0. 들어가며
오늘은 Class Activation Map (CAM)과 GradCAM에 대해서 간단하게 알아보겠다
CNN의 한계 및 CAM의 배경
기존의
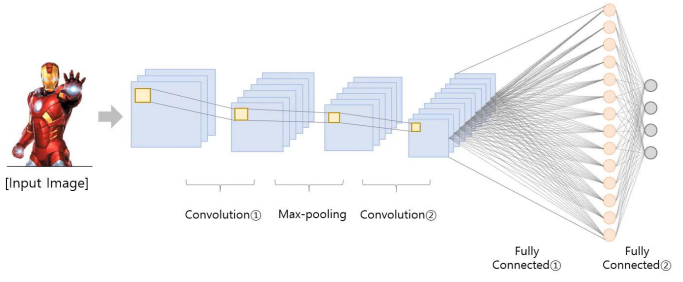
CNN구조는 Input - Conv layer - FC layer 으로 이루어져있다. 즉,CNN은 마지막 Conv layer를 FC layer로 바꾸고, Softmax 함수를 통하여 특정 이미지를 특정 클래스로 분류하는데 매우 뛰어난 성능을 보여준다.
하지만, 이렇게CNN의 마지막 layer를 FC layer로 Flatten 시킬 때, 우리는 마지막 layer의 feature map이 가지고 있던 각 픽셀들의 위치 정보를 잃게 된다.
따라서 Classifying 정확도가 아무리 뛰어날지라도, 우리는 그CNN이 Input data의 어떤 부분을 중점적으로 보고 해당 클래스로 분류했는지 알 수가 없다는 문제가 생긴다.
이번 포스팅에서는 FC layer의 구조를 살짝 바꾸면서 기존에 잃었던 위치 정보들을 얻어내는CAM에 대하여 소개할 예정이다.
1. Class Activation Map (CAM)

Class Activation Map (CAM)은 딥러닝 프레임 워크에서 예측 원인을 파악하기 위해 등장한 알고리즘이다.
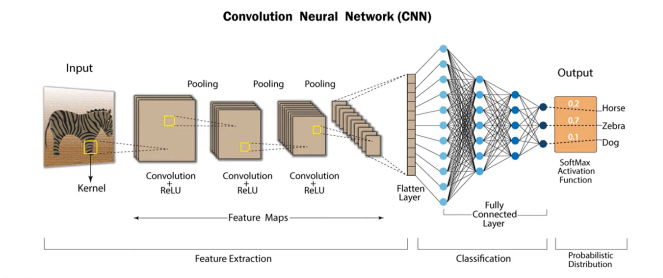
기존의 CNN 구조는 위와 같은 과정을 거쳤다.
- 이미지 데이터의 특성을 잘 반영할 수 있는 인공신경망 모델
- 2D 혹은 3D구조를 유지하면서 학습
- 일반적인 CNN은
Convolution연산,Activation연산,Pooling연산의 반복으로 구성됨
- 일정 횟수 이상의 Feature Learning 과정 이후에는
Flatten과정을 통해 이미지가 1차원의 벡터로 변환됨
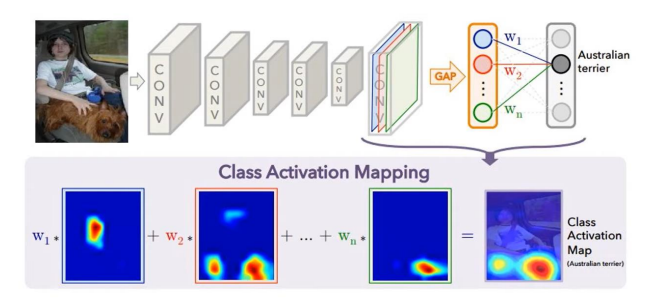
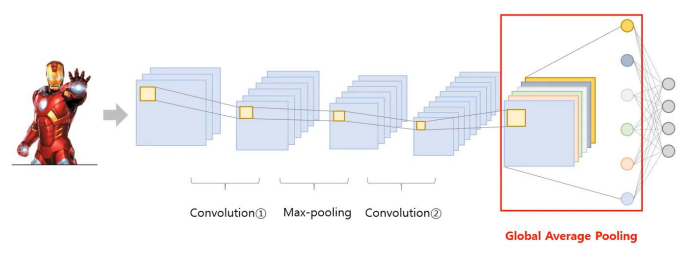
이때, CAM은 CNN에서의 flatten 과정을 거치지 않고, GAP라는 과정을 거친다는 점만 다르다.
위의 과정을 통해 어떤 부분이 class 예측에 큰 영향을 주었는지 확인이 가능하다.
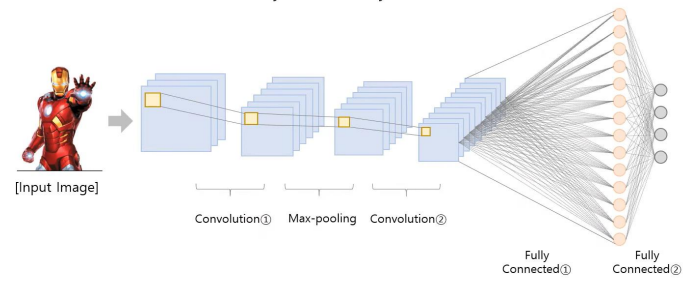
기존의 CNN 구조는 Convolution layer와 pooling layer를 활용해서 이미지 내 정보를 요약하고, 최종 분류 예측 전에 fully connected layer를 활용한다.
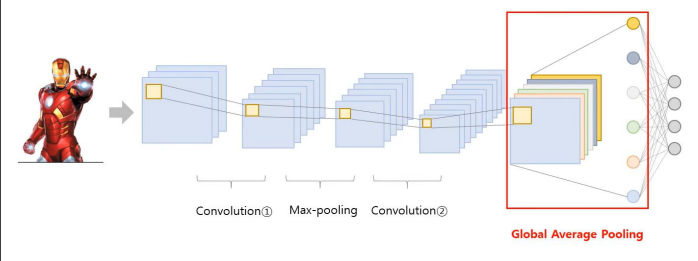
CAM 구조는 Convolution layer와 pooling layer를 활용하여 이미지 내 정보를 요약한다는 점은 CNN과 같지만, fully connected layer가 아닌 global average pooling (GAP) 구조를 사용하다는 점에서 차이가 있다.
그렇다면 Global Average Pooling (GAP)란 무엇일까?
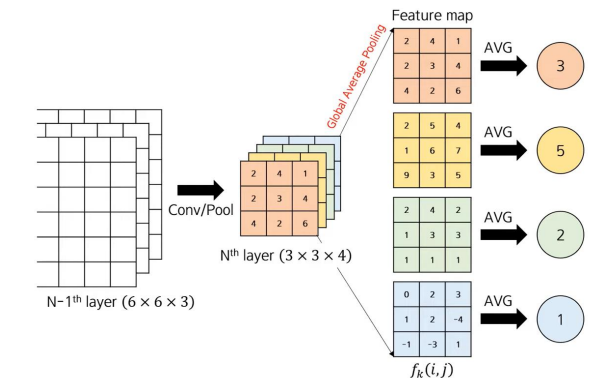
Global Average Pooling이란 각 feature map의 가중치값들의 평균이다.
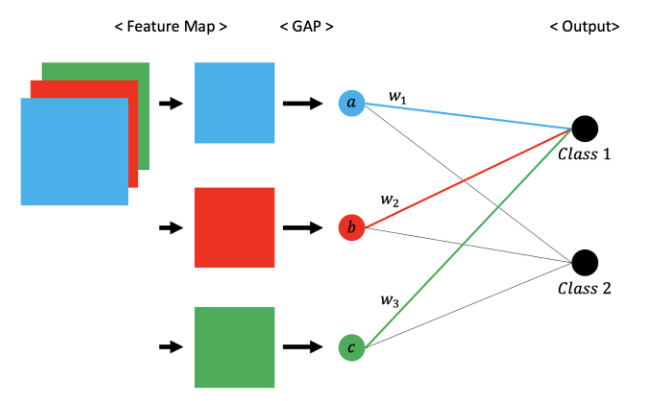
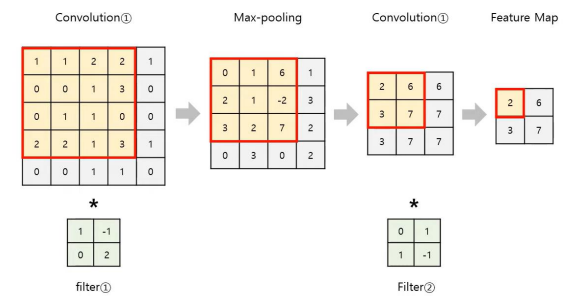
CAM의 과정을 좀 더 자세하게 알아보기 위하여 위 그림을 자세하게 파헤쳐보자.
우선, 각 feature map의 average pooling을 취하여 a, b, c값을 계산한다. 그리고 이 3개의 값들을 Input data로 하고 클래스 분류 결과값을 Output으로 하는 뉴럴네트워크를 학습시킨다.
그러면 위 그림에서처럼 각 GAP값(a, b, c)마다 관련되어 있는 w1, w2, w3값이 학습될 것이다.
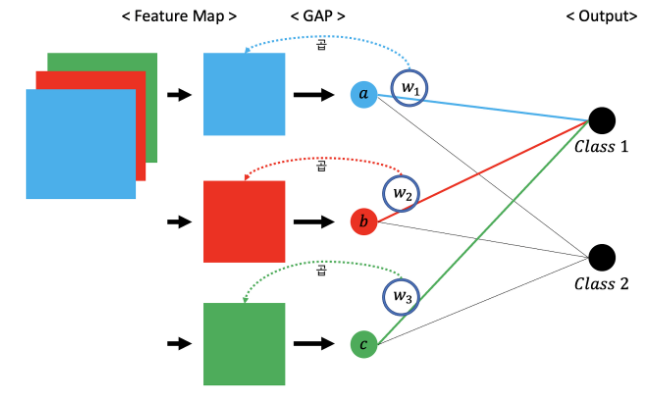
그런 다음 위 그림처럼 학습된 w1, w2, w3값을 각각 관련되어 있는 feature map에 곱해준다.
그 후, 가중치가 곱해진 각 feature map을 전부 sum해준다.
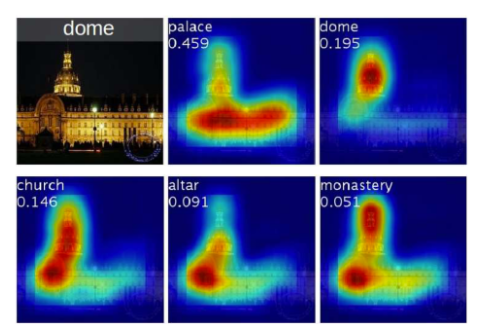
이렇게 Weighte Sum된 feature map을 Graphical하게 시각화하면 위와 같이 나타나게 된다.
이와 같이, CAM은 학습 결과 input data의 어떤 부분에서 해당 클래스로 분류가 되었는지 그 중요도를 알 수 있다.
그렇다면 이런 의문을 가질 수도 있다.
왜 CAM에서 마지막 layer으로도 원인 분석이 가능한 걸까?
-
마지막 convolution feature map이 가진 정보량이 많기 때문
-
마지막 feature map 내 1개 값은 원본 이미지에서 많은 부분을 요약한 결과임
그러나 이러한 CAM 구조도 명백한 한계를 가지고 있다.
-
GAP layer를 반드시 사용해야함
-
GAP layer를 사용해야 하기에 뒷부분에서 또 다시 fine tuning을 진행해야함
-
마지막 convolution layer에 대해서만
CAM추출이 가능
2. Grad-CAM
위에서 언급한 CAM의 한계를 극복하기 위해 새로 고안된 모델이 Grad-CAM이다.
Grad-CAM 구조는 다음과 같은 특징을 지니고 있다
-
GAP 사용 안 함
-
CNN의 기본 구조를 변형하지 않고 그대로 사용함 (즉, GAP layer 필요 X)
-
모델 이름 중 Grad는 gradient를 의미하는데, 특정 class에 특정 input이 주는 영향력을 뜻함
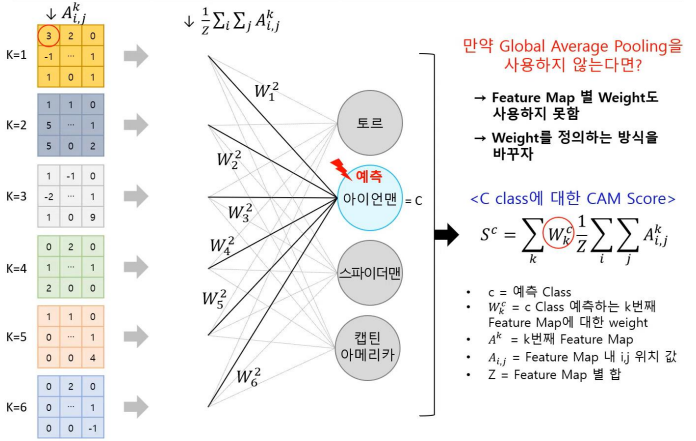
기존의 CAM의 동작 방식은 위 사진과 같다.
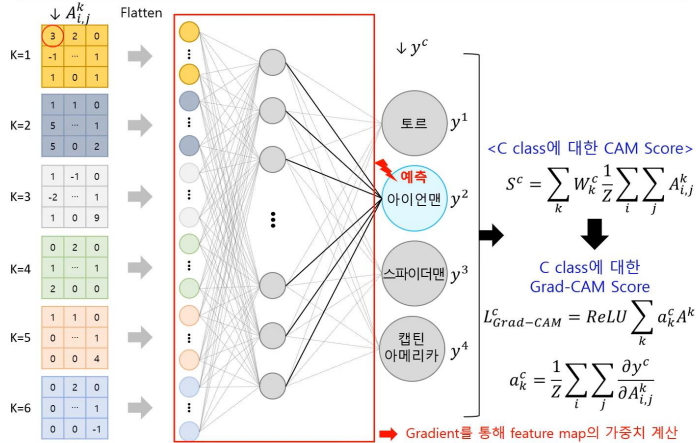
Grad-CAM의 동장방식은 위 사진과 같다.
수식을 보면 CAM과 거의 비슷하지만 다른 점이 있다.
Grad-CAM은 feature map의 픽셀값들을 각각 모두 편미분하고, 이를 모두 합한 후 픽셀 총 개수인 z로 나누어주어평균을 취해준다.
이때, 편미분을 수행한다는 것은 최종클래스 값을 기준으로 얼마나 변화하는지에 대한 변화량을 의미하기 때문에 'Grad CAM' 의 'Grad'가 Gradient (미분=변화량)을 의미하는 것이다.
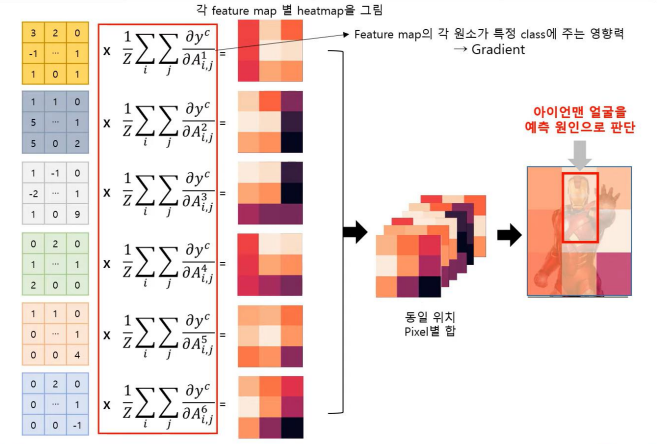
나머지 과정은 CAM과 같다. 가중치가 더한 것이 반영된 feature map들을 합하고, 이를 Graphical하게 그려보면 어떤 input이 큰 영향을 주었는지 알 수 있다.
3. 마치며
오늘은 CAM과 Grad-CAM에 대해서 알아보았다.
또한 필자는 고려대학교 김성범 교수님이 운영하시는 유튜브 채널을 보고 공부한 내용을 포스팅 하였으므로 아래 출처를 남긴다.
https://www.youtube.com/@user-yu5qs4ct2b
