0. 들어가며
오늘은 RNN과 Attention 기법에 대해서 간단하게 알아보는 시간을 가질 것이다.
해당 내용은 심화하여 다시 포스팅 할 예정이니 오늘은 가벼운 마음으로 맛만 보자.
1. 시계열 데이터
RNN은 기본적으로 시계열 데이터를 기반으로한 딥러닝 모델이다.
따라서 우선 시계열 데이터와 기존의 시계열 데이터 분석 방법은 어땠는지에 대하여 먼저 알아볼 필요가 있다.
1. 시계열 데이터 예측 분석 방법론
전통 통계 기반 시계열 데이터 분석 방법론
- 이동평균법 (Moving Average)
- 지수평활법 (Exponential smoothing)
- ARIMA (Autoregressive integrated moving average)
- SARIMA (Seasonal ARIMA)
- etc...
머신러닝 기반 시계열 데이터 분석 방법론
- Support vector machine/regrssion
- Random forest
- Boosting
- Gaussian process
- Hidden Markov model
인공지능 기반 시계열 데이터 분석 방법론
- RNN (1986)
- LSTM (1997)
- GRU (2014)
- Seq2Seq (NIPS 2014)
- Seq2Seq with attention (ICLR 2015)
- CNN and variants (2016)
- Transformer (NIPS 2017)
- GPT-1 (2018), BERT (2019), GPT-3 (2020)
2. 시계열 데이터 (Time Series Data)
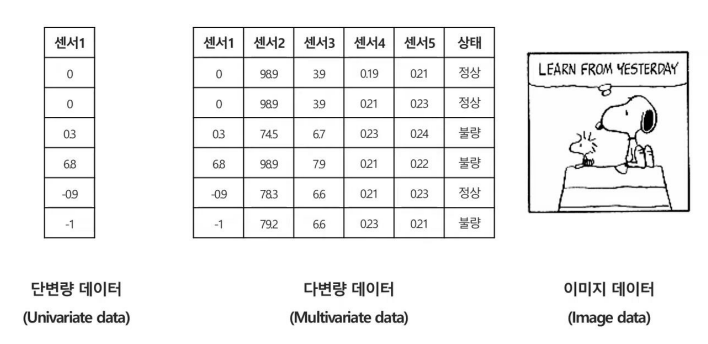
우리가 일반적으로 지금까지 보았던 데이터들은 위와 같이 단변량 데이터, 다변량 데이터, 이미지 데이터 중 하나였다.
그렇다면 시계열 데이터란 무엇일까?
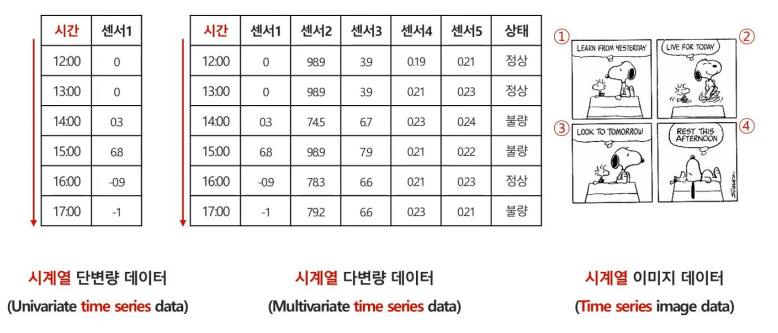
시계열 데이터 (Time Series Data)
시간의 흐름에 따라 순서대로 관측되어 시간의 영향을 받게 되는 데이터
위 사진처럼 데이터가 시간의 흐름에 따라 영향을 받는 데이터를 시계열 데이터라고 부른다.
2. Recurrent Neural Network (RNN)
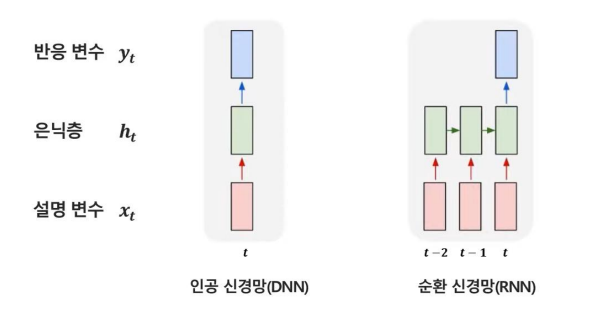
순환신경망 (Recurrent Nerual Network RNN)
이전 시점 정보들을 반영하여 시계열 데이터 모델링에 적합한 인공신경망
일반적으로 DNN과 RNN을 그림으로 도식화하면 위와 같이 그릴 수 있다.
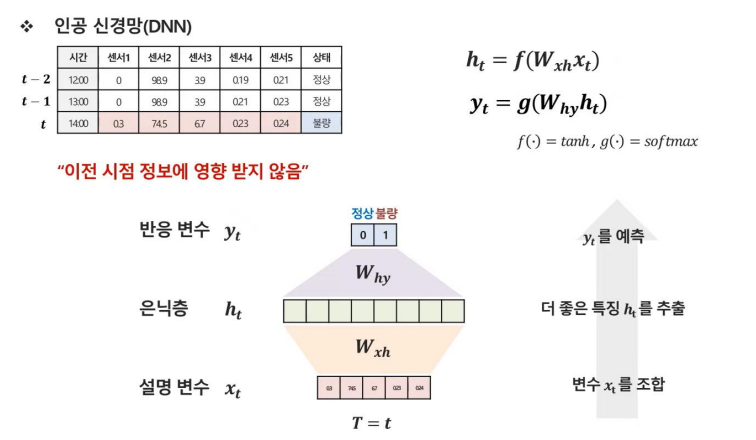
우선 우리가 알고있는 DNN부터 다시 알아보자.
DNN은 시간의 흐름에 상관없이 해당 시점의 데이터를 기준으로 학습을 하여 output을 도출한다.
그러나 이런 방식의 학습은 시간의 영향을 받는 데이터에서는 효율적이지 못 할 수 있다는 단점이 있다.
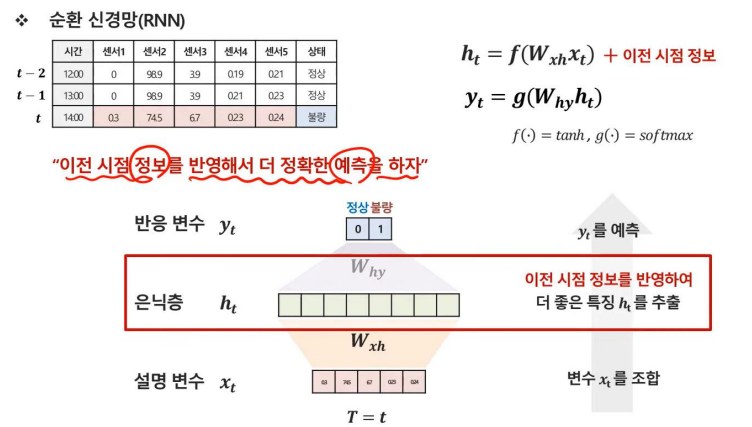
그렇다면 이전 시점의 정보를 반영해서 더 정확한 예측을 할 수 있다면 어떨까?
이런 문제의 해결방안으로 나온 모델이 바로 RNN이다.
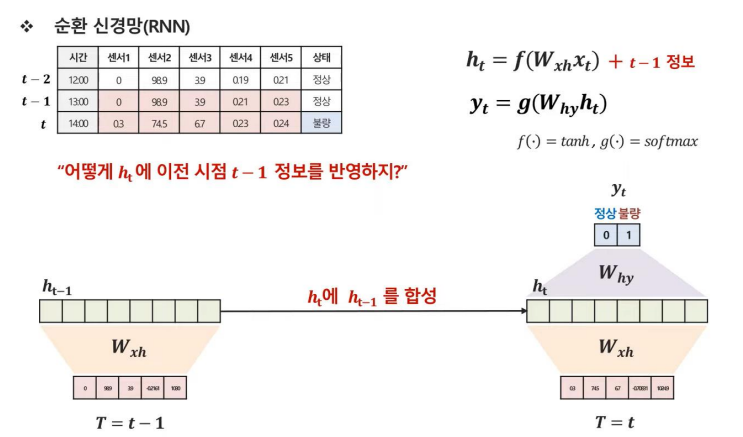
RNN은 기본적으로 이전 시점의 정보를 반영하여 output을 도출하는 모델이다. 그러기 위해서는 이전 시점인 t-1 정보를 현재 시점 t에 반영해야 하는데 어떻게 해야할까?
RNN은 t-1 시점의 은닉층과 t 시점의 은닉층을 합성하는 방식을 채택하였다.
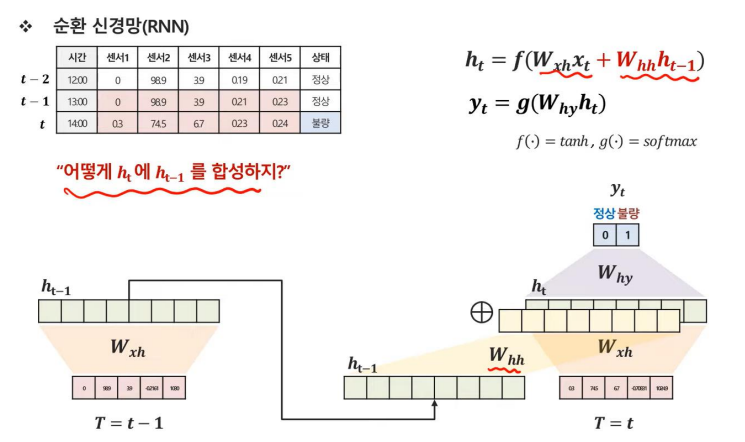
그렇다면 그 두개의 층을 어떻게 합성할까?
RNN은 이전 시점의 은닉층과 컨볼루션하는 가중치 W를 하나 더 정의하여 합성하고 해당 결과를 t 시점의 은닉층과 더해주는 방식으로 진행하였다.
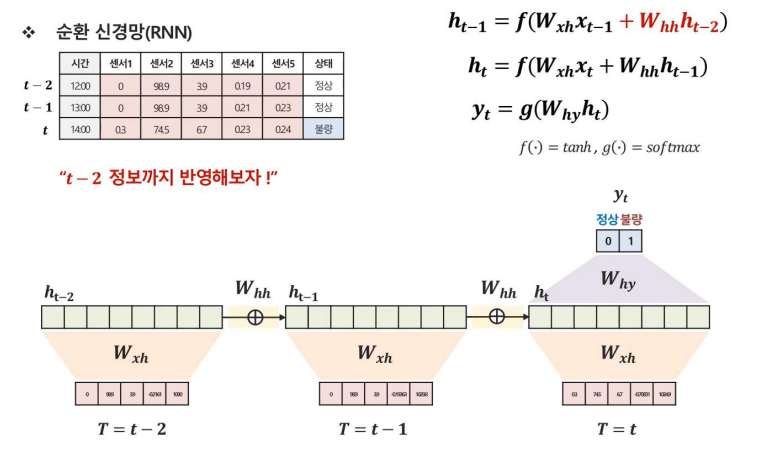
같은 방식으로 t-2까지의 정보를 반영한 식과 그림은 위와 같이 나타낼 수 있을 것이다.
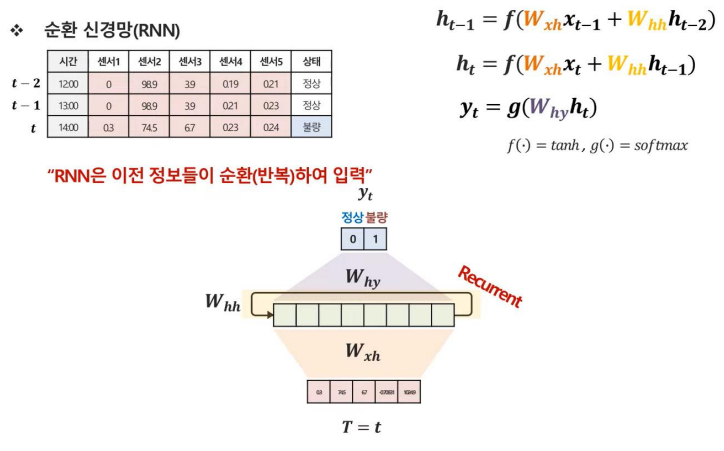
결국 RNN은 이전 정보들이 순환하여 학습하는 구조를 가지기 때문에 Recurrent라는 이름이 붙었음을 알 수 있다.
3. RNN의 종류
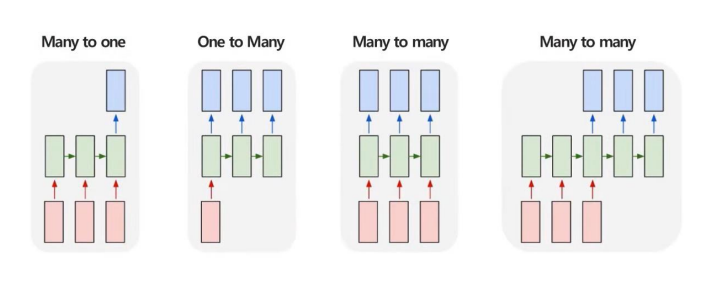
RNN은 순차적으로 입력하고, 순차적으로 에측하는 것이 가능하다. 순차적으로 입력의 길이, 순차적인 예측의 길이에 따라서 구분지을 수 있는데, 크게 보면 위와 같이 4가지의 종류로 나눌 수 있다.
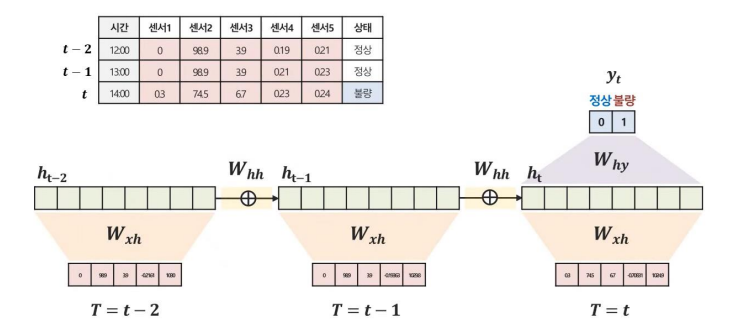
Many to one 구조
- 여러 시점 X로 하나의 Y를 예측하는 문제
- ex: 여러시점의 다변량 센서데이터가 주어졌을 때, 특정 시점의 제품상태를 예측
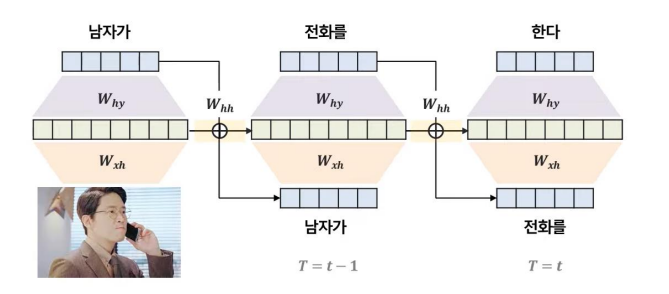
One to many 구조
- 단일 시점 X로 순차적인 Y를 예측하는 문제
- ex: 이미지 데이터가 주어졌을 때, 이미지에 대한 정보를 글로 생성하는 이미지 캡셔닝
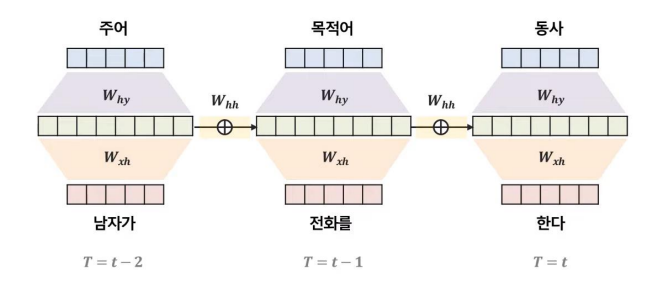
Many to many 구조
- 순차적인 X로 순차적인 Y를 예측하는 문제
- ex: 문장이 주어졌을 때, 각 단어의 품사를 예측하는 Part of speech (POS) Tagging
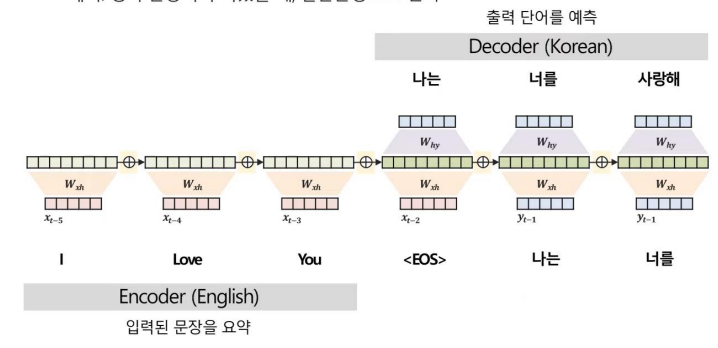
Many to many 구조
- 순차적인 X로 순차적인 Y를 예측하는 문제
- ex: 영어 문장이 주어졌을 때, 한글문장으로 번역
- 위와 같은 구조를
Seq2Seq라고 하기도 한다
4. Attention Mechanism
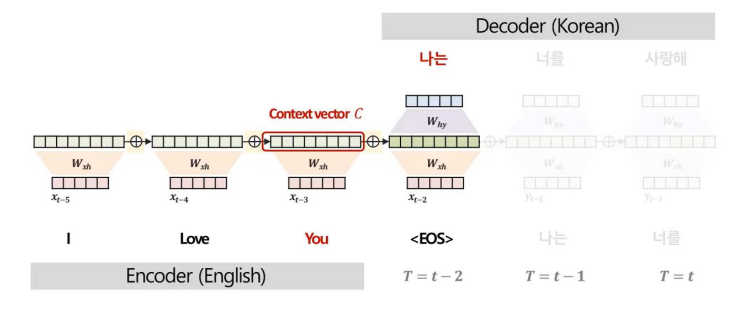
위와 같은 Seq2Seq 구조는 Decoder가 단어를 예측할 때, Encoder의 마지막 시점 은닉층 정보(context vector, C)만을 활용한다.
그러나 이러한 구조는 각 단어 예측 시 더 중요하게 집중해야 하는 Encoder 부분의 단어가 다른데 이를 반영할 수 없다는 한계가 있다.
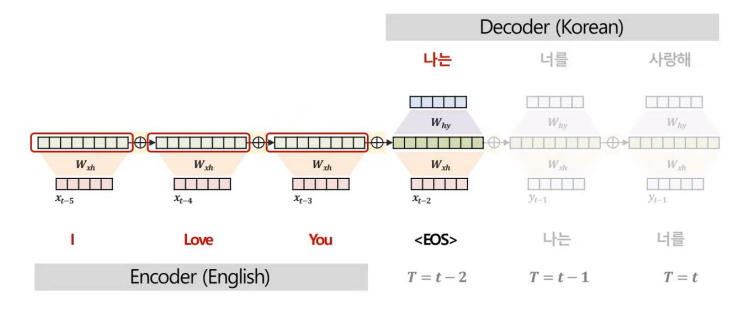
이에 대한 해결방안으로 단어 예측 시 (1) 매 시점 정보를 참고하고, (2) 중요한 단어는 더 집중해서 보자는 방식의 Attention 기법이 탄생하였다.
그렇다면 어떻게 매 시점 정보를 참고하면서 중요 단어에 가중치를 더 줄 수 있을까?
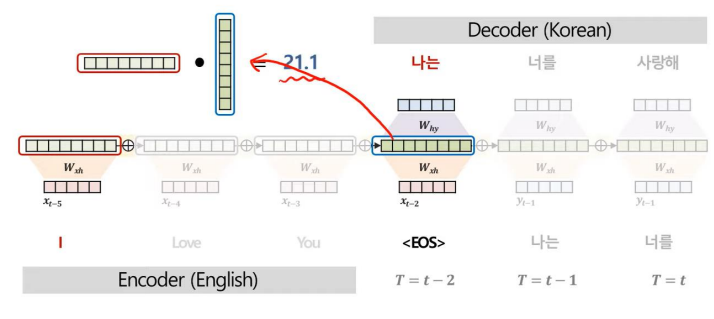
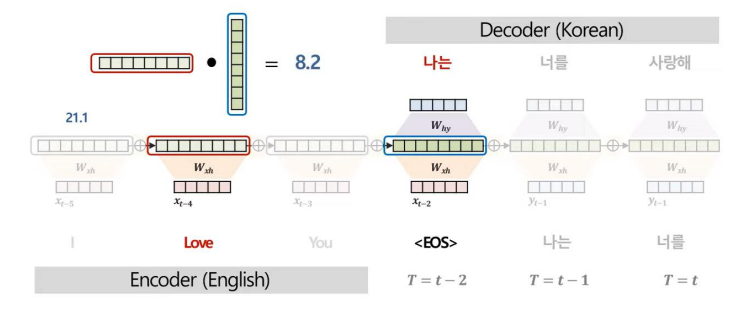
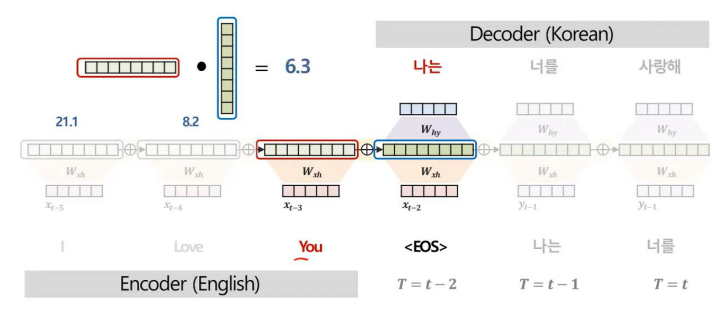
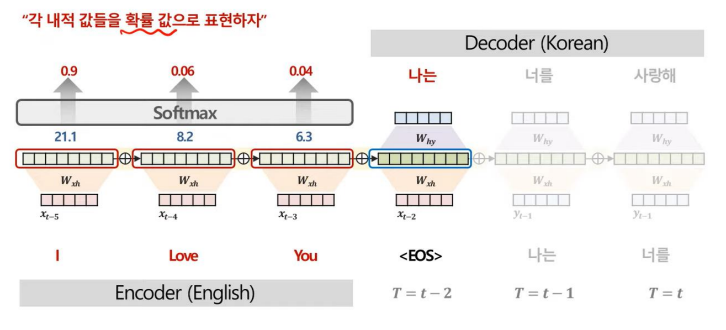
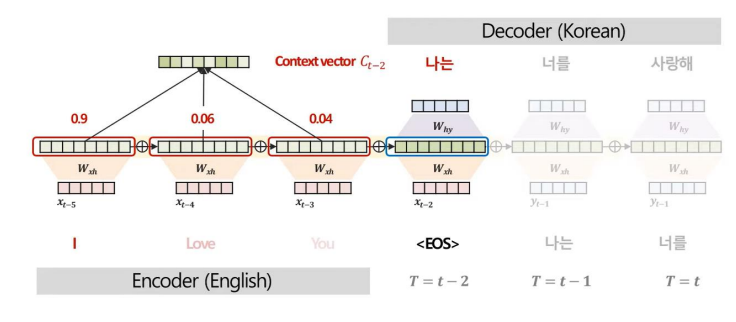
위와 같은 과정을 거치면서 Decoder의 각 시점별 Context vector, C을 구한다.
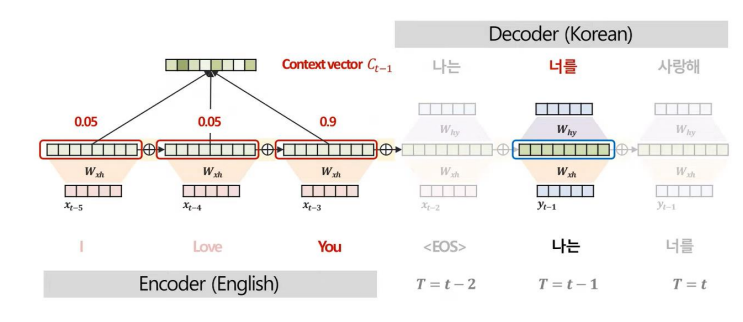
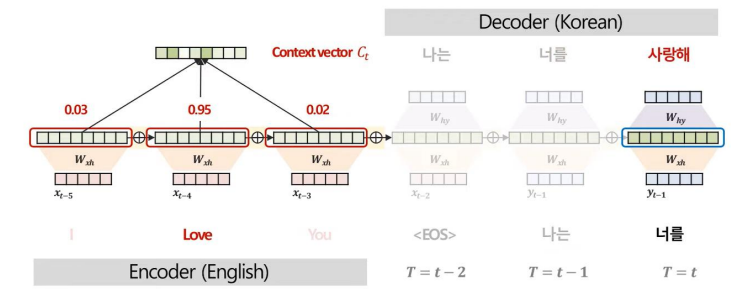
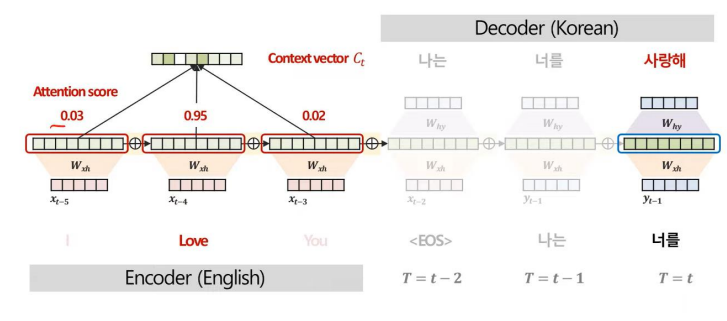
위와 같이 Attention 기법을 사용하는 과정에서 Attention Score를 산출할 수 있다.
Attenion Score는 모델이 예측에 주요하게 집중한 부분을 정량적으로 해석할 수 있다는 특징이 있다.
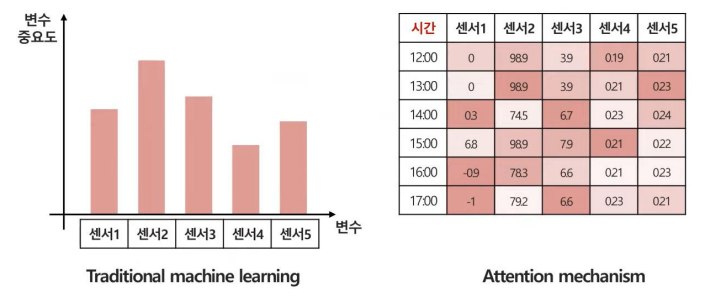
특히, 이러한 Attention 기법은 각 관측치별 중요도를 도출 가능하므로 원인이자 규명을 명확히 할 수 있다.
위 그림을 보면 전통적인 기법에서는 센서2의 중요도가 가장 크게 나타나지만, Attention 기법을 사용하여 시간별로 분석을 하면 각 시간대마다 중요한 변수가 전부 다름을 확인할 수 있다.
5. 마치며
오늘은 RNN과 Attention에 대해서 간단하게 알아보았다. 해당 내용은 보다 구체적으로 공부하는 것이 더 좋을 것 같아 후에 심화된 내용을 기반으로 다시 포스팅 할 예정이다.
또한 필자는 고려대학교 김성범 교수님이 운영하시는 유튜브 채널을 보고 공부한 내용을 포스팅 하였으므로 아래 출처를 남긴다.
https://www.youtube.com/@user-yu5qs4ct2b
