
1. Logistic Regression
1.1 Training/Validation/Testing Data
훈련, 검증, 테스트 데이터로 나눠야하는 이유:
- Training(훈련): 훈련 데이터를 기준으로 모델을 학습(Fit)시킨다. Construct classifier.
- Validation(검증): 훈련한 모델의 유효성을 확인한다. 마지막으로 시험치기 전에 성능을 확인하거나 향상시키는 방법. 예측의 오류(Residual)를 측정한다. 수능을 치기 전에 모평을 치는 느낌?! Pick algorithm and Knob the settings.
- Testing(테스트): 훈련한 모델의 성능이 좋은지, 안 좋은지 확인하는 데이터(Score), 마지막에 딱 한번만 사용한다. Estimate future error rate.
Kaggle(캐글)이 테스트 데이터를 제공하지 않는 이유:
- 모델의 일반화 성능을 올바르게 측정하기 위해서. 타겟 값까지 알려주면 그것을 토대로 사용자들이 모델의 성능을 향상시킬 수 있음.(답을 알려주고 학습시키는...)
+ 데이터 누수(Data Leakage)
의미: 학습을 시키려는 모델이 이미 타겟 값(일종의 정답)을 알고 있는 경우.
문제점: 수능 시험을 치는데 문제와 답이 유출되었다!!! 어떻게 되나? 난리난다.... 이런 느낌과 비슷..
모델이 이미 정답을 알고 있기 때문에 과적합(Overfitting) 문제나, 잘못된 모델이 만들어질 수 있다. 그러면 문제를 해결하거나, 예측을 하는 데에 오류가 발생할 수밖에 없을 것.... ㅜㅜ
1.2 Classification
1.2.1 BaseLine
분류 문제는 회귀문제와 다른 기준으로 기준 모델(Baseline)을 설정한다
- 회귀(Regression): 타겟의 평균 값
- 시계열(Timeseries): 이전 타임 스탬프 값
- 분류(Classification): 타겟의 최빈 값 - 타겟으로 많이 등장하는 값으로만 찍어도 절반은 간다. 예) 동전 던지기 - 앞면 절반만 찍어도 절반은 가고, 가위바위보는 0.333 으로만 찍어도 절반은 간다.
그렇기에 분류 문제에서는 타겟이 어떻게 나오는지(어떤 비율로 나오는지) 먼저 확인을 해봐야한다.
1.2.2 Evaluation metrics
회귀와 다른 평가 지표를 사용해야 한다!! 왜냐하면 회귀와 분류 모델이 가지는 목적이 서로 다르기 때문
- 회귀: R-squared, MAE, MSE, RMSE
- 분류: Accuracy(정확도 - 예측 값과 실제 값을 비교해서 얼마나 잘 맞췄는지 비교하는 점수), Precision, Recall, f1_score 등등이 있다.
Accuracy = 올바르게 예측한 수 / 전체 예측한 수 = (TP+TN) / (P+N)
1.3 Logistic Regression
로지스틱 회귀는 독립 변수의 선형 결합을 활용해 사건의 발생 가능성을 예측한다. 다음 그림과 같이 보통 그래프를 그린다... 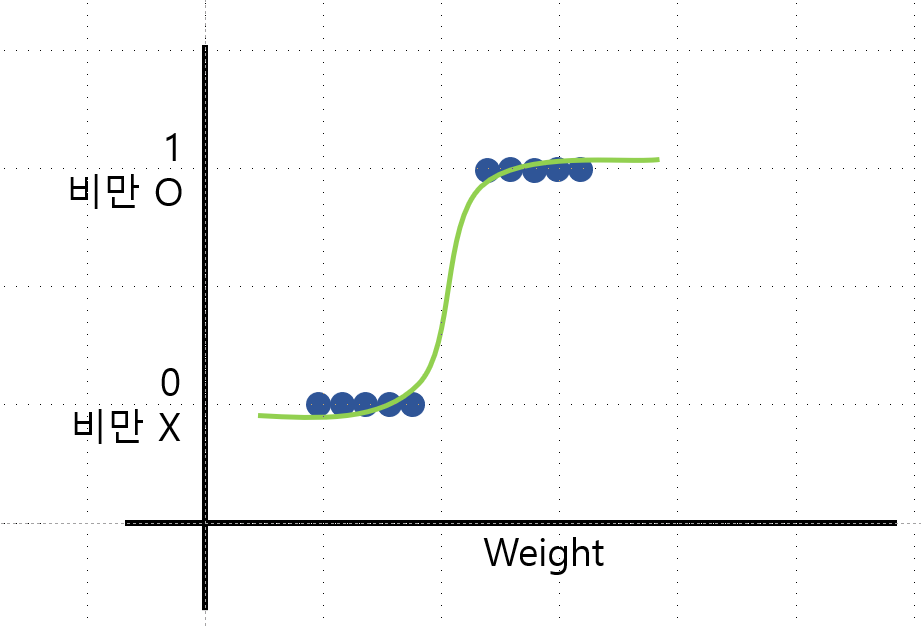 y축을 잘 보면 알겠지만 연속형 Data가 아니라 T/F로 표현할 수 있는 data다. (3개 이상도 표현 가능하다)
y축을 잘 보면 알겠지만 연속형 Data가 아니라 T/F로 표현할 수 있는 data다. (3개 이상도 표현 가능하다)
Regression 으로 표현이 되어 있지만, 실제로는 분류를 하는 지도 학습 모델이다. 샘플이 특정한 범주에 속할 확률을 추정한다!
1.4 Odds
- 오즈(Odds)를 사용해서 로지스틱 회귀의 계수를 직관적으로 이해할 수 있다.
- Odds = p/(1-p) p: 성공확률, 1-p: 실패확률. 성공확률이 실패확률에 비해 몇 배 더 높은가를 직관적으로 알 수 있다! 따라서 p=1이면 Odds는 무한대로 수렴하고, p=0이면 Odds는 0이 된다.
- 오즈에 로그를 취해 변환하는 것을 로짓변환(Logit Transformation)이라고 한다. 비선형 형태인 로지스틱 함수 그래프를 선형, 일자로 쭉 펴준다. 그래서 X의 특성에 따라 로짓이 얼마나 증가/감소 여부를 해석할 수 있게 된다.
+ PipeLine and Leakage prevention
- PipeLine: 코드 간소화. fit과 transformation을 여러 번 하는 경우.. (One_hot_encoding, impute, scaling, modeling, train, test 등등)에 반복적으로 사용하는 코드를 Pipeline으로 해결할 수 있다. 여기서 중요한 것은 실행하는 순서!!
- Leakage prevention: 데이터의 누수를 방지하기 위해서 사용한다. 즉, Test 데이터가 Train으로 흘러가지 않도록..!! 데이터 누수의 중요성은 위에서 이미 언급해두었다!

안녕하세요.