
📚 Multinomial Classification
Multinomial Classification?
Multinomial Classification은 여러 개의 분류 중 어떤 분류에 속하는지를 예측하는 분류기법이다.
2차 평면을 가정하고 Logistic Regression(Binary Classification)이 하는 일을 간단하게 말하면 데이터를 가장 잘 표현하는 직선을 찾고 그 직선을 기준으로 미지의 데이터가 어느쪽에 속하는지를 예측하는 것이라고 할 수 있다. 이 때 그 직선은 데이터를 구분짓는 구분선이라고 볼 수 있다.
차원을 늘려 3차원 공간을 가정한다면 (독립변수 2개) Logistic Regression은 데이터를 구분하는 평면을 찾고 미지의 데이터가 3차원 공간 속에서 어느 영역에 속하는 지를 예측하는 것이라고 할 수 있다. 이때 우리가 사용하는 것은 직선이 아니라 평면이 된다.
Logistic Regression의 개념을 Multinomial Classification에 적용해보자. 아래 그림과 같은 성적, 출석에 따른 학점 Grade가 있을 때 이를 2차원 평면에 점으로 표현하면 다음과 같다.
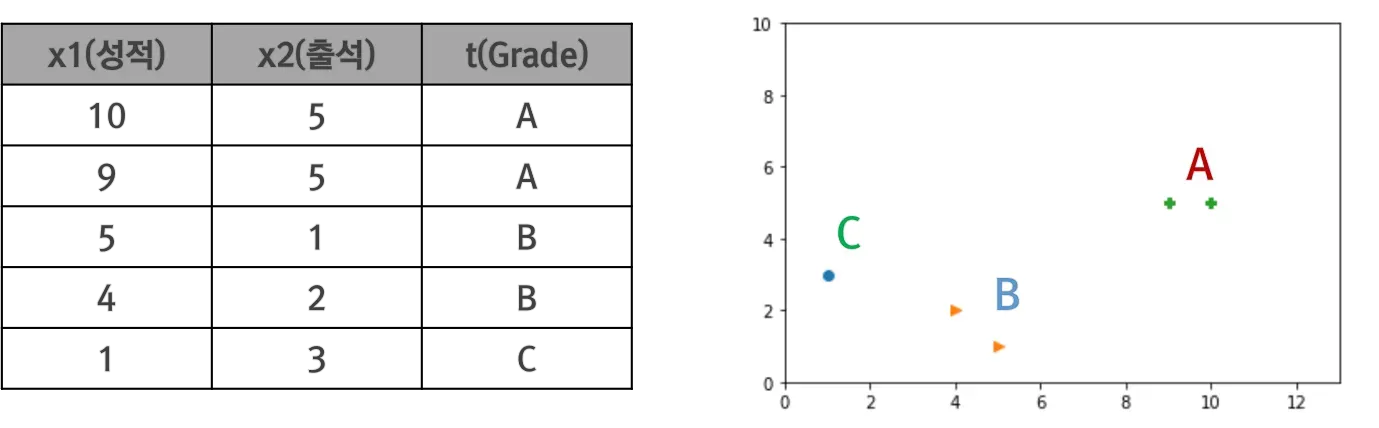
이 점들을 구분하기 위해 3개의 Binary Classification을 이용할 수 있다.
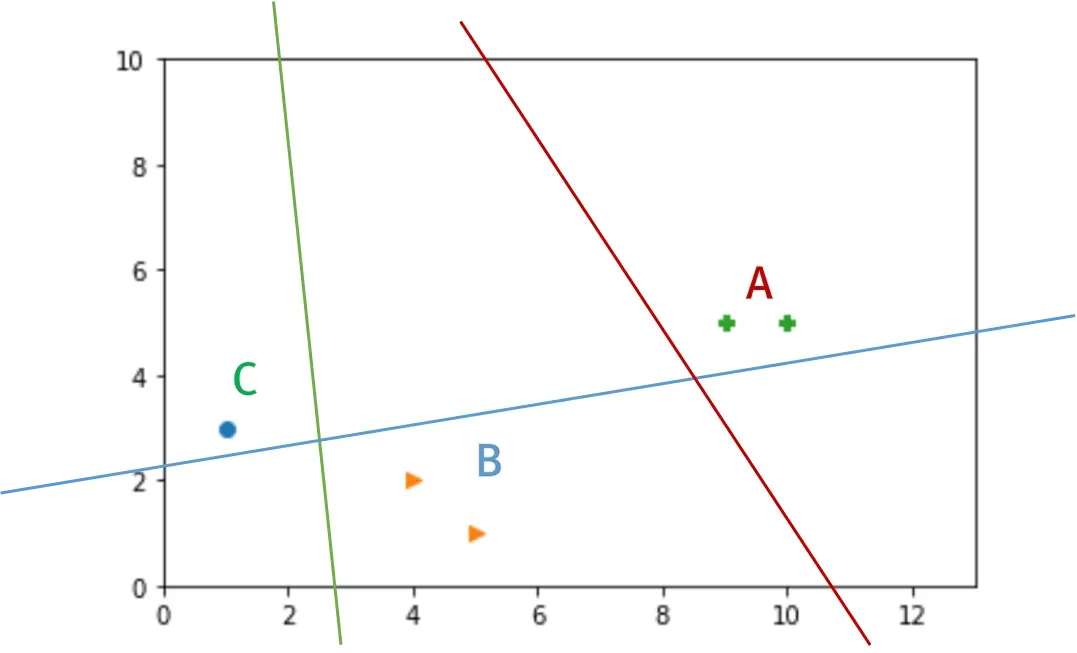
3개의 Logistic Regression을 이용하여 각각의 영역을 구분할 수 있다. 이를 행렬로 표현하면 다음과 같다.
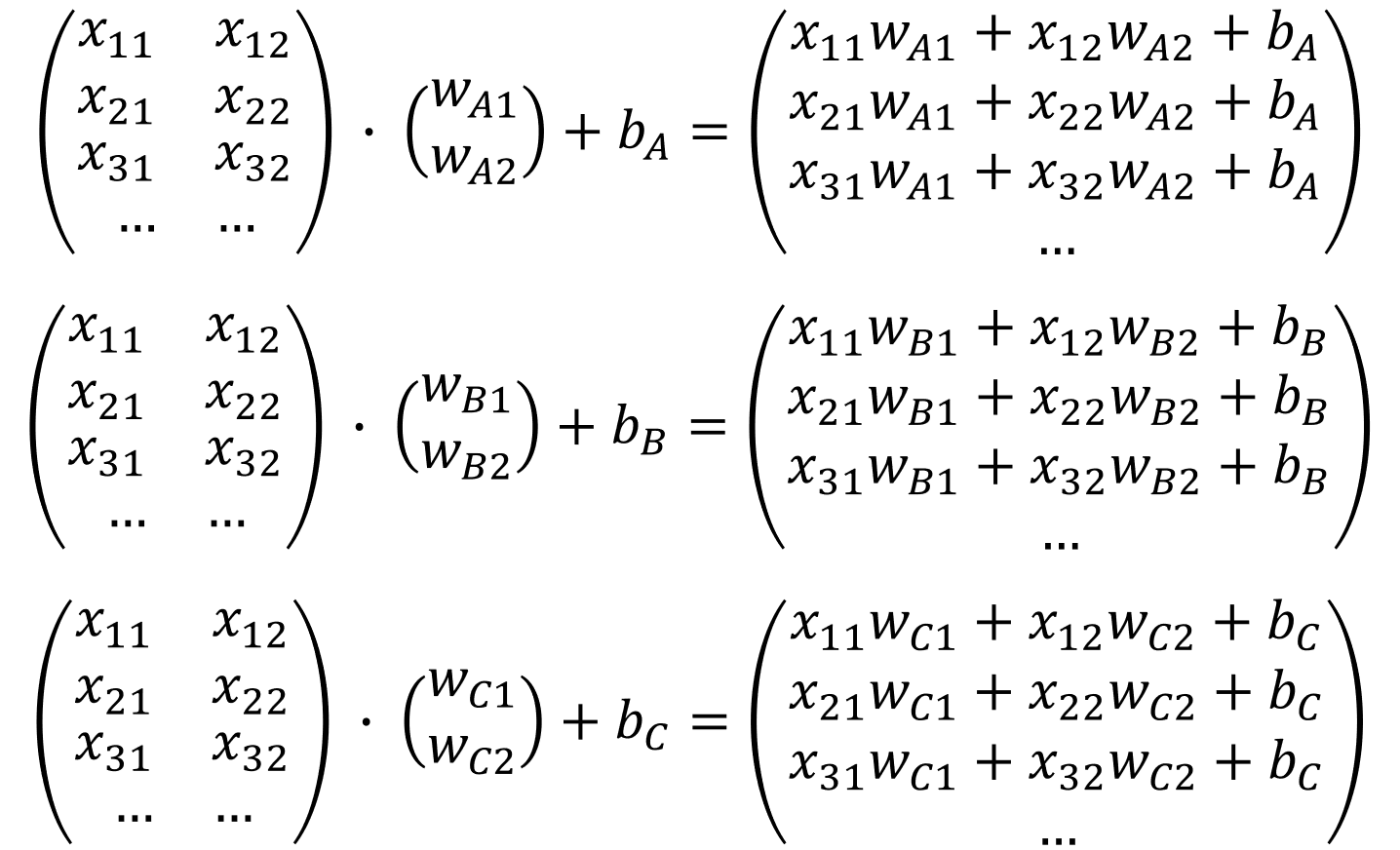
우리는 행렬연산을 이용하기 때문에 이 3개의 Logistic Regression을 하나의 행렬식으로 표현할 수 있다.
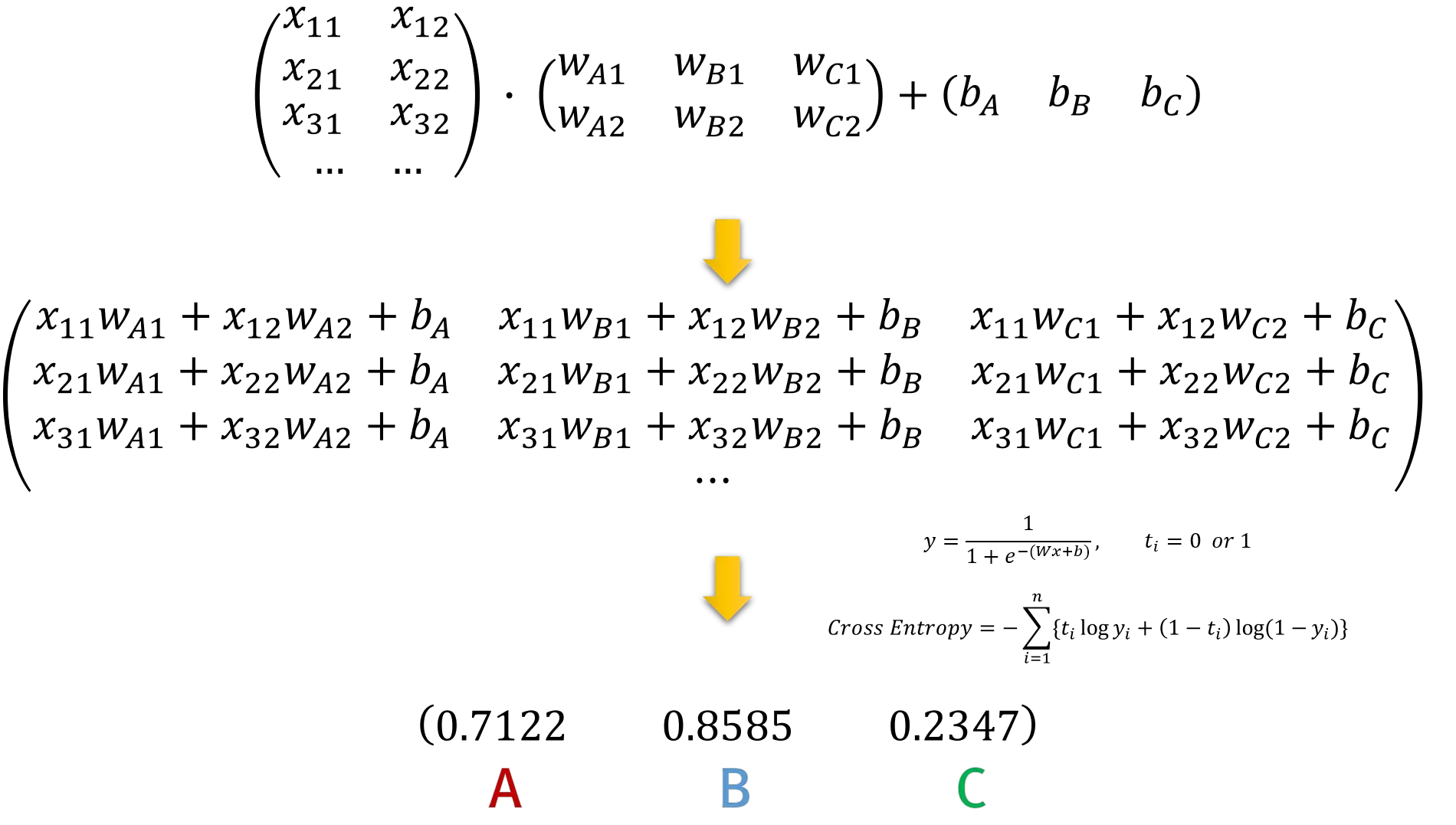
이렇게 각각의 Logistic Regression에 대한 확률값을 구할 수 있다. 이 값중 최대값을 선택하여 Multinomial Classification의 결과로 사용하면 된다.
일반적으로 Multinomial Classification의 결과값은 class를 구분하기 위한 정규화를 해주게 되는데 이때 사용하는 활성화 함수가 Softmax 함수이다.
즉, Multinomial Classification의 결과값에 대한 Softmax 연산결과의 합은 항상 1.0이다.
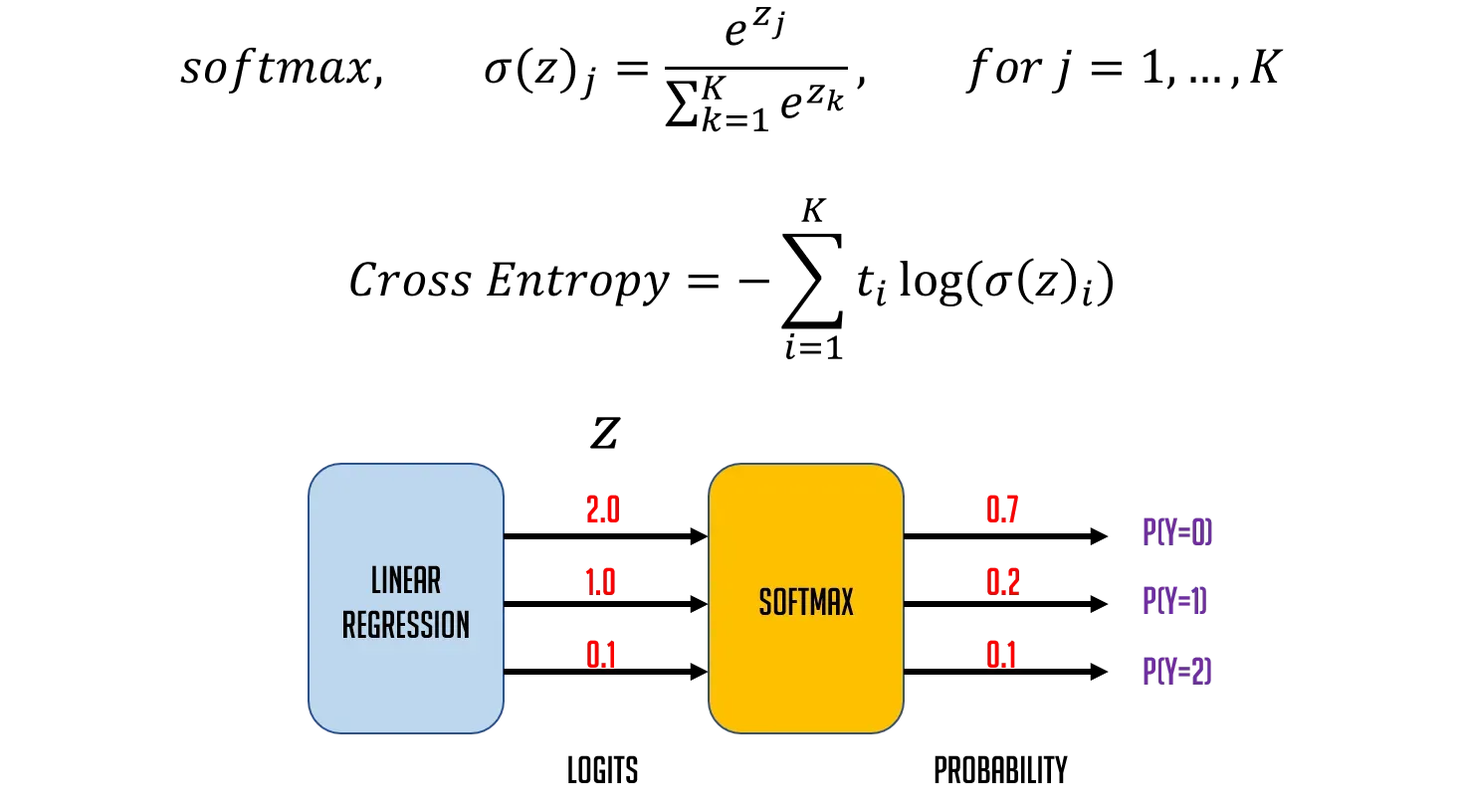
위의 식은 활성화 함수로 softmax를 사용했을 때 우리의 Model과 loss(Cross Entropy)를 나타낸 식이다.
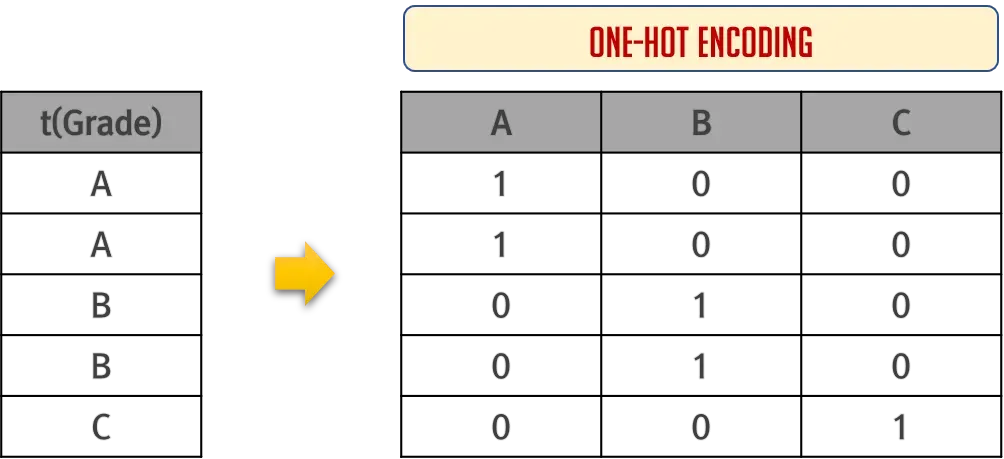
위의 예에서 성적(x1), 출석(x2)에 따른 학점(t)를 살펴보면 label이 숫자가 아닌 A,B,C와 같은 문자로 되어있다. 우리의 Multinomial은 여러개의 Logistic이 합쳐져서 만들어진 것이기 때문에 label 역시 여러개가 되어야 한다. 즉, A,B,C로 label이 표현되면 안된다는 것이다.
이 문제는 One-Hot Encoding이라는 방법으로 해결한다.
다음과 같은 방법으로 label을 변경시켜서 사용하게 된다.
이제 간단한 Mutinomial Classification 모델을 구현해보자.
📚 Data Preprocessing
BMI Data Set을 사용하여 Multinomial Classification을 구현하고 예측까지 진행하여 보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import accuracy_score📚 Raw Data Loading
df = pd.read_csv('/파일경로/bmi.csv', skiprows=3)
display(df.head())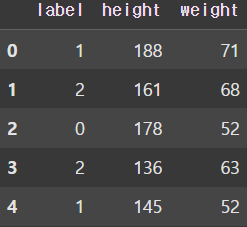
📚 결측치 확인 및 처리
df.isnull().sum()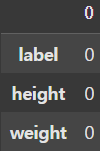
결측치는 없는 것으로 확인되었다.
📚 이상치 확인 및 처리
fig = plt.figure()
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
ax1.boxplot(df['label'].values)
ax2.boxplot(df['height'].values)
ax3.boxplot(df['weight'].values)
plt.tight_layout()
plt.show()
Boxplot을 통해 이상치도 없는 것으로 확인되었다.
📚 데이터 정규화
x_data = df[['height', 'weight']].values # 2차원
t_data = df['label'].values # 1차원
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)Classification 모델이므로 독립변수에 대해서만 정규화를 진행시켜준다. 원래는 종속변수에 대해 One-Hot Encoding 처리를 해주어야 하지만 sklearn이나 tensorflow 모델 구현 과정에서 알아서 처리할 수 있다.
📚 데이터 분할
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm, t_data,
test_size=0.3, stratify=t_data)모델 평가를 위해서 Train과 Test Set을 분할해준다.
📚 Multinomial Classification 구현 (sklearn)
sklearn_model = linear_model.LogisticRegression()
sklearn_model.fit(x_data_train_norm, t_data_train)sklearn으로 Mutinomial Classification Model을 구현할 땐 Logistic Regression Model을 구현할 때와 동일하게 linear_model의 LogisticRegression()을 사용한다. 또한, 학습할 때 One-Hot Encoding으로 종속변수(t_data)를 알아서 내부적으로 변환시켜 사용한다.
📚 모델 평가 및 예측
# 예측값 추출
sklearn_predict = sklearn_model.predict(x_data_test_norm)
# 예측값과 test 데이터에 대한 정답을 비교해서 모델의 정확도를 출력
print(accuracy_score(sklearn_predict, t_data_test)) # 0.9826666666666667
# 모델이 완성되었으니 예측 진행
my_status = np.array([[165, 62]])
print(sklearn_model.predict(scaler.transform(my_status))) # [1]
print(sklearn_model.predict_proba(scaler.transform(my_status)))
# [[0.00777841 0.92189886 0.07032273]]이때 predict() 함수를 사용하여 0(thin), 1(normal), 2(fat) 중 하나의 예측값을 추출할 수 있고, predict_proba() 함수를 사용하면 각 label의 확률값을 알 수 있다.
📚 Multinomial Classification 구현 (tensorflow)
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(2,)))
keras_model.add(Dense(units=3, activation='softmax'))
keras_model.compile(optimizer=Adam(learning_rate=1e-2),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = keras_model.fit(x_data_train_norm, t_data_train.reshape(-1, 1),
epochs=200, verbose=1,
validation_split=0.3, batch_size=100)tensorflow로 Multinomial Classification Model을 구현할 땐 활성화 함수로 softmax를 사용한다. loss 함수의 경우, binary_crossentropy 함수를 사용하는 Logistic Regression Model과 달리 categorical_crossentropy 함수를 사용한다. 이때, sqarse_categorical_crossentropy 함수를 사용하면 sklearn과 마찬가지로 One-Hot Encoding을 tensorflow 내부적으로 처리해준다.
📚 모델 평가 및 예측
keras_result = keras_model.evaluate(x_data_test_norm, t_data_test.reshape(-1, 1))
print(keras_result) # [0.0800541490316391, 0.9838333129882812]
my_status = np.array([[165, 62]])
print(keras_model.predict(scaler.transform(my_status)))
# [[3.0968402e-04 9.8861164e-01 1.1078653e-02]]tensorflow의 경우 evaluate() 함수를 통해 모델 평가를 진행하며, predict() 함수를 통해 sklearn 모델과 동일하게 예측 결과를 출력하는 것을 확인할 수 있다.
