GoogLeNet은 구글 리서치의 Christian Szegedy 등이 개발한 구조이다.
ILSVRC 2014(전세계 이미지 인식 대회)에서 톱-5 에러율이 7% 이하인 좋은 성능의 구조이다.
톱-5 에러율이란?
top-5 error는 Image Classification에서 주로 사용되는 지표이다. 쉽게 말해 모델이 예측한 Top-5 중에 실제 클래스가 있다면 맞춘걸로 판별한다.
Source : https://velog.io/@garam/top-1-error-top-5-error
이 구조에서 사용된 인셉션 모듈에는 1x1 convolution layer가 사용되었는데, 도대체 왜 1x1을 사용하고 또 이 의미가 뭔지에 대해서도 알아보자.
Parameter 수
Parameter의 수는 중요하다. 학습에 사용되는 주 자원으로, 지나치게 많다면 computing resource와 time을 너무 많이 잡아먹어 모델 학습에 어려움이 있을 것이다. 따라서 줄일 수 있다면 줄이는 것이 좋다(무조건 줄이는 것은 좋지 않다). CNN network에서 parameter 수는 어떻게 셀까?
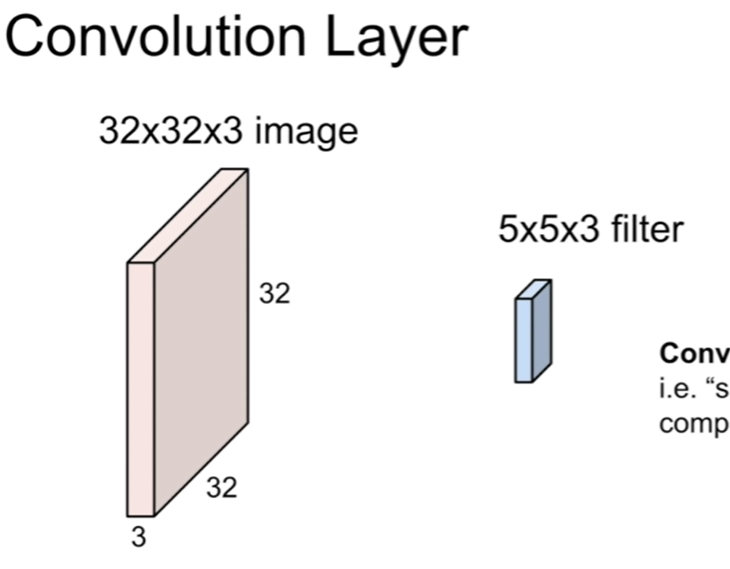
이렇게 생긴 CNN layer가 있다고 생각해보자(cs231n lecture5-slide30). Input size는 32*32*3이고, filter size는 5x5x3 이다.
즉 가로 세로가 32이며, channel이 3인 이미지에 5x5 filter를 적용한다는 것이다.
(너무나 기초적인 것을 헷갈렸다.. filter의 channel 수는 항상 input channel 수와 같다. 표기가 안되어 있다면 생략한 것이다..)
여기서 parameter 수는 뭘까?
Filter 하나에 5*5 = 25 파라미터가 있고, 각 filter는 3 channel을 가지므로
5*5*3이 된다.
만약 filter가 5개라면? 5*5*3*5(출력 filter 수)가 된다.
즉 정리해보자면 Filter width * Filter height * channel num * output filter num을 하면 된다! 쉽다!
그렇다면 1x1 convolution은 왜 쓰는지 감이 슬슬 온다. 우리는 출력 filter 수로 다음 층의 channel 수를 정할 수 있다.
Filter Number와 Output의 Channel Number
왜? 이 부분이 처음에 순간 헷갈렸다. 이유는 다음과 같다.
앞의 이미지에 있는 32323 이미지는 RGB이므로 channel 수가 3이다. Filter 1개를 적용하면 output은 1 channel로 바뀐다!
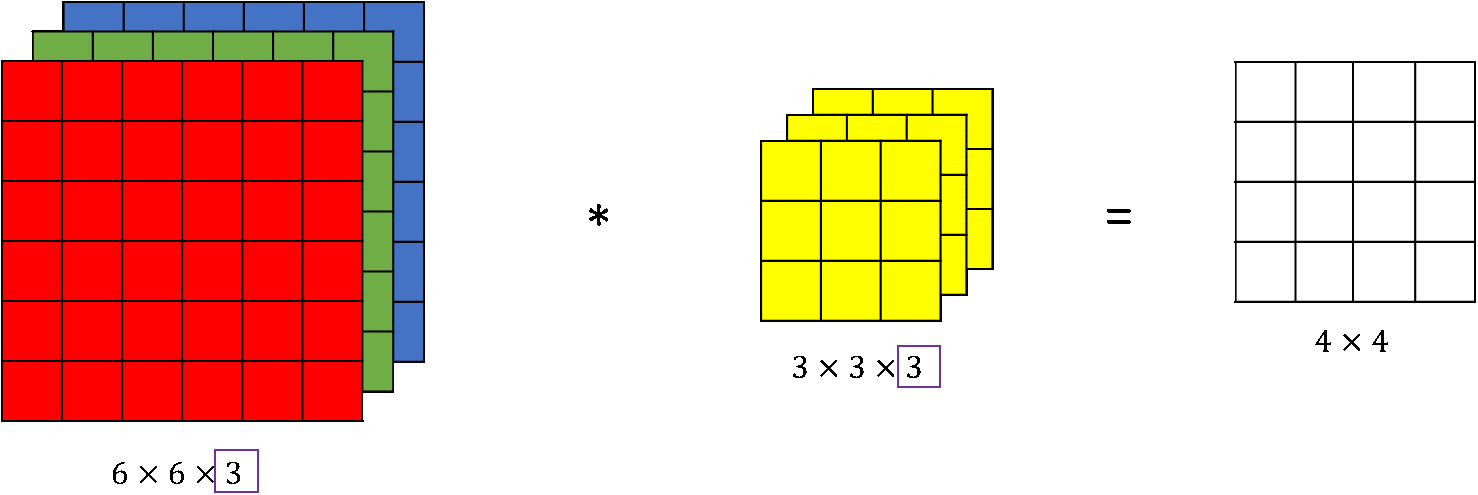
이 부분이 이해가 되지 않는다면 convolution 개념을 다시 한 번 봐야 한다.

이렇게 각 결과를 더해주는 것이다. 즉, filter가 1개라면 output의 channel은 1개가 된다.
따라서 filter 수로 output의 channel 수를 결정할 수 있다.
1x1 Convolution 적용
이제 1x1 convolution을 적용해보자. 앞서 보았듯이 여기서는 output의 channel 수 조절용으로 사용할 것이다.
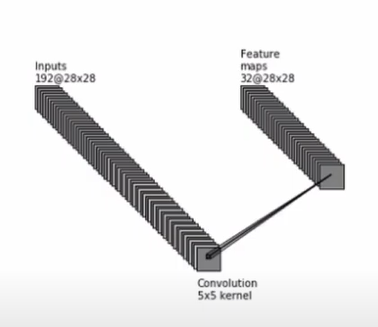
여기서 예시로 28*28*192의 input을 생각해보자. 우리가 원하는 것은 5x5 filter 32개를 적용하는 것이다(생략되어 있지만 당연히 filter의 channel 수는 192개이다, zero padding도 사용한다).
1x1 convolution이 없다면 operation(계산량) 수는 28*28*192*32*5*5~=120M이다
(parameter 수는 192*32*5*5~=0.15M이다).
그렇지만 1x1 convolution을 먼저 적용하고 5x5 filter를 적용해보자. 여기서는 1x1 filter 16개를 적용한다.
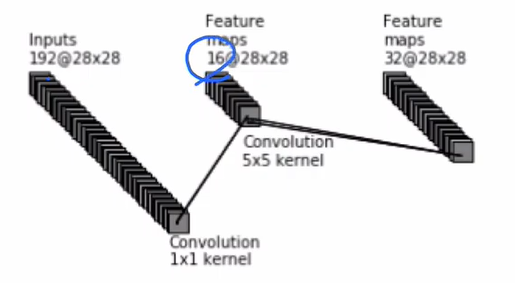
Output은 28*28*192에 1x1 filter 16개를 적용했으므로 28*28*16이 될 것이다. 여기에 5x5 filter 32개를 적용하면 최종적으로 28*28*32가 된다.
여기서 사용한 operation 수는 1*1*16*28*28*192+5*5*32*28*28*16~=12M이므로 무려 1/10 가량 줄어든다!
Parameter 수 역시 경이롭게 줄어든다. Parameter는 192*16*1*1+16*32*5*5=12800~=0.012M이다! 1/10보다 더 줄어들었다.
이해를 돕기 위한 영상이 있다. 참고해보자.
https://www.youtube.com/watch?v=BzLiyUAKvNI
장점
Parameter와 operation 수가 상당히 줄어든다. 이 경우에만 봐도 1/10 이상으로 줄어들어 이득을 볼 수 있다.
차원 축소 역시 가능하다. Filter 수를 조절하면 output의 channel 수를 조정할 수 있다. 따라서 초기 input dimension보다 작다면 차원 축소를 할 수 있어 핵심적 데이터만 뽑아낼 수 있다.
비선형성 역시 증가한다. 구글 팀이 만든 1x1 convolution은 ReLU activation을 사용하므로 이 구조가 추가됨에 따라 비선형성이 증가한다. 이는 더 복잡한 패턴 인식에 도움을 준다.
Reference
https://gaussian37.github.io/dl-keras-number-of-cnn-param/
https://www.youtube.com/watch?v=hqYfqNAQIjE
https://www.youtube.com/watch?v=VNMAXwdHUAA
https://euneestella.github.io/research/2021-10-14-why-we-use-1x1-convolution-at-deep-learning/
https://hwiyong.tistory.com/45
