
📚 Classification
분류 모델은 데이터를 분류하는 방법을 학습한다.
예를 들면, 암 종양을 분류하는 모델은 이미지 사진 (CT사진)을 입력받아 암 종양이 있는지 그렇지 않은지를 분류한다.
특히 이런 둘 중 하나로 분류하는 모델을 우리는 이진 분류(binary classification)라고 하는데 이런 이진 분류를 위한 로지스틱 회귀(Logistic Regression)부터 알아보자.
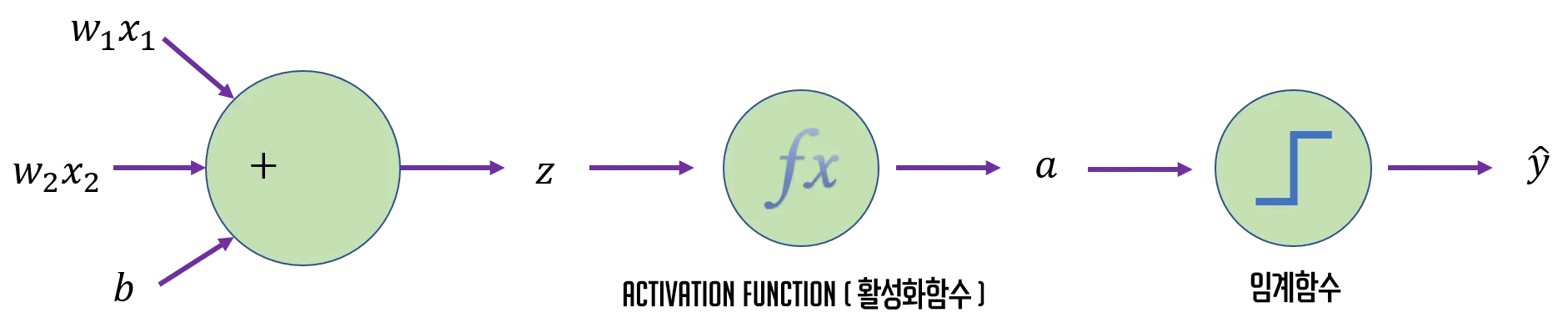
로지스틱 회귀(Logistic Regression)는 Linear Regression의 결과 값인 z를 임계함수에 보내기 전에 그 값을 변형시키는데 이때 사용하는 함수를 Activation Function(활성화 함수)라고 한다.
로지스틱 회귀에서는 활성화 함수로 Sigmoid Function(시그모이드 함수)를 사용한다.
마지막 단계에서는 임계함수(Threshold Function)를 사용하여 예측을 수행한다.
📚 Sigmoid Function
Binary Classification 시스템에서는 모델의 출력값 y가 0 또는 1만을 가져야하기 때문에 (정확히는 0과 1 사이의 실수) 함수값으로 0~1 사이 값을 가지는 sigmoid 함수를 도입해 사용한다.
시그모이드 함수는 다음과 같은 수식으로 표현되며, 그래프를 그리면 아래의 그림처럼 0과 1 사이의 값을 가지는 s 모양의 그래프가 된다.
import numpy as np
import matplotlib.pyplot as plt
x_data = np.arange(-7,8)
sigmoid_x_data = 1 / ( 1 + np.exp(-1 * x_data)) # sigmoid
plt.plot(x_data, sigmoid_x_data)
plt.show()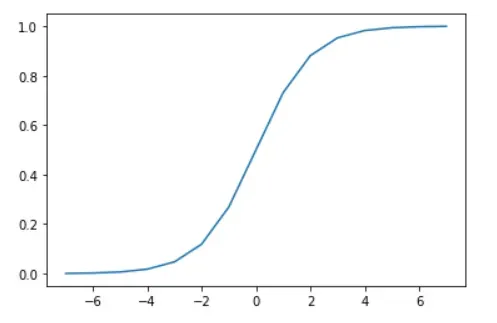
쉽게 말해, Linear Regression의 출력 Wx + b가 어떠한 값을 가지더라도 출력함수로 sigmoid 함수를 사용해서
-
sigmoid 계산값이 0.5이상이면 결과로 1이 나올 확률이 높다는 의미이기 때문에 출력값 y는 1로 정의하고
-
sigmoid 계산값이 0.5미만이면 결과로 0이 나올 확률이 높다는 의미이기 때문에 출력값 y는 0으로 정의하여
Classification 시스템을 구현할 수 있다.
따라서 Logistic Regression에서 우리가 구해야할 회귀함수는 Linear Regression의
y = Wx + b가 아닌 sigmoid(Wx + b)를 구해야 하며 식으로 표현하면 다음과 같다.
가장 최적의 W와 b 값을 구해야 하며 이를 위해서는 역시 또 loss function을 이용해야한다. (경사하강법)
📚 Cross Entropy
최적의 W와 b를 구하기 위해서는 손실함수(loss function)을 미분하면서 W와 b 값을 반복적으로 갱신해야한다.
마찬가지로, Logistic Regression에서도 손실함수를 미분해서 W와 b값을 찾아야 하는데, 손실함수를 구하기 위한 Linear Regression에서 사용했던 최소제곱법(MSE)을 Logistic Regression 함수에 적용하면 다음과 같은 수식이 된다.
만들어진 수식을 가지고 그래프를 그려보면 다음과 같은 형태로 그려지게 된다.
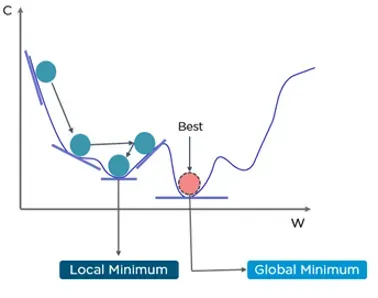
그림에서 보는 것처럼 convex 함수의 형태가 아니다. 즉, global minimum과 local minimum이 같이 공존하고 있으며 만약 W의 값이 local minimum 쪽에 들어서게 된다면 Gradient Descent Algorithm 특성 상 local minimum 값을 최소값으로 인식하는 오류가 발생된다.
따라서 Logistic Regression의 손실함수도 같이 수정해 주어야한다. Logistic Regression에서 사용하는 손실함수를 Cross Entropy라고 하며 아래의 수식으로 표현된다.
사실 Cross Entropy는 다중 분류를 위한 손실함수를 지칭한다.
이 다중 분류를 위한 손실함수를 이용하여 Logistic Regression을 위한 손실함수를 만들어 사용하는 것이다.
따라서 다중 분류를 위한 손실함수와 이중 분류를 위한 손실함수의 형태가 다르다. 하지만 실무에서는 둘 다 분류이기 때문에 이진 분류와 다중 분류를 구분하지 않고 그냥 모두 Cross Entropy 손실함수라고 부르기도 한다.
📚 Linear Regression을 통한 Logistic Regression 이해
다음의 코드와 그래프를 보며 Logistic Regression이 어떤 의미를 가지는 알고리즘인지 이해해보자.
import numpy as np
from sklearn import linear_model
import mglearn
import matplotlib.pyplot as plt
# Training Data Set
x,t = mglearn.datasets.make_forge()
# x : 2차원 0번째 컬럼은 x축 좌표, 1번째 컬럼은 y축 좌표
# t : [1 0 1 0 0 1 1 0 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 0]
mglearn.discrete_scatter(x[:,0],x[:,1],t)
plt.legend(['Class 0', 'Class 1'], loc=4)
model = linear_model.LinearRegression()
model.fit(x[:,0].reshape(-1,1),x[:,1].reshape(-1,1))
plt.plot(x[:,0],x[:,0] * model.coef_.ravel() + model.intercept_)
plt.show()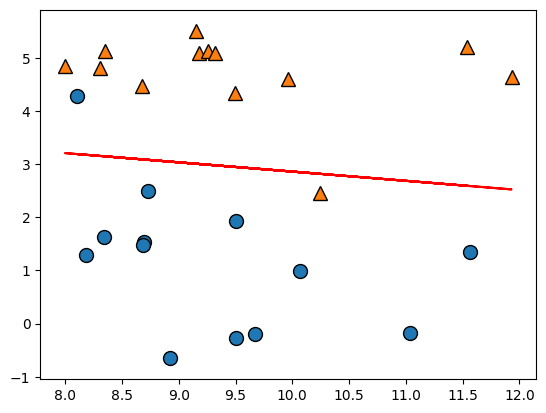
데이터 셋으로는 mglearn library 속 logistic을 위한 적절한 데이터 셋을 사용하였다. x에는 점의 좌표가 들어있고, t에는 각 점에 대한 이진 데이터(0 or 1)이 들어있다. 이를 이용하여 Linear Regression으로 학습 후 데이터를 가장 잘 나타내는 직선을 그래프에 그리면 위의 그림이 출력된다.
이를 이용하여 Logistic Regression을 간단히 설명하면,
- Linear Regression을 이용하여 Training Data Set의 특성과 분포를 나타내는 최적의 직선을 찾고,
- 그 직선을 기준으로 데이터를 분류 (Classification)해주는 알고리즘이라고 할 수 있다.
이러한 Logistic Regression은 Classification 알고리즘 중 정확도가 상당히 높은 알고리즘으로 알려져 있어 Deep Learning의 기본 Component로 사용되고 있다.
아래 그림으로 Logistic Regression의 과정을 설명할 수 있다.
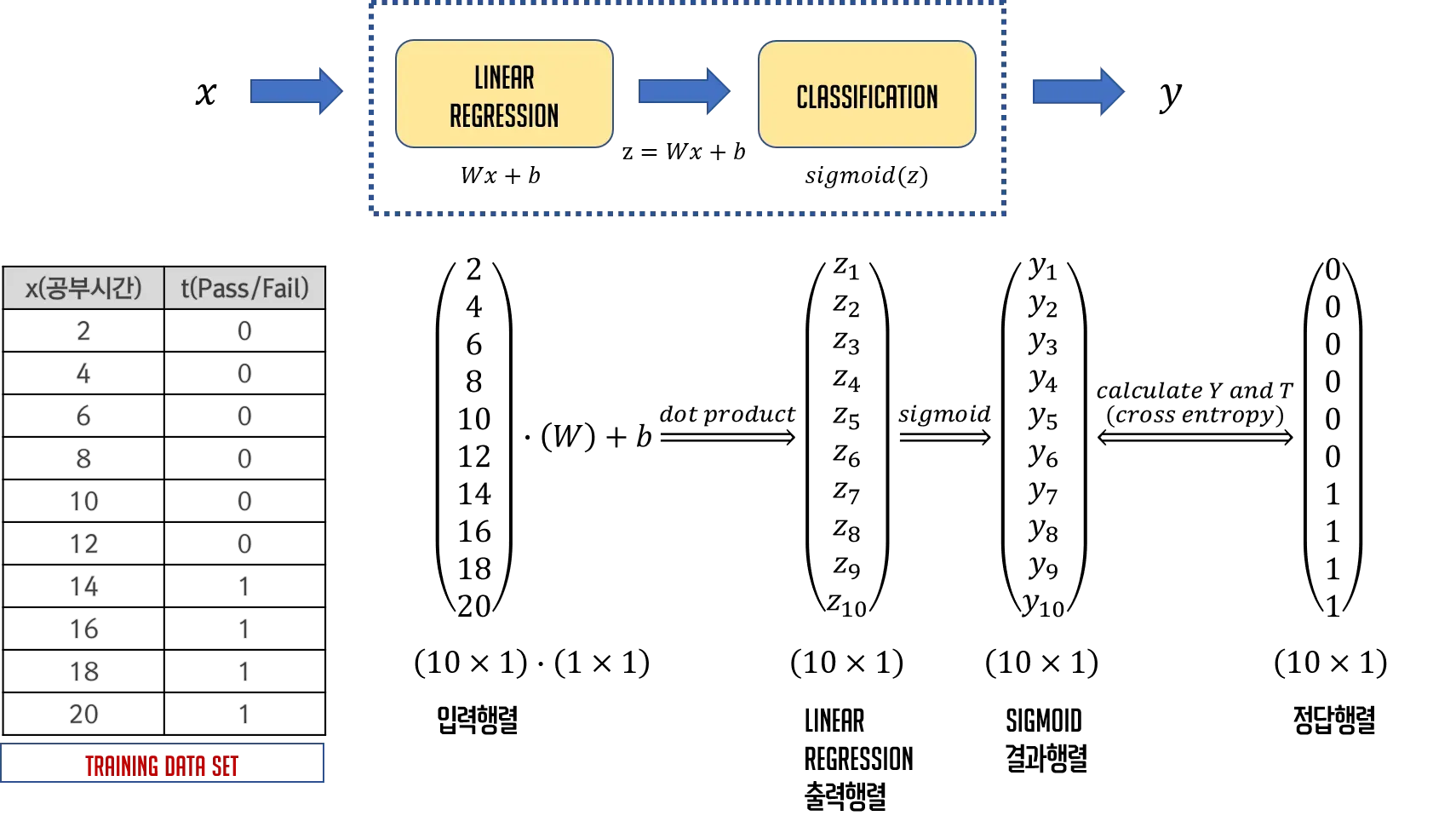
📚 Linear Regression으로는 할 수 없는가?
Linear Regression의 경우 Training Data Set의 상태에 따라 분류의 기준을 잘못 도출할 수도 있는데, 아래의 코드와 그림을 통해 알아보자.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# Training Data Set
x_data = np.array([1, 2, 5 ,8 ,10]) # 공부시간
t_data = np.array([0, 0, 0, 1, 1]) # 시험합격(0: FAIL, 1:PASS)
model = linear_model.LinearRegression()
model.fit(x_data.reshape(-1,1),
t_data.reshape(-1,1))
plt.scatter(x_data,t_data)
plt.plot(x_data, x_data * model.coef_.ravel() + model.intercept_)
plt.show()
# Linear Regression으로도 판별이 가능한 것처럼 보인다.
# 이번에는 데이터를 추가한 후 다시 한번 학습을 시키고 그래프를 그려보도록 하자!
############################################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# Training Data Set
x_data = np.array([1, 2, 5 ,8 ,10, 30]) # 공부시간 - 데이터 추가 30
t_data = np.array([0, 0, 0, 1, 1, 1]) # 시험합격(0: FAIL, 1:PASS)
model = linear_model.LinearRegression()
model.fit(x_data.reshape(-1,1),
t_data.reshape(-1,1))
plt.scatter(x_data,t_data)
plt.plot(x_data, x_data * model.coef_.ravel() + model.intercept_)
plt.show()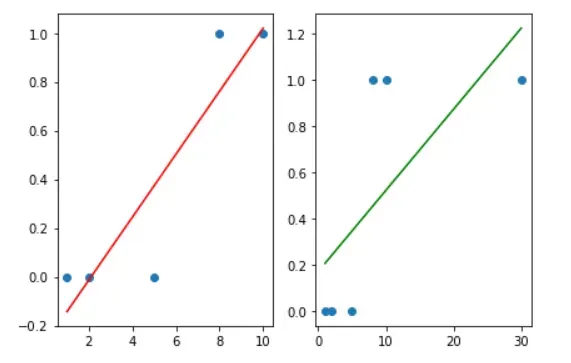
이처럼 Training data Set의 상태에 따라 기준이 모호해지는 것을 볼 수 있다. 따라서 분류 문제에서는 Logistic Regression을 사용하는 것이 더욱 정확한 예측값을 도출해 낼 수 있다.
