
📖 04장. 신경망 시작하기: 분류와 회귀
🗝️ 핵심내용
- 실제 머신 러닝 워크플로의 첫 번째 예제
- 벡터 데이터를 사용한 분류 문제 처리하기
- 벡터 데이터를 사용한 연속적인 회귀 문제 처리하기
📑 뉴스 기사 분류: 다중 분류 문제
로이터에서 공개한 짧은 뉴스 기사와 토픽의 집합인 로이터 데이터셋을 이용하여 총 46개의 토픽을 분류하는 다중 분류 모델을 알아보자.
로이터 데이터셋
# 로이터 데이터셋 로드하기
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(
num_words=10000)
print(train_data[0]) # [1, 2 ... 15, 17, 12]
print(train_labels[0]) # 3IMDB 데이터셋과 마찬가지로 각 단어 시퀀스가 사전에 따라 숫자 시퀀스로 변환되어 있다.
데이터 준비
# 데이터 인코딩하기
import numpy as np
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1
return results
x_train = vectorize_sequence(train_data)
x_test = vectorize_sequence(test_data)
print(x_train.shape) # (8982, 10000)영화 리뷰 분류 문제와 마찬가지로 각 숫자 시퀀스의 길이가 다르기 때문에 신경망 학습에 사용하기 위해 멀티-핫 인코딩(multi-hot enconding) 작업을 해주어야 한다.
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
print(y_train.shape) # (8982, 46)또한, 이진 분류 문제와 달리 다중 분류 문제의 경우 레이블이 여러개 존재하기 때문에 이 또한 학습에 사용하기 위해 원-핫 인코딩(one-hot encoding) 처리를 해주어야 한다. 원-핫 인코딩 작업을 거치면 0~45의 값이 들어있던 1차원 텐서가 각 레이블의 인덱스 자리가 1이고 나머지는 0인 벡터로 변환된다.
모델 구성
# 모델 정의하기
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(46, activation='softmax')])신경망 모델의 경우 이진 분류 모델과 크게 다르지 않지만 한가지 유의해야 할 점으론 출력 클래스의 개수가 2개에서 46개로 크게 늘어난 점이다. 이때 Dense 층에 적은 유닛의 개수를 지정하면 적은 차원의 공간은 46개의 클래스를 구분하기에 너무 많은 제약이 있을 것이다. 이렇게 되면 차원의 공간이 적은 층은 일부 정보를 누락할 수 있고, 그 층은 정보의 병목(information bottleneck)이 될 수 있으므로 여러개의 클래스를 구분하기에 충분한 차원의 공간을 지정해주어야 한다.
또한 각 입력 샘플마다 46개의 출력 클래스에 대한 확률 분포를 출력하기 위해 활성화 함수로는 softmax 함수를 사용한다.
# 모델 컴파일하기
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])이러한 다중 분류 문제에서는 손실 함수로 categorical_crossentropy 함수를 사용하고, 이때 이 함수는 두 확률 분포 사이의 거리를 측정한다.
# sparse_cross_entropy
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])이때 sparse_categorical_crossentropy 함수를 사용할 수 있는데, 이 함수는 기능은 같지만, 지금처럼 레이블에 대해 따로 원-핫 인코딩 처리를 하지 않고 정수형 레이블을 입력할 때 사용할 수 있다.
훈련 검증
# 검증 세트 준비하기
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]다중 분류 문제도 마찬가지로 모델을 검증하기 위해 훈련 데이터에서 1,000개의 데이터를 분리하여 검증에 사용할 것이다.
# 모델 훈련하기
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 50ms/step -
# accuracy: 0.9591 - loss: 0.1236 - val_accuracy: 0.8000 - val_loss: 0.9757이렇게 훈련한 결과로 history 객체에 저장되어 있는 정확도와 손실을 가지고 그래프를 나타내보자.
# 훈련과 검증 손실 그리기
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label="Training loss")
plt.plot(epochs, val_loss_values, 'b', label="Validation loss")
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()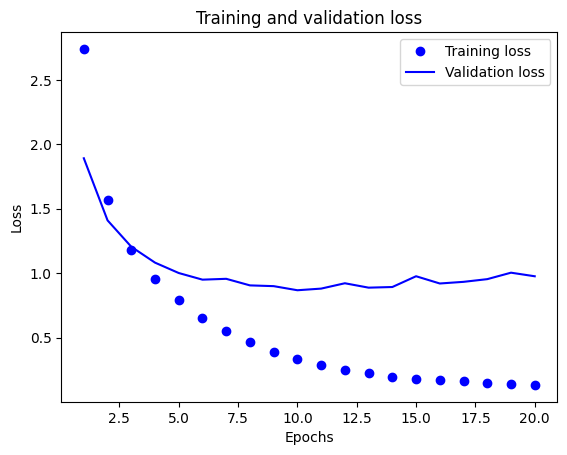
# 훈련과 검증 정확도 그리기
plt.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()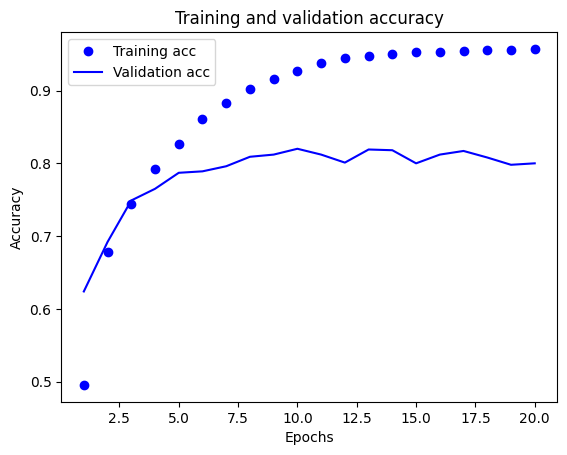
그래프를 그려본 결과 이번 모델도 10번의 에포크 이후로 과대적합(overfitting)이 발생하여 새로운 데이터에 대한 예측의 정확도가 떨어지는 것을 볼 수 있다.
# 모델 처음부터 다시 훈련하기
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train,
y_train,
epochs=10,
batch_size=512)
print(model.evaluate(x_test, y_test)) # [0.901971697807312, 0.7974176406860352]최대 에포크를 10으로 지정한 뒤 모델을 다시 훈련해본 결과 정확도 약 80%를 달성한 것을 볼 수 있다.
새로운 데이터에 대해 예측하기
# 새로운 데이터에 대해 예측하기
predictions = model.predict(x_test)
print(predictions[0].shape) # (46,)
print(np.sum(predictions[0])) # 1.0
print(np.argmax(predictions[0])) # 3이렇게 학습한 모델에 새로운 데이터를 주입하여 각 데이터에 대한 예측값을 볼 수 있는데, 이때 각 예측값은 총 합이 1인 46개의 확률 분포를 가지고 있다. 여기서 가장 큰 값(확률이 가장 높은 값)이 최종 예측 값이 된다.
충분히 큰 중간층을 두어야 하는 이유
# 정보 병목이 있는 모델
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(4, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 47ms/step -
# accuracy: 0.7296 - loss: 1.0482 - val_accuracy: 0.6590 - val_loss: 1.3782앞서 말한 정보 병목에 대해 다시 예제 코드로 조금 더 알아보자. 앞서 훈련한 모델의 중간층은 64개의 유닛을 가지고 있었는데 반해, 현재 모델은 일부로 4개의 유닛만 가지도록 구성하였다. 이러한 모델을 훈련시킨 결과, 검증 정확도는 처음 모델의 약 80%에서 약 65%까지 감소된 것을 볼 수 있고, 이는 중간층의 유닛의 개수가 충분히 크지 않아 일부 레이블에 대한 정보가 누락된 것이라고 볼 수 있다.
📑 추가 실험
층의 유닛 추가하거나 줄여보기
# 층의 유닛 추가하거나 줄여보기
model = keras.Sequential([
layers.Dense(128, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 3s 87ms/step -
# accuracy: 0.9615 - loss: 0.1116 - val_accuracy: 0.8100 - val_loss: 0.9845
print(model.evaluate(x_test, y_test)) # [1.07719886302948, 0.7943009734153748]
model = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 39ms/step -
# accuracy: 0.9431 - loss: 0.2432 - val_accuracy: 0.8050 - val_loss: 0.9496
print(model.evaluate(x_test, y_test)) # [1.0214990377426147, 0.7751558423042297]1개 또는 3개의 훈련 층 사용
# 1개 또는 3개의 훈련 층 사용
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 61ms/step -
# accuracy: 0.9584 - loss: 0.1490 - val_accuracy: 0.8310 - val_loss: 0.8034
print(model.evaluate(x_test, y_test)) # [0.8978724479675293, 0.8067675828933716]
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(46, activation='softmax')])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 54ms/step -
# accuracy: 0.9600 - loss: 0.1194 - val_accuracy: 0.8060 - val_loss: 1.1138
print(model.evaluate(x_test, y_test)) # [1.2255284786224365, 0.7756010890007019]🔗 출처
https://www.gilbut.co.kr/book/view?bookcode=BN003496
