1. Iterative Loop of ML Development
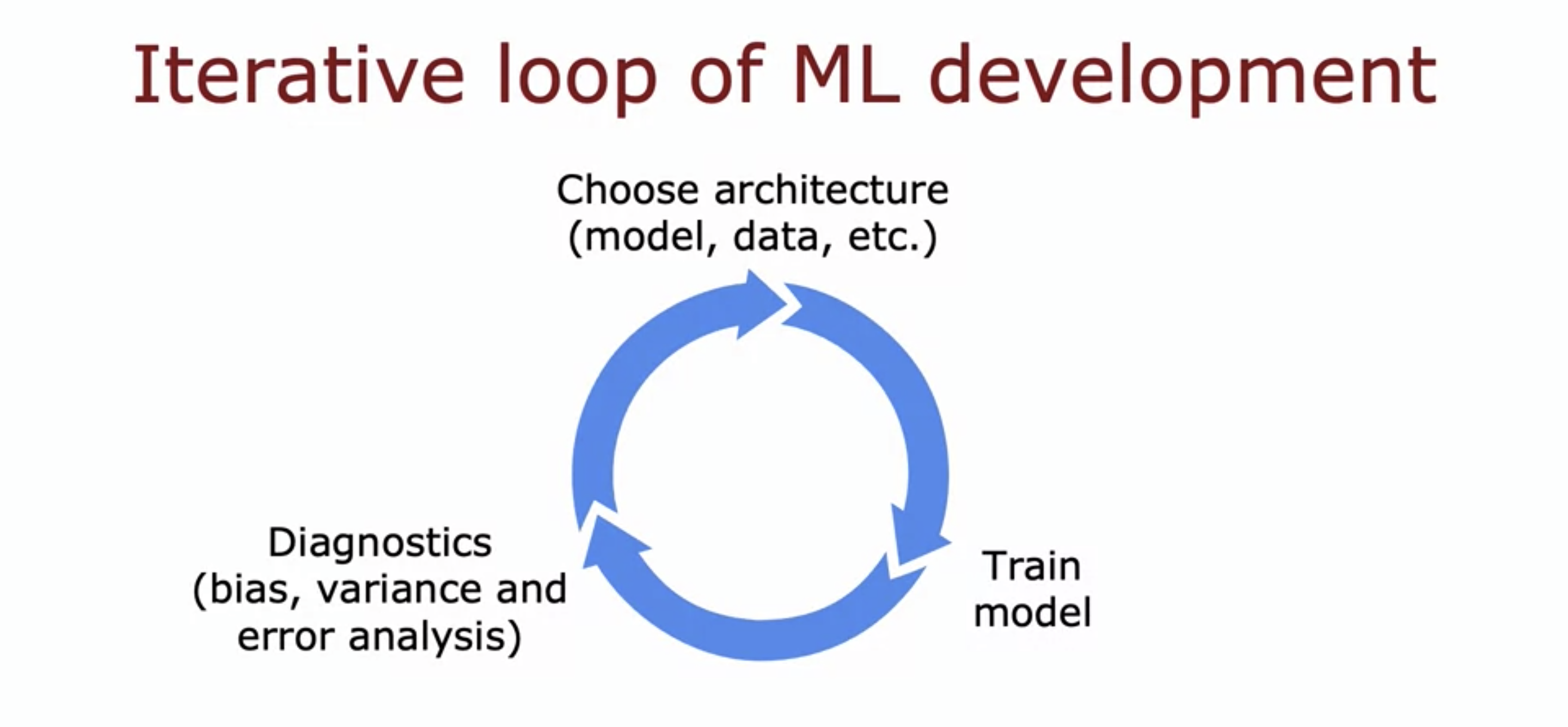
- Choosing an architecture: ML model, what data to use, what hyperparameters, etc.
- Training model: Training model will almost never work the first time.
- Diagnostics: Make decisions like make the neural network bigger, change the Lambda regularization parameter, or maybe add more data or add more features or subtract features.
- Then we go around the loop. It takes multiple iterations

- Here is an example of building a spam classifier model.
- We can use the top 10,000 words in the dictionary and use them as features, then build a neural network model.

- Collecting more data can reduce error,
- but not when there is high bias. It can reduce high variance error tho.
- We can use email header to build more sophisticated feature.
- We can define more sophisticated features from email body.
- We can design algorithms to detect misspellings.
- Coming up with more promising path forward can speed up our project.
2. Error Analysis

- Look into (manually) the misclassified data, try to find similarities / common theme.
- By categorizing the different causes of errors, we can prioritize which error to solve first.
- If m_cv is huge and there is a lot of data misclassified, then it is helpful to randomly sample a subset of them and try to categorize the errors.
- If pharmaceutical emails are misclassified, can get more data of the pharmaceutical emails specifically.
- Can also create more features, such as the name of the drugs, to help my learning algorithm become better at recognizing this type of pharma spam.
- Error analysis can be not so good for tasks that even humans are not so good at.
- For example, task like finding out which ads people would click is hard to analyze.
3. Adding more data

- if error analysis has indicated that there are certain subsets of the data that the algorithm is doing particularly poorly on, then it might be good to collect those type of data only instead of collecting all sorts of data.
3-1. Data Augmentation
- Data augmentation is increasing the size of the data artificially.
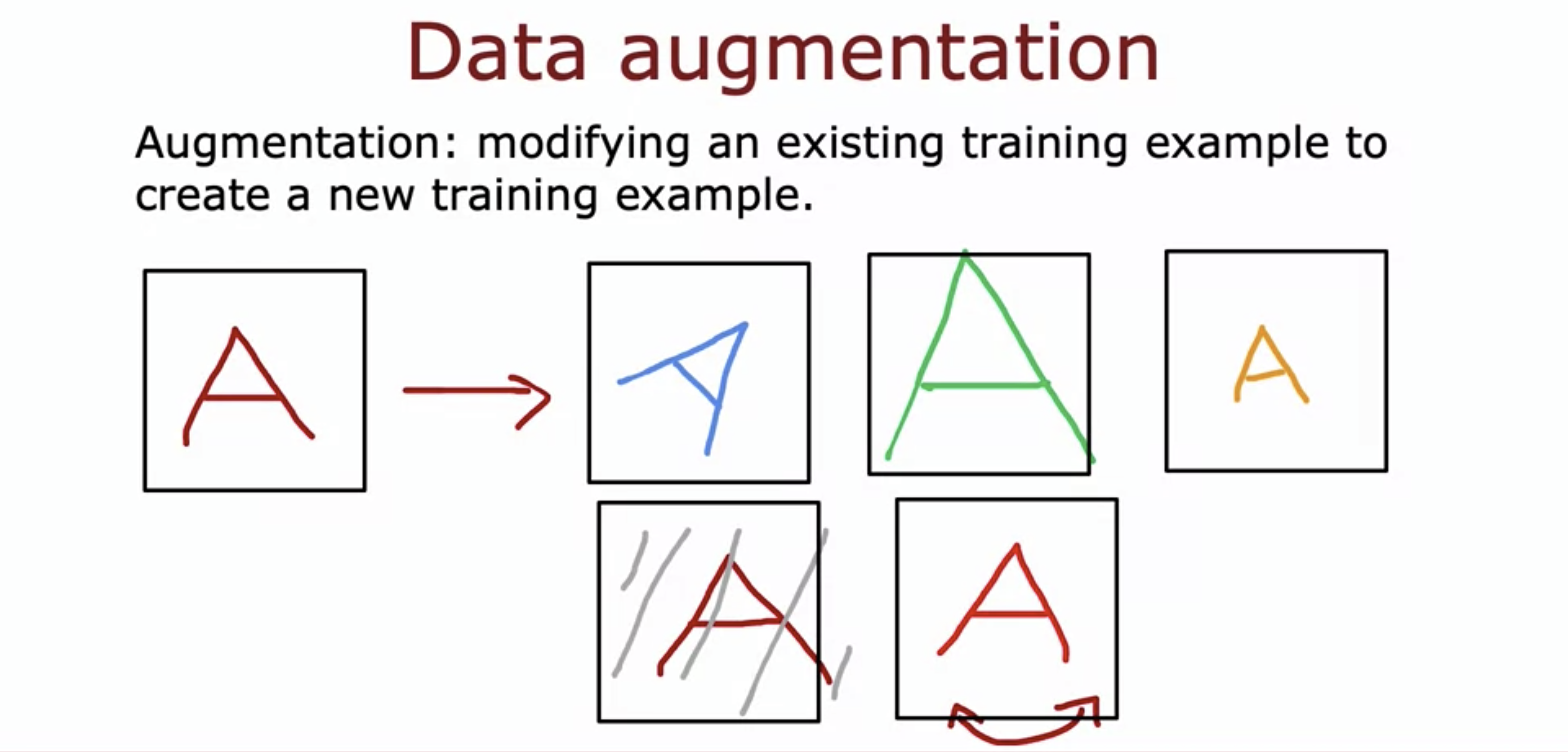
- This is an example of Optical Character Recognition (OCR).
- by rotating, enlarging, shrinking, or contrasting the letter A, we can create new training data of the letter A.
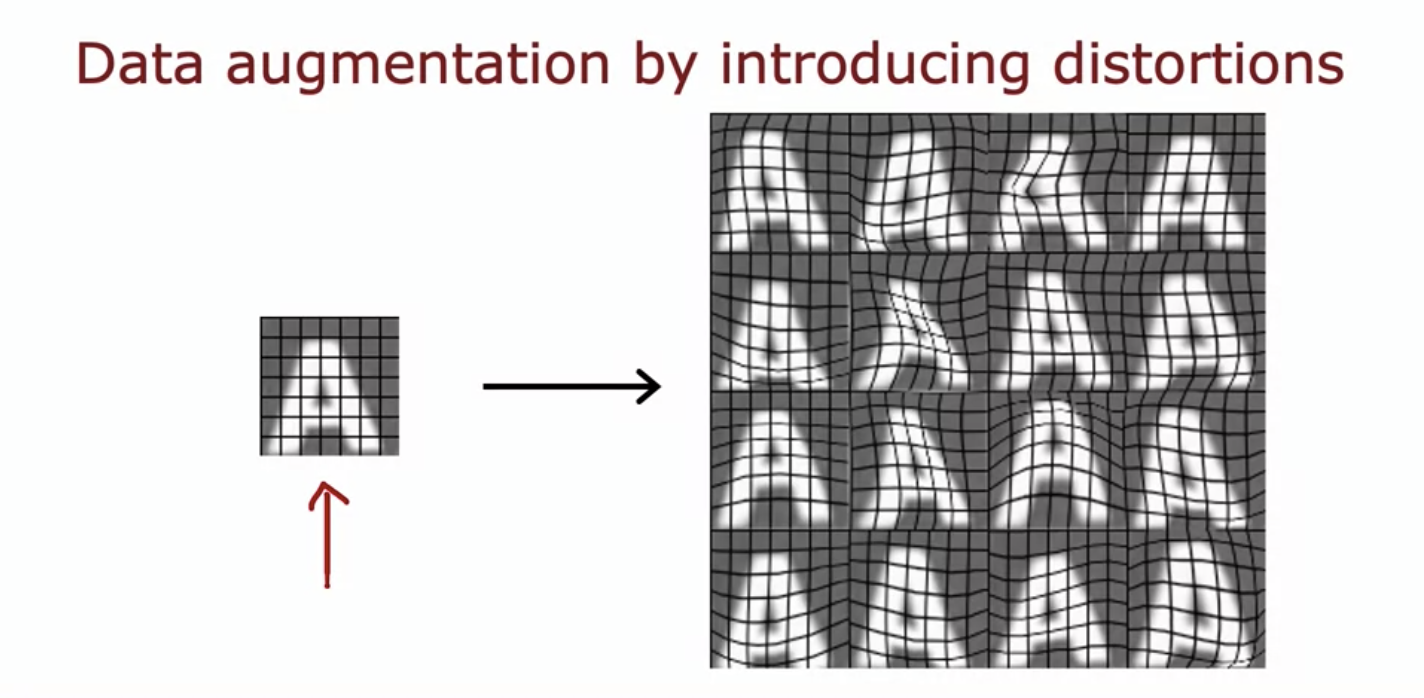
- Can put a grid on the letter A and introduce random warpings on the grid.

- Can also work with sound clips by merging different sound clips to make a new one.

- However, it doesn't work if you just randomly add noises.
- We have to make sure that the distorted data is somewhat similar to actual data.
3-2. Data Synthesis

- Synthetic data is data created by ourselves.
- With the same OCR example, the data on the left is the real data, while data on the right is data generated by text editor or on computer by ourselves.
- We can generate a large number of images or examples for our model.
- It is mostly used for computer vision task, and less for other applications.

- Over the last few decades, the conventional model-centric approach was focused more.
- However, the time has passed and there is already a number of models (linear regression, logistic, etc).
- Now it's more about how good quality your data is.
4. Transfer Learning: using data from a different task
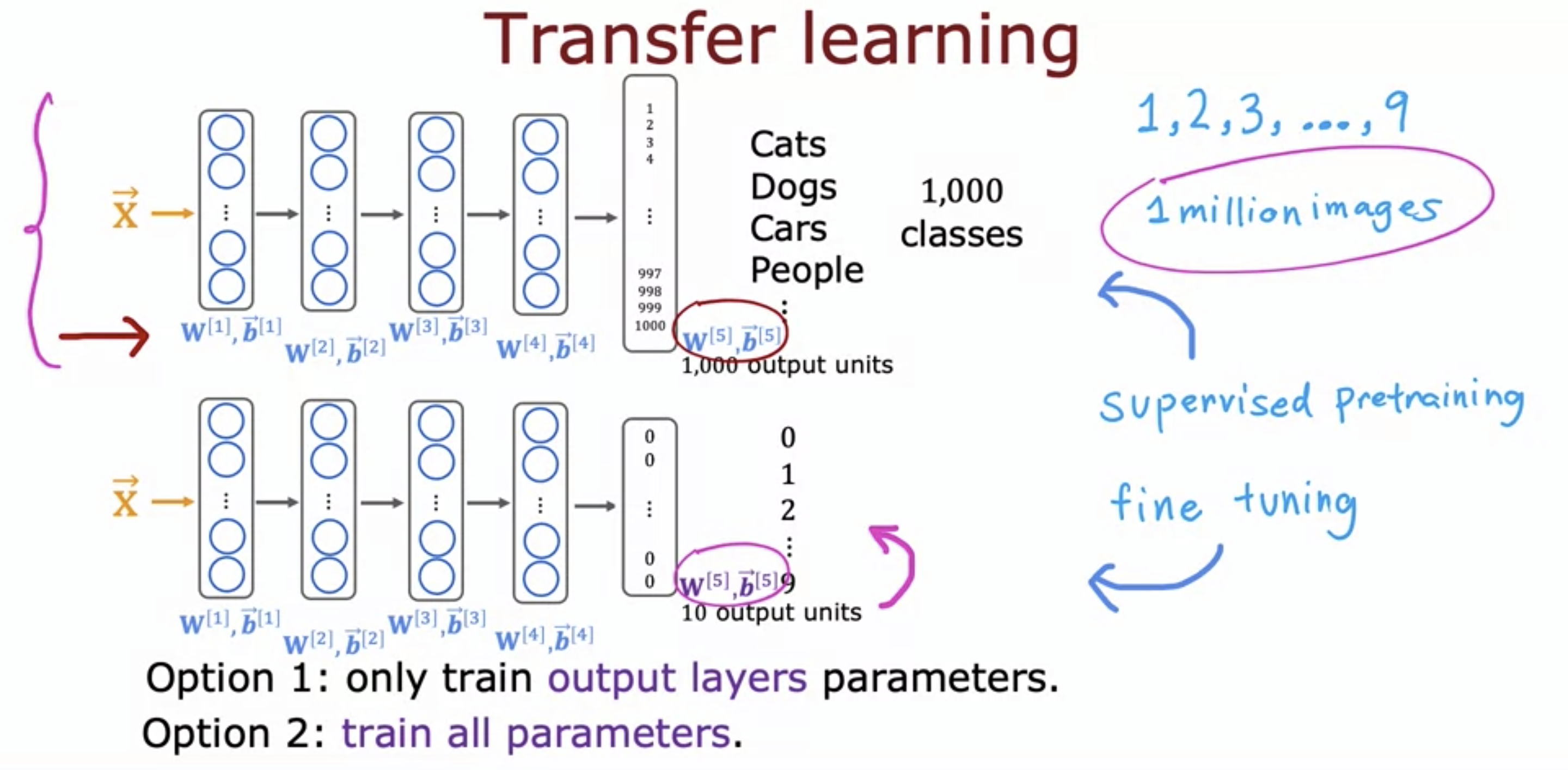
- Transfer learning is using the already trained model (with different data set) and fine tuning it to our use.
- You can choose to train all parameters of the model, including the output layers, as well as the earlier layers.
- Or, you can choose to train just the output layers' parameters and leave the other parameters of the model fixed.
- The pre-training phase is known as supervised pretraining, and the adapting phase is known as fine tuning.
- For example, the same model that is pretrained with the purpose of classifying cats, dogs, and cars can be fine tuned and used for character recognition.
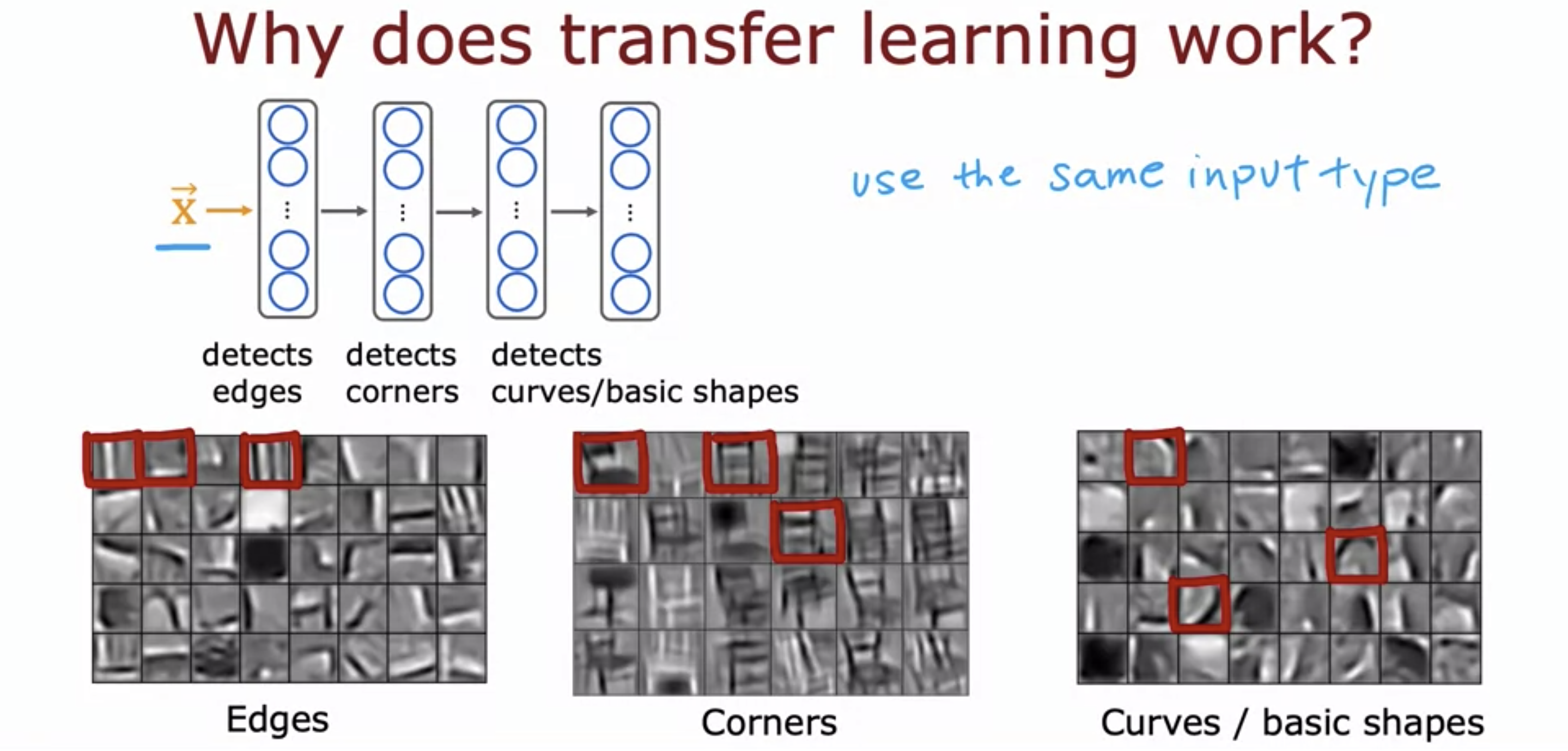
- How it works is that the algorithm that is used to analyze edges, corners, and curves can also be applied to character recognition because characters also have edges, corners, and cures.
- The input type has to be the same: the neural network used for audio recognition cannot be used for character recognition.

- We can download free neural networks published online and fine tune it using our small set of data, and it will work just fine.
5. Full cycle of a machine learning project
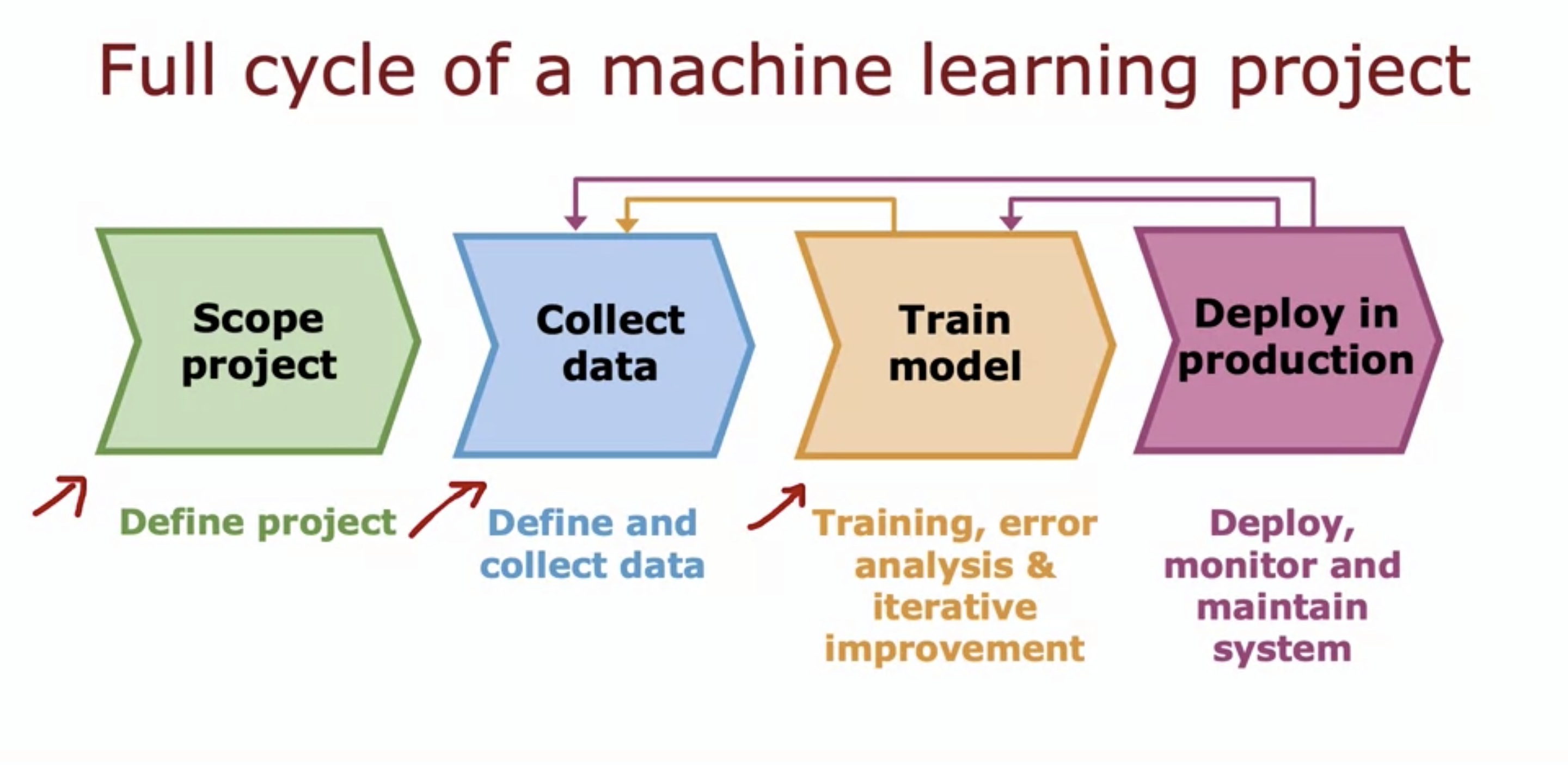
- Scope project: Defining project
- Collect data: collecting data
- Train model: training. Can go back to collecting more data after error analysis (iterative improvement)
- Depoly in production: Once we think it is ready, we can then go to deploy the project. We can always go back to training model or collecting data even, if we think the model is not doing well.
- If it is accessible, we can use the working data from the customers and use that to train our model.
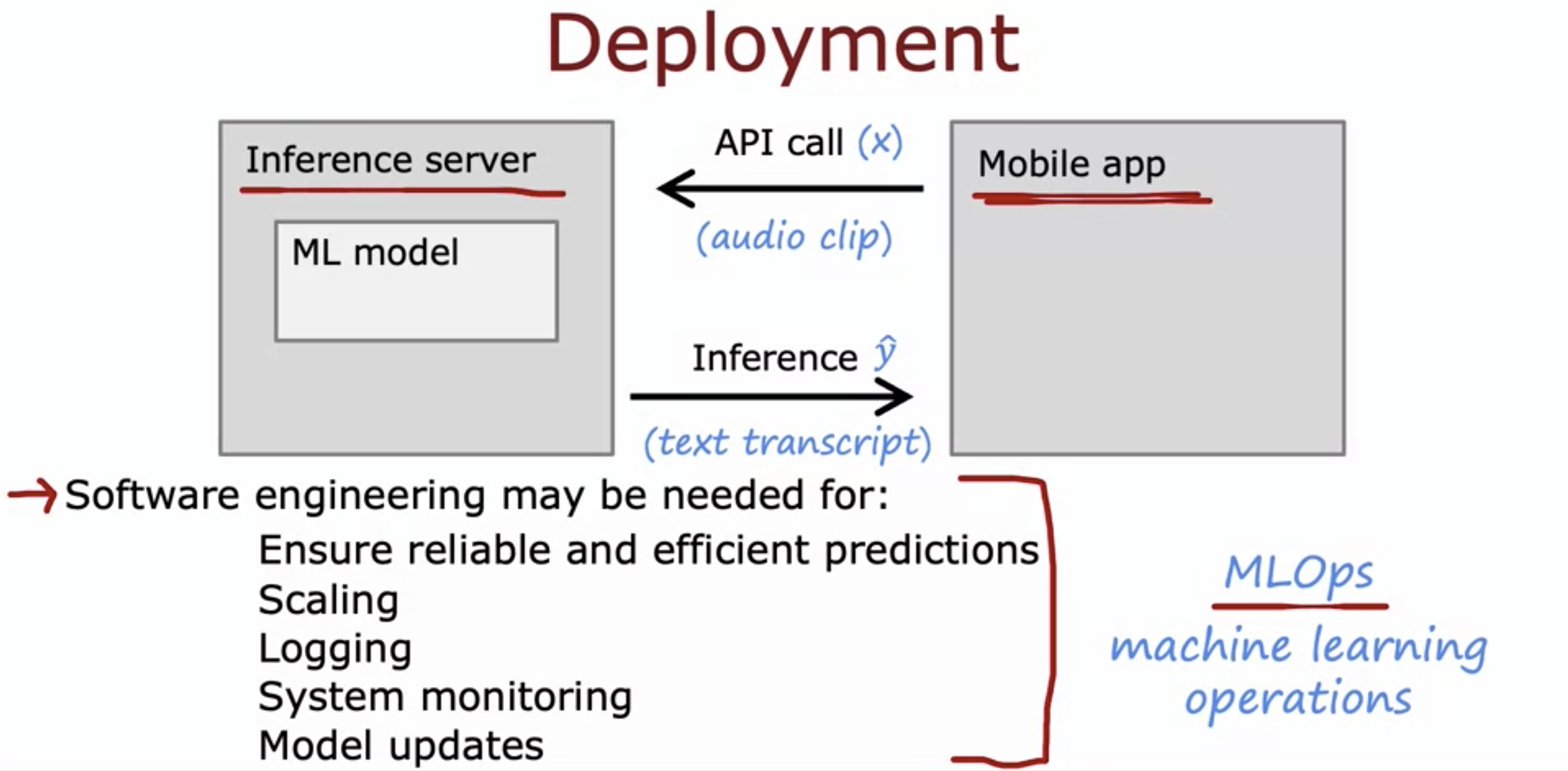
- API call transfers user inputs (ex. voice memos) to the inference server using API call where ML model is being implemented.
- Then model makes a prediction, and the inference (ex. text transcript) is delievered back to the Mobile app.
- Depending on the scale of the project, software engineering may be needed for:
- Ensuring reliable and efficient prediction
- Scaling to a large number of users
- Logging (both the input x and the inference y^, assuming the users consent to collecting their data)
- System monitoring: monitoring the effectiveness.
- Model updates: updating after monitoring.
- MLOps: Machine learning operations - the systematic practice of deploying and maintaining machine learning models in production reliably and efficiently.

everything happens for a reason