Beam Search
Greedy decoding
매 타임 스텝마다 높은 확률을 가지는 단어 하나만을 선택해서 진행한다.
이를 Greedy decoding이라고 한다.
알고리즘 공부했을 때 배운, 그리디 알고리즘처럼 당시 상황에서의 최선의 선택을 하기 때문에 앞에 Greedy가 붙은 것 같다.
이 단점중 하나는 뒤로 못 돌아가는 것이다.
Exhaustive Search
그래서 joint probability를 수식으로 사용해서 해결한다.
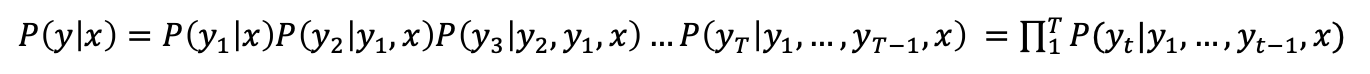
이렇게 해서 에서 작은 값을 가졌더라고 이후 값들에서 큰 값을 얻어 바뀔 수 있다.
- time step t까지의 모든 가능성을 따진다.
-> 너무 큰 시간 복잡도
Beam Search
하나의 가능성만 보는 Greedy decoding과 모든 가능성을 보는 Exhaustive Search 사이에 있는 것이 Beam Search이다.
-> k개의 경우의 수를 고려하는 방식
k : beam size (일반적으로 5 ~ 10)
그리고 위의 수식에서 단어를 하나씩 생성하면서 그때의 확률값을 하나씩 모두 곱하였다.
이를 Log를 붙여 곱셈에서 덧셈으로 식을 변경한다.
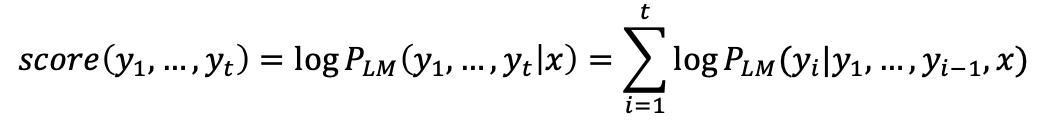

-> 여기서 beam size는 2로 가지도 2개씩 만들어지는 것을 볼 수 있다.
그리고 누적 확률로 동일한 단어라도 이전 단어가 무엇이었냐에 따라 다르게 계산된다. 다시 상위 K개를 선택하고 이 과정을 반복한다.
디코딩을 끝낼 때, greedy decoding은 <'end'>토큰으로 끝내면 되지만
beam Search decoding시에는 서로 다른 시점에서 <'end'> 토큰을 만 들 수 있기 때문에 어느 하나라도 각 hypothesis에서 END 토큰을 만들면 해당 hypothesis를 종료한다.
Stopping criterion
- timestep T를 미리 설정해두었다가 T가 되면 종료할 수도 있고
- n을 미리 설정하여 <'eos'>가 적어도 n개 이상이 되면 종료하는 방법도 있다.
Finishing up
- 완성된 hypotheses중에서 가장 높은 스코어 하나를 고른다.
- 이때, log버전의 join probability가 가장 큰 하나를 고른다.
-> 여기서 상대적으로 짧은 문장에서 joint probability가 높은 스코어를 가지는 문제점이 있다. ( 기존의 log값에 계속 -값을 계속 더하기 때문)
이 해결책으로 길이로 나눈다.
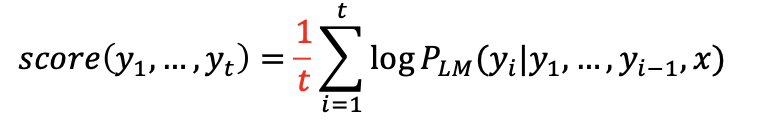
마무리
Beam Search공부하면서 슬라이딩 윈도우나 truncated backpropagation이 생각났다. 딥러닝에서는 매우 길어서 연산량이나 메모리에 부담스러우면 이런 식으로 하이터파라미터를 생성하고 자르는 것 같다...
