LoFT-LLM: Low-Frequency Time-Series Forecasting with Large Language Models
Jiacheng You, Jingcheng Yang, Yuhang Xie, Zhongxuan Wu, Xiucheng Li, Feng Li, Pengjie Wang, Jian Xu, Bo Zheng, Xinyang Chen
arXiv 2512.20002 (v1 2025-12, v3 2026-01) · KDD '26 accept · Harbin Institute of Technology (Shenzhen) + 알리바바 계열
Code: github.com/yjcGitHub0/LoFT-LLM (공개 진행 중)
한 줄 요약
LoFT-LLM은 시계열 예측을 셋으로 쪼갠다. PLFM이 DFT 기반으로 저주파 트렌드를 뽑고, iTransformer residual learner가 고주파 변동을 맡고, 마지막으로 Qwen3-8B (QLoRA fine-tuning) 가 이 두 수치 예측과 도메인 보조 변수를 자연어 prompt로 받아 refinement를 한다. 알리바바 Tianchi의 펀드 입출금(FundAR) + GEFCom 2014 태양광(Solar) 두 데이터셋에서 풀 데이터 MAE 기준 15~27% 개선, few-shot(10% 데이터) 에선 TimeLLM 대비 59% 개선을 보고한다.
왜 이 논문이 흥미로운가
LLM을 시계열에 붙이는 연구는 지난 3년 동안 "LLM에게 얼마나 깊이 예측을 맡길 것인가" 라는 스펙트럼 위에 줄 서 왔다. 한쪽 끝에는 LLM 전체를 수치 예측기로 fine-tuning하는 접근(Time-LLM, GPT4TS), 반대쪽 끝에는 Are Language Models Actually Useful for Time Series Forecasting? (arXiv 2406.16964)의 회의론이 있다.
이 블로그에서 앞서 리뷰한 두 편은 이 스펙트럼의 서로 다른 지점을 찍었다.
- Rethinking the Role of LLMs in TS Forecasting — 회의론을 80억 관측치 규모로 재평가해서 "LLM4TS는 distribution shifting이 큰 상황에서 실제로 도움이 된다"는 조건부 긍정론을 제시.
- One-for-All (rsLoRA) — LLM 본체를 거의 얼리고 rank-16 rsLoRA 어댑터만 꽂아 11배 큰 GPT4TS와 동률 MSE를 낸 경량화 증명.
LoFT-LLM은 이 둘과 또 다른 위치에 있다. LLM에게서 수치 예측을 통째로 걷어내는 쪽이다. 실수치 예측(low-freq · residual)은 전통적 구성요소(MLP + iTransformer)가 담당하고, LLM은 그 예측과 도메인 맥락(펀드 페이지뷰·CD 금리·기상 데이터)을 자연어로 받아 calibration만 한다. 말하자면 LLM을 수치 예측기가 아니라 semantic refiner로 쓰는 설계다.
한 줄로 줄이면: "시계열이 잘하는 건 시계열 모델에, 자연어 맥락 해석은 LLM에."
회의론 입장에서 보면 이 설계는 중요한 양보를 한 셈이다 — "LLM은 수치 예측 자체엔 기여가 크지 않다"를 받아들이고, LLM의 역할을 맥락 이해로 제한한다. LoFT-LLM은 "LLM4TS가 쓸 만한가"라는 오래된 질문에 "어디에 쓰면 쓸 만한가" 로 답을 바꾼 케이스다.
배경 — 왜 주파수 분해인가
실무의 금융·에너지 데이터는 두 가지 공통 난점을 갖는다.
- 노이즈가 크다 — 일별 펀드 입출금이나 시간별 태양광 발전량은 거시 트렌드 위에 단기 변동이 크게 얹혀 있다. 전체 window를 그대로 지도학습에 쓰면 고주파 노이즈가 loss에 섞여 장기 추세가 가려진다.
- 훈련 데이터가 적다 — cold start(신상품 펀드), 규제·privacy, 시장 체제 전환. 장기 히스토리가 드물고 few-shot 시나리오가 빈번하다.
저자들은 이 두 문제를 주파수 분해로 분리한다. 저주파는 안정적 트렌드 — 데이터가 적어도 학습 가능. 고주파는 변동·이상치 — 전용 모델이 별도로 처리. 거기에 도메인 맥락(보조 변수) 을 LLM이 자연어로 받아 마지막 조정을 한다.
접근 방식 / 제안 방법
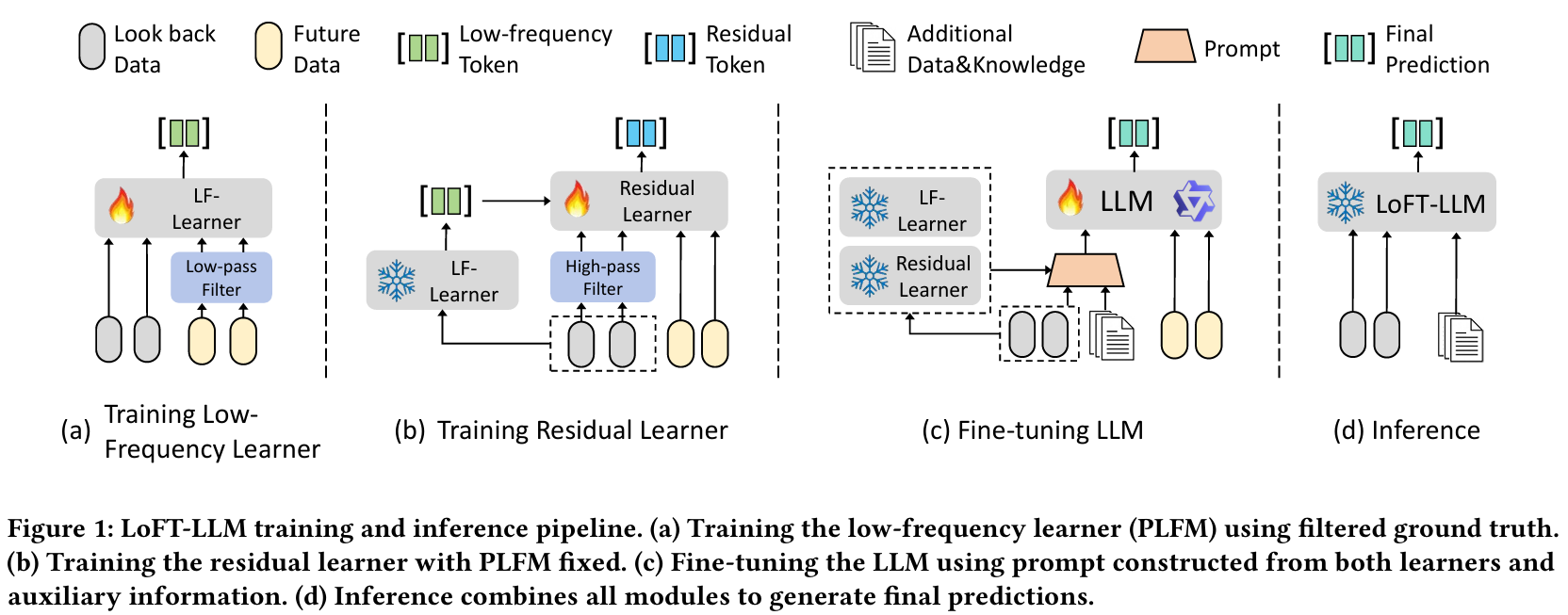
3단 파이프라인
핵심은 앞단 두 모델이 실수치 예측을 제공한 뒤 LLM이 그것을 자연어 prompt로 받아 재조립한다는 점이다. LLM은 raw 시계열을 직접 보지 않는다.
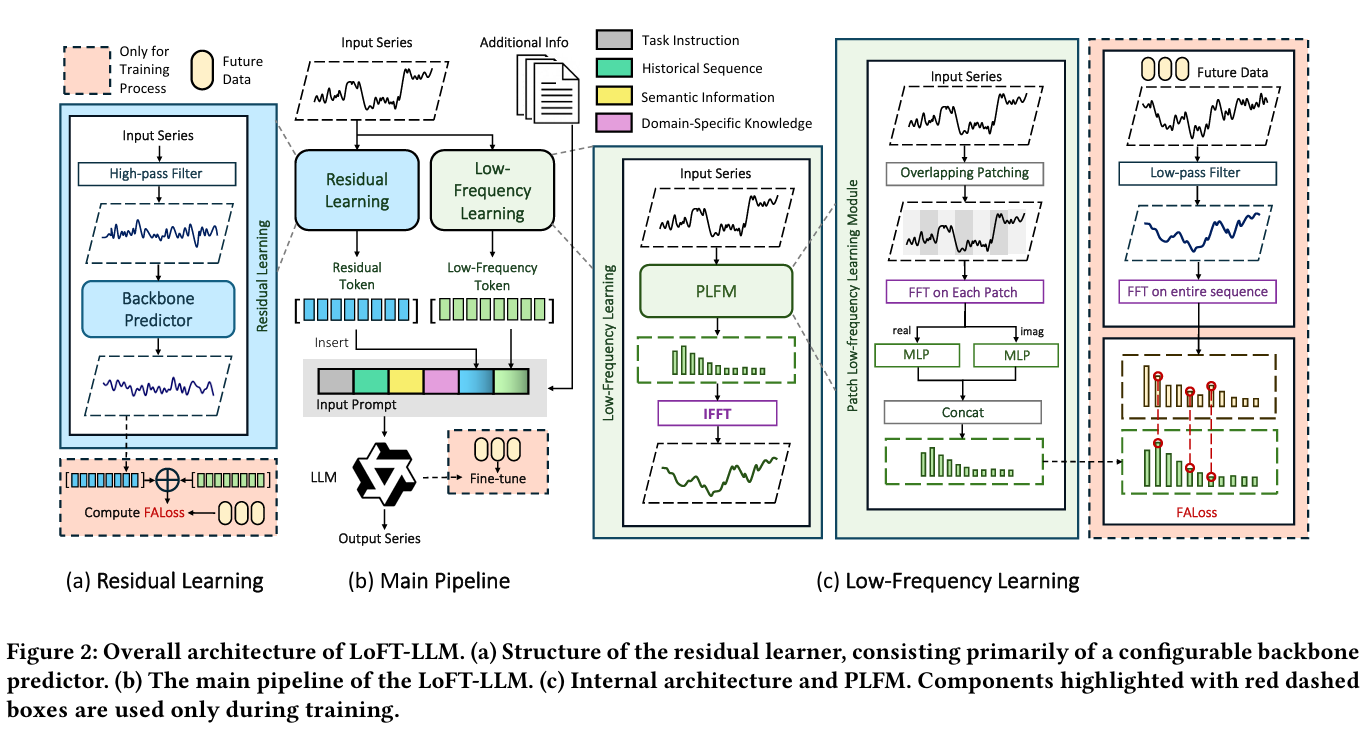
PLFM — Patch Low-Frequency forecasting Module
PLFM이 이 논문의 "진짜 새로운 부분"이다.
학습 target 재정의: 원본 를 직접 맞추지 않는다. 먼저 low-pass filter를 적용한 뒤 FFT를 태워서 저주파 성분의 Fourier coefficient를 target으로 삼는다.
입력 패치화: 입력 에 길이 ·stride ()로 overlapping patches를 만들어 개의 패치를 얻고 각 패치에 DFT 적용.
모델: 각 패치의 spectrum을 real/imaginary 둘로 나눠 쌍둥이 2-layer MLP( 분리)로 처리한 뒤 다시 합쳐 예측 spectrum을 낸다 (Eq 5). IFFT로 시간 영역 복원.
FALoss: 예측과 target을 주파수 계수 영역에서 L1으로 잰다 (Eq 2).
저자들은 Theorem 2로 FALoss가 MAE의 상한을 제공한다는 것을 Parseval-Plancherel identity 기반으로 보여, 주파수 영역에서 직접 맞추는 게 시간 영역 성능과 합리적으로 연결된다는 근거를 붙인다. 이게 이 논문의 "이론 포장" 파트.
Residual learner
저주파를 뺀 나머지(high-pass filtered input HPF())를 iTransformer (Liu et al., 2023)로 처리해 를 낸다. 아키텍처 자체는 기존 것 재사용이고, 여기서도 FALoss로 학습.
두 예측을 단순 합으로 결합: .
LLM refinement
여기가 또 다른 핵심. 위의 와 보조 변수 를 structured natural-language prompt로 엮어 LLM에 넣는다.
보조 변수의 실체:
- FundAR: 펀드 페이지 조회수(UV), 은행 CD 금리
- Solar: 운량·풍속·습도
LLM은 이 prompt를 받아 숫자 리스트 형태로 최종 예측을 토해낸다 (예: [2.481, 1.783]).
백본: Qwen3-8B + QLoRA. 구체적 LoRA rank·target module은 논문에 공개되지 않았다. 80억 파라미터는 결코 작지 않다 — 006 rsLoRA의 0.55M과 비교하면 4자리수 차이인데, 두 논문이 목표로 하는 지점이 다르다는 걸 시사한다. 006은 "LLM4TS를 얼마나 작게", LoFT-LLM은 "LLM의 언어 능력을 시계열 맥락에 얼마나 잘 붙이냐".
실험 설계
| 항목 | 내용 |
|---|---|
| 데이터셋 | FundAR (금융, daily, 2021-01-04 ~ 2022-11-09, 675 pts) / Solar (에너지, hourly, 2012-04 ~ 2013-04, 8,760 pts) |
| Target | 펀드 입출금 / 태양광 발전량 |
| 보조 변수 | FundAR: 페이지뷰·CD금리 · Solar: 운량·풍속·습도 |
| Split | 70% / 10% / 20% (time-ordered) |
| Lookback / Horizon | FundAR 30→1 · Solar 72→1 |
| LLM 백본 | Qwen3-8B (QLoRA) |
| 베이스라인 (14종) | Transformer, DLinear, PatchTST, FITS, FreTS, TimesNet, iTransformer, TimeXer, FreDF, TimeKAN, GPT4TS, TimeLLM 등 |
| Metric | MAE, RMSE, MAPE |
| Few-shot | FundAR 10% (~60 steps) · Solar 직전 7일 (168 steps) |
몇 가지 짚어둘 포인트.
- 데이터셋이 단 2개다. 17개 데이터셋으로 매크로하게 돌린 Rethinking(003)이나 6개 태스크로 뻗어나간 One-for-All(006)과 달리, LoFT-LLM은 "자기 메시지에 딱 맞는 두 데이터셋"에 집중한다. 저자들의 모티브(노이즈 + 적은 데이터 + 보조 변수 풍부)에는 잘 맞지만, 일반화 주장의 범위는 좁다.
- FundAR은 675 시점의 작은 데이터셋이다. 일반 TS 벤치마크(ETT 수만 시점)와 규모 자체가 다르다.
- 베이스라인에 Chronos·Moirai·Kronos 같은 2024~2026 TS foundation 모델이 빠져 있다. GPT4TS·TimeLLM은 포함.
주요 결과
1. 풀 데이터 — 두 도메인 모두에서 이김
FundAR (horizon 1, daily):
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| LoFT-LLM | 0.661 | 1.758 | 0.433 |
| FreDF (best baseline) | 0.982 | 2.443 | 0.609 |
MAE 기준 26.5% 개선. 금융 데이터에서 가장 강한 비-LLM 베이스라인을 상당한 차이로 앞선다.
Solar (horizon 1, hourly):
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| LoFT-LLM | 0.030 | 0.066 | 0.292 |
| FreTS (best baseline) | 0.034 | 0.067 | 0.524 |
MAE 15.4% 개선, MAPE는 거의 반으로 줄었다. 다만 RMSE는 FreTS와 거의 같다(0.066 vs 0.067). 즉 큰 오차 페널티 기준에서는 개선이 작고, 평균적·상대적 오차 기준에서 벌린 점수다.
2. Few-shot — 여기가 하이라이트
FundAR 10% (약 60 steps):
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| LoFT-LLM | 0.661 | 1.713 | 0.436 |
| TimeLLM (best baseline) | 1.622 | 3.203 | 0.796 |
MAE 59% 개선. 그리고 더 인상적인 건 풀 데이터 LoFT-LLM과 few-shot LoFT-LLM의 MAE가 거의 동일하다는 점이다(0.661 vs 0.661). 데이터를 10분의 1로 줄여도 성능이 거의 안 떨어진다는 얘기다.
단, 이 숫자에는 해석 주의가 필요하다. 격차가 커 보이는 이유 중 상당 부분은 baseline들이 10% 데이터에서 크게 무너지기 때문이기도 하다. "LoFT-LLM이 few-shot에서 특별히 잘한다"보다 "baseline 계열이 데이터 희소에 약하고 LoFT-LLM은 PLFM+LLM 쪽에 내재된 prior 덕에 덜 무너진다"가 더 정확한 기술일 것이다.
3. Ablation — 어느 구성요소가 어느 도메인에서 일하는가
논문 Table 5:
| 설정 | FundAR MAE | Solar MAE |
|---|---|---|
| Baseline (no FL, no LLM) | 1.859 | 0.066 |
| + Frequency Learning (FL only) | 0.899 | 0.034 |
| + LLM only | 0.692 | 0.043 |
| + FL + LLM (full) | 0.661 | 0.030 |
여기서 재밌는 대칭이 나타난다.
- 금융 데이터(FundAR): LLM-only (0.692) < FL-only (0.899). → 펀드 페이지뷰·CD 금리 같은 보조 변수의 의미 정보가 노이즈를 가르는 데 결정적.
- 에너지 데이터(Solar): FL-only (0.034) < LLM-only (0.043). → 태양광은 강한 주기성이 있어 주파수 분해가 대부분의 일을 끝낸다. 보조 변수 기여는 부가적.
저자들의 설계 의도("노이즈 많고 맥락 중요한 도메인 ↔ LLM", "주기 강한 도메인 ↔ 주파수 분해")와 ablation 결과가 깔끔하게 맞춰 들어가는 그림이다. 한 편의 논문 안에서 가장 설득력 있는 부분.
한계
논문에 별도 Limitations 섹션은 없다. 읽으면서 느낀 것:
- 평가 범위가 좁다. 2개 데이터셋, horizon 1만 비교됨. 장기(h=24/96) 예측과 더 다양한 도메인에서 같은 분업 구조가 유지될지는 미지수.
- Qwen3-8B의 비용. QLoRA여도 8B 백본은 edge 배포에 부담이다. 006 rsLoRA(2.2 MiB)와 대조적이고, 효율성은 이 논문의 메시지가 아니다.
- 공식 GitHub은 현재 불완전. README에 "complete code will be provided later"만 적혀 있고 star 1개 수준. KDD '26 accept 논문 치고 재현성 투자가 약해 외부 재현이 당장은 어렵다.
- Few-shot 정의의 특수성. "최근 N 시점 잘라 쓰기"라 일반적인 N-shot random sampling 프로토콜과 직접 비교하기 어렵다. 실무적으로는 의미 있지만, 기존 few-shot 논문 수치와 맞닿지 않는다.
- 베이스라인 최신성. Chronos·Moirai·Kronos 같은 TS foundation 모델이 빠져 있어 "최근 TSFM 대비 우위"까지는 보장되지 않는다.
짧은 코멘트
이 논문에서 가장 마음에 든 건 Table 5 ablation의 대칭이다. FundAR에선 LLM-only(MAE 0.692)가 FL-only(0.899)를 앞서고, Solar에선 반대로 FL-only(0.034)가 LLM-only(0.043)를 앞선다. 저자들의 설계 의도 — "보조 변수의 의미 정보가 중요한 도메인엔 LLM, 주기성이 지배하는 도메인엔 주파수 분해" — 와 실험 결과가 이렇게 대칭적으로 맞아떨어지는 경우는 드물다. 앞서 리뷰한 Rethinking이 token-level routing으로 "LLM이 어느 시점에 동원되는가"를 들여다봤다면, LoFT-LLM은 같은 질문을 ablation 한 페이지로 "LLM이 어느 도메인에서 일하는가"로 받는 셈이다. 한 편의 논문 안에서 설계 가설과 검증이 이렇게 깔끔하게 붙어 있는 건 이 논문의 가장 단정한 부분이다.
읽으면서 내내 떠오른 건 이 구도를 본인 도메인(물류·공급망 수요 예측)에 얹을 수 있을지였다. 신제품 cold start, 프로모션·재고·캘린더·기상처럼 자연어로 풀어낼 수 있는 보조 변수, 노이즈 큰 일간 수요 — 저자들이 금융·에너지에서 정리한 조건과 프로파일이 거의 그대로 겹친다. 다만 실무 물류는 다품목 × 장기 horizon이 기본값인데, 이 논문의 scope는 horizon 1 · 단일 target · 675 시점짜리 금융 데이터다. 수천 SKU의 맥락을 prompt 한 번에 녹이려고 하면 비용·일관성·compression 쪽에서 새 병목이 생길 가능성이 크다. "LLM을 수치 예측기 대신 맥락 해석기로 쓴다"는 설계 철학 자체는 공감 가지만, 공급망 실무로 옮기는 순간 prompt 엔지니어링이 거의 새 연구가 될 것 같다.
참고
- arXiv: https://arxiv.org/abs/2512.20002
- Code (WIP): https://github.com/yjcGitHub0/LoFT-LLM
- FundAR 데이터셋: 2024 알리바바 Tianchi (펀드 신청·환매 예측 대회)
- Solar 데이터셋: GEFCom 2014, Region 1
- 이 블로그의 관련 리뷰:
- [논문리뷰] Rethinking the Role of LLMs in TS Forecasting — LLM4TS가 언제 도움되는가
- [논문리뷰] One-for-All (rsLoRA) — LLM4TS 경량화의 하한
- 관련 — rsLoRA: Kalajdzievski (arXiv 2312.03732)
- 관련 — iTransformer: Liu et al. (arXiv 2310.06625)
- 반대편 입장 — Are LLMs Actually Useful for Time Series Forecasting? (arXiv 2406.16964)
