딥러닝 Regularization & Optimization
1. Regularization(정규화)
목적 : 딥러닝은 overfitting에 취약하기에 additional penalty term을 목적 함수에 추가하여 가중치를 작거나 0으로 만듦.
-
예시:
Linear RegressionRidge Regression (L2 Regularization 추가)
→ 여기서 항이 추가적인 패널티(regularization term) 임. 이 항이 클수록 weight를 작게 만들도록 강제하며, 결국 과적합(overfitting)을 방지.
Ridge Regression
목표
- 선형 회귀 + 과적합 억제
- 손실 함수에 L2 패널티 추가
수식
패널티 항 해석
- → 파라미터 전체 크기를 부드럽게 줄임
- 이득(오차 감소)이 패널티보다 커야 가 커질 수 있음
시각적 직관
- 원 안에서 해 찾음 → 덜 복잡한 모델 선택
- ⇒ 원이 작아짐 ⇒ 값 더 작아짐
λ 값의 의미
- → 일반 선형 회귀
- 커질수록 규제가 강해지고 weight 값 작아짐
- 너무 크면 과소적합 위험 있음
Lasso Regression
목표
- 선형 회귀 + 불필요한 변수 제거
- 손실 함수에 L1 패널티 추가해서 weight를 0으로 만듦
수식
패널티 항 해석
- → 각 파라미터의 절댓값에 패널티 부여
- weight가 완전히 0이 되는 경우가 많이 생김
- ⇒ 불필요한 특성 제거 = feature selection 효과
시각적 직관
- L1 제약 조건은 다이아몬드 모양
- 많은 경우 최적점이 꼭짓점에 위치 → 특정
- 예시에서 빨간 점처럼 하나의 축에 완전히 붙는 경우가 많음
λ 값의 의미
- λ가 커질수록 정규화 강도 증가 → 더 많은 weight가 0이 됨
- 너무 크면 중요한 변수까지 제거해서 성능 저하될 수 있음
2. Early Stopping
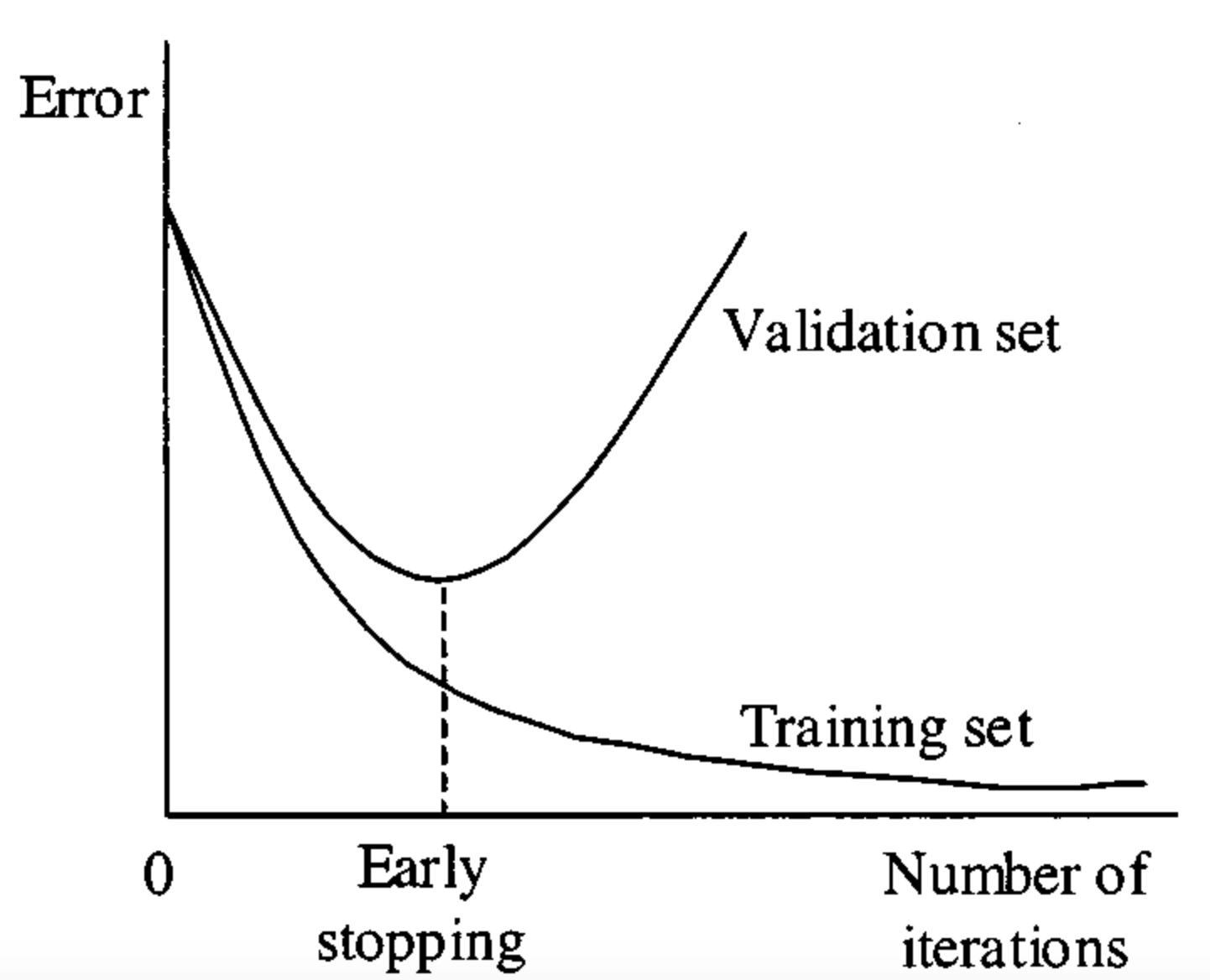
- 훈련 중 검증(validation) loss를 모니터링
- 일정 에폭 이후에는 노이즈를 배우는 구나 하고 중단
- 테스트셋은 절대 사용하지 않음!
3. Dropout
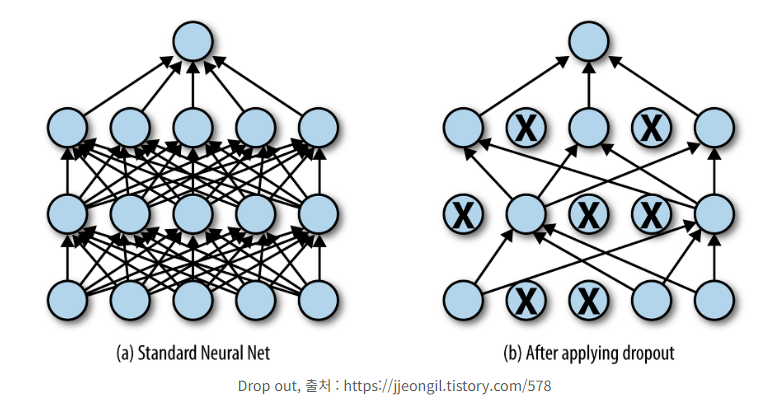
목적
딥러닝 모델이 특정 뉴런이나 패턴에 과하게 의존하는 것을 방지
학습 시 일부 뉴런을 무작위로 꺼서(co-adaptation 차단) 과적합 방지
동작 방식
Train 시: 각 뉴런을 확률 ( p )로 비활성화 (0으로 만듦)
Test 시: 모든 뉴런 사용하되, 출력을 ( p )만큼 scale 해서 정규화
->이거 싫어서 train 때 p만큼 scaling하자
import numpy as np
def train_step(data, p): # p: dropout 비율 (ex. 0.5면 50% 꺼버림)
h1 = np.maximum(0, np.dot(w1, data) + b1) # ReLU
u1 = (np.random.rand(*h1.shape) < p) / p # h1의 크기만큼 랜덤하게 뽑은 값이 p보다 작으면 0
h1 *= u1 # 드랍아웃 적용
h2 = np.maximum(0, np.dot(w2, h1) + b2)
u2 = (np.random.rand(*h2.shape) < p) / p #p로 나눠서 scaling
h2 *= u2
return np.dot(w3, h2) + b3
def test_step(data):
h1 = np.maximum(0, np.dot(w1, data) + b1) * p # p를 곱해서 scaling
h2 = np.maximum(0, np.dot(w2, h1) + b2) * p
return np.dot(w3, h2) + b3테스트 시에는 dropout을 적용하지 않음
파이토치로 적용하는 법
from torch import nn
class MyModel(nn.Module):
def __init__(self, config):
super().__init__()
self.linear = nn.Linear(224, 32)
self.dropout = nn.Dropout(p=0.2) # 20% 확률로 뉴런 끔
def forward(self, inputs, training=True):
x = self.linear(inputs)
x = self.dropout(x) # 학습 시에만 드랍아웃 적용됨
return x3-1) Cutout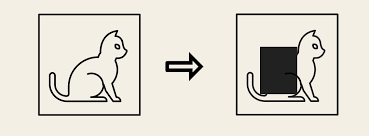
- 입력 이미지의 일부를 무작위로 잘라내기 (사각형 블록)
- 데이터 증강 기법의 일종
- 모델이 전체 이미지가 아니라 부분적인 정보만으로도 예측 가능하도록 학습
- 일반화 성능 향상 효과
4. 배치 정규화 (Batch Normalization)
처음 layer에선 전처리된 인풋이 잘 될 수 있지만? 그 다음 층에선?
층이 깊어질수록 중간에 흐르는 값들(activation) 이 점점 망가져서 Batch normalization을 해보자
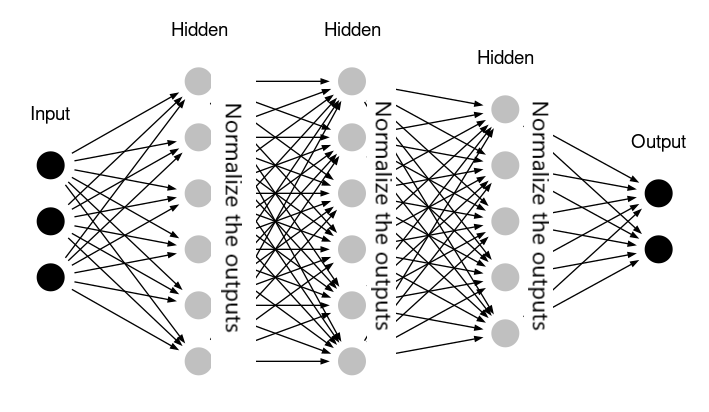
4-1) 공식 (수식 정리)
- : 번째 샘플의 번째 feature 값
- : 미니배치 크기
분산 계산
정규화된 값 계산
- : 분모 안정화를 위한 아주 작은 수
-> 이거 이렇게 해도돼? 레이어가 학습해야 할 표현력이 떨어질 수 있겠는데?
해결 방법
정규화된 출력에 대해 다음과 같이 선형 변환 파라미터를 추가:
- : scaling factor (학습됨)
- : shifting bias (학습됨)
즉, BatchNorm을 적용한 후에도 네트워크가
"필요하면 원래 표현으로 되돌릴 수 있게" 유연성을 보장함
test할 땐 학습할 때 분산, 평균을 평균내서 사용함.
4-2) 장점
-
깊은 네트워크 학습이 훨씬 쉬워짐
→ 층이 많아도 학습 안정성 유지 -
Gradient 흐름 개선
→ Vanishing / Exploding 문제 완화 -
더 큰 learning rate 사용 가능
→ 빠른 수렴 가능 -
초기값에 덜 민감해짐
→ 초기 weight 설정이 조금 틀려도 잘 작동함 -
학습 중 regularization 효과
→ Dropout 없이도 과적합 방지 기여
4-3) 다른 정규화 기법 비교
| 기법 | 통계 계산 기준 | 주 용도 |
|---|---|---|
| BatchNorm | 배치 단위 | CNN |
| LayerNorm | 특성(feature) 단위 | NLP, 트랜스포머 |
| InstanceNorm | 이미지별 채널별 | 스타일 트랜스퍼 |
| GroupNorm | 채널 그룹 단위 | Detection, small-batch CNN |
배치 정규화는 데이터가 i.i.d가 아니거나,
학습 도중 데이터 분포가 계속 바뀌면 잘 작동하지 않을 수 있음!
5. 최적화 (Optimization)
5-1) SGD의 문제점
- 로컬 최소점이나 안장점에 빠질 수 있음
- 진동(지터링, jittering) 현상으로 느린 수렴
- 데이터셋이 큰 경우 Gradient 추정이 noisy함
5-2) Momentum
- 이전 step의 방향을 따라 속도 누적
- 수렴 가속 + 진동 완화
5-3) Adagrad
- 학습률을 feature별로 자동 조절
- 자주 등장하는 feature → 학습률 감소
5-4) RMSProp
- Adagrad의 누적합 대신, 지수 감쇠 평균 사용해 학습률이 너무 작아지는 문제를 보완
- step마다 adaptive한 learning rate 적용
5-5) Adam
- Momentum + RMSProp 결합
- 딥러닝의 기본 세팅으로 가장 많이 사용
5-6) Second-Order Methods
- 예: Newton Method, L-BFGS
- Hessian 사용해서 더 빠르게 수렴
- 계산량/메모리 부담이 커서 딥러닝에서는 잘 안 씀
6. 요약
| 항목 | 기법 | 하이퍼파라미터 | 비고 |
|---|---|---|---|
| Regularization | L2, L1, Dropout, Cutout | λ, p, mask size | 과적합 방지 |
| EarlyStopping | Patience 기준 | monitor metric | 검증 loss 기준 |
| Normalization | BatchNorm, LayerNorm 등 | ε, γ, β | train/eval 구분 필수 |
| Optimizer | Adam, RMSprop, SGD+Momentum | η, β1, β2 | LR scheduler 적용 가능 |
| Augmentation | Flip, Crop, CutMix | 확률, 강도 | overfitting 감소 |
