[논문리뷰] Score-based Generative Modeling through Stochastic Differential Equations (Score-SDE, 2021)
Diffusion Models
목록 보기
4/8
0. Abstract
- NCSN과 DDPM을 통합하는 score-SDE framework를 제시
- 그 외 contributions
- predictor-corrector framework 제시
- SDE가 아닌 ODE 버전도 제시해서 sampling efficiency를 높일 수 있도록 함
- score-SDE를 통해 inverse problem을 해결하는 방법의 뼈대를 제공함
1. Introduction
-
score-based generative model
- SMLD(==NCSN, Score matching with Langevin dynamics)
- each noise scale에서의 score를 구한 후, Langevin dynamics를 이용해 샘플링하는 방식
- DDPM
- sequence of noise corruption을 학습해서 그걸 뒤집어 생성하는 방식
- continuous state spaces에서 DDPM objective는 score를 implicit하게 계산한다
- 이 두 방법을 합쳐서 score-based generative model이라 부르기로 한다
- 본 논문에서는 SDE(stochastic differential equation)를 이용해서 score-based generative model을 정형화한다
- finite number of noise X, 여기서는 noise를 continuous하게 씌운다고 생각한다

- SMLD(==NCSN, Score matching with Langevin dynamics)
-
Contributions
- Flexible sampling and likelihood computation
- sampling(reverse process) 시에 어떤 SDE solver든 사용할 수 있다
- PC (Predictor-Corrector) samplers
- numerical SDE solvers + score-based MCMC approaches
- 기존 score-based models에 적용되던 sampling methods를 통합하고 발전시킴
- deterministic samplers based on probability flow ODE
- exact likelihood computation
- allow fast adaptive sampling
- flexible data manipulation via latent codes
- uniquely identifiable encoding
- Controllable generation
- training 때는 없었던 conditioning으로 generation을 통제할 수 있음
- conditional reverse-time SDE는 unconditional score를 이용해서 계산하기 때문
- 단 하나의 unconditional score model로 class-conditional generation, inpainting, colorization 등 다양한 문제를 풀 수 있다
- training 때는 없었던 conditioning으로 generation을 통제할 수 있음
- Unified framework
- 따로따로였던 SMLD, DDPM 두 방식을 하나의 framework로 통합했다
- Flexible sampling and likelihood computation
2. Background
2.1. SMLD
- Settings
- : given data distribution
- : perturbation kernel
- : perturbed data distribution
- noise scheduling
- 은 가 될 만큼 충분히 작아야 하고
- 는 가 되도록 충분히 커야 함
- Objective
- Sampling using Langevin MCMC
2.2. DDPM
- Settings
- noise scales and
- for each data , a discrete Markov chain is constructed s.t.
- forward disffusion은 아래와 같이 one-step으로 가능
- , where
- SMLD와 비슷한 parameterization으로 살짝 바꿔주기
- : perturbed data distribution
- : variational Markov chain (reverse)
- Objective
- re-weighted variant of ELBO(evidence lower bound)를 이용한 loss
- DDPM의 을 다시 쓴 것
- Sampling using reverse Markov chain
3. Score-based Generative Modeling with SDEs
3.1. Perturbing data with SDEs
-
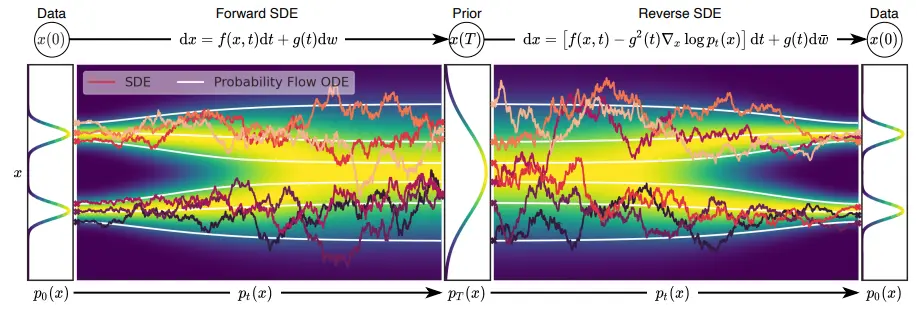
-
settings
- (data distribution)
- (prior distribution)
- goal : continuous time variable 에 대해 diffusion process 를 만드는 것
- this process can be modeled as the solution to an Ito SDE:
- : standard Wiener process (a.k.a. Brownian motion)
- <= vector valued function called the drift coefficient of
- <= scalar function called the diffusion coefficient of
- 에 dependent하고 vector valued function인 로 일반화할 수 있다 (Appendix A)
- 본 논문에서는 timestep ()에 대해, 에서 로 가는 transition kernel을 로 표기한다
3.2. Generating samples by reversing the SDE
- 선행 연구(Anderson, 1982)에 따르면 diffusion process의 reverse도 같은 형태의 diffusion process로 표현된다
- : timeflow가 반대인 () Wiener process
- : infinitesimal negative timestep
- , score of each marginal distribution을 구하면 reverse SDE를 따라 샘플링할 수 있다
3.3. Estimating scores for the SDE
- 그러면 score 를 어떻게 구할까?
- train a time-dependent score-based model
- Score-SDE Objective
- , positive weighting function
- SMLD, DDPM에서 공통적으로 그랬던 것처럼, 모든 timestep에 대해 비슷한 loss 비중을 가지도록 세팅
- is uniformly sampled over
- and
- 충분한 데이터와 model capacity가 주어졌을 때
- 여기선 denoising score matching 기준으로 objective를 설정했지만 다른 score matching 기법들을 쓸 수도 있음
- , positive weighting function
- transition kernel
- drift coefficient 가 affine transform이면 transition kernel은 항상 Gaussian이고, mean과 variance를 closed form으로 구할 수 있다
- DDPM의 one-step forward diffusion과 같은 것
3.4. Examples: VE, VP SDEs and beyond
-
NCSN과 DDPM은 이 score-SDE의 discretization으로 볼 수 있다
- drift & diffusion coefficient and 세팅이 다름
- 자세한 유도 과정은 Appendix B에
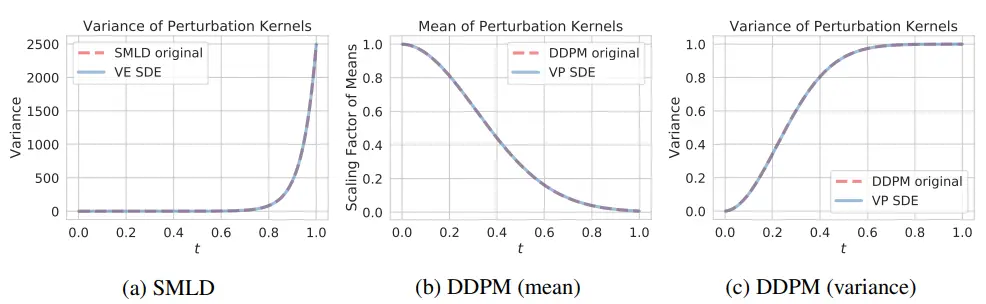
-
NCSN as VE SDE
- Markov chain :
- 여기서 을 무한으로 보내서 continuous form으로 만들면
- becomes
- becomes
- Markov chain becomes continuous stochastic process
- 정리하면, NCSN에 해당하는 forward SDE는
- 로 갈 때 variance가 발산하기 때문에 Variance Exploding SDE
-
DDPM as VP SDE
- Markov chain :
- 마찬가지로 을 무한으로 보내고 forward SDE form으로 정리하면
- 로 갈 때 variance가 유지되기 때문에 Variance Preserving SDE
-
sub-VP SDE
- new type of SDEs which perform particularly well on likelihoods
- new type of SDEs which perform particularly well on likelihoods
4. Solving the Reverse SDE
4.1. General-purpose numerical SDE solvers
- SDE를 푸는 데 이용되는 기존 solvers
- Euler-Maruyama, stochastic Runge-Kutta methods, etc.
- reverse SDE를 각기 다르게 discretize해서 stepwise sampling
- ancestral sampling (of DDPM)
- recap :
- DDPM에서 정의한 Markov chain을 거꾸로 한 것
- 이것은 reverse-time VP SDE의 많은 discretizations 중 하나라고 볼 수 있음
- reverse diffusion samplers
- reverse-time SDE를 discretize한 것
- derivations
- recap
- 여기서 =0~1을 으로 discretize하면
- VE-SDE
- Markov chain : 이므로
- , 이걸 discretized SDE에 대입하면
- VP-SDE
- Markov chain : 이므로
- , 이걸 discretized SDE에 대입하면
- recap
- unifies DDPM framework
- timesteps가 충분히 커서 각 가 0에 가깝다면, DDPM의 ancestral sampling과 VP-SDE reverse diffusion sampler는 동일한 식이 된다
- proof in Appendix E
4.2. PC samplers
-
DDPM ancestral sampling이나 reverse diffusion samplers는 reverse SDE의 해를 이용해서 샘플링하는 과정으로 볼 수 있다
-
NCSN에서는 score-based MCMC approach(annealed Langevin dynamics)를 이용해서 샘플링했는데, 이것은 estimated score function을 따라가도록 설계된 함수
- 일반적인 SDE와 달리 solution을 improve하기 위한 additional information(score)이 주어진 상황으로 생각할 수 있다
-
Predictor-Corrector (PC) samplers
-

-
predictor
- next timestep의 sample을 "predict"
- reverse SDE의 solution
- 본 논문에서 제안한 reverse diffusion sampler를 써도 되고, Euler-Maruyama같은 기존의 SDE solver 아무거나 가져와서 써도 됨
-
corrector
- estimated sample의 marginal distribution (score-based)을 참고해서 reasonable한 확률공간에 존재하도록 sample을 "correct"
- score-based MCMC approach
- 본 논문에서는 annealed Langevin dynamics를 사용하지만 다른 MCMC methods를 써도 됨
-
기존의 NCSN은 corrector-only, DDPM은 predictor-only sampling
-
이제 NCSN, DDPM의 loss 뿐만 아니라 sampling method도 한 framework로 통합했다
-
-
Experiments
-

-
CIFAR-10으로 실험, FID로 평가
-
results
- ancestral sampling보다 reverse diffusion이 약간 나았다
- corrector only는 성능이 매우 나빴다
- Predictor only로 timestep을 2배 늘리는 것보다 PC sampling을 이용하는 게 성능이 훨씬 좋았다 (계산량은 같음)
-
-
Detailed PC sampling algorithms
-
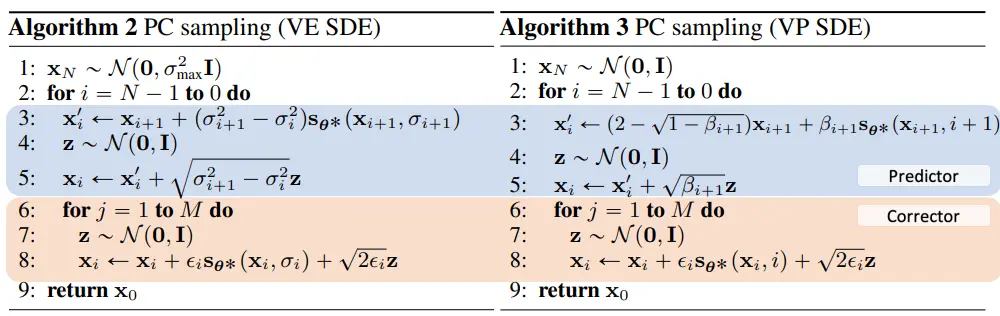
-
Predictor로는 reverse diffusion sampler, Corrector로는 annealed Langevin Dynamics를 이용함
-
4.3. Probability flow and connection to neural ODEs
- probability flow ODE
- For all diffusion processes, there exists a corresponding deterministic process whose trajectories share the same marginal as the SDE
- 그러한 deterministic process는 아래의 ODE 식을 만족한다
- derivation at Appendix D.1
- score를 알고 있으면 deterministic한 trajectory를 얻을 수 있다
- neural ODE의 한 예시로 볼 수 있다
- Manipulating latent representations
- probability flow ODE를 이용하면 를 latent space 로 인코딩할 수 있다
- => we can manipulate latent representation
- 이 encoding은 기존의 invertible models와는 달리 uniquely identifiable하다
- Efficient sampling
- probability flow ODE를 이용해서 샘플링하면 NFE를 줄일 수 있음
- 실험 결과visual quality를 해치지 않는 선에서 90%까지 줄일 수 있었다 - accuracy <-> efficiency tradeoff
- probability flow ODE를 이용해서 샘플링하면 NFE를 줄일 수 있음
- DDIM의 아이디어와 결이 비슷함
- Consistency Models로 이어짐
- Exact likelihood computation
- DDPM loss는 ELBO value를 minimize함
- neural ODE의 특성을 어떻게 잘 하면 (???) exact likelihood on any input data를 구할 수 있음
- experiments
- CIFAR-10으로 실험, bits/dim으로 평가
- results
- our DDPM > 기존 DDPM -> exact likelihood를 계산하기 때문
- DDPM cont. (objective에서 timestep을 continous value로 놓고 학습했을 때)이 discrete version보다 나았음 -> further improves likelihood
- sub-VP SDE > VP SDE
- improved architecture (DDPM++) > DDPM
4.4. Architecture improvements
- 아키텍쳐 좀 손봐서 NCSN++랑 DDPM++ 만들었다
- guided diffusion 레포에 반영되어 있음
5. Controllable Generation
- our framework의 continuous한 구조 덕분에 condition 를 추가할 수 있다
- we can also produce samples from
- bayes rule에 의해
- 이걸 reverse SDE의 기존 score function 자리에 넣으면
- 는 classifier를 따로 학습시켜서 구할 수도 있고 (classifier guidance in ADM), domain knowledge나 heuristics를 이용해서 적당히 정의해도 된다
- Experiments : class-conditional generation, inpainting, colorization
- 이 framework를 일반적인 inverse problems에 응용할 수 있다
