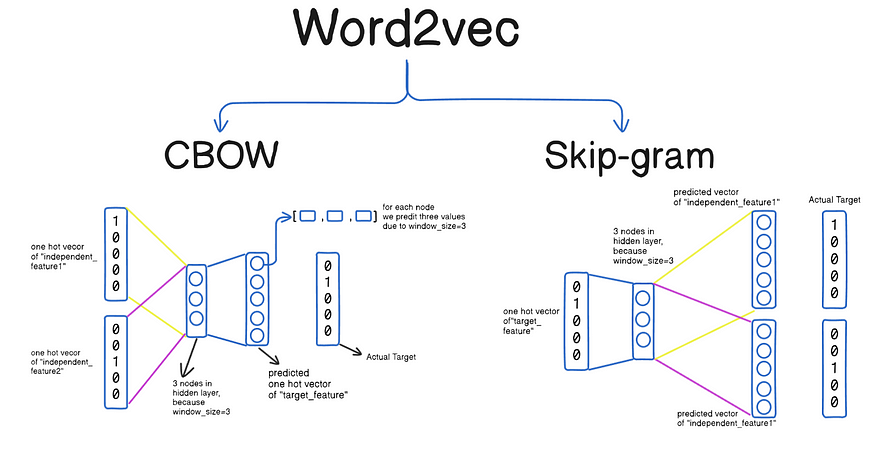
1. Sequential Data란?
- 순서(temporal order)가 중요한 데이터
- 예: 문장, 오디오, 주가, 센서 로그
- Target
- 시퀀스인지(=sequence-to-sequence) or 스칼라인지(=sequence-to-one)는 task에 따라 달라짐
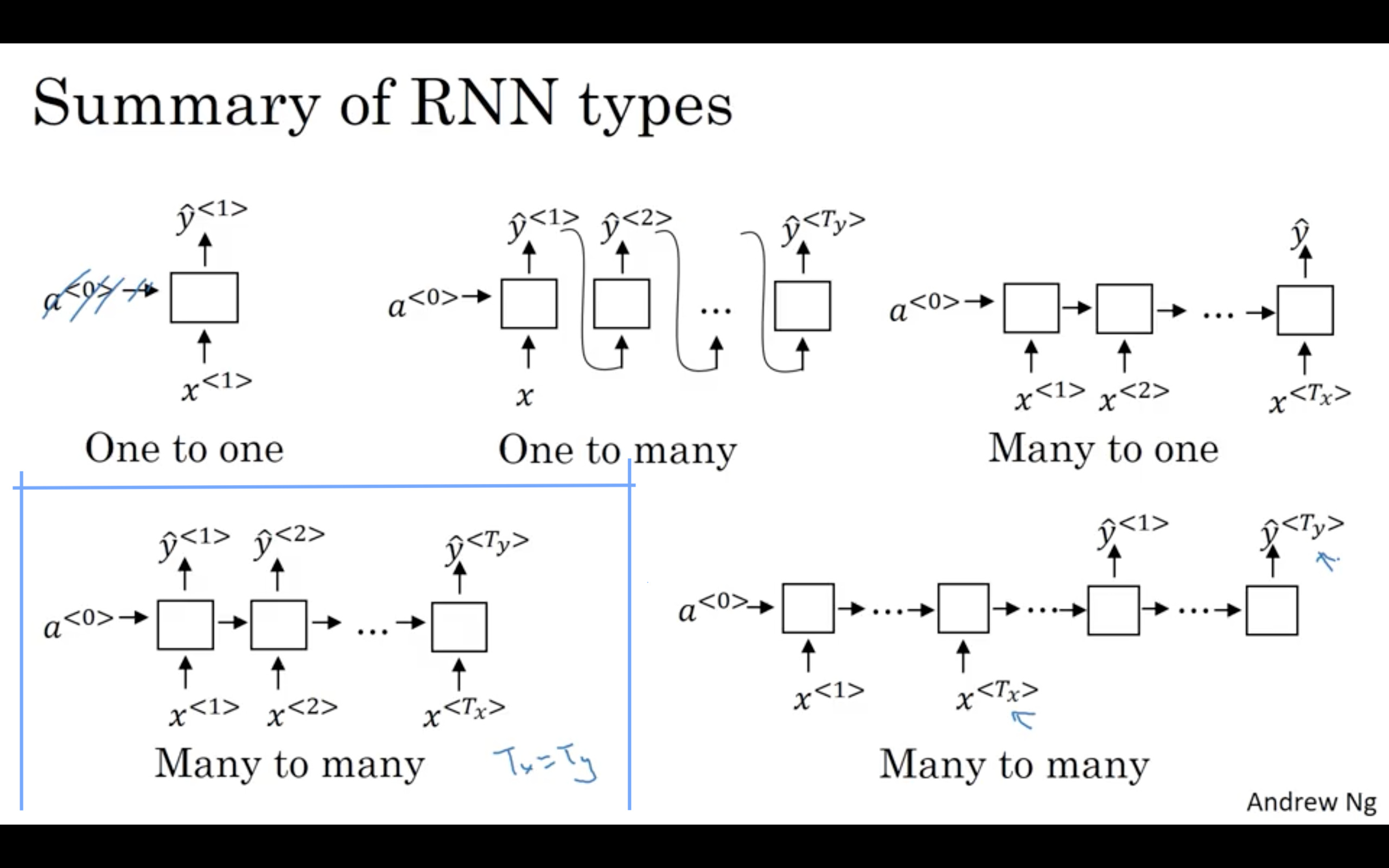
2. 대표 문제 유형 (Input / Output)
| 유형 | 예시 Task | I/O 형태 |
|---|---|---|
| One → One | 전통 MLP/ConvNet | |
| Many → One | Action Recognition (동영상 → class) | |
| Many → Many | Frame Labeling | |
| One → Many | Image Captioning | |
| Many → Many | Video Captioning |
3. Word Embeddings
- 단어를 -차원 유클리디안 공간의 벡터로 표현
- 언어학적 단위
- 가장 작은 의미 단위 (morpheme) 등을 벡터로 추상화
3-1) Data-driven 접근 (의미를 ‘데이터로부터’ 학습하기)
기본 아이디어
"단어의 의미는 같이 자주 등장하는 단어들로부터 유추할 수 있다"
즉, 단어의 정의를 사전이 아니라 통계로부터 끌어내자는 전략임
📘 예시: "학생"이라는 단어는?
- 사전 정의 없이,
- "학생" 주변에 자주 나오는 단어들을 보면:
- "학교", "수업", "과제", "시험", "선생님", ...
- 이걸 보면 우리는 이 단어가 대충 교육과 관련된 어떤 존재임을 알 수 있음
Word2Vec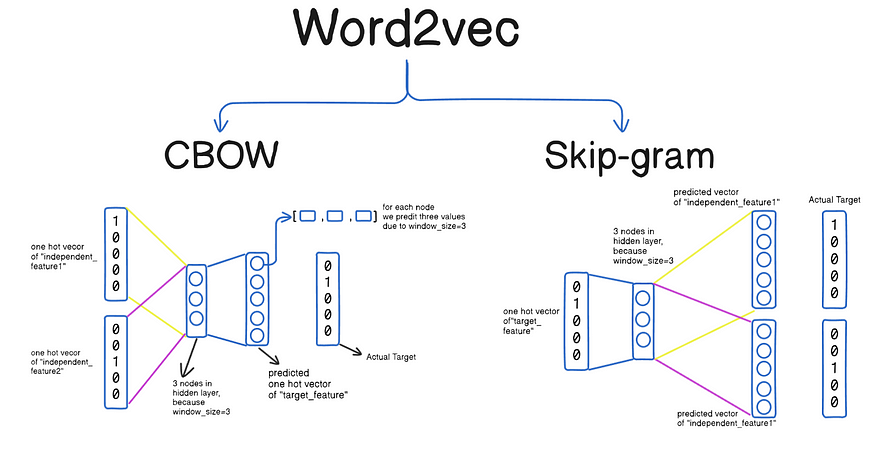
- 대상 단어 를 중심으로, 윈도우 내 주변 단어들을 예측
입력: 중심 단어
출력: 주변 단어들이 나올 확률
-
학습 목표(skip-gram):
-
확률은 softmax를 통해 계산됨:
-
실제 학습 시엔 속도 문제로 negative sampling 또는 hierarchical softmax 사용
🔧 GloVe (Global Vectors)

- Word2Vec은 local context 기반인 반면,
GloVe는 전체 말뭉치에서 단어 쌍 간의 동시 등장 빈도를 사용
아이디어: "두 단어가 자주 같이 등장할수록, 두 벡터의 내적이 커야 한다."
-
핵심 수식:
- : 단어 와 단어 의 동시 등장 빈도
- , : 각각의 단어 벡터
- log scale을 쓰는 이유: 분포가 치우쳐 있기 때문
-
손실 함수:
-
: 희귀 단어 쌍의 영향은 줄이고, 자주 나오는 쌍에 집중하기 위한 가중치 함수
4. RNN 기본 구조 (Many → One)
Sentiment Analysis 예시: 주어진 텍스트에 대해 긍정적인지 부정적인지 이진분류(regress)로 예측해보자
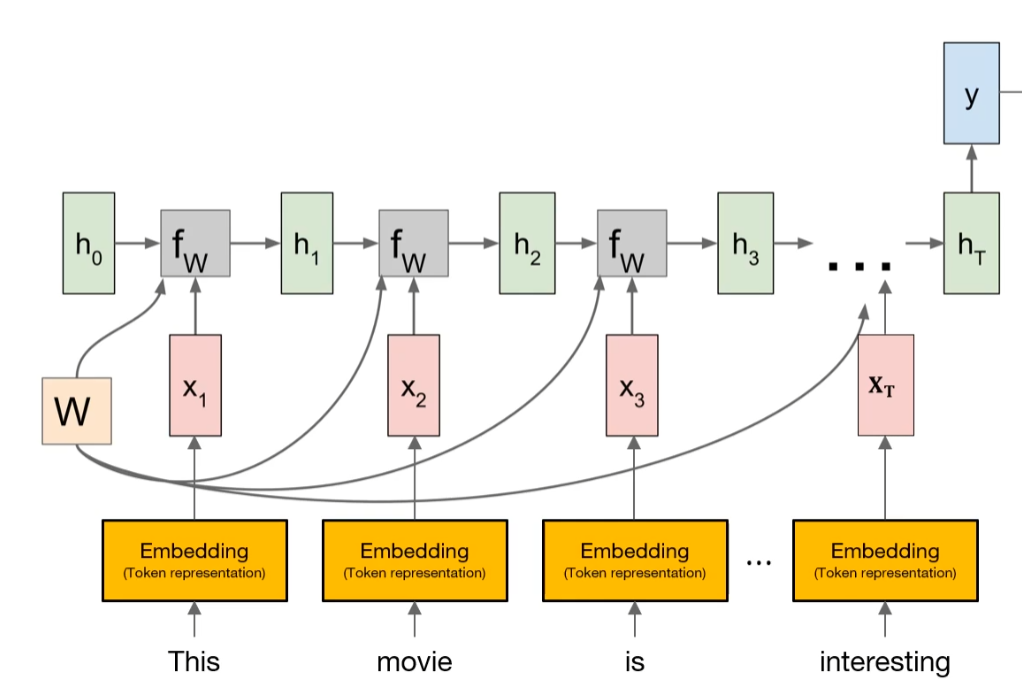
4-1) 기본 개념
- RNN은 순차 데이터(시퀀스) 를 처리하기 위한 신경망 구조
- 입력이 순차적일 때, 과거 정보를 반영해서 현재를 해석하는 모델
텍스트, 음성, 시계열 등 "순서가 중요한 데이터"에 최적
CNN으로 문장을 못 쓰는 이유
- Conv는 고정 입력 길이 필요
- 문장은 길이가 가변적 ⇒ 패딩, 슬라이딩 창 필요하여 비효율
- → Encoder (RNN) 로 문장 벡터 추출 후 downstream 사용
4-2) 기본 구조 (Many → One 예: Sentiment Analysis)
순서별 처리 방식
-
단어 임베딩:
- : 시퀀스 길이 (ex. 단어 개수)
- : 임베딩 차원
- 즉, 입력은 개의 벡터로 구성된 행렬 형태
-
RNN 셀 반복:
- : 현재 time step의 hidden state
- : 입력-은닉 가중치
- : 이전 은닉-현재 은닉 가중치
- 가중치는 모든 시점에서 공유(변하지 않음)
-
최종 출력 (예: 긍정/부정 이진 분류):
4-3) 백프로파게이션 (BPTT: Backprop Through Time)
- 일반 신경망처럼 역전파하지만,
- 모든 시점의 RNN 셀을 unroll해서 gradient를 계산함
손실이 여러 time-step을 거쳐 전파되므로,
Gradient Vanishing / Exploding 문제가 자주 발생함
5. RNN을 이용한 Language Model (Many → Many)
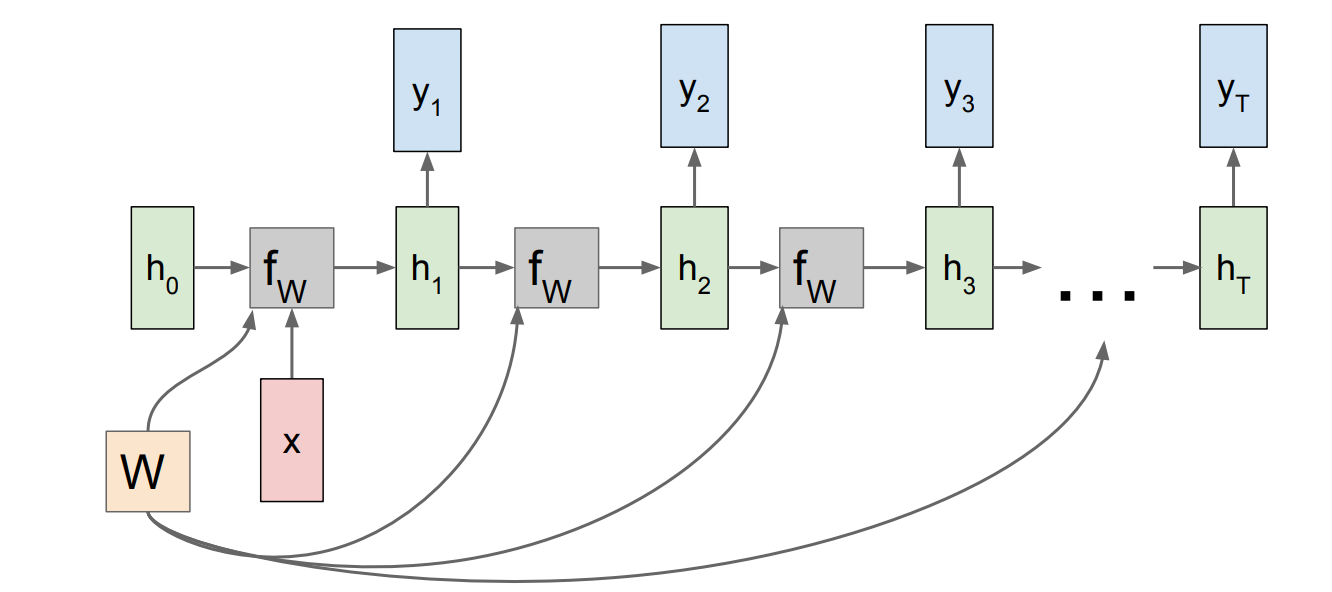
5-1) 개념 정리
Many-to-Many는 입력 시퀀스 에 대해 출력 시퀀스 를 생성하는 구조
- 입력과 출력의 길이가 같을 수도 있고, 다를 수도 있음
- 대표 과제:
- 시퀀스 레이블링 (POS tagging, NER 등) →
- 기계 번역 (English → Korean 등) →
- 언어 모델링 → 다음 단어 예측
- n-grams 사용시 조합 수가 지수적으로 (exponentially) 증가해서 RNN 사용
5-2) 언어 모델 예시 (Language Modeling)
- 주어진 단어 시퀀스 에서
다음 단어의 확률 를 예측하는 문제
수식 흐름:
- : 시점에서 예측된 다음 단어 확률 분포
- 실제 다음 단어 와 비교해 Cross Entropy Loss 계산
5-3) 시퀀스 태깅 예시 (e.g. POS Tagging, Frame Classification)
- 입력 에 대해 동일 길이의 레이블 예측
- 예: 단어마다 품사 태그 붙이기, 프레임별 동작 라벨링 등
수식 흐름 (각 시점에서 바로 예측):
- 각 시점마다 레이블 출력 ⇒ 개의 Cross-Entropy Loss 평균
6. Multi-layer RNN (Stacked RNN)
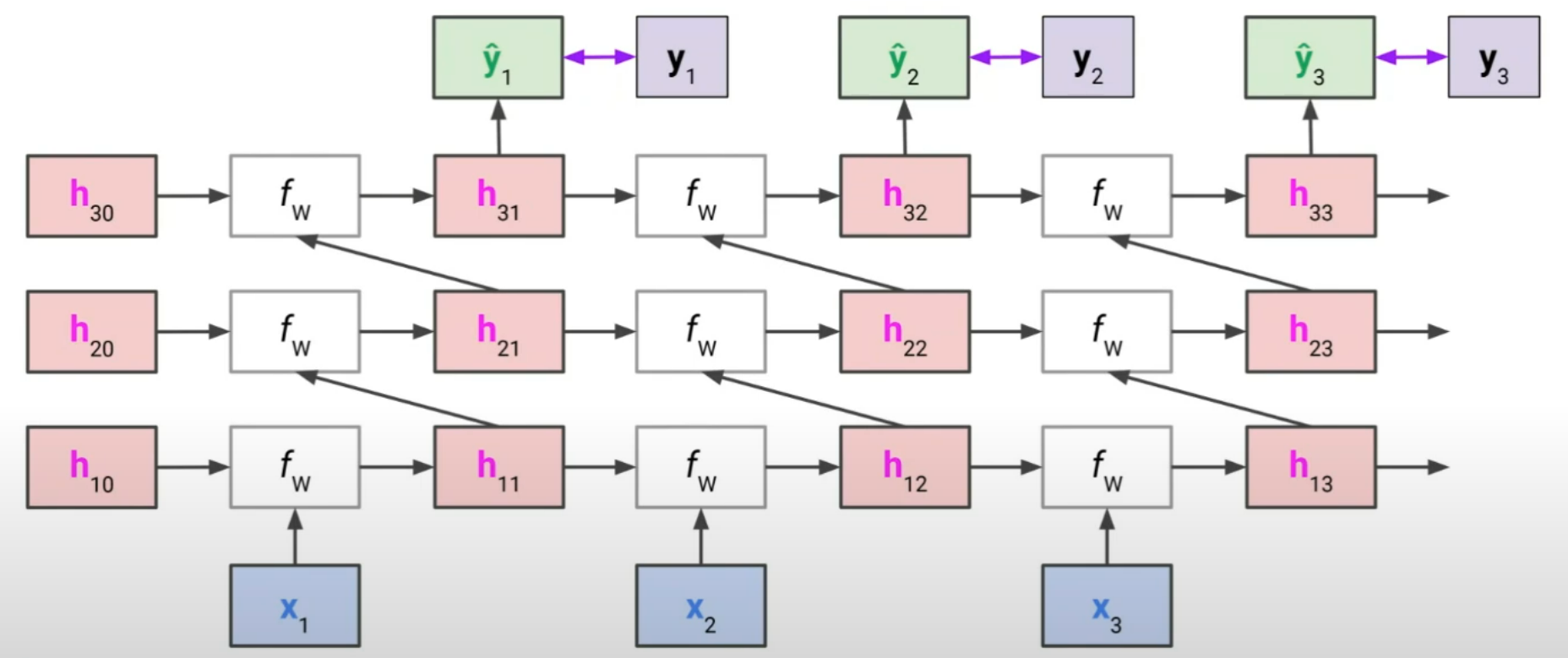
6.1) 개념 요약
RNN을 여러 층 쌓아서 더 복잡한 패턴을 학습할 수 있도록 만든 구조
- 한 층의 RNN hidden state 출력이 다음 층의 입력으로 들어감
- 일반적인 구조:
- Layer 1:
- Layer 2:
- ...
- 최종 출력:
6.2) 수식 표현
한 시점 에서 번째 RNN layer의 계산:
- 일 때:
- 파라미터 는 레이어마다 별도 (공유되지 않음)
- 시점 간에는 공유, 레이어 간에는 별도
6.3) 왜 여러 층을 쌓는가?
- 1층짜리 RNN은 제한적인 표현력
- 여러 층을 쌓으면:
- 낮은 층: 저수준 패턴 (단어, 문법 등)
- 높은 층: 고수준 의미 (문장 의미, 감정 등)
7. PyTorch RNN API 메모
rnn = nn.RNN(input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=False)
# 입력: (seq_len, batch, input_size)
x = torch.randn(seq_len, batch, embedding_dim)
h0 = torch.zeros(num_layers, batch, hidden_dim)
output, hn = rnn(x, h0)8. RNN의 장점과 단점 정리
장점 (왜 쓰는가?)
| 항목 | 설명 |
|---|---|
| 가변 길이 입력 가능 | 입력 시퀀스의 길이가 달라도 처리 가능 (패딩만 잘 하면 됨) |
| 파라미터 수 고정 | 시간 길이에 관계없이 같은 RNN 셀 반복 사용 → 메모리 효율적 |
| 순서 정보 유지 | 시계열 구조에 맞게 정보를 앞에서 뒤로 전달 |
| 모델이 긴 문장도 다룰 수 있음 | 단어 수 5개든 500개든, 구조상 문제 없음 |
단점 (왜 요즘 잘 안 쓰이는가?)
| 항목 | 설명 |
|---|---|
| 병렬화 불가 | 시퀀스는 순차적으로 처리해야 하므로 GPU 최적화 어려움 (느림) |
| Vanishing/Exploding Gradient | 시퀀스가 길어질수록 역전파에서 기울기 소실/폭발 가능 |
| 장기 기억 어려움 | 앞에서 본 정보가 뒤로 갈수록 사라짐 (long-term dependency 문제) |
| 학습 어렵고 느림 | 수렴까지 오래 걸림, 학습률 민감함 |
정리 요약
RNN은 "순서가 있는 데이터"에 아주 유용하지만
병렬 처리와 장기 기억이 약해서
요즘은 LSTM, GRU, Transformer로 많이 대체됨
