Sound-guided Semantic Video Generation
Multimodal (sound-image-text) embedding space를 사용하여 사실적인 Video를 생성하는 framework를 제시하고, 새로운 고해상도 풍경 video dataset (audio-visual pair)를 제세한다.
1. Introduction
기존의 Video 생성 기법은 random한 noise vector에서 처음 생성되기 때문에, 생성된 video가 semantically하게 의미있지 않다, 즉 생성된 Video의 맥락이 없다. 이러한 문제를 해결하기 위해 Sound라는 modality를 고려할 수 있는데, Sound는 video의 tone을 반영하고 있으며, 영상의 시공간적 문맥이 Sound와 깊게 연관되어 있기 때문이다.
하지만 대부분의 sound-based video 생성 method는 verbal sound(말하는 소리)에 의존하고 있으며 non-verval sound로 실감나는 video를 생성할 때는 아래와 같은 문제점들이 발생한다.
- 생성된 video의 시공간적 문맥이 sound와 일관되어야 하지만, sound와 visual은 직관적으로 연결되어 있지 않다. (하나의 sound로 여러 문맥의 영상이 존재할 수도 있다)
- 생성된 video의 움직임이 frame 사이에서 물리적으로 그럴 듯 해야한다, 즉 생성된 영상에서의 움직임들이 frame간에 자연스러워야 한다.
- 사실적인 Video 생성을 위한 non-verbal sound ↔ video pair dataset이 부족하다.
본 논문에서는 입력된 sound와 일관성 있는 영상을 생성하기 위해, Sound-encoder가 sound input을 latent space 에 넣고 처음의 latent code와의 연관성을 찾을 수 있도록 학습시키고, CLIP의 large-scale로 훈련된 multimodal embedding space과 matching하며 StyleGAN의 latent space에서 latent vector를 움직이면서 사실적인 video를 생성하도록 한다.
추가로 sound에서 의도된 궤도(frame간 연관성)를 찾는 frame generator를 제시한다. Frame generator는 coarse, mid, fine style을 예측하여 매 time별 latent vector의 nonlinear한 guidance를 제공한다. 이를 바탕으로 audio sementic meaningful하고 다양한 출력을 생성할 수 있다.
마지막으로 고해상도의 풍경 video dataset (audio-visual pairs)을 제시한다.
2. Related Work
StyleGAN Latent SPace Analysis
기존의 연구되었던 latent mapper는 noise로부터 sampling된 image와 text prompt를 pairing해주었지만, random하게 sample된 image가 실제 video처럼 연속된 동작을 가질 수 없다는 한계가 존재했다.
따라서 본 논문에서는 style latent code가 audio-visual mutimodal embedding space에서 다음 frame 생성을 위해 움직일 방향을 가르켜주는데, CLIP의 joint embedding space를 사용하여 방향을 최적화 한다.
Sound-guided Video Generation
기존의 방법론:
conditional variational autoencoder method: latent space에서 다음 video frame의 분포를 예측
본 논문에서 제시된 방법론은 음악에 국한된 sound가 아니며 user의 guidance가 노출되는 sound의 sementic을 반영한 고해상도 영상을 생성한다.
3. Sound-guided Video Generation
웃는 소리를 입력으로 넣으면 사람이 웃는 영상이 나오는 생성 모델을 만들기 위해서 모델은 두 가지 조건을 충족해야 한다.
- 입력 sound를 이해하고, trained video 생성기에 이를 반영하는 능력
→ Sound Inversion Encoder로 해결 - 사실적이며, 시간적으로 연속된 형태의 video sequence를 생성하는 능력
→ StyleGAN-based Video Generator로 해결
추가로 CLIP-based의 multimodal (image, text, audio) joint embedding space를 활용하여 입력 sound와 생성된 video간의 일관성을 유지한다.
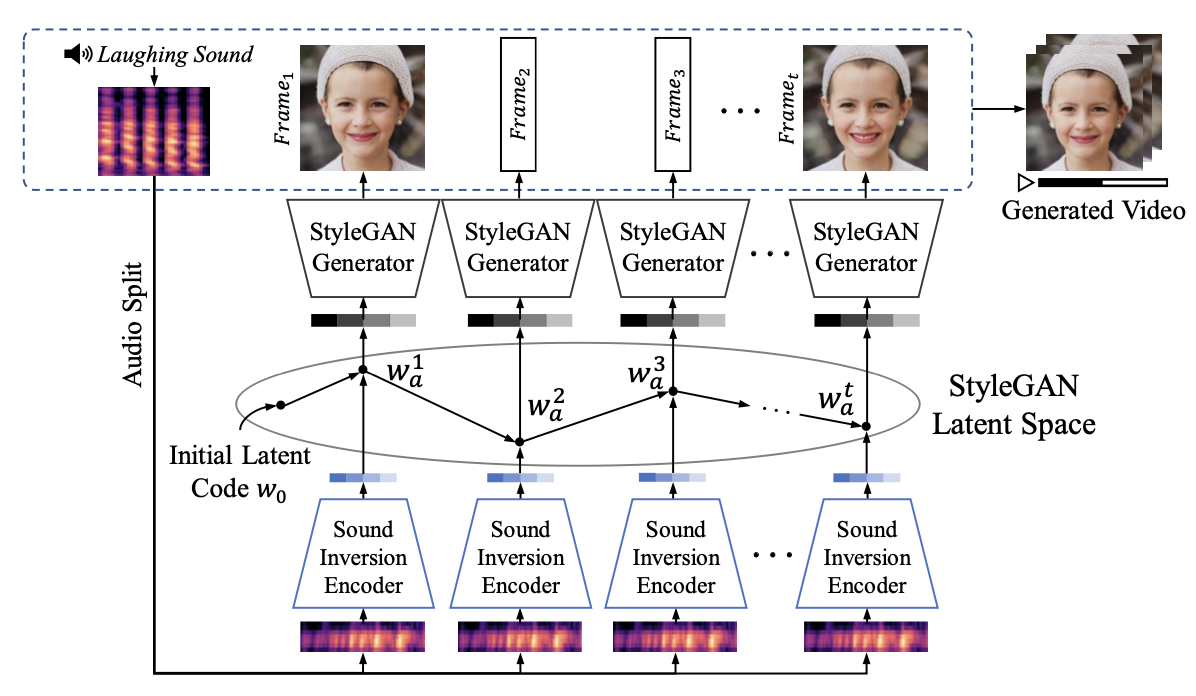
위 그림은 논문에서 제시한 sound-guided video 생성 model의 구조로, 위에서 설명한 Sound Inversion Encoder, StyleGAN-based Video Generator로 이루어져 있다.
Sound Inversion Encoder가 입력 sound를 받아서, video 생성을 위한 latent code를 생성하고, Video Generator는 Latent Space에서 넘어온 latent vector로 일괄된 frame을 생성한다.
Inverting Sound Into the StyleGAN Latent Space
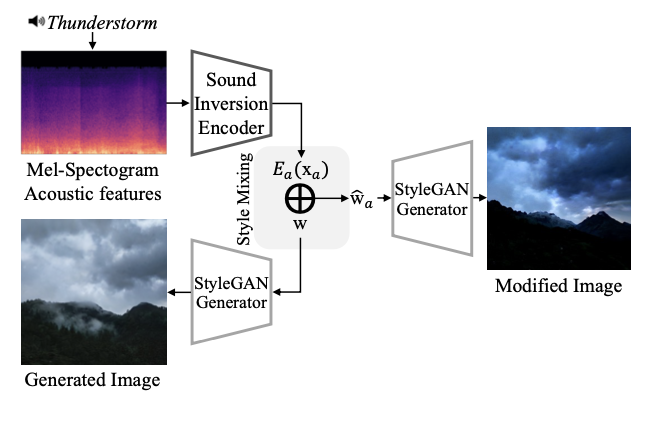
위 그림에서 보이는 것 처럼, frame 생성을 위한 sound-guided latent code는 아래 식으로 생성된다.
Sound Inversion Encoder는 로 식에서 표현되는데, Melspectrogram Acoustic feature 를 입력 받아서 pre-trained StyleGAN feature space 에 속해있는 latent feature 를 출력한다.
Encoder의 output인 는 random하게 sampling된 space상의 latent code와 행렬합 연산을 하여 최종 output인 가 된다.
Pre-trained된 CLIP-based embedding space는 positive한 triplet pair(sound, text, image가 semantic하게 같은 의미를 가짐)는 가깝게 mapping되어 있고, negative한 pair는 멀리 mapping되어 있다.
이 특징을 사용하여 latent code 로 생성된 이미지와 audio input간의 cosine 거리를 최소화 하는데 아래의 식으로 정의된다.
은 StyleGAN generator이며, 과 은 각각 CLIP의 image, audio encoder이다.
즉 Sound Inversion Encoder로 생성된 sound-guided latent code 로 생성된 이미지와, 입력 audio의 CLIP embedding space에서의 cosine 유사도를 최소화 하는 방향으로 model을 optimize할 수 있는 것이다.
위 loss function은 text↔audio간 embedding vector 비교에도 사용될 수 있는데 audio label을 text prompt로 사용하여 CLIP embedding space에서의 image와 text간 cosine 유사도를 최소화 해줄 수 있다.
따라서 Sound Inversion Encoder들의 loss식은 아래와 같이 정의되고, 이를 최소화하는 방향으로 encoder를 훈련한다.
는 로 encoder를 통해 생성된 latent code의 평균값이다. latent code의 평균값과 latent code간 거리를 loss에 포함하여, image sequence간의 유사한 semantic을 공유할 수 있도록 하였다.
Sound-guided Semantic Video Generation
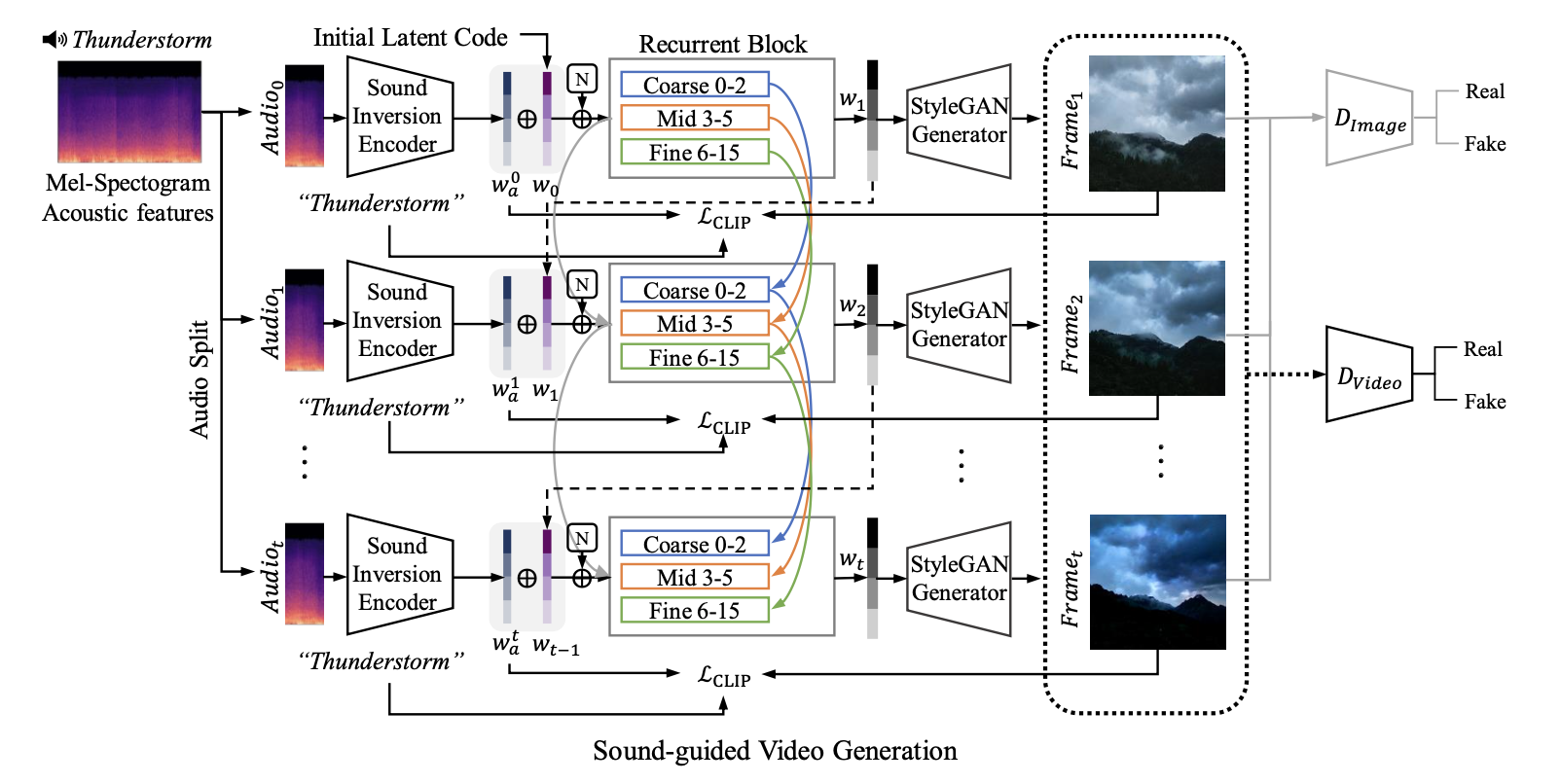
위 그림은 sound-guided video generation model의 구조도이다. Sound-Inversion Encoder는 시간 t 별로 잘라진 audio 신호를 바탕으로 latent code를 생성하고, Video generator는 이웃 fame과 일관되도록 훈련되어 반복적으로 latent code로 부터 frame을 생성한다. 추가로 image, video discriminator인 와 를 훈련하여 사실적인 video frame을 생성하도록 하였다.
각 시간별 latent vector input은 위 식과 같이 StyleGAN의 attributes를 조절하는 3개의 latent group으로 나뉜다. 은 Recurent Neural Network로 t-1시점의 latent code를 바탕으로 다음 time step의 latent code를 예측한다.
이는 앞서 설명한 것 처럼 이웃한 frame간의 연관성을 높이려고 latent space에서 각 style별로 이전 frame의 style을 반영하여 semantic한 연관성을 유지하려고 하는 시도로 보인다.
최종적으로 생성된 T 시간의 길이를 가지는 video는 아래의 식으로 정의된다.
추가로 생성된 video를 PatchGAN의 구조를 기반으로 하는 discriminator()에 forwarding하여 더 realistic한 Video를 생성하도록 한다. 또한 image discriminator를 사용하여 각 frame에도 이를 적용한다.
위 식에서 확인할 수 있듯이, model을 adversarially하게 훈련하여 생성된 이미지()를 더 실제처럼 보이게 한다. 최종적으로 위의 loss function들을 조합하여, video generation model은 아래의 loss function을 optimize하여 학습한다.
4. Experiments
Datasets
- Sub-URMP(72 video-audio pairs): 좋은 quality의 dataset이지만, video clip 수가 적고, 오케스트라 playing sound만 포함하고 있음
- High Fidelity Audio-Video Landscape Dataset (Landscape: 자체 제작): 9,280개의 clip, 총 26시간 길이의 video dataset.
Comparison to Existing Sound-guided Video Generation
- Quantitative Evaluation: Sound 정보가 video 생성에 효과적임을 증명했고, 다른 modality를 사용했을 때보다 source 정보와 더 상관성 높은 video를 생성하는 것을 확인했다.
- Evaluation Metrics: Inception Score(IS), Frechet Video Distance(FVD) 사용. 두 metrics 모두 합성된 video와 real간의 distribution gap을 측정.
- Qualitative Evaluation: TräumerAI는 realistic한 video를 생성하지 못했고, Sound2Sight나 CCVS도 distorted되었다. 반면 제시된 방법은 높은 fidelity의 영상을 생성했다.
Ablation Studies
- CLIP embedding 공간에서의 코사인 유사도를 최소화하여, inversion reconstruction performace가 향상되었다.
- StyleGAN의 attribute를 조정하는 recurrent block들 중 coarse와 middle recurrent block이 viewpoint와 semantically하게 의미있는 motion 변화를 조정하였다.
User Study
- User study에서도 여타 SOTA approach보다 훨씬 더 좋은 성능을 보였다고 한다.
Sound-guided Video Editing with Text Constraints
Text와 sound의 조합이 더 풍부한 정보를 가진 다양한 video를 생성할 수 있었다. CLIP space가 text↔image pair로 훈련되었기 때문이다.
5. Discussion
Limitations
- 생성되는 frame이 StyleGAN의 latent space에 의존적이다.
- pre-trained image generator의 weight를 필요로 하기 때문에, training 시간이 길어진다.
Personal Thoughts
Sound가 주는 암시적인 정보가 text보다 훨씬 더 다양하기 때문에, embedding space에서 더 풍부한 정보를 generator에게 전달할 수 있다는 것을 배울 수 있었다. 추가로 text와 결합하여 더 좋은 성능을 보이는 것도 확인할 수 있었는데, 최근 meta에서 발표한 ImageBind에서 보인 것 처럼 다양한 modality의 결합은 궁극적으로 더 좋은 성능으로 이끄는 것 같다.
