0. 들어가며
Deep Learning 모델의 가장 기본인 DNN에 대해서 간단하게 알아보겠다.
[ML] 시리즈에서 뉴럴네트워크의 기본적인 내용들을 적은 글이 있으니 보다 자세한 내용을 원한다면 아래 링크를 참고하자.
https://velog.io/@albert0811/ML-Artificial-Neural-Networks1
1. 뉴럴네트워크 파라미터 결정, 비용함수
DNN에 들어가기에 앞서 뉴럴네트워크 모델을 먼저 알아보자.
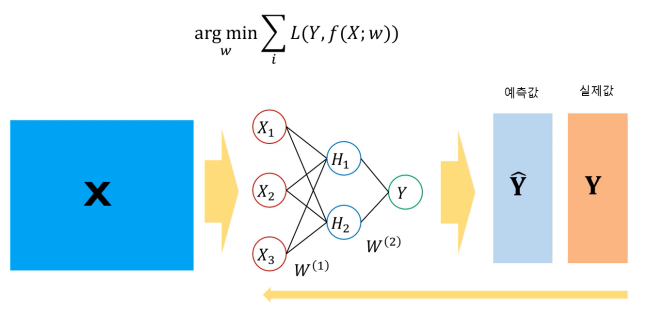
뉴럴네트워크 모델의 비용함수는 다른 모델들과 마찬가지로 예측한 Y값과 실제 Y값의 차이를 최소로하는 가중치를 찾는다.
즉, Loss function이 최소가 되는 가중치 w를 찾는 것이다.

예를 들어, Y가 범주형인 경우에는 비용함수로 cross entropy를 사용하고, 위 사진처럼 예측한 Y값과 실제 Y값의 차이에 따른 Loss가 계산할 수 있다.
차이가 크면 Loss도 크게, 차이가 작으면 Loss도 작게 나옴을 확인할 수 있다.
2. 다중 클래스 - Softmax Function
지금까지는 output layer에서 sigmoid function을 사용하여 이진분류를 수행하는 모델을 보았다.
그러나, 여러 개의 클래스를 분류해야 하는 모델이라면 softmax function을 사용해야 한다.

output layer의 크기를 범주 개수만큼 정하고 softmax를 사용하면 Multiclass classification 모델로 쉽게 변형이 가능하다.
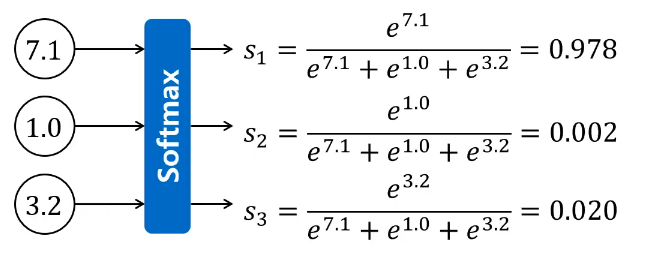
만약 위와 같은 레이블 분류 예제가 있다고 한다면 softmax를 사용한 후의 값이 첫 번째 레이블이 0.978로 가장 높으므로 위의 데이터는 첫 번째 레이블로 분류가 될 것이다.
3. Batch Size, Epoch
Batch size: 1회 업데이트 시 사용할 관측치의 수
- 클수록 빠르지만 성능 저하
- 작을수록 느리지만 성능 향상
- 속도와 성능 사이의 trade-off가 존재함
Epochs: 전체 데이터에 대한 학습을 반복하는 횟수

전체 데이터가 2000개가 있다면 위의 예제에서는 Batch size를 200으로 iteration을 총 10번 반복하면 전체 데이터를 1번씩 모두 학습한 것이므로 epoch 한 번을 돌렸다고 할 수 있다.
4. Early Stopping
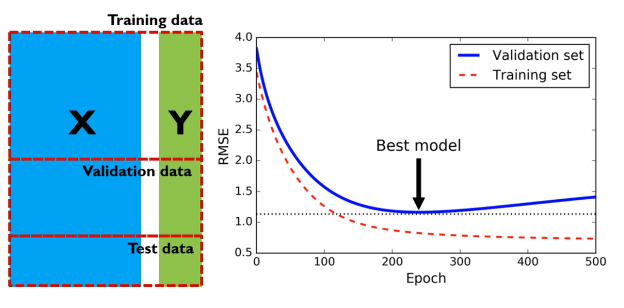
모델을 학습하다보면 epoch에 따라 training set과 validation set의 loss가 달라진다.
training set은 epoch이 반복될수록 loss가 점점 줄어듬을 볼 수 있는데 단순히 loss가 줄었다고 해서 좋은 모델은 아니다.
해당 모델이 해당 데이터셋에 overfitting 되었을 가능성이 높기 때문이다.
따라서, 가장 최고의 모델은 traning set으로 훈련한 모델의 validation set에서 가장 작은 loss를 가지는 지점에서의 모델이다.
5. Deep Neural Network (DNN, 심층신경망)
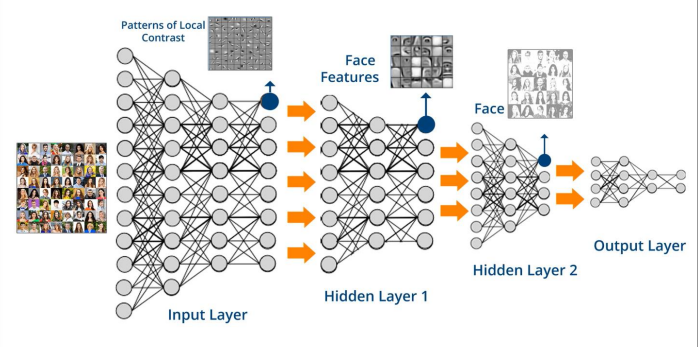
Deep Neural Network (DNN)
- 여러 층으로 이루어진 복잡한 구조의 인공신경망
Advantages of DNN
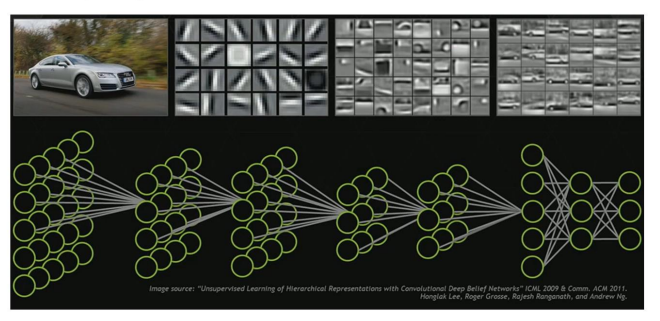
DNN은 고차원의 데이터(이미지, 음성, 텍스트)를 그대로 사용하더라도 자동으로 feature를 정의할 수 있다는 장점이 있다.
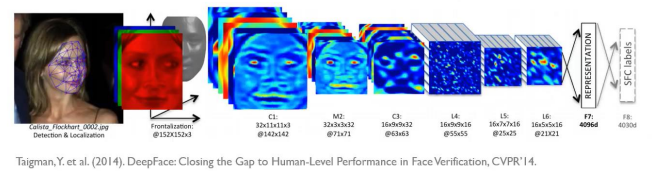
또한 기존의 머신러닝 방법론에 비해 우수한 예측 정확도를 가지고, 특정 분야에서는 인간의 능력보다 우수한 성능을 보여주기도 한다.
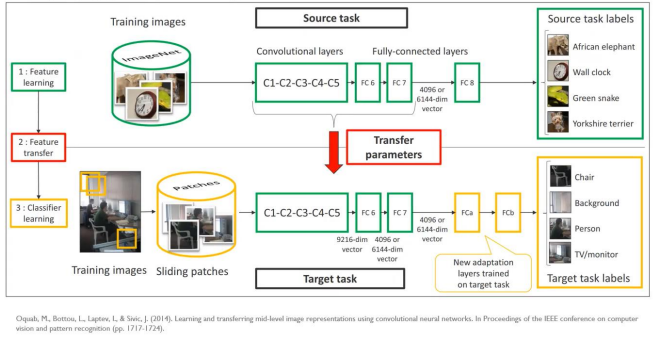
특히, 특정 데이터(도메인)에서 학습된 구조를 다른 데이터(도메인)에서도 사용할 수도 있다는 굉장히 효율적인 장점이 있다.
이를 Transfer Learning(전이학습)이라고 한다.
Disadvantages of DNN
이러한 장점이 있는 반면 DNN은 여러가지 문제점도 존재하는데 다음과 같다.
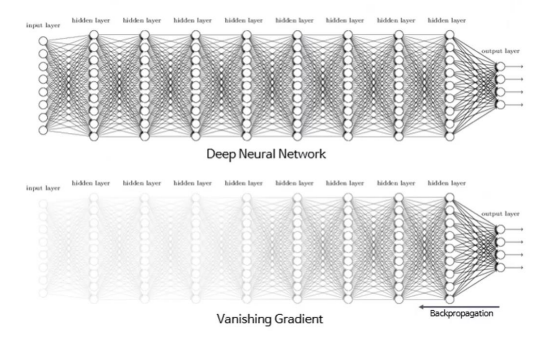
문제점: layer를 많이 사용하면 학습이 안 됨
sigmoid function을 활성함수로 사용하면 hidden layer의 수가 증가함에 따라 하위 층으로 갈수록 gradient가 0이 될 가능성이 높아져서 Backpropogation이 진행되지 않는다.
이런 문제를 Vanishing Gradient(기울기 소실)이라고 한다.
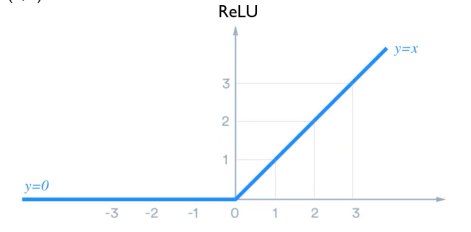
해결책: Gradient가 소실되지 않는 새로운 활성 함수 사용
Vanishing Gradient 문제를 해결하기 위해서 'Squashing' 특성이 없는 activation function인 ReLU를 사용할 수 있다.
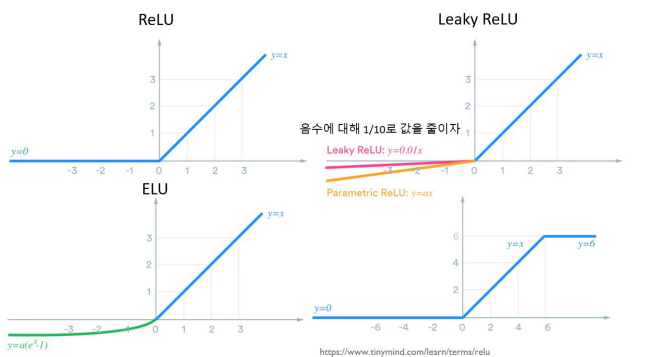
ReLU뿐만 아니라 ReLU를 변형한 다른 활성함수를 사용하기도 한다.
문제점: layer를 많이 사용하면 overfitting 발생
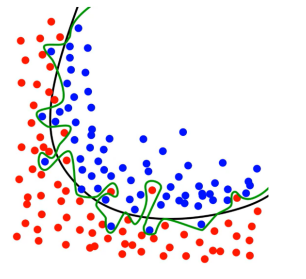
위 사진처럼 층을 많이 쌓으면 모델이 해당 데이터셋에만 적합하게끔 학습을 진행하여 overfitting이 발생할 수 있다는 문제가 있다.
해결책: Drop-Out, 모델 관점
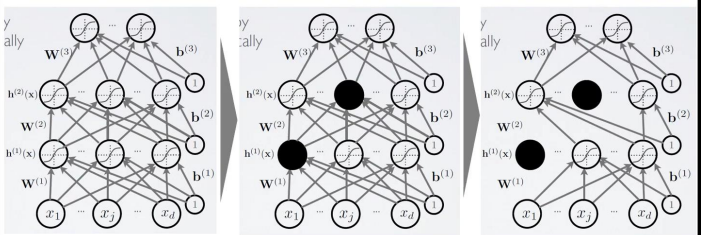
Drop-Out 방식은 학습 과정에서 일부러 특정 노드들에 연결된 가중치들은 업데이트를 하지 않는다. 또한 어떤 노드를 업데이트 시키지 않을 것인가는 무작위로 하여 결정한다.
위와 같은 방식으로 학습을 진행하면 모델이 하나의 데이터셋에 overfitting하는 것을 어느 정도 방지할 수 있다.
해결책: Data Augmentation, 데이터 관점
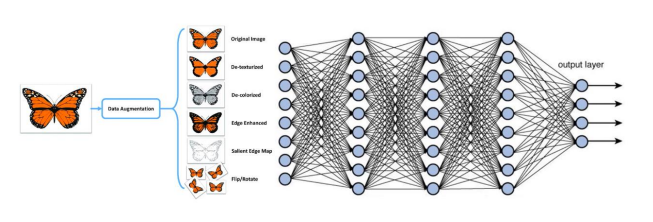
모델의 파라미터의 수가 엄청나게 많은데 보유하고 있는 데이터의 수가 너무 적기 때문에 overfitting이 발생한다.
그렇다면 현재 보유한 데이터를 증폭해서 학습시킨다면
overfitting도 막고 모델 정확도도 올릴 수 있지않을까?
그 방법이 바로 Data Augmentation이다.

위 사진처럼 하나의 나비, 햄스터 데이터를 증폭하여 여러 가지의 데이터로 만들어 학습을 시킨다면 특정 데이터에 과적합하는 것을 방지할 수 있다.
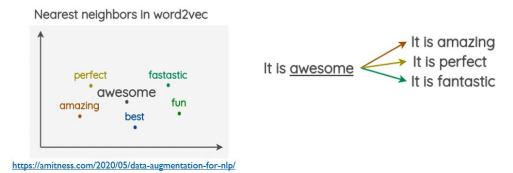
이러한 Data Augmentation은 꼭 이미지 데이터뿐만 아니라 텍스트에서도 사용할 수 있다.
위 사진은 'awesome'이라는 문자를 비슷한 뜻의 다른 단어들로 증폭하여 학습을 진행시킬 수 있다는 예시이다.
6. 마치며
오늘은 뉴럴네트워크와 DNN에 대해서 간단하게 알아보았다.
다음 포스팅에서는 CNN에 대하여 알아볼 예정이다.
또한 필자는 고려대학교 김성범 교수님이 운영하시는 유튜브 채널을 보고 공부한 내용을 포스팅 하였으므로 아래 출처를 남긴다.
https://www.youtube.com/@user-yu5qs4ct2b

좋은 정보 감사합니다.
https://ai-ethics.tistory.com/4