DETR - End-to-End Object Detection with Transformer
이번에 소개할 논문은 Facebook AI 팀에서 공개한
Transformer 방식을 Computer Vision의 Object Detection 분야에 적용시킨 DETR입니다.
DETR은 DEtection + TRansformer 의 줄임말로, 이름에서부터 Transformer가 Detection 방식에 사용됨을 유추할 수 있습니다.
논문 제목에서 End-to-End 라는 말의 의미는,
(뒤에 등장하지만)기존 Detection Network가 가지고 있는 초매개변수(Hyper-Parameter, ex. NMS, threshold, anchor-box etc.)를
Transformer의 End-to-End 방식의 학습을 통해 없앴다고 볼 수 있습니다.
1. Abstract
논문에서 크게 주장하는 핵심은 다음과 같습니다:
1. 사용자가 설정해야 하는 것(Hand-designed Components) 을 제거
2. Simple한 Network 구성
3. 이분법적 매칭(Bipartite Matching)과 Transformer의 Encoder-Decoder 구조 사용 추가적으로, Object Detection 분야 뿐 만 아니라
Panoptic Segmentation(a.k.a Instance Segmentation) 분야에서도 좋은 성능을 보여준다고 합니다.
2. Model Architecture
네트워크의 전체적인 구성은 다음과 같습니다:

해당 네트워크는 크게 본다면
1) Convolution Neural Network(ResNet)
2) Transformer Encoder
3) Transformer Decoder
4) Feed-Foward Network(FFN)
이렇게 4단계로 구분할 수 있습니다.
DETR은 이 4단계를 통해 입력 데이터를 곧바로 분류 정보 및 bbox 정보를 추론 하기 때문에,
NMS와 같은 사용자의 입력 값을 요구하는 알고리즘이 필요하지 않습니다.1) Convolution Neural Network
CNN의 주 목적은 입력 영상 데이터의 특징 추출 입니다.
논문에서 사용한 CNN(=Backbone)은 ResNet으로,
3ch W H 영상 데이터가 입력으로 들어온 후 > 최종 2048ch W/32 H/32 크기의 Feature Map을 생성합니다.

저자는 Backbone CNN으로 ResNet50 모델을 사용하였는데,
해당 모델의 맨 마지막 channel 깊이는 2048임을 알 수 있습니다.
2) Transformer Encoder
CNN을 거쳐 생성된 Feature Map은 1x1 convolution을 통해 d 차원(=d 채널)으로 축소됩니다.
- Encoder는 Sequence Data를 입력으로 받기 때문에, Vectorizing함을 알 수 있습니다.
- 또한, 축소 된 d 채널은 Spatial하게 분리하여 H*W 크기로 구성된 d 개의 조각으로 분리할 수 있습니다.
2) Transformer Encoder
CNN을 거쳐 생성된 Feature Map은 1x1 convolution을 통해 d 차원(=d 채널)으로 축소됩니다.
Encoder는 Sequence Data를 입력으로 받기 때문에, Vectorizing함을 알 수 있습니다.
또한, 축소 된 d 채널은 Spatial하게 분리하여 H*W 크기로 구성된 d 개의 조각으로 분리할 수 있습니다.
각각의 d개 조각은 Encoder Layer의 입력으로 Sequencial하게 들어가며, Encoder Layer는 기본적인 구조로 구성되어 있습니다.
- Encoder Layer는 Multi-head Self-attention module로 구성되어 있습니다.
Encoder에서 살펴 볼 것은 다음과 같습니다:
* 원래 Transformer는 입력 데이터의 순서가 출력 데이터에 영향을 주지 않습니다.
* 하지만 Vision 문제에서는 분리 된 d개의 조각에 대한 순서다가 중요하기 때문에 각각의 Attention Layer마다 Position Embedding을 실시합니다.3) Transformer Decoder
Decoder 역시 Encoder와 동일하게 Standard한 구조를 따릅니다.
Encoder의 출력으로 d size의 N Embedding이 나오고, 이는 그대로 Decoder의 입력으로 들어갑니다.
Decoder에서 살펴 볼 것은 다음과 같습니다:
* 원래의 Decoder는 분리 된 d 개의 조각을 하나의 Sequence로 보고, 통째로 입력 데이터로 들어갑니다.
* 하지만 DETR에서는 각각의 Decoder Layer마다 N 개의 Embedding 객체를 Parallel하게 Decoding합니다.
* 또한, Encoder처럼 각각의 Attention Layer에 Object Query를 추가하여 Position Embedding과 유사한 작업을 합니다.4) Feed-Foward Network(FFN)
FFN 같은 경우는 단순한 구조로 되어 있습니다:
- 3 Layer의 Perceptron으로 구성되어 있습니다.
- 각각의 Perceptron은 ReLU 활성화 함수와 d 차원의 은닉층, 1개의 Linear Projection으로 되어 있습니다.
또한, FFN을 거치게 되면 Predict한 값이 나오게 되는데, 이 값은 다음과 같습니다:
1) Center X (relative)
2) Center Y (relative)
3) Height (relative)
4) Width (relative)
(Relative한 좌표는 픽셀의 개수를 count하는 절대 좌표가 아닌, 이미지 전체의 H/W에 비례하는 0과 1사이의 좌표 값입니다.)
FFN은 Softmax 함수를 통해 분류 라벨 또한 Predict 합니다.
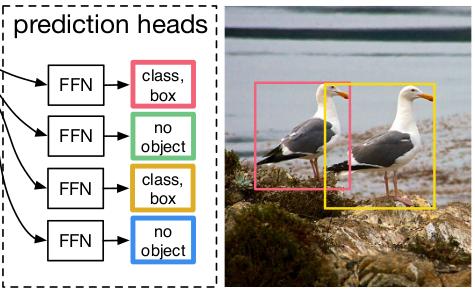
Predict 할 때, Ground-Truth 개수가 5개이고, Detection 객체 개수가 7개라면
Ground-Truth 쪽에 2개의 (no object)를 만들어줍니다.

그림과 같이, 4개의 객체를 검출했다면, 2개는 (no object) 항목으로 할당하고 2개는 정답으로 처리하여 이분법(bipartite)적으로 처리하게 됩니다.
3. Experiments
실험 조건은 다음과 같습니다:
| Item | Content |
|---|---|
| Comparison Network | Faster-RCNN |
| Optimizer | AdamW |
| Backbone | ResNet-50, ResNet-101 |
| Epoch | 300 |
| Dataset | COCO 2017 |
실험에 사용된 Dataset은 COCO 2017의 detection + segmentation 데이터 세트 입니다.
Segmentation은 Panoptic Segmentation의 성능 측정을 위해 사용하였습니다.

그림에서 보는 것과 같이,
1. 대부분의 상황에서 DETR의 parameter 개수가 현저히 낮음을 알 수 있으며,
2. Average Precision은 6 case 중 4 case에서 Faster-RCNN보다 높음을 알 수 있습니다.
여기서 Faster-RCNN이 높은 케이스 중, AP-Small size는 Faster-RCNN이 27.2로 23.7의 DETR보다 우월하게 높습니다.
즉, DETR은 작은 Object에 대해서 상대적으로 약함을 보입니다.
4. Source Code
논문의 저자는 Paper 맨 뒤에 간단한 구현 코드를 공개했습니다.
Abstract에서 말한 것처럼, 코드는 매우 간단한 구조로 되어 있습니다:

이 코드에서 우리는 ResNet-50 모델을 사용한 것과, 내부 프레임워크에서 제공하는 수준의 Transformer 함수를 그대로 사용한 것을 알 수 있습니다.
(Paper Review는 제가 스스로 읽고 작성한 글이므로, 주관적인 내용임을 밝힙니다.)
