
📖 04장. 신경망 시작하기: 분류와 회귀
🗝️ 핵심내용
- 실제 머신 러닝 워크플로의 첫 번째 예제
- 벡터 데이터를 사용한 분류 문제 처리하기
- 벡터 데이터를 사용한 연속적인 회귀 문제 처리하기
📑 영화 리뷰 분류: 이진 분류 문제
인터넷 영화 데이터베이스로부터 가져온 양극단의 리뷰 5만개로 이루어진 IMDB 데이터 셋을 이용하여 리뷰 텍스트를 기반으로 영화 리뷰를 긍정과 부정으로 분류하는 이진분류를 배워보자.
IMDB 데이터 셋
# IMDB 데이터 셋 로드하기
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0]) # [1, 14, 22 ... 19, 178, 32]
print(train_labels[0]) # 1케라스에 포함되어 있는 IMDB 데이터 셋은 이미 전처리되어 있어 각 리뷰(단어 시퀀스)가 사전에 있는 고유한 단어를 나타내는 숫자 시퀀스로 변환되어 있다.
# 리뷰를 다시 텍스트로 디코딩하기
word_index = imdb.get_word_index()
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
decoded_review = " ".join(
[reverse_word_index.get(i - 3, "?") for i in train_data[0]])
print(decoded_review) # ? this film was ...that was shared with us all단어와 정수 인덱스를 매핑한 딕셔너리를 호출하여 텍스트로 변환해보면 실제로 영화 리뷰를 나타내는 문장이 출력되는 것을 볼 수 있다.
데이터 준비
이렇게 받아온 숫자 리스트를 바로 신경망에 주입할 수는 없는데, 각 숫자 리스트의 길이가 모두 다르기 때문이다. 이때 두가지 방법으로 동일한 크기의 텐서로 변환할 수 있는데,
- 같은 길이가 되도록 패딩(padding) 처리를 한다. 이때 변환된 텐서의 크기는
(25000, 2494)가 된다.- 리스트를 멀티-핫 인코딩(multi-hot encoding)하여 0과 1의 벡터로 변환한다. 이때 변환된 텐서의 크기는
(25000, 10000)이 된다. (데이터를 불러올 때 등장하는 빈도에 따라 10,000개로 제한했기 때문이다.)
여기서는 두번째 방식을 사용하여 데이터를 벡터로 변환해보자.
# 정수 시퀀스를 멀티-핫 인코딩으로 인코딩하기
import numpy as np
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1
return results
x_train = vectorize_sequence(train_data)
x_test = vectorize_sequence(test_data)
print(x_train.shape) # (25000, 10000)크기가 (25000, 10000)이고 모두 0으로 이루어진 넘파이 배열을 생성한 뒤, 각 숫자 리스트의 원소의 인덱스의 위치를 1로 만들면 된다.
# 레이블을 벡터로 변환
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print(y_train[0]) # 1.0
print(y_train.shape) # (25000,)레이블 또한 0과 1로 나누어지는 이진 분류 문제이므로 0과 1로 이루어진 벡터로 쉽게 변환시킬 수 있다.
신경망 모델 만들기
이제 데이터가 준비되었고 신경망 모델을 만들 차례이다. Dense 층을 쌓을 때 고려해야 할 사항이 몇가지 있다.
- 얼마나 많은 층을 쌓을 것인가?
- 각 층에 얼마나 많은 유닛을 둘 것인가?
# 모델 정의하기
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])우선 이 문제에 대해선 16개의 유닛을 가진 2개의 은닉 층(hidden layer)와 리뷰의 감정을 스칼라 값의 예측으로 출력하는 마지막 층으로 구성할 것이다.
이때 유닛의 수를 잘 설정해야 하는데, 유닛을 늘리면(표현 공간을 더 고차원으로 만들면) 더욱 복잡한 표현을 학습할 수 있지만 계산비용이 커지고 원하지 않는 패턴까지 학습할 수도 있다. (Overfitting 정도가 커질 수 있다.)
# 모델 컴파일하기
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']) 마지막으로 손실함수와 옵티마이저를 선택해야 한다. 여기선 일반적으로 거의 모든 문제에 기본 선택으로 좋은 rmsprop 옵티마이저와 현재 확률을 출력하는 모델을 사용하고 있으므로 bianry_crossentropy 손실함수를 사용할 것이다.
훈련 검증
# 검증 세트 준비하기
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]모델을 검증할 때는 반드시 훈련에서 사용하지 않은 새로운 데이터를 가지고 검증해야 한다. 여기서는 원본 데이터에서 10,000개의 데이터를 추출하여 사용하였다.
# 모델 훈련하기
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 28ms/step -
# accuracy: 0.9985 - loss: 0.0116 - val_accuracy: 0.8713 - val_loss: 0.5678이제 모델을 훈련하기 위한 모든 준비를 마쳤으니 모델을 훈련할 차례이다. 이렇게 구성한 모델을 훈련시킨 결과 검증 정확도와 검증 손실이 각각 약 0.87, 0.57로 도출된 것을 볼 수 있다.
이제 각 에포크마다 훈련 손실, 정확도와 검증 손실, 정확도의 변화를 그래프로 확인해보자.
# 훈련과 검증 손실 그리기
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label="Training loss")
plt.plot(epochs, val_loss_values, 'b', label="Validation loss")
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()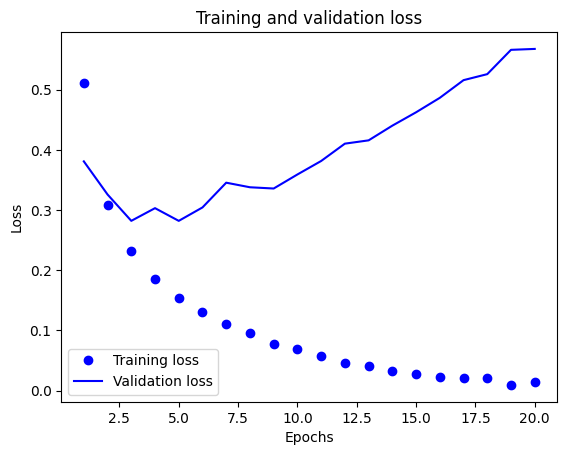
# 훈련과 검증 정확도 그리기
plt.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()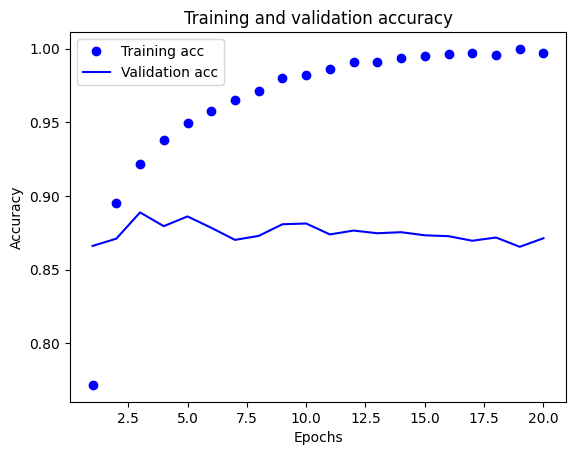
그래프로 확인해본 결과 훈련 데이터에 대한 손실과 정확도는 이상적으로 0과 1에 근사하는 반면, 검증 데이터에 대한 손실과 정확도는 특정 에포크(여기서는 3)을 이후로 점점 역전되는 것을 볼 수 있다.
이는 모델이 훈련 데이터에 과도하게 최적화되어 과대적합(Overfitting) 정도가 너무 커져 일반적인 데이터는 잘 예측하지 못하는 현상이 발생한 것이다.
그렇다면 세 번의 에포크만 훈련해보고 모델을 평가해보자.
# 모델을 처음부터 다시 훈련하기
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=3, batch_size=512)
print(model.evaluate(x_test, y_test)) # [0.2863631546497345, 0.8836399912834167]예상대로 검증 손실과 정확도가 향상된 것을 확인할 수 있다.
이렇게 훈련된 모델에 테스트 데이터를 예측해보자.
# 훈련된 모델로 새로운 데이터 예측하기
print(model.predict(x_test))
# [[0.21212997]
# [0.9997897 ]
# [0.6856325 ]
# ...
# [0.11690941]
# [0.08786383]
# [0.4185627 ]]이렇게 테스트 데이터에 대해 예측해본 결과 각 데이터에 대한 확률값을 출력하며, 이는 0과 1에 가까울 수록 얼마나 모델이 확신하는지 정도를 알 수 있다.
📑 추가 실험
1개 또는 3개의 훈련 층 사용
# 1개 또는 3개의 훈련 층 사용
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 39ms/step -
# accuracy: 0.9924 - loss: 0.0539 - val_accuracy: 0.8757 - val_loss: 0.365
print(model.evaluate(x_test, y_test)) # [0.38974112272262573, 0.8660399913787842]
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 33ms/step -
# accuracy: 0.9999 - loss: 0.0041 - val_accuracy: 0.8711 - val_loss: 0.6531
print(model.evaluate(x_test, y_test)) # [0.7019034624099731, 0.8586000204086304]층의 유닛 추가하거나 줄여보기
# 층의 유닛 추가하거나 줄여보기
model = keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 4s 89ms/step -
# accuracy: 0.9893 - loss: 0.0353 - val_accuracy: 0.8738 - val_loss: 0.6070
print(model.evaluate(x_test, y_test)) # [0.6481730341911316, 0.8632400035858154]
model = keras.Sequential([
layers.Dense(8, activation='relu'),
layers.Dense(8, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 28ms/step -
# accuracy: 0.9939 - loss: 0.0368 - val_accuracy: 0.8745 - val_loss: 0.4251
print(model.evaluate(x_test, y_test)) # [0.46115225553512573, 0.8644400238990784]mse 손실함수 사용해보기
# mse 손실함수 사용해보기
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='mse',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 29ms/step -
# accuracy: 0.9910 - loss: 0.0118 - val_accuracy: 0.8692 - val_loss: 0.1009
print(model.evaluate(x_test, y_test)) # [0.1099785640835762, 0.8566799759864807]tanh 활성화 함수 사용해보기
# tanh 활성화 함수 사용해보기
model = keras.Sequential([
layers.Dense(16, activation='tanh'),
layers.Dense(16, activation='tanh'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# Epoch 20/20
# 30/30 ━━━━━━━━━━━━━━━━━━━━ 1s 29ms/step -
# accuracy: 0.9997 - loss: 0.0042 - val_accuracy: 0.8665 - val_loss: 0.6708
print(model.evaluate(x_test, y_test)) # [0.734409749507904, 0.8532400131225586]🔗 출처
https://www.gilbut.co.kr/book/view?bookcode=BN003496
