BLEU Score
NLP 논문을 읽다보면 정말 자주 나오는 것 같다.
우선 precision과 recall을 먼저 알고 넘어가야한다.
Precision & Recall
이미지 분류 모델처럼 cross-entropy loss와 같이 일반적인 loss 방법들을 사용하면 NLP에서 맞지 않을 수 있다.
가령 문장 생성 task에서 한 문장이나 단어를 빼먹거나 문장을 더 많이 생성한다면 현재 상황을 제대로 반영하지 못한다.
예를 들어 I love you -> Oh I love you로 예측했다고 하면, 결론적으로 이 모델은 하나도 맞추지 못한 것이다. 하지만 이 경우는 Oh를 제외하기만 하면 모두 맞는 모델인데 기존 평가방법들은 이러한 정보를 반영하지 못한다.
그래서 precision과 recall 개념을 이용한다.
Reference : Half of my heart is in Havana ooh na na
Predicted : Half as my heart is in Obama ooh na
위와 같은 문장에서
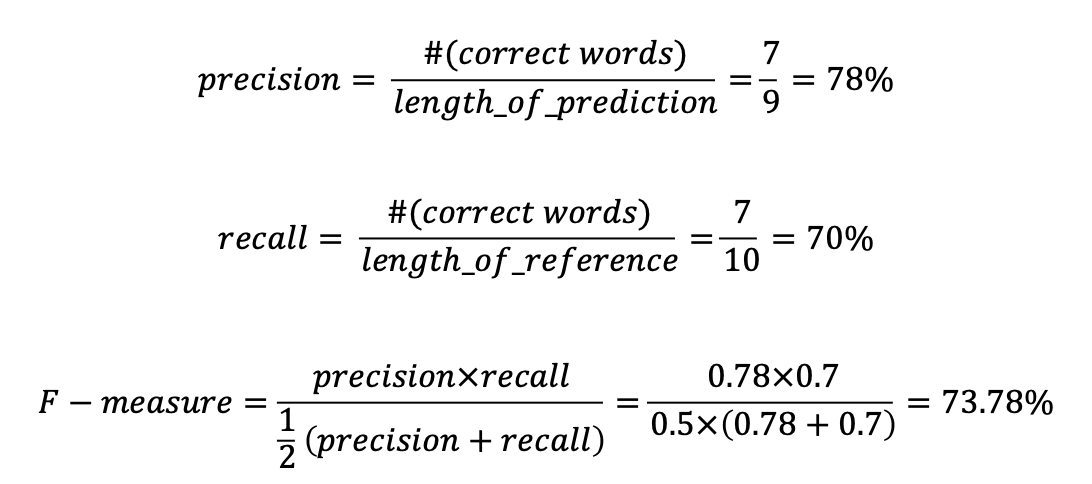
- Precision은 예측된 결과를 받는 우리가 실질적으로 느끼는 정확도이다.
- Recall은 예측된 결과를 받는 우리가 못 보고 모른 채 넘어가는 정보 없이 얼마나 정보를 받는 지를 말해준다.
위에서 precision 결과인 78과 recall 결과인 70의 산술평균을 구할 수도 있고 기하평균을 구할 수도, 조화평균을 구할 수도있다.
이 평균내는 방법들은 산술평균이 가장 크고 그 다음이 기하, 마지막이 조화순으로 크다.(산술 > 기하 > 조화)
조화평균을 이용하여 보다 작은 값에 더 많은 가중치를 부여한다.
F-measure는 precision과 recall의 조화평균이다.
하지만
Reference : Half of my heart is in Havana ooh na na
Predicted : Havana na in heart my is Half ooh oh na
이러한 경우에서는 Precision, recall, F-measure 모두 100%가 된다. 하지만 순서가 전혀 맞지 않은 상태이다.
그래서 더 나아가 성능평가로 BLEU score를 사용한다.
BLEU Score
- 하나하나 ground truth와의 비교뿐만 아니라 N-gram으로 연속된 단어와의 비교도 한다.
- Recall은 무시하고 Precision만을 가지고 구한다.
-> 이는 NLP 번역의 특성을 생각해보면 이해가 간다. 얼마나 빠짐없이 번역을 했는가 보다는 번역이 된 문장이 얼마나 의미를 잘 담고있는지가 더 중요하기 때문이다.
-> 이 부분은 precision의 기하평균을 내기위한 수식이다. 여기서 조화평균을 쓰지 않은 것은 여기서는 작은 값에 지나치게 가중치를 주기 때문이다.- recall을 따로 구하지 않아도, 만약 모든 단어가 매칭된 상황이나 예측 문장 수가 더 많을 경우 recall이 높은 것을 당연하게 생각할 수 있다.
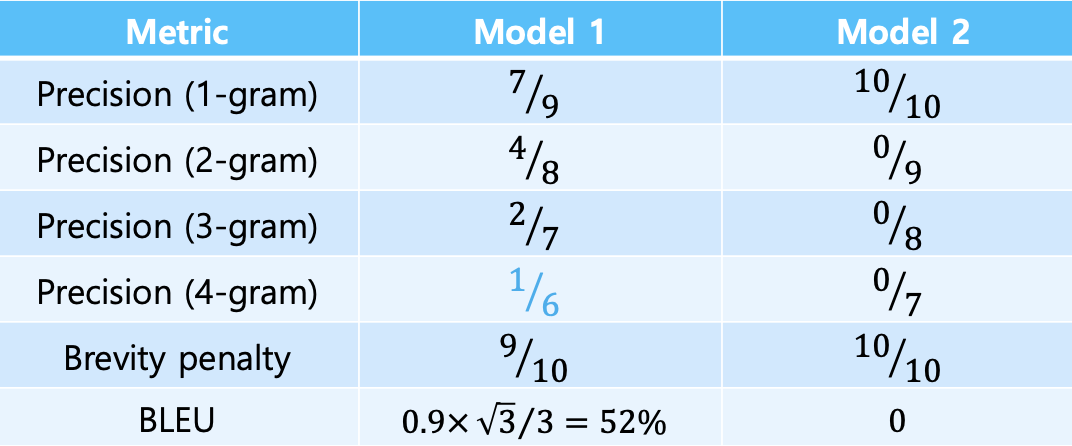
model 1 : Half as my heart is in Obama ooh na
model 2 : Havana na in heart my is Half ooh of na
이러한 상황일 때 각 n-gram Precision과 BLEU는 아래와 같다.
(brevity penalty는 문장의 길이를 말한다.)
마무리
BLEU Score가 왜 NLP에서 중요한 지를 느낄 수 있었다.
그리고 요즘 Action Segmentation에 대해서 공부하고 있는데, 이 task도 시계열 예측을 따르고 이 문장생성과 비슷한 점이 많아보여 BLEU를 사용해도 좋을 것 같다는 생각이 문득 들었다.

영어에서는 띄어쓰기를 기준으로 단어를 나눌 수 있어서 BLEU 스코어를 계산하기 비교적 수월할 것 같은데요.
한국어에서는 어미에 따라 스코어가 달라질 수 있지 않을까요?
'생각했지만' <-> '생각하면'
한국어에서 이런 경우를 어떻게 평가하는지 알아보면 좋을 것 같습니다!