1. RNN의 핵심 문제: Exploding / Vanishing Gradient
Backpropagation Through Time (BPTT)
- RNN의 순전파는 다음과 같다:
- 역전파 시 반복적으로 가 곱해지기 때문에 아래와 같은 문제가 생김:
- 이면 gradient가 점점 작아짐 → Vanishing Gradient
- 이면 gradient가 점점 커짐 → Exploding Gradient
Xavier / He Initialization의 한계
- 파라미터를 1에 가깝게 초기화하려는 시도
- 하지만 시퀀스 길이가 길면 여전히 gradient가 폭발하거나 사라질 수 있음
CNN의 경우 가중치가 레이어별로 고정되어 있고 깊이도 상대적으로 작아서 gradient가 폭발/소멸하는 문제가 덜하지만 RNN은 하나의 가중치 행렬을 시퀀스 길이만큼 반복해서 곱하기 때문에, 길이가 길수록 gradient가 지수적으로 커지거나 작아질 위험이 큼
2. 해결 방법
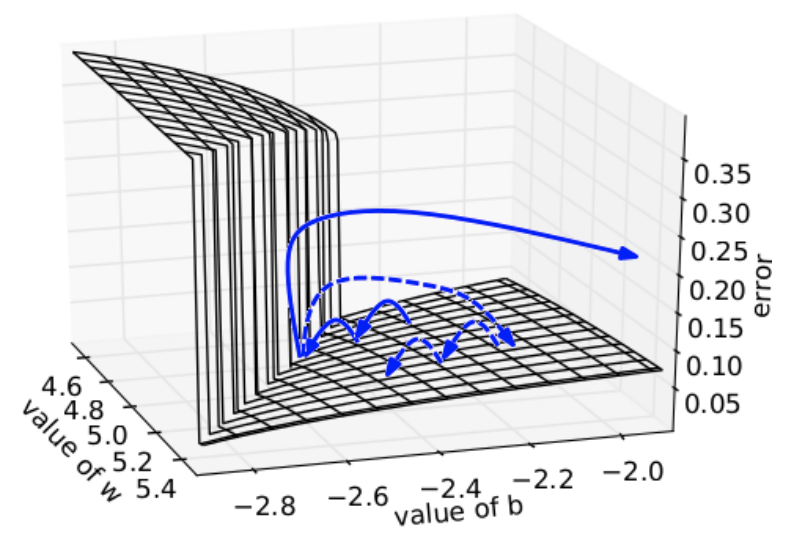
(1) Exploding Gradient → Gradient Clipping
- gradient가 일정 threshold 이상이면 크기만 잘라내고 방향은 유지함
# Algorithm 1: Pseudo-code for norm clipping the gradients
# Let g be the gradient vector
if ||g|| ≥ threshold:
g ← (threshold / ||g||) * g
end if ||g||는 gradient 벡터의 L2 norm (크기)
만약 이 크기가 미리 정해둔 threshold보다 크다면:
방향은 그대로 유지하고
크기만 threshold로 비례 축소함 (normalize 후 scale)
(2) Vanishing Gradient 문제는 왜 해결이 어려운가?
문제 요약
- RNN에서는 시간 축으로 같은 가중치 행렬이 반복 곱해지므로,
- 인 경우 gradient가 지수적으로 작아져서 사라짐(Vanishing)
- 이 현상은 시퀀스가 길어질수록 심각해짐
- 특정 입력이 몇십 step 뒤 출력에 영향을 미치기 어려워짐
- 즉, long-term dependency 학습이 어려워짐
해결책: 수학적으로는 어렵다 → 구조적으로 해결하자
수학적으로 해결 어려운 이유
- gradient는 곱셈 연산으로 계속 줄어들 수밖에 없음
- 단순히 초기화를 조정해도 시퀀스가 길면 결국 사라짐
구조적 접근: Long-term Dependency를 기억하게 하자
1. LSTM (Long Short-Term Memory)
기존 RNN은 시퀀스가 길어질수록 오래된 정보를 잊어버리는 문제가 발생함 → Vanishing Gradient Problem
이를 해결하기 위해 LSTM은 내부에 Cell State()라는 장기 기억용 벡터를 도입함.
핵심 아이디어
- 기존 RNN은 오직 (hidden state) 하나만 가지고 정보를 주고받았음
- LSTM은 외에 cell state 를 따로 유지하여 중요한 정보는 이 쪽에 따로 저장함
- 정보의 추가(add)와 삭제(remove)를 gate를 통해 제어함
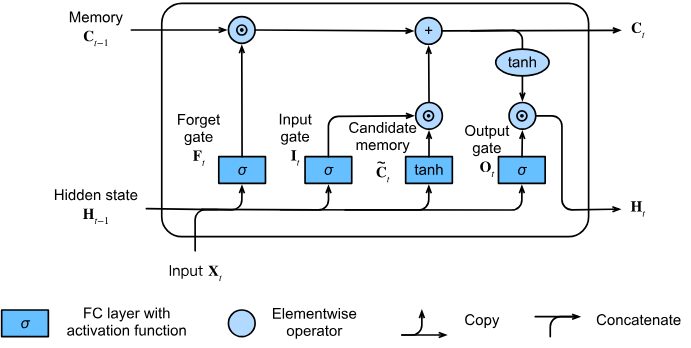
LSTM 구조 구성요소
LSTM은 총 3개의 Gate와 2개의 State를 사용함
| 요소 | 역할 |
|---|---|
| Cell state (장기 기억) | |
| Hidden state (출력) | |
| Forget gate | 과거 정보를 얼마나 지울지 결정 |
| Input gate | 새 정보를 얼마나 저장할지 결정 |
| Output gate | 최종적으로 출력할 정보를 제어 |
1. Forget Gate (잊을 정보 선택)
과거의 기억 을 얼마나 유지할지 결정
- 값이 1에 가까우면 기억 유지, 0에 가까우면 잊음
2. Input Gate (저장할 정보 선택)
현재 입력과 이전 출력으로부터 새 정보를 생성하고 얼마나 저장할지 결정
3. Cell State 업데이트
기존 기억 과 새로운 후보 를 조합하여 현재 기억 를 생성
4. Output Gate (출력 제어)
출력할 정보를 결정
최종 hidden state 는 다음과 같이 계산됨
요약: LSTM 작동 순서
- Forget gate로 중 일부를 제거
- Input gate로 새 정보 중 일부를 선택하여 추가
- 이 두 정보를 합쳐 새로운 생성
- Output gate로 출력값 생성
장단점 정리
장점
- RNN보다 오래된 정보를 잘 기억할 수 있음
- Vanishing Gradient 문제를 완화함
- 시계열, 번역, 음성 인식 등에 효과적
한계
- 완전히 문제를 해결하지는 못함 (아주 긴 시퀀스에서는 여전히 힘듦)
- 구조가 복잡하고 파라미터 수가 많음
2. GRU
GRU는 LSTM과 유사한 성능을 가지면서도 구조가 더 간단하고 계산 효율이 높은 순환 신경망.
핵심 특징
- LSTM과 달리 cell state()가 없음
- 대신 모든 정보를 hidden state() 안에 담아 전달함
- 구조가 간단해져서 파라미터 수가 적고 계산이 빠름
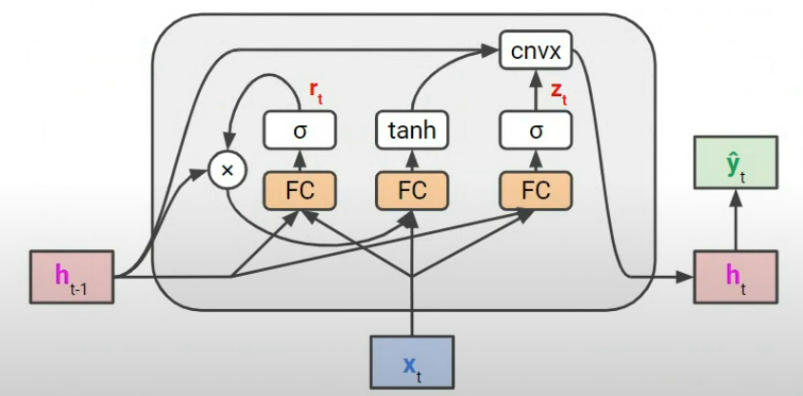
GRU 구조
1. Update Gate ()
- 과거 정보를 얼마나 유지할지 결정
- LSTM의 forget + input gate 기능을 하나로 합친 것
2. Reset Gate ()
- 과거 정보를 얼마나 무시할지 결정 (새로운 정보 반영 여부)
3. Candidate Hidden State ()
- 현재 시점의 새 정보를 계산함
- reset gate가 적용된 과거 hidden state를 사용
4. 최종 Hidden State ()
- 과거 정보와 새로운 정보의 가중 평균
- update gate가 둘 사이를 얼마나 반영할지 결정함
GRU 핵심 요약
- cell state 없이 hidden state 하나로 모든 정보 처리
- Gate 조합이 더 간단해서 구조도 단순
- LSTM과 성능은 비슷하지만
- 파라미터 수 적고
- 연산량이 적음
- 학습 속도가 빠름
3.Seq2Seq: Sequence-to-Sequence 모델
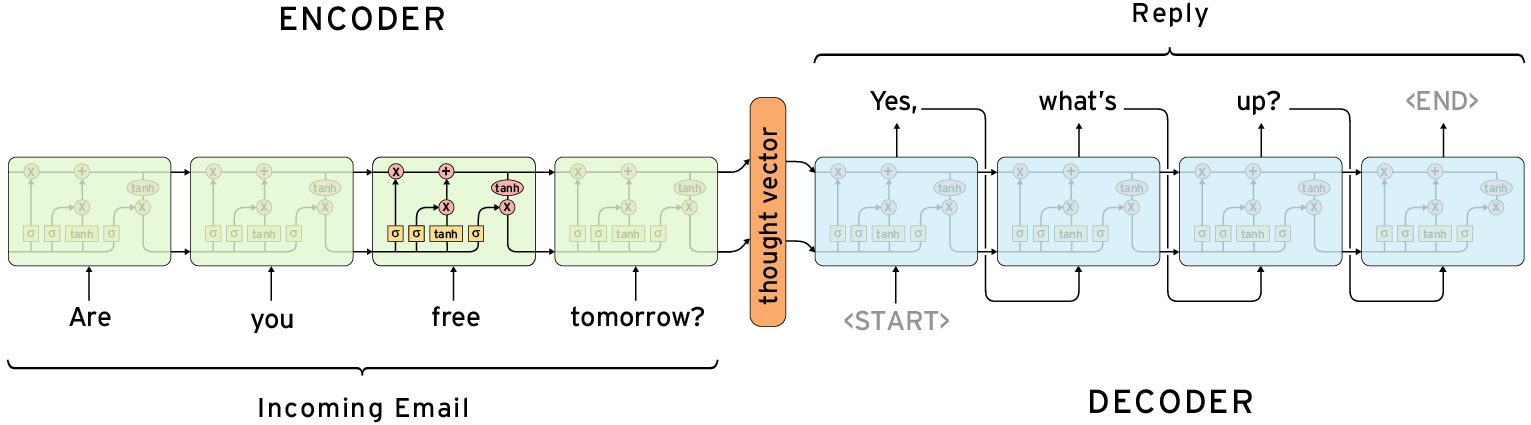
개요
- Seq2Seq는 입력 시퀀스와 출력 시퀀스의 길이가 다르고, 의미/순서도 다를 수 있는 문제를 다루는 모델 구조
- 대표적인 사용 예시: 기계 번역
- 예: "나는 밥을 먹는다" → "I eat rice"
왜 필요한가?
- 단순 RNN은 입력과 출력 길이가 같고, 시간 순서가 매칭되어야 잘 동작함
- 하지만 번역 같은 문제에서는 입력과 출력의 길이도 다르고, 단어 순서도 다름
구조 요약
1. Encoder
- 입력 시퀀스를 순서대로 읽음
- 내부적으로 hidden state를 업데이트하면서 전체 문장을 요약
- 최종 hidden state는 context vector로 사용됨
- 이 단계에서는 아웃풋이 없음
Encoder는 many-to-one 구조
2. Decoder
- 인코더가 만든 context를 받아, 하나씩 출력 생성
- 처음 입력은 special token (start of sentence)
- 이전 시점의 출력이 다음 시점의 입력으로 들어가는 방식 → Auto-regressive Generation
Decoder는 one-to-many 구조
Auto-regressive Generation
- 디코더는 이전에 생성한 단어를 기반으로 다음 단어를 예측함
- 반복적으로 다음 단어를 생성해서 전체 문장을 생성함
Teacher Forcing (학습 시)
- Auto-regressive 방식은 예측이 틀리면 이후 모든 결과에 영향
- 학습 중에는 예측값이 아닌 정답을 다음 입력으로 넣어줌 → Teacher Forcing
if use_teacher_forcing:
decoder_input = target[t] # 정답 사용
else:
decoder_input = predicted_token # 모델이 생성한 예측 사용
