는 것에 더 집중했다.
Techniques
본 연구에서는 영상과 QA pair을 표현하기 위해 LSTM을 사용했고, input word representation과 output word representation 모두에서 의미론적 attention 메커니즘을 수용했다.
또한, 영상과 QA pair을 표현하기 위해 다른 attention 메커니즘과 LSTM을 사용하여 영상에서 복잡한 시공간적 패턴을 찾을 수 있게한다.
3. TGIF-QA Dataset
TGIF-QA 데이터셋은 56,720개의 애니메이션 GIF로부터 얻은 103,919개의 QA pair으로 구성된다.
3.1 Task Definition (과제 정의)
TGIF-QA 데이터셋에서는 4가지의 질문(과제)들을 소개하는데, 그들 중 3가지가 영상 VQA에서 새로운 유형의 질문들이다.
Video QA
Repetition Count
하나의 행동이 영상에서 몇 번 반복되는지 세는 개방형 질문이다.
Repeating Action
위의 repetition count와 유사하다. 영상 내에서 반복되는 행동을 파악하는 객관식 과제이며, 5가지의 선택지를 제공한다.
State Transition
특정 상태 전 또는 후의 상태가 무엇인지 파악하는 객관식 과제이며, 5가지의 선택지를 제공한다. 얼굴 표정(행복 - 슬픔), 행동(달리기 - 걷기), 장소(테이블 - 바닥), 물체 상태(빈 - 가득찬)의 변화를 파악하는 것이 state transition에 포함된다.
위의 3가지 과제들은 영상의 여러 프레임을 분석하는 것이 요구되며, 이 세가지 질문들을 video QA라고 총칭한다.
Frame QA
3가지 질문들 이외에도 하나의 과제를 더 추가하는데, frame QA라고 불리며 영상의 하나의 프레임으로부터 정답을 얻을 수 있는 과제이다.
이 과제를 위해 TGIF에서 제공하는 영상 자막을 NLP 기반 기법으로 활용하여 자막으로 자동적으로 QA pair을 만들었다.
개방형 질문이며, 완성된 문장으로 질문이 주어졌을 때 질문에 대한 가장 알맞는 정답을 해야하는 과제이다.
3.2 QA Collection (QA 수집)
Frame QA 수집을 위해서 Ren et al.의 Exploring Models and Data for Image Question Answering 논문에서 사용된 방법을 TGIF 데이터셋의 자막에 그대로 적용하였다.
이 방식으로 51,225개의 GIF로부터 53,083개의 QA pair을 만들었다.
영상 QA를 위해서 크라우드소싱과 template-based 접근법을 혼합하였다. 이를 통해 19,485개의 GIF로부터 50,836개의 QA pair을 만들었다.
Croudsourcing
2가지의 정보를 모으는 크라우드소싱 연구를 진행했다.
1) 반복
반복되는 행동에 대한 주어, 동사, 목적어, 그리고 반복 횟수
2) 상태 변화
주어, 변화 유형(표정, 행동, 장소, 또는 물체 중 하나), 변화된 상태 이전 상태 또는 다음 상태.
총 568명이 참여했으며, 하나의 비디오클립마다 5센트를 받았다.
Quality Control
정의한 과제들 중 입력 데이터의 형태가 정해지지 않은 과제가 포함되어 있기 때문에 입력 데이터의 품질 상태가 매우 중요하다.
본 연구에서는 자동으로 부주의한 참여자들을 확인하고 걸러내었다. 159개의 반복 영상 클립과 172개의 상태 변화 영상 클립으로 구성된 validation set을 만들어서 직접 적절한 정답을 달았고, 참여자들의 과제에 이를 포함하여 제대로 답을 다는지 확인했다. validation set에 올바른 답을 하지 못한 참여자들은 블랙리스트에 올려서 다른 과제에 참여하지 못하도록 하였고, 제출한 정답은 사용하지 않았다.
Post Processing
WordNet lemmatizer을 이용하여 모든 동사를 정리했으며, VerbNet을 사용하여 각각의 상태에서 주된 동사를 찾아내었다. DBpedia Spotlight로 정답에서 얻어진 적절한 명사들을 찾았고, 그것들을 동일한 더 널리 쓰이는 명사로 변경했다(사람 이름, 동물 이름, 신체부위 등). 또한, 정답에 있는 소유격을 모두 제거하였다.
QA Generation

위의 Table 2에 따라 QA pair을 만들었다. 만들어진 질문들에 문법적 오류가 있을 수 있는데, 그러한 오류들은 LanguageTool으로 수정하였다.
그 후, 각각의 QA pair마다 객관식 문항들을 만들기 위해 데이터셋에서 4개의 문장들을 선택하며, 자세한 방법은 아래와 같다.
Dictionary의 모든 동사를 Common Crawl Dataset에 pretrained된 GloVe word embedding을 이용해 300D 벡터로 표현한다. 그 후, 동사와 정답간의 cosine similarity가 중위값보다 큰 동시에 후보 동사들간의 cosine similarity가 최대인 동사 4개를 선정한다. 이후, 후보 동사들이 들어간 문장 4개를 랜덤으로 선정한다.
행동 반복 횟수를 세는 과제에서는 반복되는 횟수가 0인 데이터도 추가하였다.
3.3 Comparison with Other Video VQA Datasets

위의 Table 4에서는 다른 2개의 VQA 데이터셋과 TGIF-QA 데이터셋을 비교한다. LMSDC-QA는 LSMDC 2016의 VQA task에서 사용된 데이터를 의미한다.
위의 Table 4에서는 다른 두 데이터셋은 영화 영상으로 이루어진 데이터셋인 것과는 다르게 TGIF-QA는 소셜미디어의 GIF로 이루어진 데이터셋이어서 영상과 문자의 원천과 객관성 측면에서 유일하다는 것을 보여준다.
또한, TGIF-QA는 다른 두 데이터셋과는 달리 개방형 질문과 객관식 질문이 모두 존재한다.
TGIF-QA는 LSMDC-QA보다 작지만 영상 VQA에 고유한 과제들을 포함한다. 그래서 TGIF-QA는 기존 데이터셋들을 고유한 과제들로 보충할 수 있다.
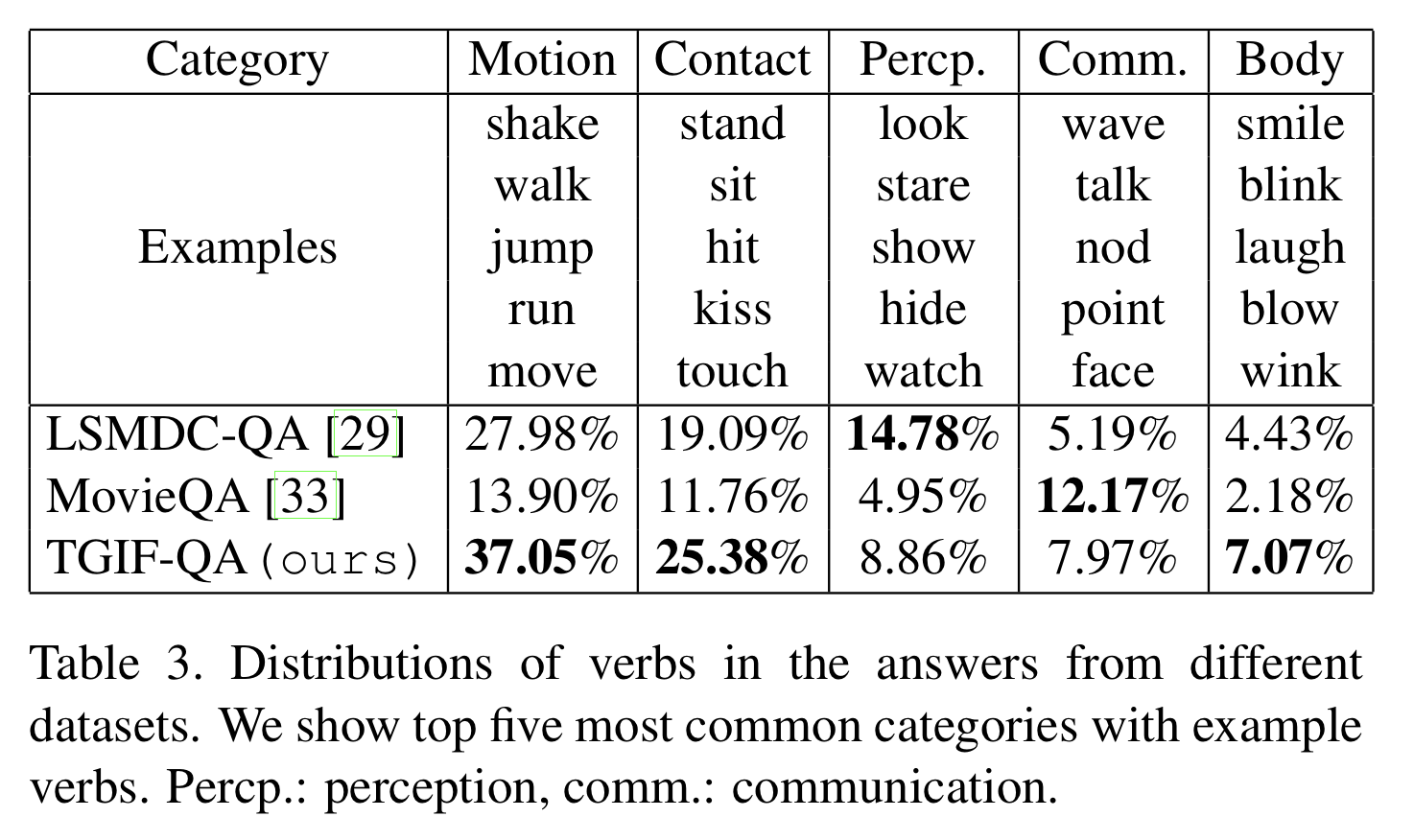
Table 3은 정답에서 사용된 동사의 분포를 보여준다. WordNet hierarchy에서 얻어진 가장 흔한 동사 유형 5개를 보여준다. TGIF-QA는 motion과 contact 유형의 동사들과 같은 동적인 동사들을 다수 포함하며, 이 특징은 영상을 이해하기 위한 시공간적 추론의 필요성을 제시하기 때문에 TGIF-QA의 매우 중요한 특징이라고 할 수 있다.
4. Approach
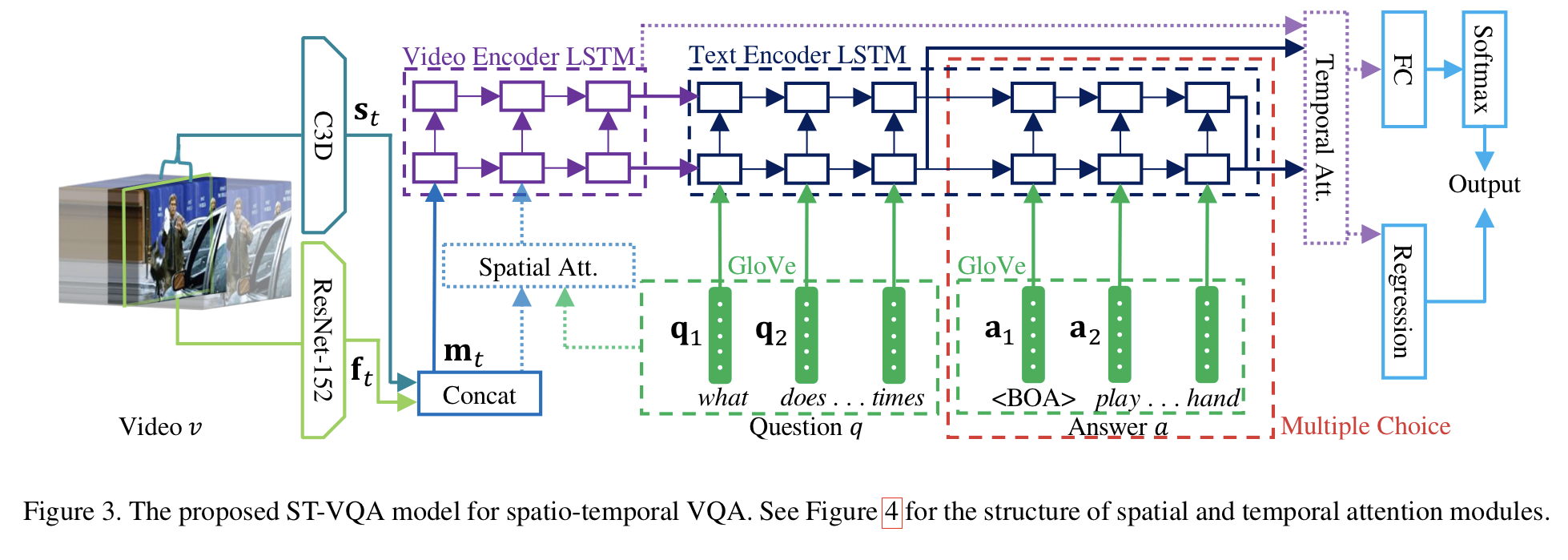
본 연구에서는 Spatio-Temporal VQA(ST-VQA) 모델을 사용한다. 모델의 입력으로는 video, question sentence, answer phrase로 구성되어있는 튜플 (v, q, a)를 받는다. 여기서 answer phrase는 필수 입력 요소가 아니며, 객관식 질문에만 제공된다(Figure 3의 빨간색 점선 참고). 출력의 경우, 개방형 질문일 경우 단어 하나이며, 객관식 질문일 경우 호환성 점수 벡터이다. ST-VQA 모델은 각각의 입력마다 dual-layer LSTM을 사용하여 영상과 QA 문장 간의 영상-문자 관계를 파악한다.
4.1 Feature Representation
Video Representation
Frame-level과 sequence-level 모두에서 영상을 표현한다. Frame-level의 경우, ImageNet 2012 데이터셋을 pretrain한 ResNet-152를 사용하고, sequence-level의 경우 Sport1M 데이터셋을 pretrain한 C3D를 사용한다. 불필요한 프레임의 반복을 줄이기 위해 4개의 프레임마다 하나를 수집한다. C3D에서는 각 time step마다 16개의 연속적인 프레임을 중앙으로 하고, 만약 영상 길이가 짧다면 첫번째나 마지막 프레임을 패딩한다.
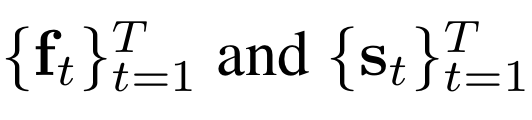
{f}은 ResNet-152를 의미하고, {s}은 C3D를 의미하며, T는 sequence의 길이이다.
Spatio-temporal attention 메커니즘의 사용 여부에 따라 다른 feature representation을 사용한다. ResNet-152의 경우, spatial attention 메커니즘을 사용할 때는 res5c layer의 feature map이 feature이 되며, 사용하지 않을 때는 pool5의 feature이 ResNet-152의 feature이 된다. C3D의 경우, spatial attention 메커니즘을 사용할 때는 conv5b layer의 feature map이 feature이 되며, 사용하지 않을 때는 fc6의 feature이 C3D의 feature이 된다.
Text Representation
문자 입력에는 질문과 정답, 즉 두 가지의 유형이 존재한다.
질문은 완전한 문장이지만, 정답은 문구이다. 본 연구에서는 두 유형 모두 단어의 연속으로 고려하고 같은 방식으로 표현한다.
Common Crawl 데이터셋으로 pretrain한 GloVe word embedding을 활용하여 주어진 데이터의 각 단어를 300D 벡터로 표현한다.
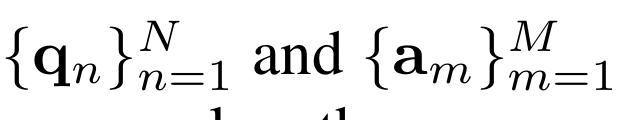
{q}은 질문 벡터이며, {a}은 정답 벡터이다. N과 M은 sequence의 길이를 의미한다.
4.2 Video and Text Encoders
Video Encoder
Figure 3의 보라색 박스를 보면 알 수 있듯이, video encoding LSTM을 사용하여 영상 feature인 {s}(C3D)와 {f}(ResNet-152)를 encoding한다.

먼저 두 feature을 concatenate하고, 그것을 dual-layer LSTM에 차례대로 넣어 각 차례마다 hidden state인 h를 얻는다.
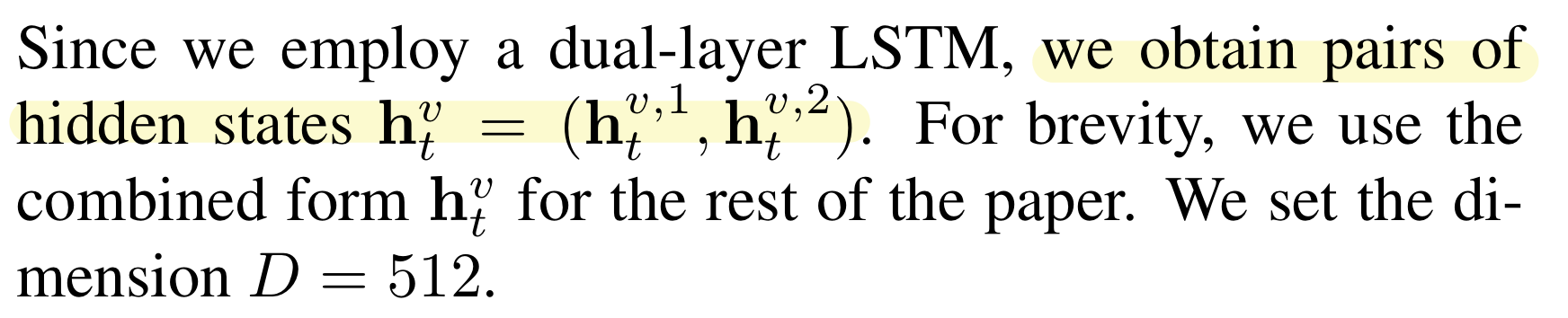
본 연구에서는 dual-LSTM을 사용하기 때문에 한 쌍의 hidden state를 얻는다.
Text Encoder
Figure 3의 남색 박스를 보면 알 수 있듯이, text encoding LSTM을 사용하여 문자 feature인 {q}(질문)과 {a}(정답)을 encoding한다.
개방형 질문들은 정답이 없고 문제만 있지만, 객관식 질문들은 문제와 정답 후보들이 있다. 본 연구에서는 질문과 각각의 정답 후보들을 dual-layer LSTM으로 encoding한다.
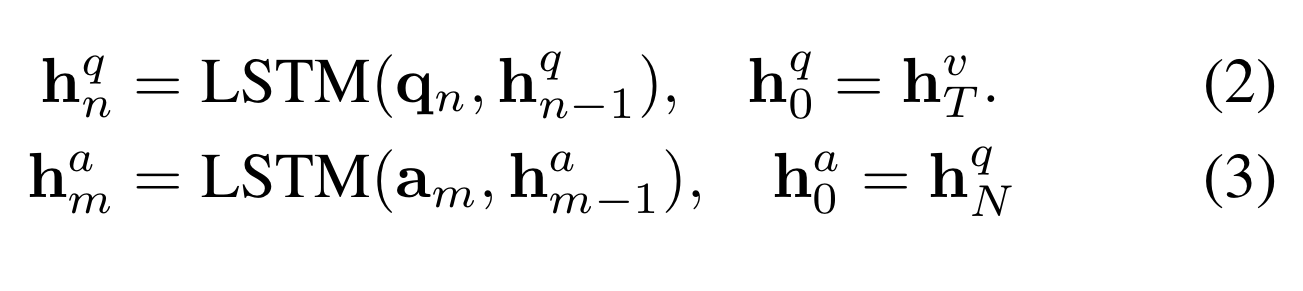

문제의 첫 hidden state인 h를 video encoder의 hidden state인 h로 설정하여 영상 정보가 text encoder으로 넘어가도록 한다. 또한, 정답의 첫 hidden state인 h를 질문의 마지막 hidden state encoder으로 설정한다.
4.3 Answer Decoders
객관식 1개, 그리고 개방형 2개로 총 3개의 정답을 제시하는 decoder을 만들었다.
Multiple Choice
answer encoder의 마지막 hidden state인 h를 W가 모델의 파라미터인 linear regression의 입력으로 받고, 각 정답 후보에 대한 실제 점수를 계산한다.
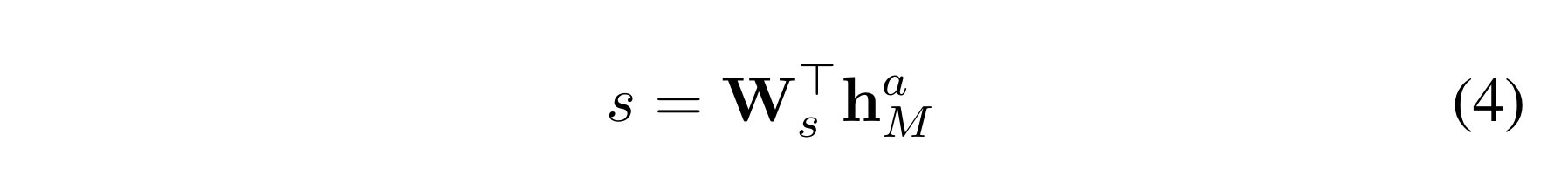
아래와 같이 짝비교(pairwise comparison)의 hinge loss를 최소화하는 방식으로 decoder를 학습시킨다.
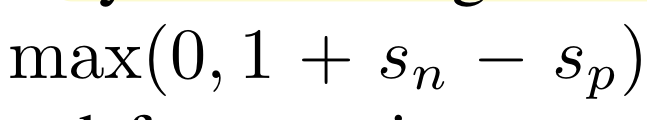
여기에서 Sn과 Sp는 틀린 답과 옳은 답으로부터 계산된 점수를 의미한다.
이 decoder을 이용하여 반복되는 행동을 찾는 과제와 상태 변화에 대한 과제를 해결한다.
Open-ended, number
Multiple Choice와 비슷하게, answer encoder의 마지막 hidden state인 h를 linear regression의 입력으로 받으며 위의 (4)번 식에 bias인 b를 더하여 정수 값의 정답을 계산한다. 정답과 예측값 사이의 L2 loss를 최소화하는 방식으로 decoder을 학습시킨다.
이 decoder을 이용하여 반복 행동 횟수를 세는 과제를 해결한다.
Open-ended, word
question encoder의 마지막 hidden state인 h를 입력으로 받으며 vector o의 confidence score를 계산하여 단어 집합인(vocabulary of words) V에서 정답을 선택한다.
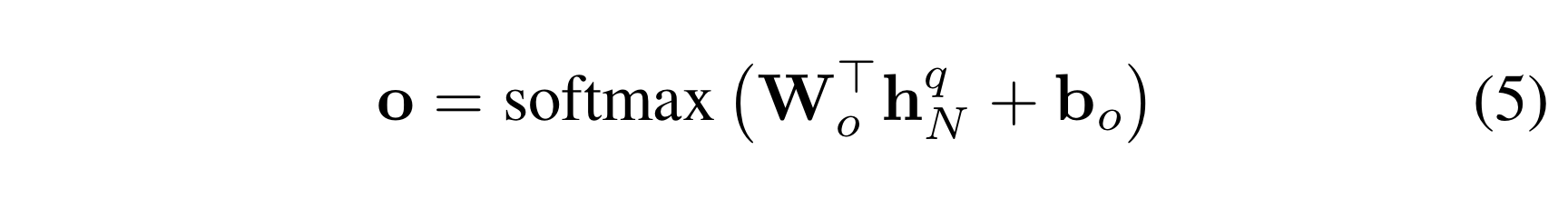
여기서 W와 b는 모델의 파라미터이다. Softmax loss fuction을 최소화하는 방식으로 decoder을 학습시킨다. 최종 정답은 아래의 식으로 얻어진다.
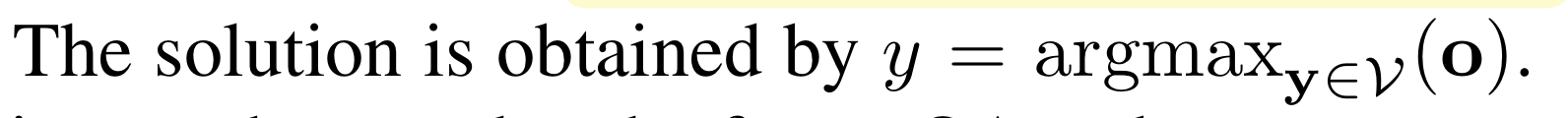
이 decoder으로 frame QA 과제들을 해결한다.
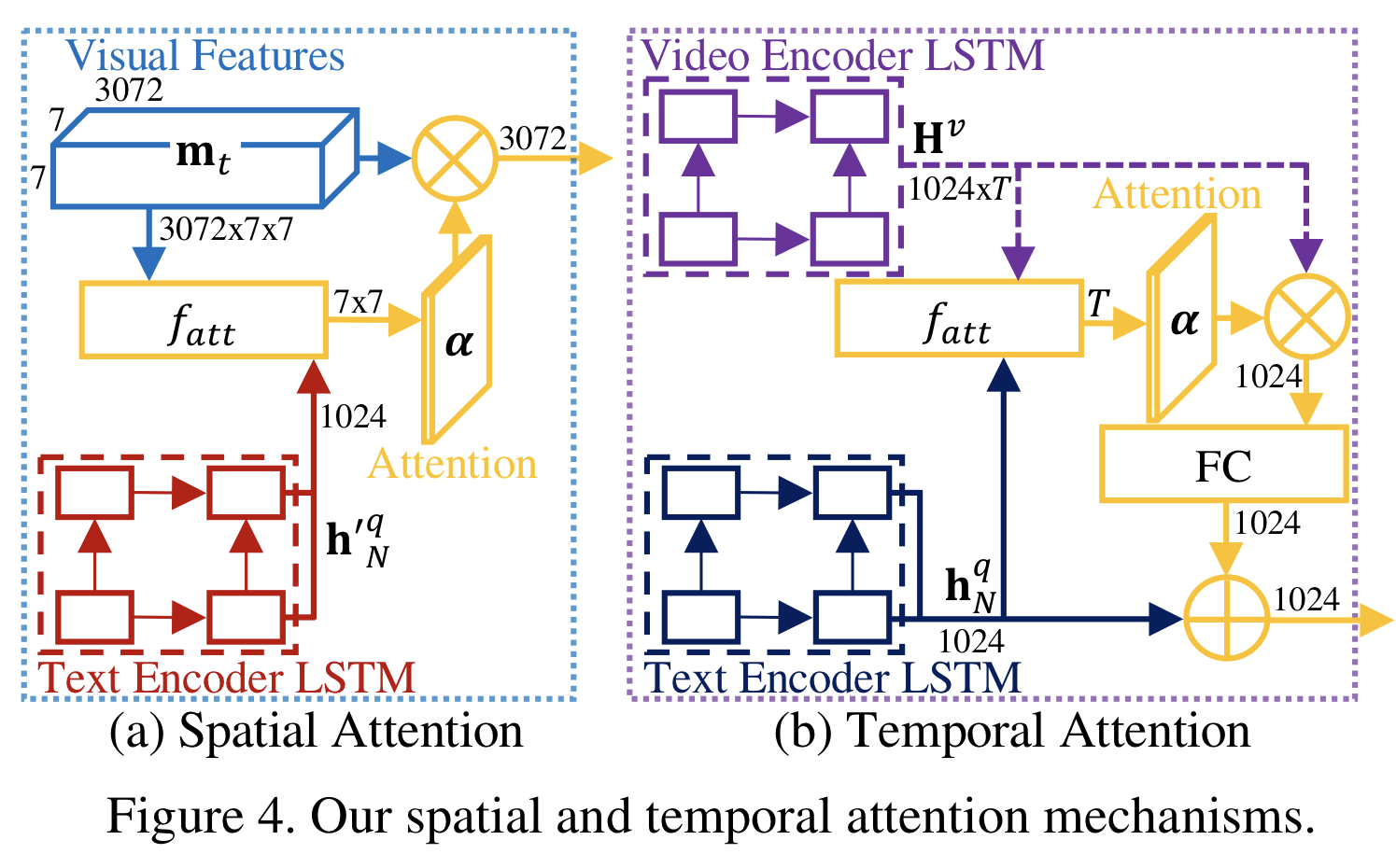
4.4 Attention Mechanism
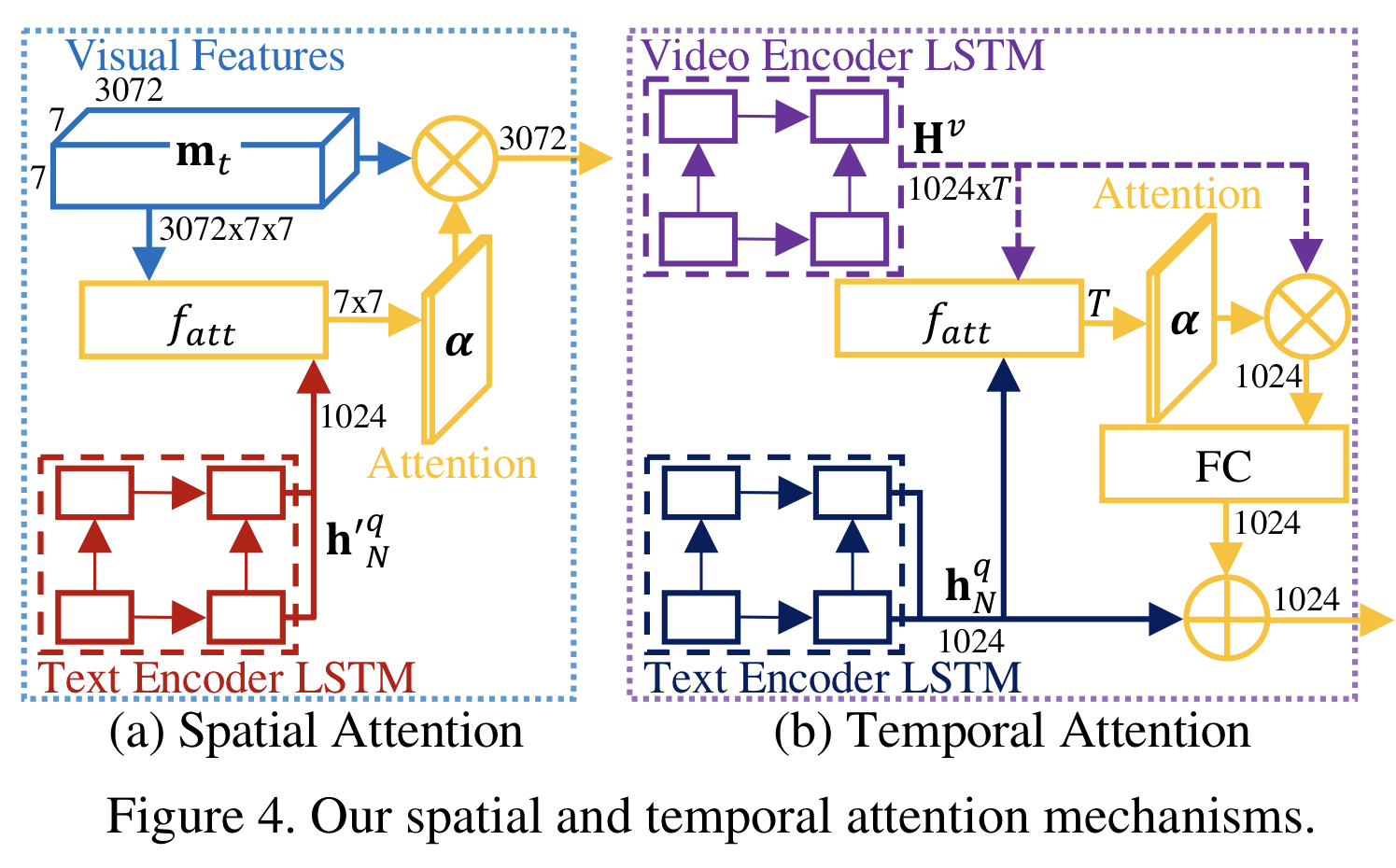
본 연구의 과제들이 영상에 대한 시공간적 추론을 필요로하지만, 지금까지 소개한 모델은 video encoder이 영상의 시공간적 정보의 필수적인 세부 내용을 단순화시켜 표현하기때문에 과제들을 해결하는 것에 적합하지 않다. 그래서 본 연구에서 사용되는 Figure 4과 같은 시공간 Attention mechanism을 이제 설명하려고 한다. 지금까지 설명한 모델 부분들은 각 frame에서 어떤 곳을 봐야할지 학습하게 해주었다면, 지금부터는 과제를 해결하기 위해 어떤 frame을 봐야할지 학습하게 해준다. 각 attention의 종류에 따라 다른 메커니즘을 적용하는데, 공간적 attention은 Xu et al의 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention을 참고하였고, 시간적 attention은 Bahdanau et al의 Neural Machine Translation by Jointly Learning to Align and Translate을 참고하였다.
Spatial Attention
각 단어마다 frame의 어떤 위치를 봐야하는지 학습하기 위해서 공간적 정보가 보존되어있는 시각 정보(표현)과 QA pair을 연관시킨다. 또한, 영상 decoder에서 각 frame을 encoding할 때 문자적 신호가 필요하다. 그러나 모델이 영상을 encoding한 후에 QA pair을 받기 때문에 해당 정보는 미리 알 수 없다. 본 연구에서는 문자 encoder과 모델의 파라미터를 공유하는 또 다른 dual-layer LSTM을 정의함으로써 간단히 해결한다.
Figure 4의 (a)가 공간 attention mechanism을 보여준다. 영상에서 각 time step마다 아래와 같은 7 x 7 공간 attention mask를 수행한다.
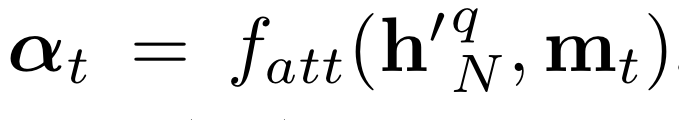
여기에서 h'은 문자 encoder의 출력값이고, m은 시각정보의 feature map이다.
그 후, 아래와 같은 attended 시각 정보(표현)를 영상 encoder으로 전달한다.
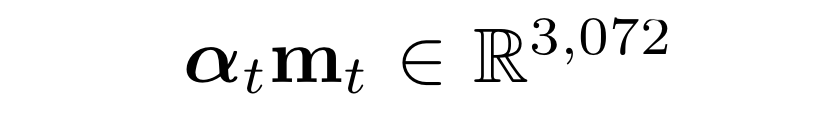
att 함수는 multi-layer perceptron(MLP)와 softmax function으로 구성되어진다. 여기에서 MLP는 512개의 노드로 이루어져 있고, tanh 활성화함수가 사용된다.
Temporal Attention
영상에서 어떤 frame을 봐야하는지 학습하기 위해서 시간적 정보가 보존되어있는 시각 정보(표현)과 QA pair을 연관시킨다.
Figure 4의 (b)가 시간 attention mechanism을 보여준다.
영상과 질문들을 encoding한 후에, 아래와 같은 1 x T 시각 attention mask를 수행한다.
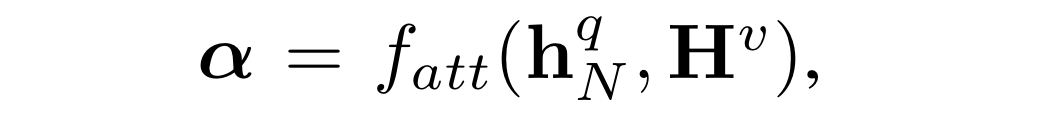
여기에서 h는 문자 encoder의 마지막 state이고, H는 영상 encoder의 state sequence이다.
그 후, 아래와 같이 attended textual signal을 계산한다.
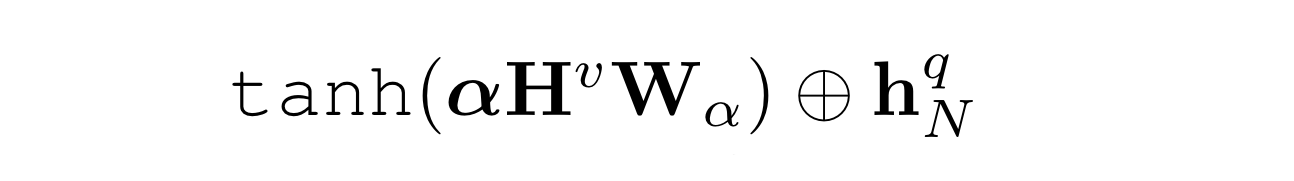
여기에서 +는 element-wise 합이며, 이것은 정답 decoder으로 전달된다.
공간적 차원 T에 대한 attention과 동일한 att 함수를 사용한다.
4.5 Implementation Details
본 연구에서는 영상과 QA text로부터 특징을 얻기 위해 ResNet, C3D, 그리고 GloVe를 사용했다. 모델의 다른 부분들은 모두 TensorFlow를 사용했다. dual-layer LSTM의 경우, dropout rate 0.2와 layer normalization을 모든 노드에 적용한다. 학습을 위해 ADAM optimizer을 사용하였고, 초기 Learning Rate로는 0.001을 지정하였다. LSTM의 가중치는 모두 균일 분포에서 초기화되었고, 다른 가중치들은 정규분포에서 초기화되었다.
