딥러닝 학습 핵심 정리: 활성화 함수부터 전처리, 학습률까지
1. Activation Function (활성화 함수)
Sigmoid
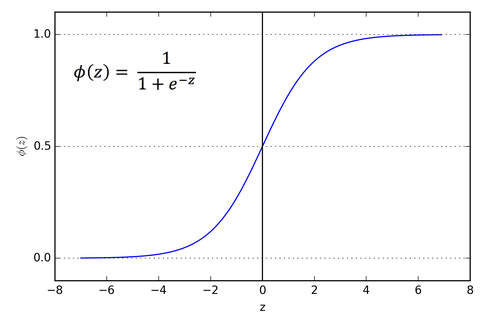
-
출력 범위: 0 ~ 1
-
직관적인 출력
-
Gradient vanishing
→ 입력값이 크면 기울기 0 근처로 수렴 -
Not zero-centered
→ 항상 양수 출력 → gradient가 한쪽 방향만 흐름 -
입력이 항상 양수면
→ 모든 gradient가 양수 or 음수
일반적으로 은닉층에서는 사용하지 않음,
출력층에서 확률 해석용으로 사용
Tanh
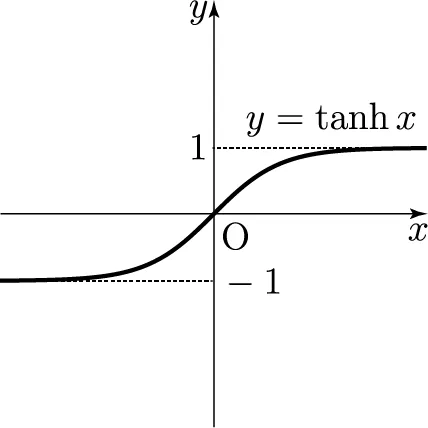
- 출력 범위: -1 ~ 1
- Zero-centered
- 여전히 gradient vanishing
출력층에서 확률 해석용으로 사용
ReLU (Rectified Linear Unit)
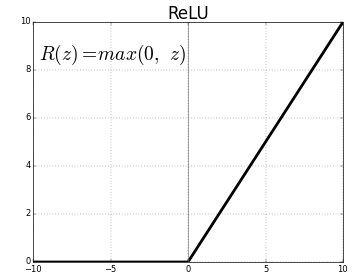
-
정의:
-
양수 구간에서 선형 → saturation 없음
-
계산 간단하고 빠름
-
Dead ReLU problem
→ 이면 gradient = 0 -
Zero-centered 아님
기본적으로 가장 많이 사용됨
Leaky ReLU
- 정의:
- 음수에서도 작은 gradient 존재 (보통 )
- Dead ReLU 문제 해결
- 는 추가적인 하이퍼파라미터
ELU (Exponential Linear Unit)
- 에서 exponential 형태로 완만하게 접근
- Dead neuron 완화
- 연산 비용 증가
결론
- 기본은 ReLU
- 성능 향상 필요 시 → Leaky ReLU 또는 ELU
- Sigmoid / Tanh는 출력층에만 사용
2. 데이터 전처리 (Preprocessing)
Zero-centering
- 전체 평균을 빼서 데이터 중심을 0으로 맞춤
- 학습 수렴 속도 개선
정규화 (Standardization)
- 표준편차로 나누기 → 분산을 1로 조정 양쪽 축에 대한 분산을 같게 해줌
3. 데이터 증강 (Data Augmentation)
왜 필요한가?
- 데이터 수집 = 돈 + 시간
- 기존 데이터에서 semantics를 유지하며 다양한 형태 생성
주요 기법
- Horizontal Flip (좌우 반전)
- Vertical Flip (상하 반전, 조건부)
- Random Crop → translation invariance
- Scaling → 다양한 사이즈 학습
- Color Jitter → 밝기, 채도, 대비 등 변화
예시
- Train:
→ 짧은 축을 L로 맞춘 뒤
patch 여러 개 추출 - Test (10-crop):
여러 스케일로 resize 후 crop 10개 → 다수결 예측
4. Weight Initialization (가중치 초기화)
Xavier Initialization
학습 초기에 weight가 너무 작거나 크면, forward/backward 시의 값이 발산하거나 소멸(vanishing)될 수 있음.
특히 심층 신경망에서는 층을 거치며 gradient가 점점 작아지는 gradient vanishing 문제가 심각해질 수 있음.
이를 방지하기 위해, 각 층에서 출력의 분산이 입력의 분산과 동일하게 유지되도록 weight의 분산을 조정해야 함.
신경망의 각 층에서 입력과 출력의 분산이 동일하게 유지되도록
weight의 분산을 조정하는 것이 Xavier Initialization의 핵심.
1) 문제 세팅
입력:
가중치:
출력:
의 각 원소는 다음과 같이 계산됨:
2) 출력 분산 계산
출력 의 분산은 다음과 같다:
가정:
- , 는 서로 독립 (independent)
- 모든 와 는 동일한 분포 (i.i.d.)
따라서:
모든 요소가 동일한 분산을 가진다고 하면:
3) 입력과 출력 분산을 같게 만들기
목표:
입력 분산과 출력 분산이 같게 유지되도록 설정
즉,
위의 결과식과 결합하면:
따라서:
4) 초기화 구현
import numpy as np
# 각 층의 차원: [4096, 4096, 4096, 4096, 4096, 4096, 4096]
dims = [4096] * 7
hs = []
# 입력 벡터 (배치 크기 16)
x = np.random.randn(16, dims[0])
# Xavier 초기화 + tanh 활성화 반복
for d_in, d_out in zip(dims[:-1], dims[1:]):
# Xavier Normal Initialization (N(0, 1/d_in))
W = np.random.randn(d_in, d_out) / np.sqrt(d_in)
# 선형 변환 + tanh 활성화
x = np.tanh(x.dot(W))
# 출력 저장
hs.append(x)
5.Learning Rate (학습률)
러닝레이트는 파라미터를 얼마나 크게 업데이트할지를 결정하는 하이퍼파라미터.
너무 크거나 작으면 학습이 제대로 되지 않는다.
Learning Rate가 너무 크면?
- 손실 함수가 급격히 튀고 발산함
- 최적점 근처에서 overshooting 발생
- 모델이 수렴하지 않음
Learning Rate가 너무 작으면?
- 학습 속도 매우 느림
- local minima에 갇힐 수 있음
- 수렴까지 시간이 오래 걸림
적절한 Learning Rate 의 필요성
러닝레이트는 보통 크게 시작해서 점점 줄이는 전략을 사용한다.
이를 learning rate decay 또는 schedule이라고 한다.
Learning Rate Decay 전략
1) Step Decay
- 일정 epoch마다 learning rate를 일정 비율로 감소
- 예: 매 30 epoch마다 절반으로 감소
2) Exponential Decay
- 지수 함수처럼 점점 더 작게 감소
- : decay rate (보통 작은 값)
3) Linear Decay
- 학습이 끝날수록 선형적으로 감소
- : 총 학습 step 수
4) Inverse Square Root Decay
- 초반에는 학습률이 빠르게 줄고, 후반에는 완만하게 감소
- Transformer 류 모델에서 자주 사용됨
5) Cosine Annealing (코사인 감소)
- learning rate가 코사인 곡선 형태로 서서히 감소
- 주기적으로 다시 증가시키면 SGDR (Cosine with Restarts)
- : 현재 epoch
- : 전체 주기(epoch)
Warm-up 전략
초기 학습률이 너무 크면 불안정한 학습이 발생할 수 있음.
따라서 처음엔 아주 작은 learning rate로 시작해서 점차 증가시키는 warm-up 기법을 사용.
