
📚 성능평가 - Evaluation
우리는 Model을 구현한 다음 당연히 성능 평가를 진행해야한다.
먼저, 우리가 가지고 있는 Training Data Set을 어떻게 이용해서 성능 평가를 진행해야 하는가에 대해서 알아보자.
우선 Evaluation을 할 때 기억해야 하는 점은 Training Data Set으로 학습한 후, Training Data Set으로 Evaluation을 진행하면 안된다는 점이다. 그러면 어떻게 성능 평가를 진행해야 할까?

위의 그림에서 Validation Set과 Test Set의 차이점은
- Test Set은 최종 성능을 평가하기 위해 사용된다는 것이다. 즉, Training 과정에는 포함되지 않는다는 것이다.
- 반면, Validation Set은 Training 과정에 참여하여 Training이 된 여러 Model 중 가장 좋은 모델을 선택하기 위한 Set이라고 생각하면 된다. 이러한 Validation Set을 사용하는 이유는 우리가 만든 Model이 잘 만든 모델인지를 평가하기 위해서이다. 즉, Training Set의 일부를 Model의 성능 평가를 위해서 희생하는 것이다.
만약 Test Set이 Model을 개선하기 위해서 사용된다면 그것은 Test Set이 아니라 Validation Set이라고 해야한다는 것이다.
이처럼 학습 데이터(Training Data Set)의 일부를 검증 데이터(Validation Data Set)으로 사용하는 방법을 Hold-Out Validation이라고 한다.
좋은 방식이긴 하지만 한가지 단점도 존재하는데, 데이터를 나눈 방식 자체가 성능 추정에 민감한 영향을 미친다는 것이다.
또 한가지 문제가 있는데 만약 Training Data Set의 크기가 이 희생을 감당하지 못할 정도로 작다면 어떻게 해야할까?
이 두가지 문제를 해결하기 위해서는 K-Fold Cross Validation이라는 방법을 사용한다. 이 방법은 모든 데이터를 Training과 Validation에 사용하는 방법이다.
우리가 Validation을 하는 이유는 당연히 더 좋은 성능의 Model을 개발하기 위해서이다. Training Set을 이용해서 평가를 진행하면 안되기 때문에 Validation Set을 이용해 평가를 진행하며 Model을 튜닝하여 Model의 성능을 높일 수 있다.
간단한 예를 들자면, Training Set으로 진행한 Model의 Accuracy는 높은데 Validation Set으로 진행한 Model의 Accuracy는 낮게 나왔다면 Model이 overfitting되어 있다는 의미로 받아 들일 수 있다. 이럴경우 Regularization을 진행한다거나 epoch을 줄이는 방식들을 이용하여 overfitting을 막는 방법을 고려할 수 있다.
또한, Original Data Set을 Training, Test, Validation Data Set으로 나눌 때 각각의 클래스가 어느 한쪽으로 몰리지 않도록 골고루 섞여야 한다는 점도 기억해야한다.
from sklearn.model_selection import train_test_split
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(x_data, t_data,
test_size=0.2, stratify=t_data)이처럼 sklearn의 train_test_split을 사용하여 test_size에 지정한 비율로 데이터 셋을 나눌 수 있고, stratify에 지정한 데이터 셋을 기준으로 나눌 수 있다.
📚 성능 평가 지표 - Metric
머신러닝 모델을 평가할 때 올바른 평가지표를 사용하는 것은 정말 중요하다.
우리는 해결하려는 문제에 적합한 평가지표를 활용해야 하며 머신러닝 결과를 활용하는 다른 분야와의 소통도 고려한 평가지표를 사용해야 한다.
📚 Classification - Confusion Metric
우리가 구현한 Logistic Regression Model이 잘 만들어진 모델인지 확인하는 가장 직관적인 방법은 우리의 Model이 예측한 결과를 실제 정답과 비교해서 정답을 맞춘 비율을 확인하는 것이다.
정답은 이미 True, False로 나누어져 있고, 우리의 분류모델 역시 True와 False로 결과를 예측해 놓았다. 이것을 이용하면 아래의 그림처럼 2x2 형태의 matrix로 그 형태를 나누어 볼 수 있다.
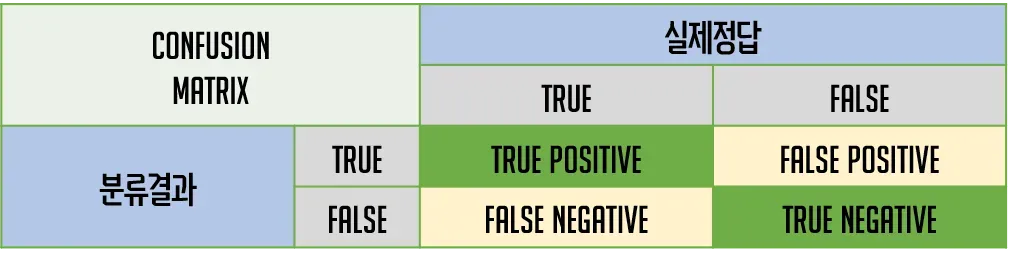
위와 같은 분류표를 confusion matrix라고 한다.
- True Positive(TP) : 실제 True인 정답을 True로 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True로 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False로 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False로 예측 (정답)
📚 Classfication - Accuracy (정확도)
Accuracy(정확도)는 다음의 식으로 표현된다. 전체 예측 건수에서 정답을 맞힌 건수의 비율을 의미한다.
Accuracy(정확도)는 가장 직관적으로 모델의 성능을 나타낼 수 있는 지표이다.
가장 좋은 지표인듯 보이지만 Accuracy는 domain의 bias(편향)를 반드시 고려해야 한다는 점을 기억해야 한다.
bias(편향)?
우리의 분류기가 CT 사진을 이용해 희귀병을 판단하는 분류기라고 가정하자.
당연히 거의 대부분의 경우 음성으로 판정될 것이고 양성인 경우는 아주 희박할 것이다. 1000명 중 1명만 양성이고 나머지 999명은 음성이라고 했을 때 만약 우리의 분류기를 무조건 음성으로 분류하도록 만들어도 99.9%의 정확도를 가진다는 것이다.
우리의 분류기는 True Negative만을 맞추고 True Positive는 발견하지 못하지만 분류기의 Accuracy는 상당히 높게 나타난다. 이런 현상을 Accuracy Paradox(정확도 역설)이라고 하기도 한다.
📚 Classification - Recall (재현율)
Recall은 실제 True인 것 중에서 우리의 Model이 True라고 예측한 것의 비율이다. 그래서 True가 발생할 확률이 적을 때 사용하면 좋다. Recall은 다음과 같은 식으로 표현이 가능하다.
통계학에서는 sensitivity, 다른 분야에서는 hit rate라는 용어로 사용하는 개념이다.
그러나 Recall 역시 완벽한 평가 지표가 될 수 없다.
희귀병 판별 문제에서 언제나 True로 분류하는 방식으로 분류기를 만들면 Accuracy는 상당히 낮아지지만 Recall은 1이 되기 때문이다.
📚 Classification - Precision (정밀도)
Precision은 우리의 Model이 True로 분류한 것 중 정말로 True인 것들의 비율이다. 다음과 같은 식으로 표현할 수 있다.
Positic 정답률, PPV(Positive Predictive value)라고도 부른다.
위의 희귀병 판단 문제에서 언제나 True로 판별하는 분류기를 만들었을 경우 Recall은 1이 나오지만 Precision은 0에 가깝게 나오게 된다.
📚 Classification - F1 Score
F1 Score는 Precision과 Recall의 조화평균이다. 다음과 같은 식으로 표현할 수 있다.
왜 평균을 사용하지 않고 조화 평균을 사용할까?
조화평균은 산술평균보다 큰 비중이 끼치는 bias가 줄어드는 평균이다. 단순히 평균을 내는 것 보다는 bias를 의식해서 평균을 내는 조화평균이 더 합리적이라고 생각해서이다. F1 Score의 값을 도식으로 표현한다면 다음과 같다.
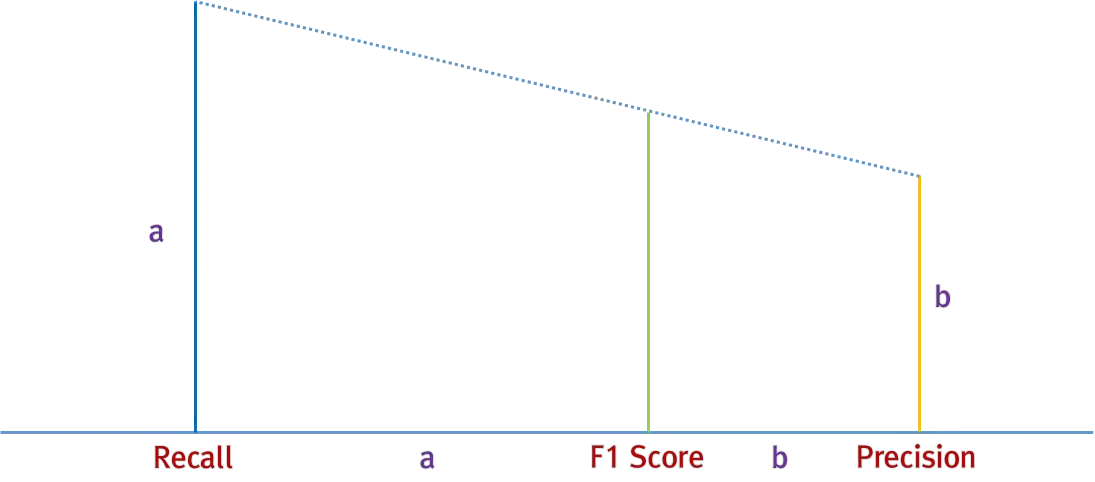
간단하게 예를 들자면, recall이 1이고 precision이 0.01을 가지는 분류기가 있다고 가정했을 때 recall과 precision의 산술평균을 구하게 되면 이기 때문에 절반은 맞추는 것으로 보이게 된다. 하지만 조화평균을 구하면 로 계산되기 때문에 해당 분류기의 성능이 좋지 않다는 것을 알 수 있다.
간단한 코드로 sklearn에서 제공하는 평가지표를 쉽게 구하기 위한 함수들을 알아보자.
from sklearn.metrics import accuracy_score, recall_score
from sklearn.metrics import precision_score, f1_score
labels = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1]
predict = [0, 1, 1, 1, 1, 0, 1, 0, 1, 0]
print(accuracy_score(labels, predict)) # 0.3
print(recall_score(labels, predict)) # 0.42857142857142855
print(precision_score(labels, predict)) # 0.5
print(f1_score(labels, predict)) # 0.4615384615384615📚 K-Fold Cross Validation
K-Fold Cross Validation
K개의 Fold를 생성해서 교차검증을 진행하는 방식이다.
일반적으로 총 데이터 수가 작은 경우 Training/Validation/Test Set으로 분류하여 성능평가를 진행하는 것보다 더 많은 데이터를 이용하여 성능평가를 진행할 수 있다. 데이터 수가 적은데 Validation과 Test에 데이터를 할애하게 되면 underfitting이 발생하는 등 성능이 낮은 모델이 생성될 수 있기 때문이다.
K-Fold Cross Validation 과정은 아래의 그림으로 한번에 설명이 가능하다.
만약 Accuracy를 평가척도로 사용한다면 각각의 Accuracy를 구한 후 전체 평균을 이용하여 우리 Model의 평균 Accuracy를 측정할 수도 있습니다.
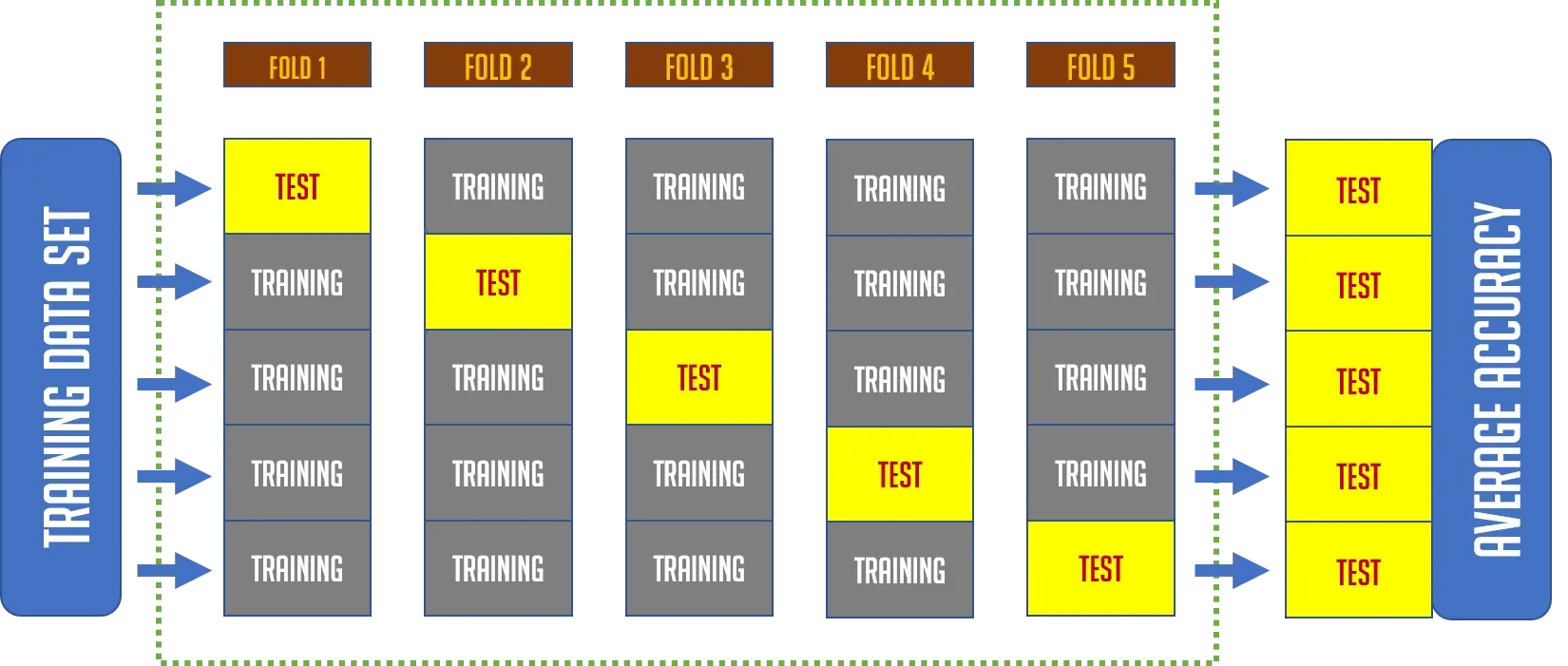
이 방식의 장점은 일반적인 Validation Set이 가질 수 있는 bias 문제를 해결할 수 있을 뿐만 아니라 적은 데이터로도 성능평가가 어느정도 가능하게 해준다는데 있다.
하지만 성능평가에 시간이 더 오래걸린다는 단점도 있다.
from sklearn.model_selection import cross_val_score
score = cross_val_score(sklearn_model, x_data_train, t_data_train, cv=5) 단, K-Fold Cross Validation는 sklearn Model에 대해서만 사용할 수 있다.
