

📚 Data Preprocessing
데이터 분석 및 머신러닝의 정확도는 분석 데이터의 품질에 좌우된다. 데이터 품질을 높이기 위해서는 누락데이터(결측치), 비정상데이터(이상치), 중복데이터 등의 오류를 수정하고 분석 목적에 맞게 변형하는 과정이 필수인데, 이를 Data Preprocessing이라 한다.
-
데이터 수집 (Data Collection) : 데이터 수집은 전처리 과정의 첫번째 단계로, 다양한 출처에서 데이터를 수집하는 과정이다. 데이터는 Database, CSV파일, 웹 스크래핑, API 등을 통해 수집할 수 있다.
-
데이터 정리 (Data Cleaning) : 데이터 정리는 데이터의 전처리의 중요한 단계 중 하나로, 데이터 셋 내의 오류나 불완전한 데이터를 식별하고 제거 또는 수정하는 과정이다.
-
결측값 처리 (Missing Values Handling)
- 삭제 (Drop) : 결측값이 있는 행이나 열을 제거한다. 데이터가 충분히 많고, 결측값이 적은 경우에 유용하다.
- 대체 (Impute) : 결측값을 다른 값(평균, 중앙값, 최빈값 등)으로 대체한다.
-
이상치 처리 (Outlier handling)
- 이상치는 데이터 셋의 패턴과 맞지 않는 극단적인 값이다.
- 이상치를 처리하는 방법으로는 제거하거나, 특정 값으로 대체하거나, 변환(ex. 로그 변환)하는 방법이 있다.
-
중복 데이터 제거 (Duplicate Removal)
- 중복된 행을 제거하여 데이터의 정확성을 높인다.
- 데이터 변환 (Data Transformation) : 데이터 변환은 데이터를 분석하기 쉽게 변형하는 과정이다.
-
데이터 인코딩 (Data Encoding)
- 레이블 인코딩 (Label Encoding) : 범주형 데이터를 숫자로 변환한다.
- 원-핫 인코딩 (One-Hot Encoding) : 범주형 데이터를 이진 벡터로 변환한다.
-
특징 생성 (Feature Engineering)
- 새로운 피처를 생성하여 모델의 예측력을 높이는 과정이다.
- 예를 들어, 날짜 데이터를 년, 월, 일로 분리하거나 수익률같은 유용한 파생 변수를 생성할 수 있다.
- 피처 스케일링 (Feature Scaling) : 피처 스케일링은 모든 특성(feature)을 같은 크기 범위로 맞추는 과정이다. 이는 거리 기반 알고리즘(k-NN, SVM 등)에서 특히 중요하다.
- 표준화 (Standardization)
- 데이터를 평균 0, 표준편차 1로 변환한다.
- 정규화 (Normalization)
- 데이터를 0과 1 사이의 범위로 스케일링한다.
- 데이터 분할 (Data Splitting) : 데이터를 훈련세트(Training Set)와 테스트세트(Test Set)로 나누는 과정이다. 모델을 훈련시키고 평가하는 데 사용된다. 일반적으로 훈련세트는 70-80%, 테스트세트는 20-30%로 나눈다.
📚 결치값 처리
결치값이 많아지면 데이터의 품질이 떨어지고 머신러닝 알고리즘을 왜곡하는 현상이 발생하기 때문에 제거하거나 적절한 값으로 대체하는 과정이 필요하다.
데이터가 충분히 많다면 삭제가 가장 좋은 방법이다.
seaborn module에서 제공하는 titanic 데이터 셋을 이용하여 알아보자.
import seaborn as sns
# titanic data set
df = sns.load_dataset('titanic')
display(df.head())
결치값 확인
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 891 entries, 0 to 890
# Data columns (total 15 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 891 non-null int64
# 1 pclass 891 non-null int64
# 2 sex 891 non-null object
# 3 age 714 non-null float64
# 4 sibsp 891 non-null int64
# 5 parch 891 non-null int64
# 6 fare 891 non-null float64
# 7 embarked 889 non-null object
# 8 class 891 non-null category
# 9 who 891 non-null object
# 10 adult_male 891 non-null bool
# 11 deck 203 non-null category # 688개의 결치값 확인
# 12 embark_town 889 non-null object
# 13 alive 891 non-null object
# 14 alone 891 non-null bool
# dtypes: bool(2), category(2), float64(2), int64(4), object(5)
# memory usage: 80.7+ KBDataFrame의 요약정보를 출력한다. RangeIndex : 891이기 때문에 각 열에 891개의 데이터가 있는 것을 알 수 있다. 이때, deck 열에 203개의 유효한 데이터가 있는 것을 볼 수 있는데, 이는 688개(891 - 203 = 688)의 결치값이 존재하는 것을 확인할 수 있다.
print(df['deck'].value_counts(dropna=False))
# deck
# NaN 688
# C 59
# B 47
# D 33
# E 32
# A 15
# F 13
# G 4
# Name: count, dtype: int64이때 value_counts() 함수에 dropna 인자를 False로 전달하면 NaN(결치값)이 688개 존재하는 것을 확인할 수 있다.
display(df.isnull()) # notnull()도 있다.
display(df.isnull().sum(axis=0))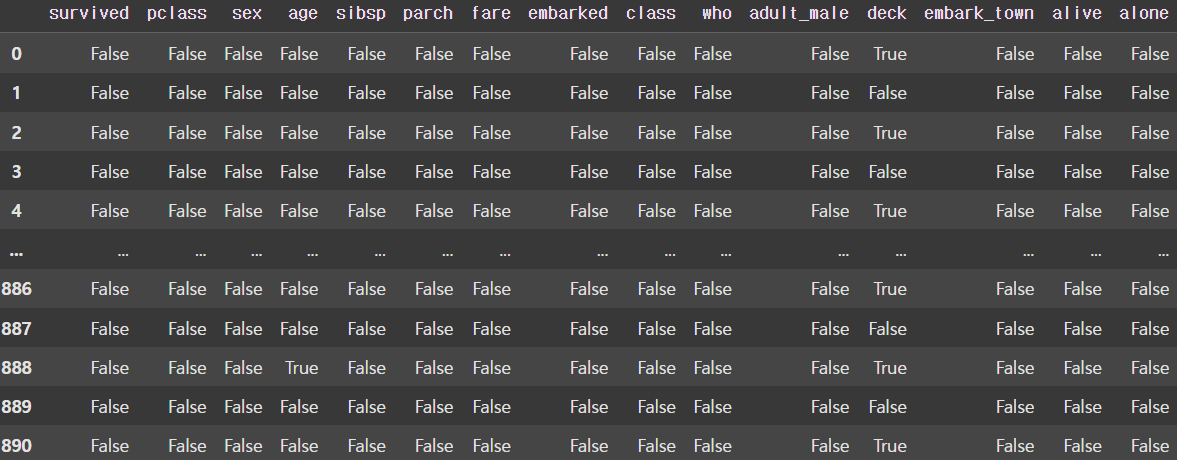 | 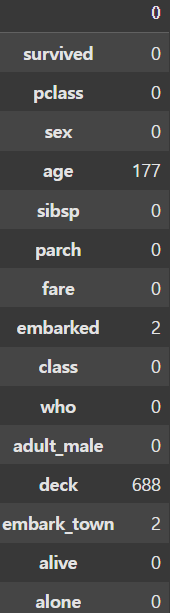 |
|---|
결치값을 바로 찾는 방법으로 isnull() 함수와 notnull() 함수가 있다. 이를 통해 생성한 DataFrame에 sum() 함수를 적용시키면 Python에서는 True는 1, False는 0이므로 결치값의 개수를 알 수 있다.
결치값 제거
new_df = df.dropna(axis=1, inplace=False)
# 이렇게 하면 NaN이 포함된 모든 column이 삭제된다.
display(new_df.head())
display(new_df.isnull().sum(axis=0))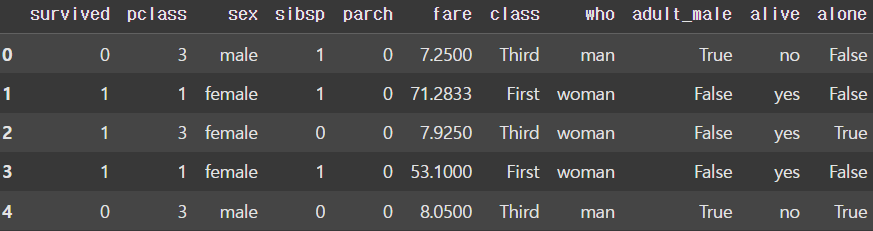 | 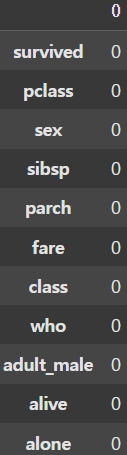 |
|---|
NaN을 제거하는 함수로는 dropna()가 있다. 이때 dropna()에 지정한 axis의 값에 따라 열단위(axis = 1) 삭제, 행단위(axis = 0) 삭제를 지정할 수 있다. deck 열에 약 900개중 700개의 데이터가 NaN이기 때문에 임의의 값으로 채우는 것보단 삭제하는 것이 좋다. 그러나 이렇게하면 NaN이 별로 없는 컬럼까지 모두 삭제되게 된다.
new_df = df.dropna(axis=1, inplace=False, thresh=500)
display(new_df.head())
display(new_df.isnull().sum(axis=0)) | 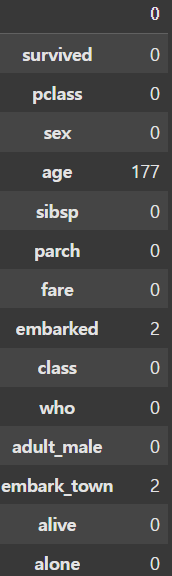 |
|---|
NaN이 매우 많은 컬럼만 골라서 삭제하고 싶다면 dropna() 함수에 thresh 인자를 전달하여 NaN의 개수가 지정한 값보다 큰 컬럼만 골라서 삭제할 수 있다.
df2 = new_df.dropna(axis=0, how='any')
display(df2.isnull().sum(axis=0))
df2 = new_df.dropna(subset=['age'], axis=0, how='any')
display(df2.isnull().sum(axis=0))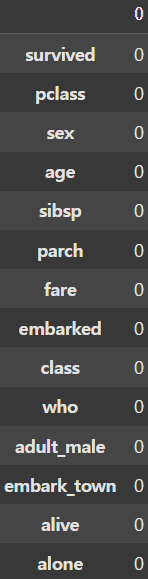 | 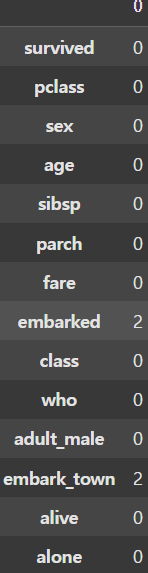 |
|---|
이제 문제가 되는 컬럼을 삭제했다면 NaN을 행단위로 삭제할 차례이다. 이때 dropna() 함수에 axis=0 으로 지정하면 행단위의 삭제를 할 수 있다. 이때 how 인자에 'any'를 전달하여 NaN이 하나라도 포함되는 행을 지울 수 있으며, 컬럼과 마찬가지로 subset 인자에 원하는 컬럼을 지정하여 삭제하고자 하는 열에 대해서만 삭제를 진행할 수도 있다.
결치값 치환
가끔 결치값이 NaN이 아닌 다른 값(ex. ?, - 등)으로 입력되기도 한다. 이때는 replace() 함수를 사용하여 np.nan 값으로 변경해주고 처리하는 것이 좋다.
df.replace('?', np.nan, inplace=True)
이 부분에 대해서는 이후 MPG 데이터 셋을 다룰 때 알아보자.
print(df['age'].head(10))
# age 열의 NaN 값을 나이 데이터의 평균으로 치환
mean_age = df['age'].mean(axis=0) # NaN값을 제외하고 평균 계산
df['age'].fillna(mean_age, inplace=True)
print(df['age'].head(10)) | 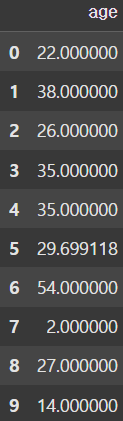 |
|---|
먼저, NaN을 평균값으로 치환해보자. age열의 데이터를 보았을 때, NaN 값이 존재하는 것을 확인할 수 있다. 이를 mean() 함수를 사용하여 age열의 모든 값의 평균을 구한 뒤, fillna() 함수를 이용하여 모든 NaN 값을 age의 평균으로 치환할 수 있다.
display(df['embark_town'][825:830])
# idxmax() 메소드를 이용해서 가장 큰 값의 index를 얻어온다.
most_freq = df['embark_town'].value_counts(dropna=True).idxmax()
display(most_freq)
df['embark_town'].fillna(most_freq, inplace=True)
display(df['embark_town'][825:830])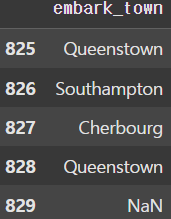 | 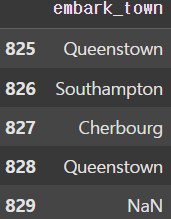 |
|---|
이번엔 승선도시를 나타내는 embark_town 열에 있는 NaN을 승객들이 가장 많이 승선한 도시(최빈값)의 이름으로 치환해보자. 이때 idxmax() 메서드를 사용하여 가장 큰 값의 index를 가져와 fillna() 함수로 치환하면 된다.
# method='ffill' 옵션을 주면 앞 행에 있는 값으로 치환하고
# method='bfill' 옵션을 주면 뒤 행에 있는 값으로 치환한다.
df['embark_town'].fillna(method='ffill', inplace=True)
print(df['embark_town'][825:830])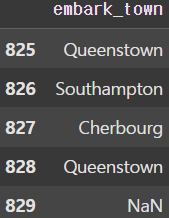 | 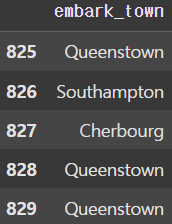 |
|---|
또한 데이터의 특성 상 서로 이웃하고 있는 데이터끼리 유사성을 가질 가능성이 높은데, 이럴 땐 ffill() 또는 bfill() 함수를 사용하여 앞이나 뒤로 이웃하고 있는 값으로 치환하는 것도 하나의 방법이다.
📚 중복 데이터 처리
분석 결과가 왜곡될 수 있기 때문에 하나의 데이터 셋에서 동일한 관측값(행)이 2개 이상 중복되는 경우 중복데이터를 찾아서 삭제해야한다.
또한 그 값이 정말 중복인지 확인하는 과정도 거쳐야한다.
중복 데이터 확인 및 삭제
data = {
'c1' : ['a', 'a', 'b', 'a', 'c'],
'c2' : [1, 1, 1, 2, 3],
'c3' : [1, 1, 2, 2, 2]
}
df = pd.DataFrame(data)
display(df)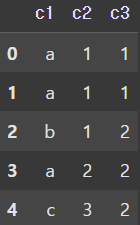
중복 데이터 확인을 위헤 임의로 DataFrame을 생성하였다.
new_df = df.duplicated()
display(new_df)
# duplicated() 함수를 Series에도 적용할 수 있다.
my_col = df['c2'].duplicated()
display(my_col)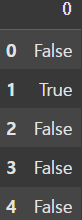 | 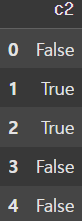 |
|---|
duplicated() 함수를 사용해 Boolean Mask를 생성하여 중복 데이터를 확인할 수 있고, 각각의 Series에도 적용시킬 수 있다.
new_df = df.drop_duplicates()
display(new_df)
# subset을 사용하여 기준을 정해줄 수 있다.
new_df = df.drop_duplicates(subset=['c2', 'c3'])
display(new_df) |  |
|---|
중복 데이터를 삭제하기 위해선 drop_duplicaes() 함수를 사용하여 삭제할 수 있다. subset을 지정하지 않으면 0행과 1행이 중복되므로 1행이 삭제되는 것을 볼 수 있고, subset을 지정하면 지정한 컬럼을 기준으로 삭제를 진행하며 코드로는 0행의 c2, c3열과 1행의 c2, c3열이 같으므로 1행이 삭제되는 것을 볼 수 있다.
📚 범주형(Category) 데이터 처리
데이터 분석 알고리즘에 따라 연속 데이터를 그대로 사용하기 보다는 범주형 데이터로 변환해서 처리하는게 효율적인 경우가 많다.
MPG 데이터 셋을 사용하여 알아보자.
import numpy as np
import pandas as pd
df = pd.read_csv('/파일경로/auto-mpg.csv',
header=None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'moder_year', 'origin', 'name']
display(df)
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 398 entries, 0 to 397
# Data columns (total 9 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 mpg 398 non-null float64
# 1 cylinders 398 non-null int64
# 2 displacement 398 non-null float64
# 3 horsepower 398 non-null object
# 4 weight 398 non-null float64
# 5 acceleration 398 non-null float64
# 6 moder_year 398 non-null int64
# 7 origin 398 non-null int64
# 8 name 398 non-null object
# dtypes: float64(4), int64(3), object(2)
# memory usage: 28.1+ KB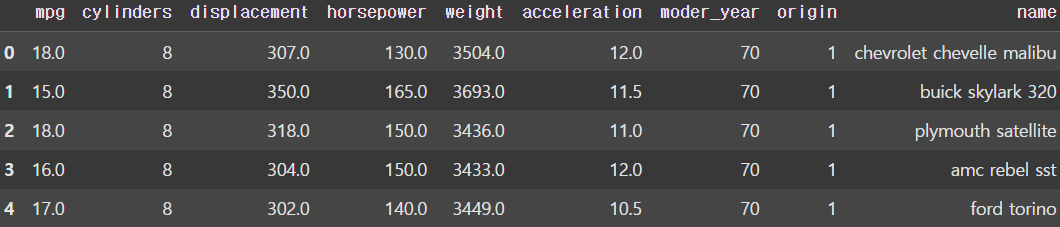
구간 분할 (Binning)
df['horsepower'].replace('?', np.nan, inplace=True)
df.dropna(subset=['horsepower'], axis=0, inplace=True)
df['horsepower'] = df['horsepower'].astype('float')
df.info()
# <class 'pandas.core.frame.DataFrame'>
# Index: 392 entries, 0 to 397
# Data columns (total 9 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 mpg 392 non-null float64
# 1 cylinders 392 non-null int64
# 2 displacement 392 non-null float64
# 3 horsepower 392 non-null float64
# 4 weight 392 non-null float64
# 5 acceleration 392 non-null float64
# 6 moder_year 392 non-null int64
# 7 origin 392 non-null int64
# 8 name 392 non-null object
# dtypes: float64(5), int64(3), object(1)
# memory usage: 30.6+ KB먼저 앞서 다뤘던 replace() 함수를 사용하여 horsepower열에 있는 ?(결치값)을 NaN으로 치환하여 삭제해준다. 그러면 총 398개의 행에서 392개의 행으로 줄어든 것을 확인할 수 있다.
count, divider = np.histogram(df['horsepower'], bins=3)
print(count) # [257 103 32]
print(divider) # [ 46. 107.33333333 168.66666667 230.]이후 NumPy의 histogram()이라는 함수를 사용하면 각 구간에 데이터가 몇개 있는지, 각 구간의 기준이 몇인지를 알 수 있다.
이때 bins에 값을 전달하여 몇개의 구간으로 나눌지 정할 수 있는데, 3개의 구역으로 전달할 경우
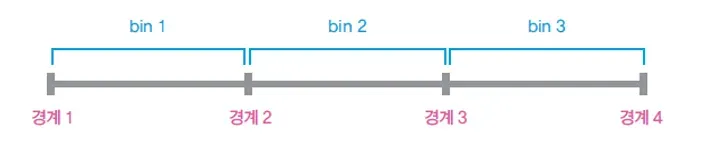
이와 같이 구간이 나눠지게 된다.
bin_name = ['저출력', '보통 출력', '고출력']
df['hp_cut'] = pd.cut(x=df['horsepower'], bins=divider,
labels=bin_name, include_lowest=True)
display(df)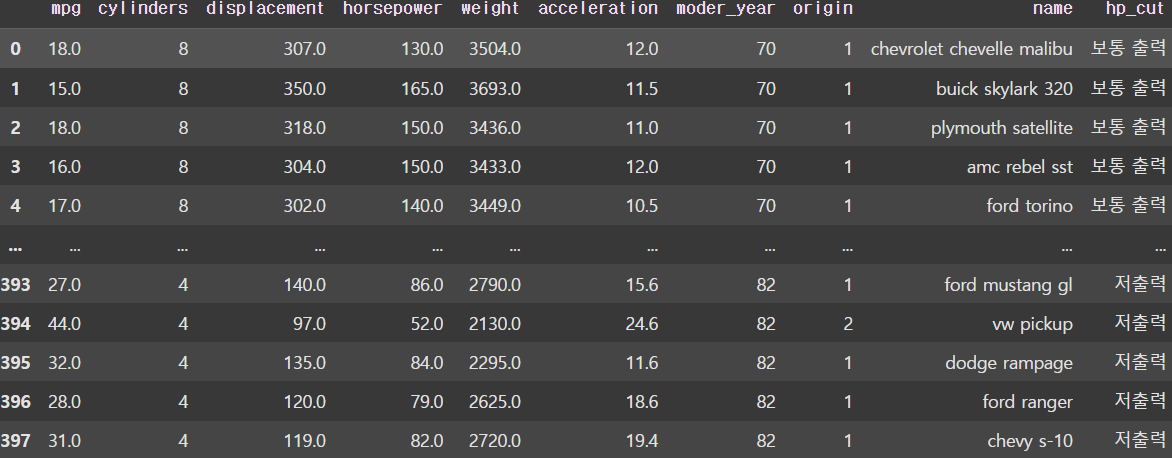
이후 나눠진 구간을 활용하여 cut() 함수를 사용해 이와 같이 Binning 처리를 할 수 있다.
dummy variable
위와 같이 horsepower열의 숫자형 연속 데이터를 hp_cut열의 범주형 데이터로 변환할 수 있음을 확인했다. 그러나 이처럼 category를 나타내는 범주형 데이터를 머신러닝 알고리즘에 바로 사용할 수 없는 경우가 많은데 이는 컴퓨터가 인식 가능한 값으로 표현해야 하기 때문이다.
이때 숫자 0 또는 1로 표현되는 dummy variable(더미변수)를 사용한다. 여기서 0과 1은 크고 작음을 의미하지 않고 어떤 특성이 있는지 여부만을 나타낸다.
이처럼 범주형 데이터를 컴퓨터가 인식할 수 있도록 0과 1로만 구성되는 One Hot Vector로 변환한다고 해서 One-Hot_Encoding이라고 부르기도 한다.
horsepower_dummies = pd.get_dummies(df['hp_cut']) # Series => DataFrame
display(horsepower_dummies)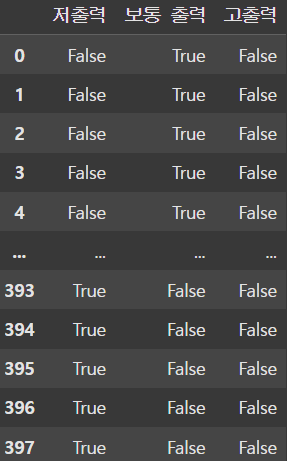
이처럼 get_dummies() 함수를 사용하면 전달받은 Series를 0과 1로 이루어진 DataFrame으로 변환해준다.
📚 Feature Scaling
Normalization (정규화)
각 변수(DataFrame의 각 열)에 들어있는 숫자 데이터의 상대적 크기 차이때문에 머신러닝 결과가 달라질 수 있다. 예를 들어 A변수는 0~1000 범위의 값을 가지고 B변수는 0~1 범위의 값을 갖는다고 하면 상대적으로 큰 숫자 값을 가지는 A변수의 영향이 더 커지게 된다.
따라서 숫자 데이터의 상대적인 크기 차이를 제거할 필요가 있는데, 각 열에 속하는 데이터 값을 동일한 크기 기준으로 나눈 비율로 나타내는 것을 Normalization (정규화)라고 한다.
이 과정을 거치게 되면 각 열의 데이터 범위는 0~1 혹은 -1~1이 된다.
가장 쉬운 방법 중 하나는 Min-Max Scaling이라고 불리는 방법으로, 다음과 같은 수식으로 표현한다.
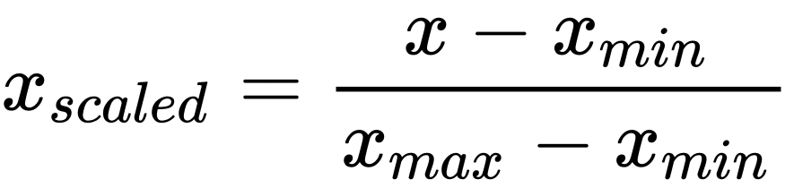
max_min = df['horsepower'].max() - df['horsepower'].min()
df['horsepower_norm'] = (df['horsepower'] - df['horsepower'].min()) / max_min
display(df)
이처럼 horsepower열에 대해 정규화를 한 결과, 모든 데이터 값이 0~1 사이의 값으로 변환된 것을 볼 수 있다.
