Soundini: Sound-Guided Diffusion for Natural Video Editing
zero-shot setting에서 Video의 특정 영역에 sound-guided visual effect를 더하는 method.
1. Introduction
Proposed method:
- Video decomposition-based:
영상에서 특정 object와 background representation을 분해하고, object를 편집한 후 video를 re-render한다. 시간적 연속성에 대한 성능은 뛰어나지만, 특정 object만 편집할 수 있다는 단점이 존재한다.
- Generative models based:
대량의 image를 GAN에 pre-train하여 특정 semantic attribute를 편집할 수 있도록 하는 방법.
위 두 방법 모두 정형화된 style과 역동적인 visual effect를 주는데 한계를 가진다.
기존의 sound가 scene을 표현할 때 가지는 이점(음색, 강도, 볼륨으로 dynamic한 context를 표현할 수 있다)를 사용하여 GAN의 latent space에서 image manipulation을 하였지만, 이러한 방식은 reconstruction과 editability간의 trade-off가 발생하기 때문에 위 논문에서는 Denoising Diffusion Probabilistic Models(DDPMs)를 사용한다.
DDPMs으로 visual effects를 추가하는 것 역시 인접 frame의 motion정보가 없기 때문에 힘든 작업이지만, 논문에서 제시하는 framework에서는 pre-trained audio latent representation을 사용하여 diffusion sampling을 진행함으로써 sound-guided motion과 appearance editing을 만들어 낸다. 또한 optical flow-based guidance를 통하여 warped frame들을 matching 시킴으로써 frame간 시간적 일관성을 유지한다.
2. Related Work
GANs을 통한 video editing 작업은 face를 editing하는데 집중하거나, GAN의 latent space domain에 의존한다는 단점이 존재하였다. 추가로 여러 domain을 활용한 video editing 연구에서는 dynamic motion을 생성하는데 실패하였지만, 최근 text-driven video diffusion model이 video editing에 좋은 성능을 보이고 있다.
Diffusion model은 noise가 포함된 image를 denoising하는 법을 학습함으로써 입력된 noise에서 이미지를 생성할 수 있다. editing된 image의 퀄리티는 이미 SOTA GAN을 넘어섰지만, 기존의 연구는 frame간 연결성을 신경쓰지 않기 때문에 편집된 시간적 일관성이 떨어진다. 본 논문에서는 optical flow guidance diffusion을 제시하여 이러한 이슈를 해결한다.
또한 sound-driven visual의 최신 연구는 joint audio-visual latent space를 사용하여 sound를 통한 이미지 합성을 수행하는데, sound의 semantic한 특성만 고려할 뿐 audio와 관련된 motion을 생성하지 못한다는 단점이 있다. 위 논문에서는 diffusion frame sampling과정에서 visual effect의 motion과 audio signal의 변화를 matching하면서 이 문제를 해결한다.
3. Method
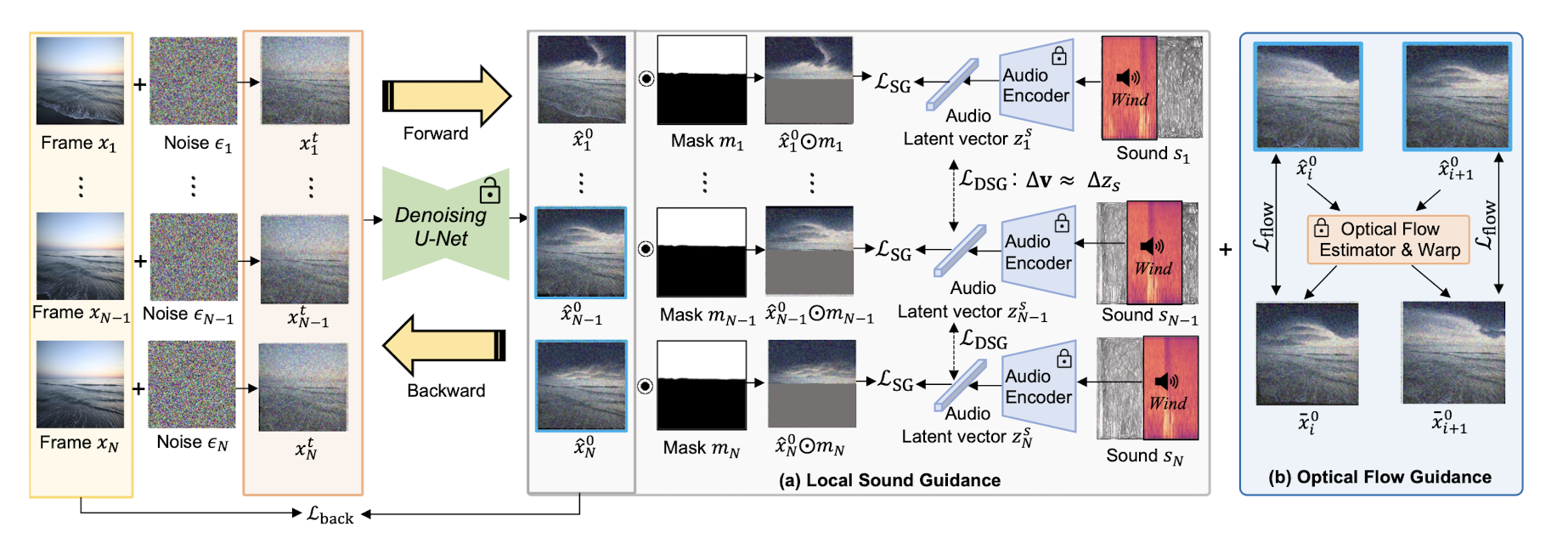
위 그림은 Soundini의 전반적인 구조로 모델의 목표는 ROI에서 sound와 일관된 방향의 visual change를 video에서 만들어내는 것이다. 위 목표를 이루기 위해 Local Sound Guidance 와 ****Optical Flow Guidence**** 두개의 guidence를 사용한다.
Local Sound Guidance
제시된 method는 DDPMs를 차용한다. Video에서 forward Markov chain은 로 i는 N개의 frame index 번호를 뜻한다. i번째 frame에 대해 data 분포가 ~ 로 주어진다면, Markov transition은 아래와 같이 정의된다.
Forward nosing process는 에서 를 아래의 식에 따라 noise를 추가하며 만들어 낸다.
~이며, , 이다. denoise후 markov chain을 생성하기 위해, 의 prior 분포를 사용하여 reverse process를 아래 식을 따라서 수행한다.
t = T, …, 1로 time step의 역순을 밟아가며 위 식이 진행된다. denoise encoder인 가 으로부터 noise가 add된 형태인 를 denoise하도록 한다. 따라서 denoising autoencoder는 을 로부터 예측할 수 있게 되고 최종적으로 예측된 은 아래 식으로 나타낼 수 있다.
Blended-diffusion은 image-text multi-modal embedding space를 사용하여 diffusion이 target prompt로 향하도록 guide한다. 이러한 접근 방식을 각 frame과 주어진 audio fragment 간의 cosine 유사도의 평균으로 확장하여 loss function()으로 본 논문에서는 채택하였다. 식은 아래와 같다.
는 CLIP의 image encoder이다. 식을 정리해보면, denoising autoencoder로 생성된 frame 에 user-input mask 연산을 수행한 image의 CLIP embedding space에서의 latent와, 같은 timeline에 존재하는 audio fragment 의 latent 간의 cosine 유사도 평균을 loss function으로 사용하여 같은 timeline에서의 sound와 생성되는 image가 matching되도록 한 것이다.
Sound와 Image의 appearance와 style을 time축에서 맞춰준 것 뿐만 아니라, visual change와 sound의 진행이 맞아 떨어지도록 새로운 loss function()를 정의하였다. 이는 아래와 같다.
는 로 계산될 수 있는데, i+1의 frame과 i frame간의 embedding space에서 latent간의 차이이다. 는 audio embedding에서의 direction으로 visual 과 audio direction사이의 cosine유사도를 최소화 하여 audio와 visual이 embedding space에서 향하는 방향이 같도록 한 것이다.
Optical Flow Guidance
합성된 동영상에서의 시간적 연속성을 위해, optical flow-based guidance를 diffusion 과정에서 제공한다.
RAFT를 사용하여 i번째, i+1번째의 양방향 optical flow를 획득하고, 각 frame을 warp하여 새로운 warped frame 을 예측된 optical flow로 생성해낸다. N개의 frame에 대해 diffusion process를 수행할 때, frame간의 mean squared loss를 계산하는데 이때 mask연산을 하여 ROI에 대해서만 guidance를 제공하는 것이 아닌 frame 전체 영역에 적용한다. 전체 영역을 고려하여 시간적으로 일관된 visual effect가 발생할 수 있기 때문이다. 식은 아래와 같다.
마지막으로 합성된 frame에서 source의 background를 유지하기 위해, 아래와 같은 식을 적용한다.
과 는 source frame에서 background의 feature를 capture한다. sampling 이후, input frame에서 masking area를 빼주어, background를 유지한다. 위의 모든 loss function을 추합하여 아래와 같이 total loss를 정의할 수 있다.
위 식의 는 각 term의 정도를 정하는 hyperparameter로 특히 를 조정하여 시간적 일관성과 dynamic한 motion간의 trade-off를 조절할 수 있었다. 를 time step t를 따라 점진적으로 증가시켜 주어 영상의 끝 부분에서 수정된 영상이 너무 못알아볼 정도가 되지 않도록 조정하였다.
4. Result
Qualitative Analysis
- Sound의 semantic한 변화에 따라 Video의 특정 region도 함께 변하는 editing이 가능했다.
- Sound의 volumn변화도 video editing에 반영되었다. volumn이 커질수록 sound editing의 반영이 더 잘되었다.
- Neural Layerd Atlases(NLA)와 비교했을 때 더 사실적이고 자연스러운 결과를 출력했다.
- 다른 SOTA model들이 하지 못하는 sound transition이나 volumn과 연결된 image editing을 수행했다.
- Video editing시 특정 영역에서의 수정이 전체 영상의 맥락과 일치하도록 영상이 편집된다.
- Video에서의 mask영역만이 아닌 global area 또한 입력된 sound의 맥락에 맞게 수정할 수 있다.
Quantitative Evaluation
- Neural Layerd Atlases(NLA), Blended Diffusion, VQGAN+CLIP 세 모델과 비교.
- 제시된 모델의 optical flow guidance가 높은 시간적 일관성을 유지하도록 하였다.
- baseline보다 더 높은 quality의 video를 출력해냈다.
- 더 높은 semantic한 일관성을 가진 video 출력 (CLIP score: embedding space에서 cosine 유사도 계산)
5. Discussion
Limitation
- mask shape과 주어진 mask area에서 editing하려는 object가 sound의 content와 잘 matching되어야 editing이 수월하게 발생한다.→ 인접 frame을 pixel단위로 처리하기 때문이다.
Personal Thought
Sound의 semantic한 특성 뿐만 아니라 시간 축 상에서의 sound의 변화도 video editing에 반영될 수 있도록 한 것이 main contribution인 것 같다. editing시 source의 consistency를 유지하면서 dynamic한 motion 변화를 이끌어 내도록 하는 hyperparameter를 찾아내는 것이 관건이었을 것 같고, hyperparameter의 변화량 정도가 서로 다른 source 영상에 대해 동일하게 적용되는지 의문이 생겼다.
