1. Decision tree model
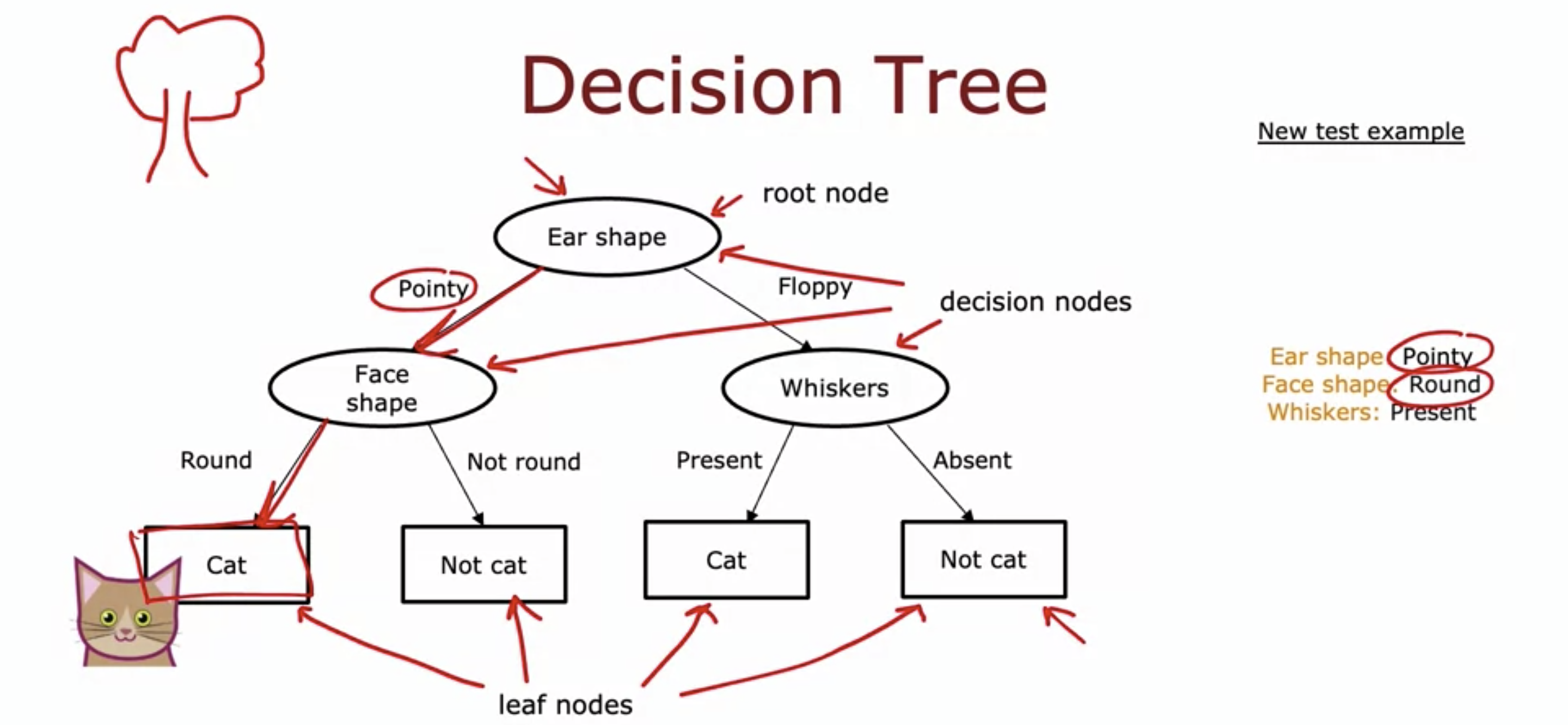
- Root node, decision node, and leaf node.
- A training example goes down the tree and is classified whether it is a cat or not a cat.
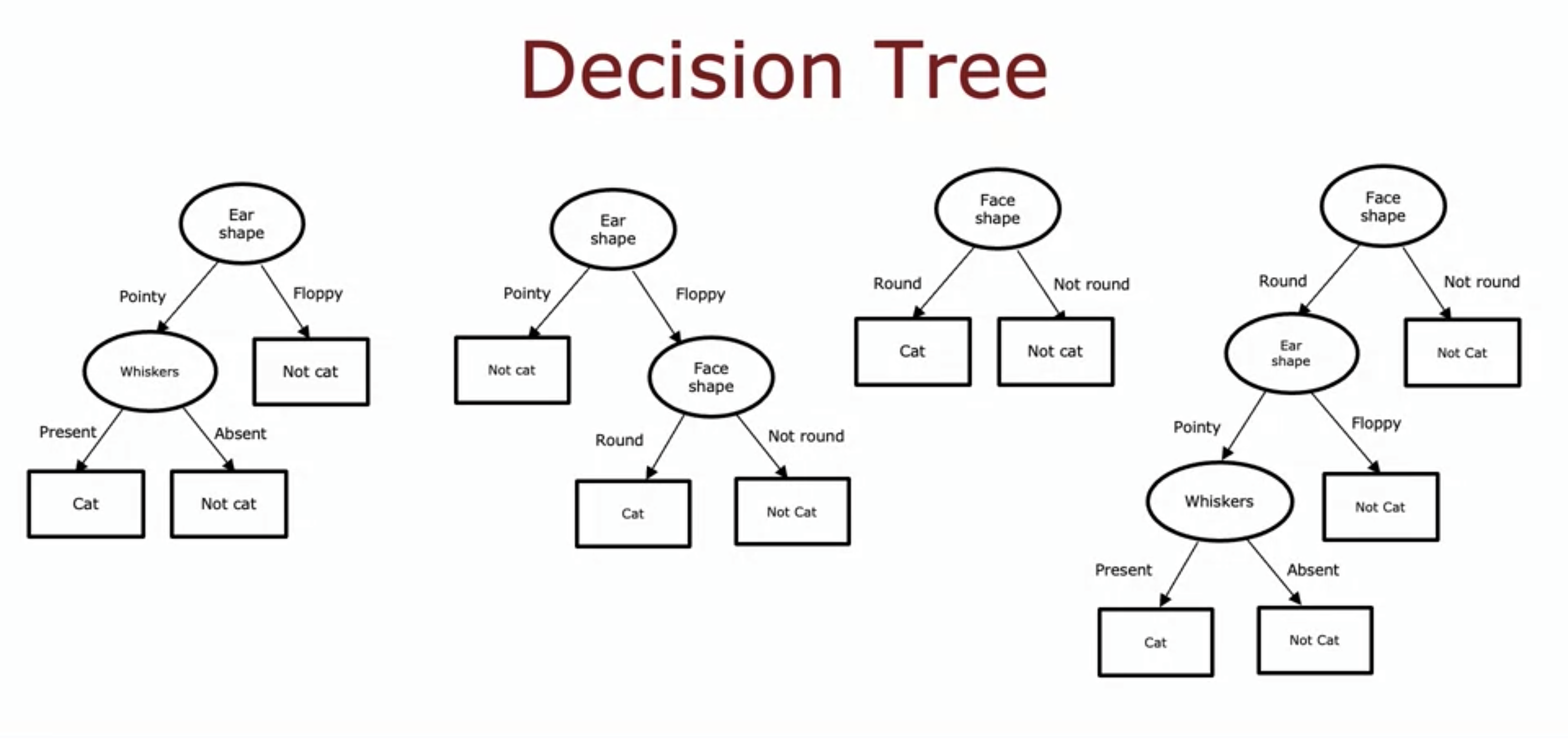
- Depending on which tree model we use, it may be working well on the data set or not.
- It is our job then to find the best fitting decision tree.
2. Learning Process
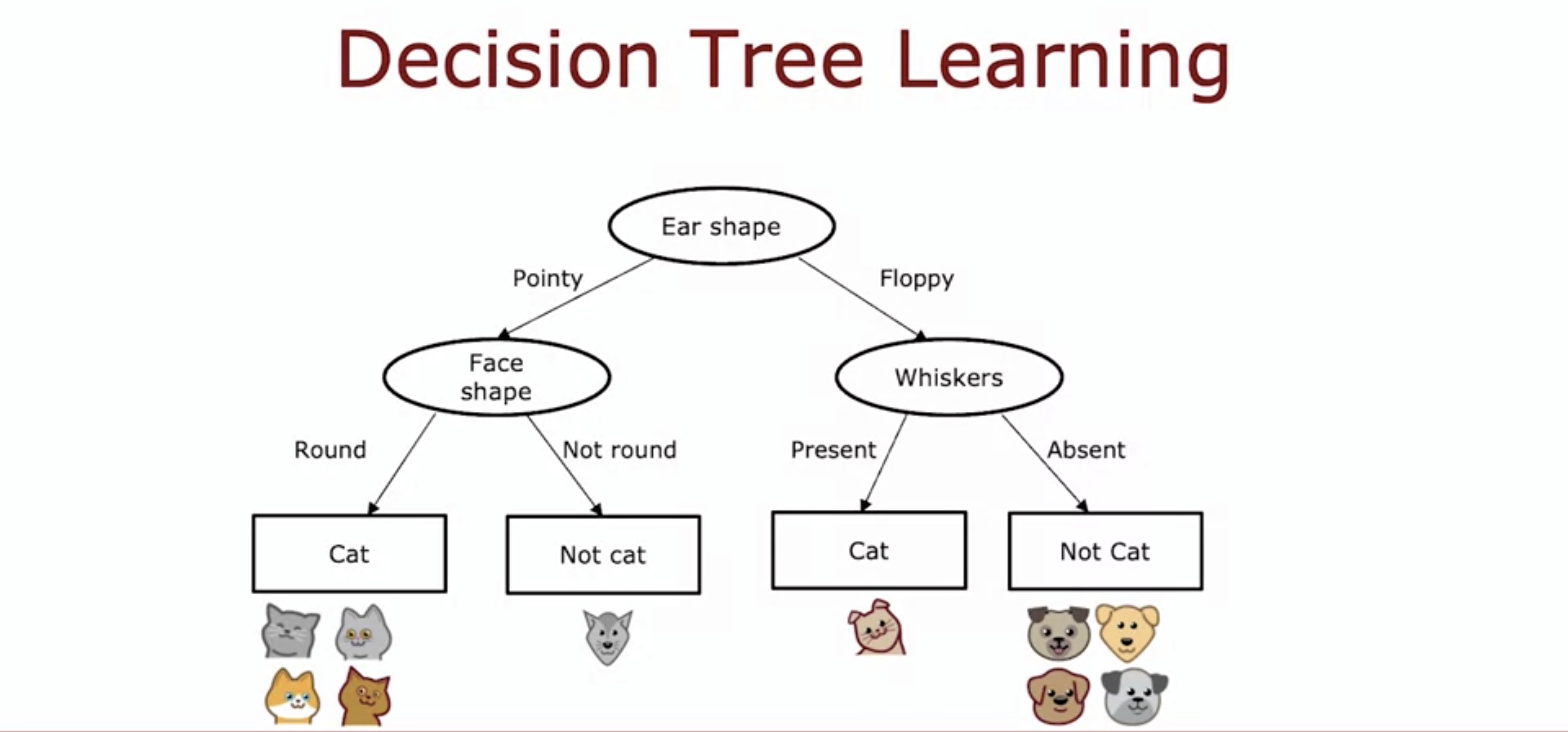
- What feature are we using as a root node?
- split the data set using the root node.
- Focus on the left node and decide which feature to put there.
- Split again using the left node.
- Splitting ends when the whole data set on the node is cat.
- Repeat on the right node.
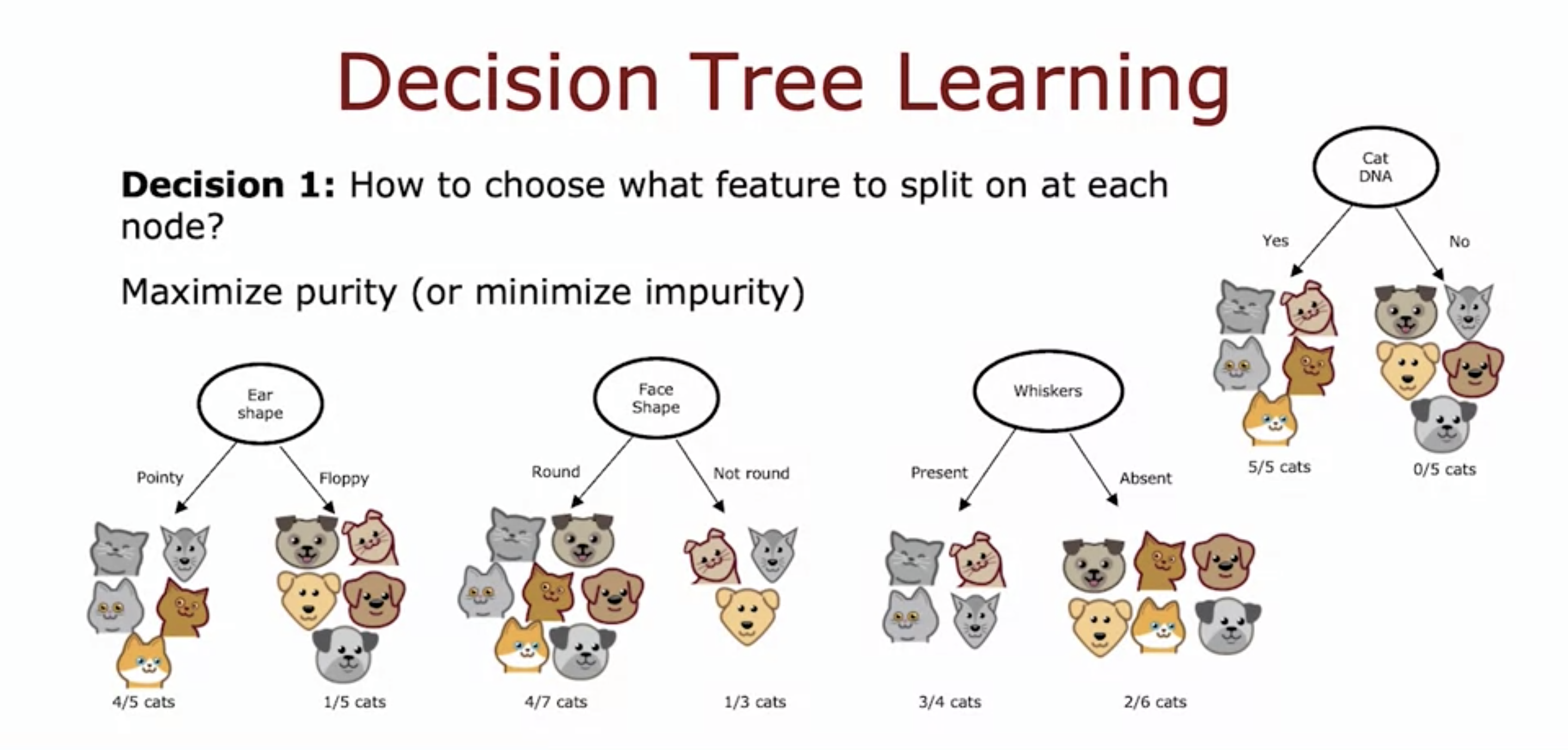
-
How do we choose which feature to use at which node?
- Decision tree chooses feature to maximize purity (there is only one class in each of the next node.)
-
We use the concept of entropy to predict the impurity of the corresponding data set.

-
When do we stop splitting?
-
When a node is 100% class
-
When splitting a node will result in exceeding the maximum depth
- The purpose of setting a maximum depth value is to make sure that the tree doesn't get too big or unwieldy,
- And to prevent overfitting.
-
When the improvement is below threshold.
- Again, to keep the tree small and prevent overfitting.
-
If the number of examples in the node is below threshold.
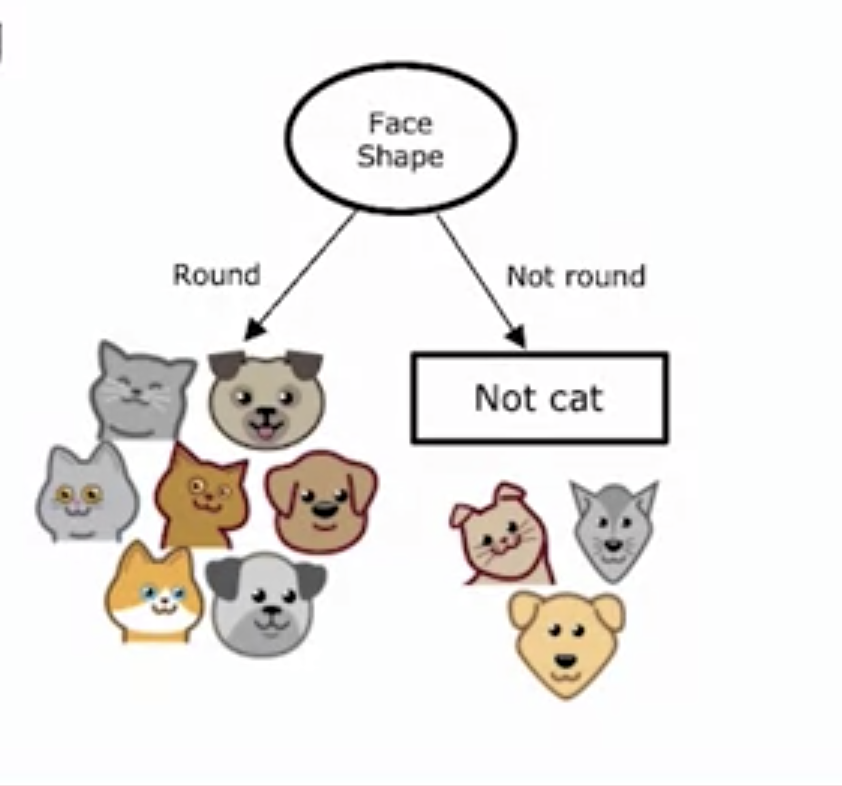
-
Since on the right now there are 2/3 dogs, and the number of examples is small, we decide that it is not cat.
-

everything happens for a reason