
Open-Domain QA(ODQA) 분야에 한 획을 그었던 REALM 논문을 리뷰했다. RAG 모델링을 요즘에 찾아보면서 Financial AI 프로젝트를 진행하고 있다보니, REALM 논문을 자연스럽게 찾아보게 되었다.
0. Abstract
Language model pre-training은 QA와 같은 NLP task에 많은 양의 world knowledge를 포착하는 것으로 나타났다.
❗ 그러나 이 knowledge는 neural network의 parameter에 암시적으로(implicitly) 저장되므로 더 큰 network가 더 많은 fact를 cover 해야한다.
보다 모듈적이고 해석 가능한 방식으로 knowledge를 capture하기위해 latent knowledge retriever를 사용하여 language model pre-train을 보강한다. 이를 통해 model은 pre-train, fine-tuning 및 inference 중에 사용되는 wikipedia와 같은 large corpus로부터 document를 검색하고 관찰할 수 있게 해준다.
Masked language model을 사용하고 수백만 document를 고려하는 retrieval 단계를 통해 knowledge retriever를 unsupervised 방식으로 pre-train하는 방법을 처음으로 보여준다.
- Open-QA(Open-Domain Question Answering)의 까다로운 task를 fine-tuning하여 RetrievalAugmented Language Model pre-training(REALM)의 효과를 보였다.
- 3가지 인기있는 Open-QA benchmark에서 명시적 및 암시적인 knowledge(explicit and implicit knowledge) 저장을 위한 SotA model과 비교하여 이전의 모든 방법을 상당한 차이(4-16% 정확도)로 능가하는 동시에 interpretability 및 modularity 등의 이득을 제공하는 것을 발견했다.
1. Introduction
✅ LLM model에는 massive text corpora로 학습되어 surprising amount of world knowledge가 저장됨.
- Language model pre-training의 최근 발전에 따르면 BERT, RoBERTa 및 T5 와 같은 model에는 놀라운 world knowledge가 저장되어 있다.
- 이러한 world knowledge는 massive text corpora로 부터 학습에 의해 획득하였다.
- (ex) BERT는 “The ___ is the currency of the United Kingdom” 에서 누락된 단어를 찾을 수 있다. (answer: “pound”).
✅ language model에서 학습된 world knowledge는 neural network의 parameter에 암시적으로(implicitly) 저장됨.
- network에 어떤 knowledge이 저장되어 있고, 어디에 저장되어 있는지 판단하기가 어렵다.
- storage space는 network의 크기에 따라 제한된다.
- 더 많은 world knowledge를 capture하려면 더 큰 network를 학습해야 하므로 속도가 느리거나 고비용이 든다.
❗ 보다 해석가능하고 모듈 방식의 knowledge를 capture하기위해 학습된 textual knowledge retriever를 통해 language model pre-train을 보강하는 새로운 framework인 REALM(Retrieval-Augmented Language Model)을 제안!!
- Parameter에 knowledge를 저장하는 기존 Language model과 달리, inference중에 어떤 knowledge를 검색하고 사용할지 결정하도록 model에 요청하여 world knowledge의 역할을 명시적으로(explictly) 노출한다.
- Prediction을 수행하기 전에 language model은 retriever를 사용하여 wikipedia와 같은 large corpus에서 document를 검색한 다음 해당 문서를 탐색하여 prediction을 알려준다.
- 이 model을 end-to-end로 학습하려면 아래 그림과 같이 전체 textual knowledge를 고려하는 검색 단계를 통해 backpropagation이 필요하다.
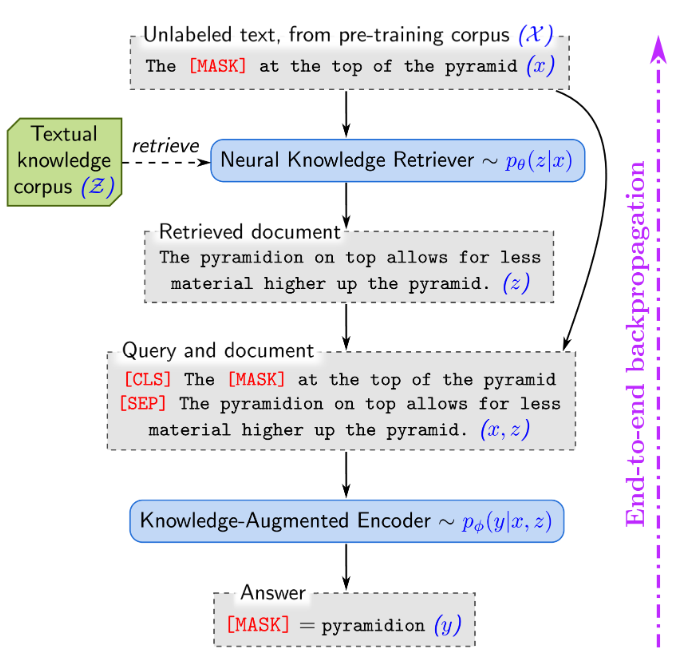
기존 Language model들에서는, task를 수행할 때 knowledge가 필요한 경우, model의 parameter안에 저장된 knowledge를 활용하여 task를 수행하였다. 그러나, REALM은 retriever를 사용하여 large corpus로부터 knowledge를 가져오고, 이를 이용하여 task를 수행한다는 차이점이 있다.
✅ REALM의 key intuition
unsupervised text의 performance-based signal을 사용하여 retriever를 학습시키는 것
💡 Language model의 perplexity를 개선하는 검색은 도움이 되고 보상되어야 하며 정보가 없는 검색은 penalty를 받는다.
예를 들어 위의 그림에서 model이 “the ___ at the top of the pyramid”의 빈칸을 채워야하는 경우, retriever는 “The pyramidion on top allows for less material higher up the pyramid.”라는 document를 선택하면 보상을 받는다. 예측 가능한 검색 방법을 latent variable language model로 모델링하고 marginal likelihood를 최적화하여 학습한다.
🤔여러 document들 중에서 task에 알맞은 document라는 것을 어떻게 알 수 있을까?
: MIPS(Maximum Inner Product Search) 알고리즘을 이용한다.
간단하게 말하자면, document z와 input x의 embedding vector 간의 inner product(내적) 값을 계산하여, 이를 이용한다는 것이다.
( Pre-train동안 large-scale neural retrieval module을 통합하는것은 retriever가 각 pre-train step마다 수백만개의 후보 문서를 고려해야하고, 그 결정을 통해 backpropagate해야하기 때문에 계산상의 문제가 된다.)
2. Background
Language model pre-training
Language model pre-training의 목표는 일반적으로 unlabeled text corpora에서 유용한 language representation을 배우는 것이다. 결과적으로 pre-trained model은 primary interest(in our case, OpenQA)의 downstream task에 대해 추가로 학습(미세조정)될 수 있으며 종종 처음부터 학습보다 더 나은 일반화를 유도한다. ▶️ Pre-trained 모델이 여러 downstrem task에 대해서 꽤 괜찮은 성능을 보인다.
기본 형식으로 masked language model(MLM) 은 input text에서 누락된 token을 예측하도록 학습한다. ▶️ 대중화된 MLM 변형에 중점을 둔다.
Open-domain question answering (Open-QA)
World knowledge를 통합하는 model의 성능을 측정하려면 world knowledge에 중요한 downstream task가 필요 ▶️ NLP에서 가장 knowledge-intensive인 task중 하나는 Open-QA이다.
Open-QA의 “open”은 model이 SQuAD와 같은 기존의 독해 이해(RC:Reading Comprehension)task와 달리 답변을 포함하는 context를 받지 않는다는 것이다. RC model은 single document를 이해하지만 Open-QA model은 수백만 개의 document에 대한 지식을 유지해야 한다.
본 논문에서는 textual knowledge corpus Z를 knowledge source로 사용하는 Open-QA system에 중점을 둔다. 이러한 system중 다수는 retrieval-based approach을 사용한다.
질문 x가 주어지면,
-> corpus Z에서 관련 document z를 검색
-> document에서 정답을 추출
💡 REALM은 이 패러다임에서 영감을 얻어 이를 language model pre-train으로 확장!
💡 최근 연구에서는 x에 seq2seq model을 사용하여 token-by-token으로 y를 generation하는 generation-based systems을 제안
💡 두 패러다임(retrieval-based approach, generation-based systems)의 SotA system과 비교할것이다.
3. Approach
<REALM의 pre-training 및 fine-tuning task approach>
3.1 - retrieve-then-predict generative process로 공식화
3.2 - 해당 process의 각 component에 대한 model architecture에 대해 설명
3.3 - REALM의 generative process의 likelihood를 maximizing하여 REALM pre-training 및 fine-tuning을 구현하는 방법을 설명, 도중 중요한 computational challenge를 해결하고 학습이 작동하는 이유를 설명하고, inductive biases를 주입하기 위한 전략을 논의
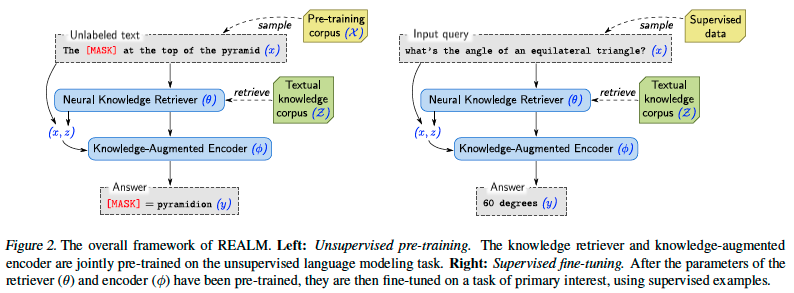
아래 그림은 REALM 전체 framework이다.
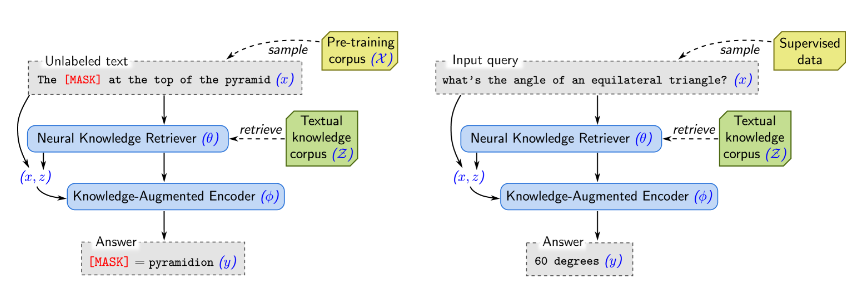
3.1. REALM’s generative process
Pre-train 및 Fine-tune에 대해 REALM은 일부 inputx를 사용하여 가능한 output y에 대한 distribution p(y∣x)를 학습한다.
▶️ 특정 sequence가 input으로 주어졌을 때, model의 vocab에 대한 분포를 학습한다는 것
🔻 Pre-train의 경우 (왼쪽 사진)
task : masked language modeling
x : 일부 token이 masking된 pre-training corpus X의 문장
model : 누락된 token의 value y를 예측하는 모델
🔻Fine-tuning의 경우
task : Open-QA
x : 질문
y : 답변
REALM은 p(y∣x)를 검색, 예측 두 단계로 분해한다.
- Input x가 주어지면 먼저 knowledge corpus Z에서 유용한 document z를 검색
- 유용햔 document z에대해서 distribution p(z∣x)의 sample로 modeling
- 이후 검색된 z와 original input x를 모두 condition으로 하여 p(y∣z,x)로 modeling된 output y를 생성
( y를 생성할 수 있는 overall likelihood를 얻기 위해 z를 latent variable로 취급하고 가능한 모든 document z에 대해 marginalize 하고자 아래의 수식 사용 )
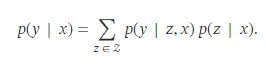
3.2. Model architecture
위의 REALM의 핵심 수식 속 두 가지 주요 component인 p(z∣x)를 modeling하는 neural knowledge retriever과 p(y∣z,x)를 modeling하는 knowledge-augmented encoder를 설명한다.
💡Knowledge Retriever
Retriever는 dense inner product model을 사용하여 다음과 같이 정의됨
▶️ 아래과 같은 방법을 통해 input(x)와 document(z)간의 확률을 구해서 유용한 document z를 검색
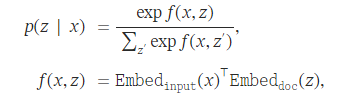
: x를 d 차원 vector에 mapping하는 embedding 함수
: z를 d 차원 vector에 mapping하는 embedding 함수
x와 z사이의 relevance socre f(x,z)는 vector embedding의 inner product로 정의된다. retrieval distribution p(z|x) 은 모든 relevance score에 대한 softmax 이다.
Wordpiece tokenization(Google이 BERT를 사전 학습하기 위해 개발한 토큰화 알고리즘)을 적용, [CLS] token을 접두어로 붙이고, [SEP] token으로 segment 분리 및 input 마지막에 추가한다.
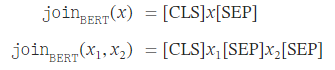
이러한 embedding vector는 BERT를 활용하여, BERT에 해당 input x와 document z를 BERT input representation의 형태로 변형한 뒤, BERT에 input으로 넣고 [CLS] token 위치의 output을 matrix W를 통해 linear transform 한 결과이다.

이렇게 구해진 embedding matrix들끼리의 relevance score, 즉 inner product 결괏값을 구하는 f(x,z)를 진행한 뒤, 모든 document z에 대해 softmax를 취해주어 p(z|x)를 구해주게 된다.
추가적으로, 논문에서는 여기에 사용된 projection maxtrix W 들과 BERT의 parameter들에 대해, retriever parameter θ 라고 명시한다.
💡Knowledge-Augmented Encoder
knowledge-augmented encoder는 input x와 document z가 주어졌을 때 output y에 관한 확률인 p(y|z,x)를 modeling 한다. 즉, x와 z를 input으로 받아 y를 산출해 내는 아키텍처이다.
다만,아래 그림을 보면 Knowledge-Augmented Encoder의 Pre-training시와 Fine-tuning시의 작동 방식은 살짝 다르다.
✔️ Pre-training의 경우 (왼쪽 사진)
pre-training시에는 MLM task를 수행하기 때문에, [MASK] token 위치의 원래 token을 예측하게 된다. 이 과정을 나타내는 수식은 아래와 같다.
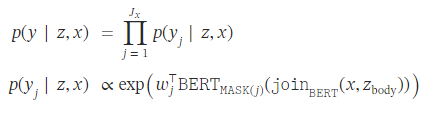
0) setting
- : [MASK] token으로 치환된 j번째 token의 위치에 해당하는 BERT output
- : input x 안에 존재하는 [MASK] token의 전체 개수
1)
input x와 document z의 본문 부분인 를 BERT의 input representation 형식으로 변환한다. 즉, [CLS] x [SEP] $z_ {body}$ [SEP] 형식으로 변환된다.
2) ⊺join_{BERT}
이후 변환한 input representation을 BERT에 input으로 집어넣어, [MASK] token으로 치환된 j번째 token의 위치에 해당하는 output을 추출한다. 이 output을 vocab size로 linear transform해주는 matrix ⊺를 행렬곱을 취해주게 되면, input x와 document z가 주어졌을 때 해당 [MASK] token에 대한 확률을 구할 수 있게 된다.
3) p(y|z,x) 최종 계산
이 과정을, 하나의 input sequence x 안에 존재하는 모든 [MASK] token에 대해 수행하고, 각각의 token에 대한 확률을 곱해주게 된다.
✔️ Fine-tuning의 경우 (오른쪽 사진)
Fine-tuning시에는 Open-QA task를 수행한다. 이때, input은 question이고, output y는 question에 대한 answer이다.
❗ 이때 answer y는 document z 안에 연속된 token으로 구성된 sequence로 포함되어 있다고 가정❗
REALM은 BERT 기반의 model이기에, generation task를 수행하지 않기 때문에 특정 corpus안에서 알맞은 부분만 추출하는 방식으로 Open-QA task를 수행하게 된다. generation task로 이러한 과정을 수행하는 model은 이후 연구에서 등장하게 된다.
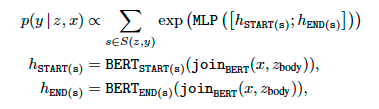
➕ knowledge-augmented encoder의 parameter들은 ϕ로 명시
➕ Knowledge retriever의 parameter는 θ라고 명시
3.3. Training
Implementing asynchronous MIPS refreshes
Pre-training과 fine-tuning은 공통적으로 올바른 output인 y의 log-likelihood인 를 maximize 하는 것을 목적으로 학습된다. 학습 과정 속에서, knowledge retriever와 knowledge augmented encoder는 diffentiable 한(훈련 가능한) neural network로 구성되었기 때문에, 에 대한 gradient를 계산하여 update를 할 수 있다.
❗ 수식 상 전체 document에 대한 모든 확률을 더하게 되는데, 이는 너무 많은 계산량을 요구하는 문제가 발생
🤔 전체 document에 대한 p(y|x) 구하는 데 계산량을 어떻게 줄일 수 있을까?
: MIPS(Maximum Inner Product Search) 알고리즘을 사용
(input x와 document z의 relavance score로 inner product, 내적 연산값을 사용)
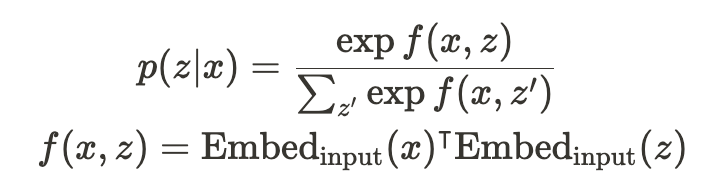
Relavance score로 inner product를 사용하기에, MIPS 알고리즘 적용이 가능해지며 이는 top-k document를 찾을 때, document 수가 늘어날 때마다 요구되는 running time과 storage space가 sub-linearly(선형 시간 이하, eg.O(logn))한, 매우 효과적인 결과를 도출할 수 있다.
❗ MIPS를 적용하기 위해, REALM model은 모든 document z에 대해 를 미리 계산해야 한다. 그러나, 이러한 는 model의 학습이 진행되면서 계속 바뀌게 된다....
🤔 값이 계속 업데이트 되는데, 어떻게 MIPS게산에 사용되나?
: 몇백 training step마다 비동기적으로 document에 대해 re-embedding과 re-indexing을 진행하는 방법을 사용한다.
이 방법 또한 update가 진행되지 않는 training step들에서 살짝 모순이 있기는 하지만, 저자들은 실험을 통해 해당 방법론이 충분히 좋은 성능을 냈다고 말한다. (또한, top-k를 가져오는 것이기에, 발생하는 약간의 모순이 상쇄된다고도 말한다.)
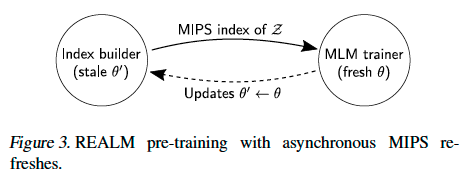
이러한 asynchronous refreshing은 pre-training과 fine-tuning 모두에 적용가능하지만, 논문에서는 pre-training에만 적용하고, fine-tuning시에는 MIPS index를 pre-train 된 parameter θ로 한 번만 구축한 뒤, refresh를 하지 않았다고 한다.
▶️ fine-tuning이 진행되는 과정 동안 을 update 하지 않는다는 것이다.
그러나, 에 대해서는 계속 update 되기 때문에, retrieval function은 input x에 대해서는 계속해서 update가 된다고 말한다.
What does the retriever learn?
knowledge retrieval of REALM은 잠재적(latent)하기에, training objective가 어떻게 의미있는 검색을 돕는지 분명하지 않다. 여기에서는 prediction accuracy를 향상시키는 retrieval에 대한 reward 방법을 보여준다.
주어진 query x 및 document z에 대해 f(x,z)는 knowledge retriver가 document z에 할당하는 “relevance score”임을 상기한다. REALM pre-train 동안 knowledge retriever의 parameter θ에 대한 gradient를 분석하여 gradient descent 한 단계가 점수를 어떻게 변화시키는지 알 수 있다.
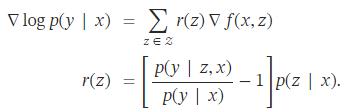
각 문서 z에 대해 gradient는 retriever가 score f(x,z)를 r(z) 만큼 변경하도록 한다. r(z)가 양수이면 증가하고 음수이면 감소. r(z)는 p(y∣z,x)>p(y∣x) 인 경우에만 양수이다. p(y∣x)는 p(z∣x)에서 document를 random sampling할 때 p(y∣z,x)의 기대값이다. 따라서 document z는 기대보다 성능이 좋을 때마다 positive하게 update를 받는다.
3.4. Injecting inductive biases into pre-training
논문에서는 REALM을 훈련시킬 때, retrieval이 보다 의미 있는 방향으로 학습되기 위해 아래와 같은 추가적인 기법을 활용했다고 한다. 다음 4가지가 그 추가적인 기법이다.
Salient span masking
REALM의 pre-training은 MLM task를 수행한다. 그런데, MLM task를 수행할 때 masking이 random 한 token에 대해 적용되기 때문에, REALM의 목적이 맞지 않는 masking이 진행될 수 있다.
REALM은 knowledge가 필요한 task, 즉 knowledge-intensive task를 잘 수행하기 위해 만들어지는 model이기 때문에, 논문에서는 이러한 목적을 잘 수행하기 위해 masking도 knowledge가 필요한 token 위주로 진행하는 salient masking을 수행한다고 한다.
ex) 5월 5일은 어린이날이다.
라는 문장에서 MASK를 적용하는 token은 5월 5일 과 어린이날이다.
Null document
retriever가 가져오게 되는 top-k document에 null document를 추가하는 기법이다. 이는 masking 된 token을 predict 할 때, knowledge가 필요 없는 경우에는 이러한 null document를 retrieve 하게끔 하여 model의 retriever로 하여금 알맞은 document를 가져오게끔 하는 기법
Prohibiting trivial retrievals
pre-training corpus와 knowledge corpus가 같은 경우를 방지하는 기법이다. 만약 masking 된 input x가 document z에 있는 문장과 같은 문장이면, model은 x와 z의 관계를 학습하는 것이 아닌, 순전히 문자열이 matching 되는지 확인하는 방향으로 학습될 가능성이 있다. 따라서, 저자들은 pre-training 과정에서 이러한 경우들을 제외시켰다고 한다.
Initialization
원활한 학습을 위해, 기존 ORQA의 parameter를 knowledge-retriever의 초깃값으로 설정하였고, knowledge-augmented encoder의 parameter의 초깃값은 uncased BERT-BASE model의 parameter로 설정하고 학습을 진행하였다고 한다.
4. Experiments
소개한 REALM을 가지고 Open-QA task에 대해 성능 확인을 해보았다.
4.1. Open-QA Benchmarks
NaturalQuestions-Open, WebQuestions, CuratedTrec Dataset을 가지고 Open-QA task에 사용하였다.
4.2. Approaches compared
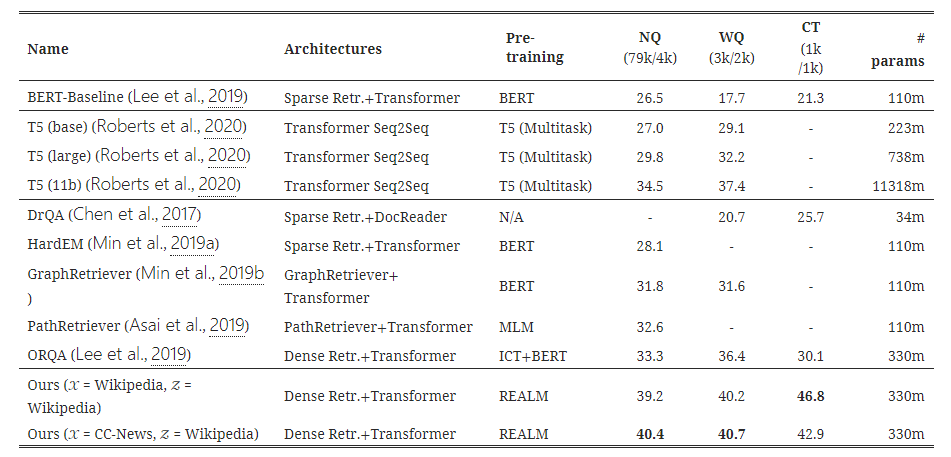
Ours라고 표에 명시된 모델이 REALM 모델의 결과인데 가장 우수하다.
Retrieval-based Open-QA
대부분의 Open-QA system은 먼저 knowledge corpus에서 관련있는 document를 검색한 다음 MRC system을 사용하여 document에서 답변을 추출한다. 이 패러다임에서 knowledge는 corpus에 명시적으로 저장된다. Retrieval을 구현하기 위한 여러가지 방법을 비교.
많은 접근법은 sparse bag-of-words matching와 같은 학습되지 않은 휴리스틱 검색을 사용하거나 관련 document의 small set을 선택하기 위해 질문에 entity linking를 사용한다. 이러한 문제는 일반적으로 학습된 model을 사용하여 rerank되지만 초기 휴리스틱 검색 단계에 따라 적용 범위가 제한될 수 있다. 표1의 DrQA, HardEM, GraphRetriever, PathRetriever가 위와 같은 접근법이다.
최근 일부 접근법은 MIPS index를 사용하여 학습 가능한 검색을 구현하도록 제안되었다. ORQA는 REALM과 유사한 latent variable model을 사용하여 Open-QA를 공식화하고 marginal likelihood를 maximizing하여 학습한다. 그러나 REALM은 새로운 language model pre-training 단계를 추가하고 고정 index를 사용하지 않고 MIPS index를 backpropagation한다. REALM pre-training 및 ORQA의 retriever는 3.4절에 설명된 ICT를 사용하여 초기화된다.
Generation-based Open-QA
Open-QA에 대한 새로운 대안은 질문을 sequence prediction task로 modeling 하는것이다. 질문을 간단히 encoding한 다음 이를 기반으로 token별로 답변을 decoding 한다. GPT-2는 model에 대량의 knowledge를 주입할 수 있는 방법이 처음에는 불분명 했지만 sequence-to-sequence를 통해 주어진 context를 사용하지 않고 직접 답변을 생성하는것에 대한 가능성을 암시했다. 그러나 fine-tuning이 없기 때문에 성능면에서 경쟁력이 없었다. T5는 주어진 context에서 명시적으로 추출하지 않고 직접 답변을 생성하는 것이 실행 가능한 접근법이지만, context document가 제공되는 MRC에서만 실험을 하였다.
가장 경쟁력 있고 비교 가능한 baseline을 위해 T5를 fine-tuning하는 연구와 비교한다
4.3. Implementation Details
Fine-tuning
Lee et al.(2019)논문에서와 같은 hyper-parameter를 재사용 했다. Knowledge corpus는 2018년 12월20일 영어 wikipedia를 사용. Document는 greedy하게 288개의 BERT wordpiece로 나누어져 1300만 건이 넘는 retrieval 후보가 된다. Fine-tuning 중 상위 5개 후보를 고려하고 12GB GPU가 있는 single machine에서 model을 실행할 수 있다.
Pre-training
BERT의 default optimizer를 사용하여 batch size가 512이고 learning rate를 3e-5로 설정하여 64개의 Google Cloud TPU에서 200k step을 pre-train. MIPS index의 document embedding step은 16개의 TPU에서 병렬화 된다. 각 예에서 null document ∅를 포함하여 8개가 넘는 후보 document를 검색하고 marginalize한다.
4.4. Main results
아래의 표가 그 결과이다.
REALM이 모든 task에 대해 SOTA를 달성한 것을 확인할 수 있다. 특히, T5와 비교했을 때 parameter 수에서 큰 차이를 보이는데도 불구하고 REALM의 성능이 더 우수한 것을 확인할 수 있다.
결과 표를 보면 T5기반의 generative Open-QA system은 강력하며 T5-11B model이 previous SotA보다 성능이 뛰어나다. T5의 크기를 늘리면 일관된 개선이 이루어 지지만 계산 비용이 많이 든다. 반대로 REALM은 최대 T5-11B model보다 성능이 뛰어나면서도 30배 더 작다. T5는 pre-train동안 SQuAD의 추가 MRC dataset에 접근한다는 점을 유의해야 한다. 이러한 data에 접근하면 REALM에 도움이 될 수 있지만 실험에서는 사용하지 않았다.
REALM과 가장 직접적인 비교는 ORQA이며 fine-tuning setup, hyperparameters, training data는 동일하다. ORQA에 비해 REALM의 개선은 순전히 더 나은 pre-train 방법 때문이다.
4.5. Analysis
아래 표는 REALM의 중요한 component를 제거한 후 NaturalQuestions-Open에 대한 결과이다. End-to-end 결과 외에도 fine-tuning을 적용하기 전에 상위 5개의 검색에서 gold answer가 얼마나 자주 나타나는지 보고 한다. 후자의 측정지표는 pre-training동안 검색 개선의 기여를 더 크게 분리한다.
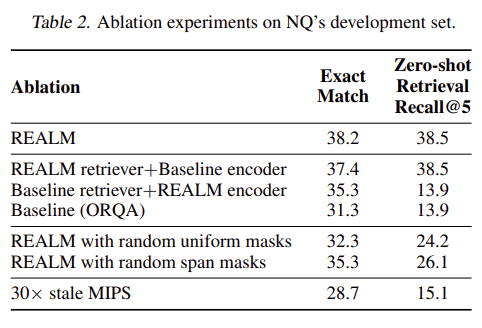
Encoder or Retriever
먼저 REALM pre-training이 retriever 또는 encoder 또는 둘 다를 향상시키는지 여부를 결정한다. 이를 위해 REALM pre-training 전에 retriever 또는 encoder의 parameter를 baseline 상태로 재설정하고 fine-tuning중에 feed 할수 있다. Encoder와 retiriever는 모두 REALM 학습의 이점을 개별적으로 얻을 수 있지만 최상의 결과를 위해서는 두 component가 동시에 작동해야 한다.
Masking scheme
Masking scheme (1) random token masking introduced in BERT (Devlin et al., 2018) and (2) random span masking proposed by SpanBERT (Joshi et al., 2019) 두가지를 비교한다. 이러한 span masking은 표준 BERT 교육 (Joshi et al., 2019)을 사용한 이전 연구에서 영향을 미치지 않는 것으로 나타 났지만 REALM에서는 중요하다. 직관적으로, latent variable learning은 검색의 유용성에 크게 의존하므로 일관된 학습 신호(consistent learning signal)에 더 민감하다.
MIPS index refresh rate
Pre-train 과정에서 parallel process를 실행하여 corpus document를 다시 embedding 하고 MIPS index를 다시 작성한다. 결과적으로 약 500 training step마다 refresh를 수행한다. 빈번한 index refresh의 중요성을 보여주기 위해 느린 refresh 빈도를 사용하는 것과 비교한다. 표2의 결과는 stale index가 model 학습에 부정적인 영향을 줄 수 있으며 이를 줄이면 더 나은 최적화를 제공할 수 있음을 나타낸다.
Examples of retrieved documents

위의 표는 REALM masked language model의 예측 예시를 보여준다. 예시에서 “Fermat”은 올바른 단어이며 REALM(행c)은 단어를 BERT model(행a)에 비해 훨씬 높은 확률로 제공한다. REALM은 관련 사실(행b)이 있는 일부 document를 검색할 수 있기 때문에 정답의 marginalized probability가 크게 증가한다. 이것은 unsupervised text로만 학습된 경우에도 REALM이 mask된 단어를 채우기 위해 document 검색을 할 수 있음을 나타낸다.
6. Future Work
🤔 구조화된 지식으로부터 어떤 정보가 유용한지에 대한 의사결정을 배우는것
🤔 multilingual setting. 많은 양을 가진 언어로 지식을 검색하여 적은 양의 언어를 더 잘 표현하는것
🤔 multi-model setting. text에서 거의 관찰되지 않는 지식을 제공할 수 있는 영상이나 비디오 검색
🔖 Reference
참고한 리뷰 포스팅1
참고한 리뷰 포스팅2
