Very Deep Convolutional Networks for Large-Scale Image Recognition(VGGNet) - 논문 구현
Paper Review
VGGNet은 ILSVRC 2014에서 2등을 한 컴퓨터 비전 모델이다.
이번 포스팅에서는 본 논문의 Introduction, ConvNet Configurations를 정리하고, VGGNet의 구현 코드를 작성해볼 예정이다.
1. Introduction
최근 Convolutional Network는 ImageNet과 같은 큰 데이터셋의 쉬운 접근과 컴퓨팅 시스템의 높은 성능(GPU) 덕분에 큰 데이터셋에서의 이미지와 비디오 인식에서 큰 성공을 이루었다.
컴퓨터 비전 분야에서 Convolutional Network가 많이 사용되기 시작하면서, AlexNet의 정확도를 향상시키고자 하는 많은 시도들이 이루어졌다. 본 논문 또한 같은 선상에서 정확도를 향상시키는 것에 초점을 맞추고 있으며, Convolution Network의 깊이를 증가시킴으로써 정확도를 향상시키려고 한다. 본 논문에서는 Convolution layer을 추가함으로써 깊이를 증가시키는데, 3x3 convolutional filter을 사용함으로써 실현 가능했다.
2. ConvNet Configurations
2-1. Architecture
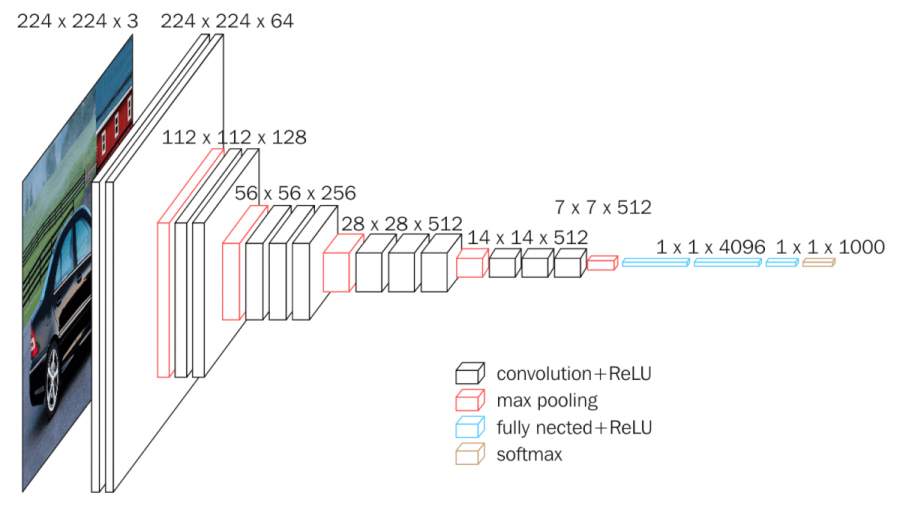
Convolution Network에서 입력 사이즈를 224x224 RGB를 고정적으로 사용한다. 이미지 전처리로는 mean-RGB를 subtract함으로써 normalizing을 진행한다. 전처리된 이미지는 convolutional layer들을 지나게 되는데, 이 때 위에서 언급했듯이 3x3이라는 작은 receptive field의 filter을 사용한다. Stride는 1이며, padding으로 1을 설정하여 이미지 사이즈를 유지하였다. MaxPooling도 사용하는데, 2x2 pixel window와 stride를 2로 설정하였다.
Convolutional Layer들을 지난 후에 총 4개의 Fully Connecetd Layer을 지나게 된다. 첫 2개의 FC layer들은 채널을 4096으로 설정하고 각 layer 뒤에 dropout을 0.5로 설정했다. 세번째 layer과 softmax layer은 class 수만큼 채널을 설정하였다. 마지막 FC layer을 제외한 모든 layer은 relu를 활성화함수로 사용하였다.
2-2. Configurations
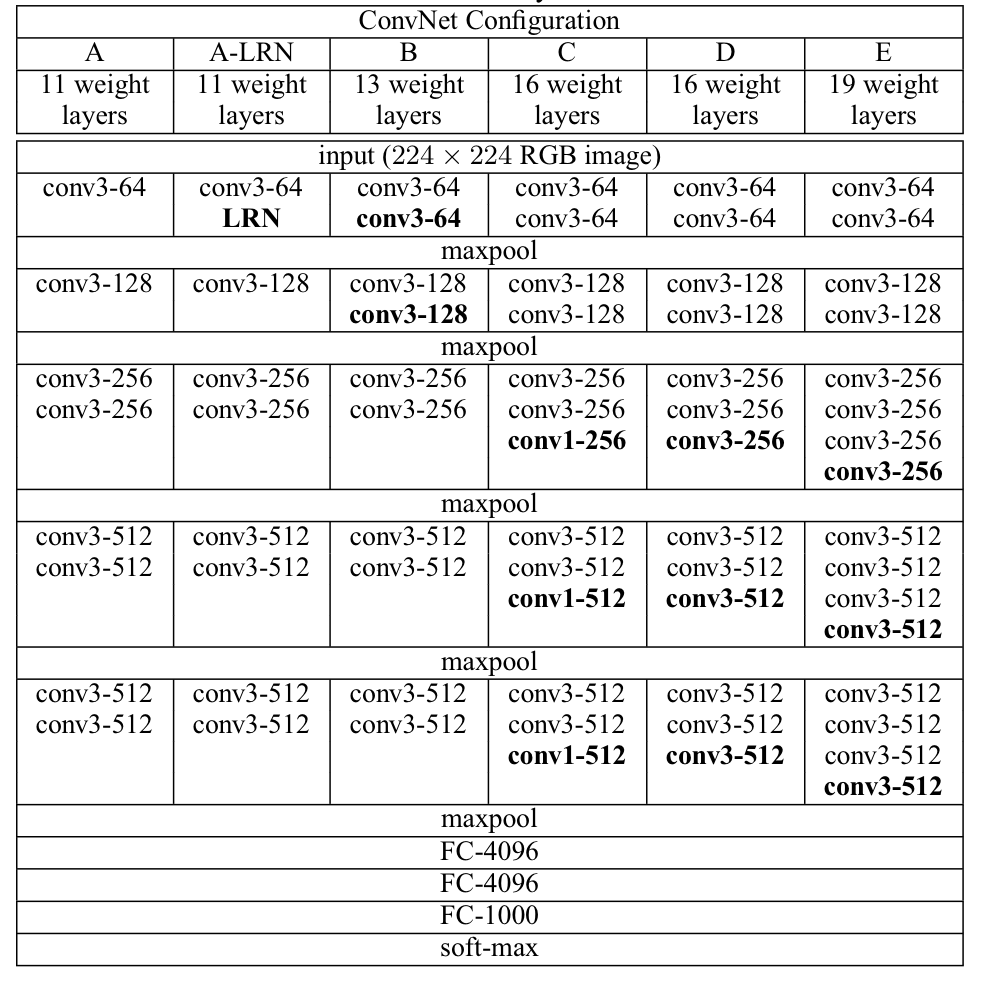
모든 구성(A-E)은 깊이에서의 차이만 있으며, 구조는 2.1과 같다.
2-3. Discussion
VGGNet은 이전 논문들에서 제시된 모델들과는 다르게 큰 receptive field가 아닌 작은 receptive field(3x3)를 모델 전체에서 사용한다.
3x3 convolutional filter
3x3 convolutional filter으로 두 번 연산을 하는 것과 5x5 convolutional filter으로 한 번 연산을 하는 것은 아래의 이미지와 같이 결과적으로 동일한 사이즈의 특성맵을 산출한다. 3x3 convolutional filter으로 세 번 연산을 하는 것은 7x7 필터로 한 번 연산을 하는 것과 대응된다.
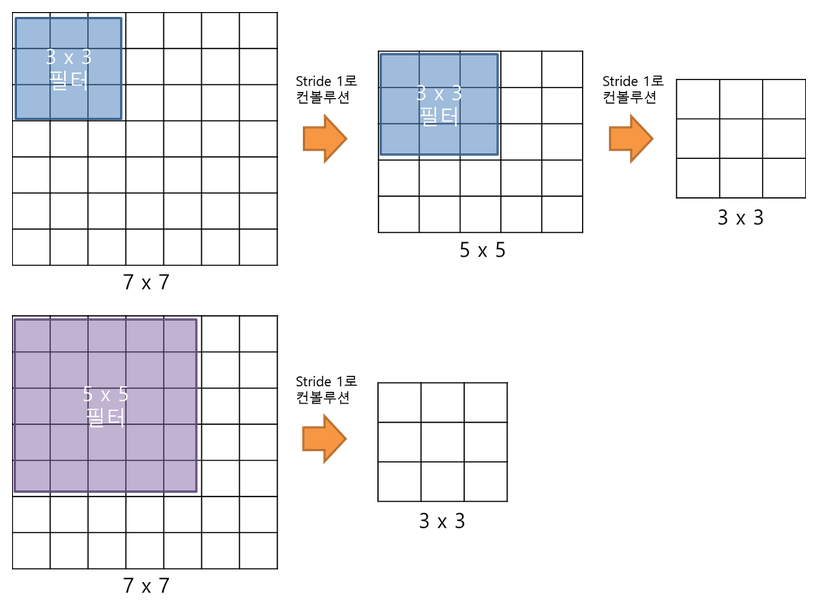
3x3 convolutional filter을 여러번 사용할 때의 이점은 아래와 같다.
- 하나의 비선형함수만 지나지 않고 여러번 지남으로써 비선형성이 증가하여 모데의 특징 식별성이 증가한다.
- 파라미터의 수가 감소한다.

실제로 table 2를 보면 알 수 있듯이, 11개의 layer으로 구성된 A와 19개의 layer으로 구성된 E의 파라미터 수를 비교했을 때 11개밖에 차이가 나지 않는 것을 알 수 있다.
논문 구현
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, Dropout, Flatten, Activation, MaxPooling2D
def vggmodel_E(in_shape=(224, 224, 3), classes = 10):
input_tensor = Input(in_shape)
#filter_size = 64
x = Conv2D(64, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-64_1')(input_tensor)
x = Conv2D(64, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-64_2')(x)
x = MaxPooling2D((2, 2), strides = 2, name = 'MaxPooling_1')(x)
#filter_size = 128
x = Conv2D(128, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-128_1')(x)
x = Conv2D(128, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-128_2')(x)
x = MaxPooling2D((2, 2), strides = 2, name = 'MaxPooling_2')(x)
#filter_size = 256
x = Conv2D(256, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-256_1')(x)
x = Conv2D(256, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-256_2')(x)
x = Conv2D(256, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-256_3')(x)
x = Conv2D(256, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-256_4')(x)
x = MaxPooling2D((2, 2), strides = 2, name = 'MaxPooling_3')(x)
#filter_size = 512 #1
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_1')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_2')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_3')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_4')(x)
x = MaxPooling2D((2, 2), strides = 2, name = 'MaxPooling_4')(x)
#filter_size = 512 #2
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_5')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_6')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_7')(x)
x = Conv2D(512, (3, 3), strides = 1, padding = 1, activation = 'relu', name = 'conv3-512_8')(x)
x = MaxPooling2D((2, 2), strides = 2, name = 'MaxPooling_5')(x)
#fully connected
x = Dense(4096, activation = 'relu', name = 'FC-4096_1')(x)
x = Dropout(0.5, name = 'dropout_1')(x)
x = Dense(4096, activation = 'relu', name = 'FC-4096_2')(x)
x = Dropout(0.5, name = 'dropout_2')(x)
x = Dense(classes, activation = 'relu', name = 'FC-n_classes')(x)
output = Dense(classes, activation = 'softmax', name = 'output')(x)
model = Model(inputs = input_tensor, outputs = output)
model.summary()
return model
