[AI&ML_Eng : 개념 공부.] : 텍스트 감성 분석 (Sentiment Analysis) 01.

▽ [AI&ML_Eng : 개념 공부.] : 텍스트 감성 분석 (Sentiment Analysis) 01.
목 차
1. Article at a Glance (요약 및 확장)
2. 감성 분석이란 무엇인가? (Definition & Scope)
3. 어떻게 분석하나? (Analysis Methods)
4. 감성 분석과 딥러닝 (Deep Learning)

1. Article at a Glance (요약 및 확장)

2. 감성 분석(Sentiment Analysis)이란 무엇인가? (Definition & Scope)
감정/감성의 뜻 정리.
-
감정 분석.
- "감정"은 인간이 느끼는 기쁨, 슬픔, 분노 등의 감정 상태를 의미
- "감정분석"은 텍스트에서 감정 상태를 분석한다는 의미를 명확히 전달
- 이 표현은 특히 인간의 감정 상태에 초점을 맞춘 분석을 할 때 적합
-
감성 분석.
- "감성"은 감정뿐만 아니라 감각, 직관, 느낌 등을 포함하는 더 넓은 의미
- "감성분석"은 텍스트에 담긴 정서적 반응이나 주관적 느낌을 분석하는 데에
더 넓은 의미를 포함할 수 있음 - 감정을 포함한 보다 포괄적인 분석을 의미할 때 사용될 수 있음
-
일반적으로 감정보다는 '감성분석'이라고 쓰임.
감성 분석 정의
위키 : 언어 처리, 텍스트 분석, 계산 언어학 및 생체 인식을 활용하여 감정 상태와 주관적인 정보를 체계적으로 식별, 추출, 정량화 및 연구하는 기술
AWS : 디지털 텍스트를 분석하여 메시지의 감정적 어조가 긍정적인지, 부정적인지 또는 중립적인지를 확인하는 프로세스
주관적 요소의 정량화.
감성 분석은 '자연어 처리(NLP)' 분야의 한 갈래로,
텍스트 데이터에 담긴 주관적인(Subjective) 정보를 객관적인 수치로 변환하는 작업.
- 주관적 요소
: 단순히 사실(Fact)을 나열한 문장(→ 객관적 탐지)이 아닌
작성자의 의견(Opinion), 감정(Emotion), 평가(Evaluation), 태도(Attitude) 등이 포함된 부분을 의미.
- 정량화
: 분석된 감정을 컴퓨터가 처리할 수 있는 형태, 즉 {수치, 도식, 등급 } 등의 객관적 지표로 나타내는 것.- ex) "이 제품은 훌륭하다!" → 긍정 (+1) 또는 감성 점수 +0.9
단순 분류를 넘어선 분석 목표.
감성 분석은 단순히 텍스트 전체를 '긍정/부정'으로 분류하는 것을 넘어, 훨씬 더 복잡하고 디테일한 목표를 가짐.
- 개체(Entity) 및 속성(Aspect) 추출
: 어떤 대상(제품,서비스,인물)의 '어떤 속성'에 대한 감성인지를 파악.
- ex) "새 휴대폰의 디자인은 예쁘지만, 배터리 수명은 실망스럽다."
- → '디자인'에 대해 긍정, '배터리 수명'에 대해 부정.
(이러한 방식을 속성 기반 감성 분석이라고 합니다.)
- 의견 보유자(Opinion Holder) 분석
: 누가(어떤 사용자 그룹이, 어떤 인물이) 그 감성을 표현했는지까지 파악하여
더욱 심층적인 고객 세분화 분석이 가능.
감성 표현의 정량화 방식.
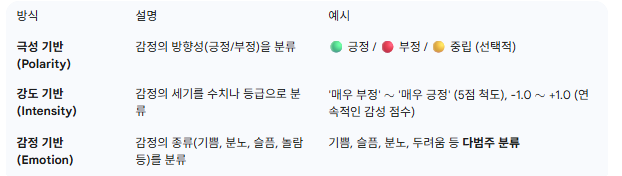
3. 어떻게 분석하나? (Analysis Methods)
감성 분석은 기존에는 크게 두 가지 접근 방식으로 나룰 수 있다고 하지만, 이제는 4가지로 나눌 수 있다고 봅니다.
감성사전 기반 분석(Lexicon-based Approach)
-
원리
: 미리 구축된 감성 사전(Sentiment Lexicon)을 사용하여
텍스트 내 단어들의 감성 점수를 합산하거나 통계적으로 처리하여 최종 감성을 판별 -
감성 사진 구성
: 감성 단어("좋다","나쁘다","만족","실망" 등등)와
그에 해당하는 "극성 범주(긍정/부정) 및 감성 점수"로 구성. -
장점
- 학습 데이터가 필요 없어 '데이터 라벨링(Labeling) 비용이 절감'
- 새로운 도메인에 적용하기 비교적 용이.
-
단점
- 감성 사전의 품질이 분석 성과에 직결되며,
사전에 없는 단어나 새로운 유행어, 도메인 특화 단어 (ex: 의학 용어, 금융 용어)의 처리가 어려움.
- 감성 사전의 품질이 분석 성과에 직결되며,
- "부정어(Not)나 수식어(매우,조금)"의 영향을 처리하기 위한 복잡한 규칙이 필요.
- '문맥 의존성'을 파악하기 어려움
- ex) 가격은 싸지만, 만족스럽지 않다 -> '만족스럽다'를 긍정으로만 판단할 수 있음.
- 예전 방식이며, 요즘은 잘 사용을 안하는 듯 함.
기계학습 기반 분석(Machine Learing-based Approach)
-
원리
: 대량의 '라벨링된 텍스트 데이터'(긍정/부정으로 미리 분류된 데이터)를 학습하여,
텍스트의 패턴과 감성 간의 관계를 스스로 파악하는 "분류 모델(Classification Model)"을 구축.
-
특징
- 지도 학습(Supervised Learing)방식이 주로 사용
- 충분하고 잘 라벨링된 학습 데이터가 필수적.
-
전통적 머신러닝 모델
-
나이브 베이즈(Naive Bayes)
: 단순하지만 효율적이며, 각 단어가 독립적이라고 가정하고 분류. -
서포트 벡터 머신(SVM)
: 데이터를 잘 분리하는 최적의 경계(Hyperplane)를 찾아 분류 성능이 우수. -
결정 트리(Decision Tree) 및 앙상블 기법(Random Forest, Gradient Boosting)
: 복잡한 규칙을 이해하기 쉽도록 분류.
-
-
전통적 기계학습의 어려움
- 텍스트 데이터는 단어의 종류가 많고(높은 차원)
- 각 단어의 출현 빈도는 낮아서(희소성,Sparsity)
- 데이터의 효율적인 표현과 특징 추출이 분석 성과에 매우 중요.
속성 기반 감성 분석 (Aspect-Based Sentiment Analysis, ABSA).
- 원리.
: 텍스트 전체의 감성이 아닌, "특정 개체의 세부 속성(Aspect)"에 대한
감성만을 분리하여 분석.
- 분석의 정교함
: 고객이 "제품-가격" 에 만족하는지, "디자인"에 불만족하는지 등등
세밀한 고객 목소리(Voc)를 파악하여 '제품 개선 우선수위' 셀렉에 활용.
- 단계
: ① 개체 및 속성 추출 → ② 속성에 대한 의견 표현 추출 → ③ 각 속성별 감성 극성 분류.
- 난이도
: 일반 감성 분석보다 훨씬 복잡하며, 딥러닝 기술이 필수적으로 요구.
AI 및 대규모 언어 모델 기반 접근 (AI and Large Language Model-based Approach)
-
원리.
: 최근 가장 우수한 성능을 보이는 방법으로, '딥러닝(Deep Learning)' 기술과
'트랜스포머(Transformer)' 구조를 기반으로 하는 LLM을 활용.워드 임베딩과 딥러닝 모델의 활용
이 접근법은 전통적인 기계 학습의 한계였던, "단어의 의미 및 문맥 부족" 문제를
"워드 임베딩(Word Embedding)"을 통해 해결 -
워드 임베딩(Word EMbedding)
: 단어를 "저차원의 밀집 벡터(Dense Vector)"로 변환하여
단어간의 "의미적,문법적 관계"를 수학적으로 표현.- ex) Word2Vec, GloVe, 이를 통해 딥러닝 모델은 단어의 단순한 존재 유무가 아닌, "**의미 유사성**을" 파악 가능.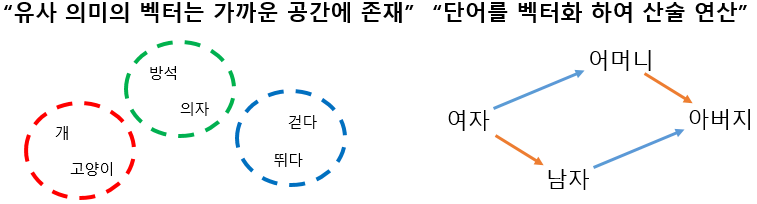
-
대표 딥러닝 모델
- RNN/LSTM
- 텍스트의 "순서 정보"를 처리하여 문맥을 파악.
- 특히 LSTM은 장기적인 문맥 의존성을 처리하는 데 강점.
- CNN
- 문장에서 감성을 나타내는 "핵심 구절(Local Features)"이나 패턴을
효율적으로 추출하는데 사용.
- 문장에서 감성을 나타내는 "핵심 구절(Local Features)"이나 패턴을
- RNN/LSTM
대규모 언어 모델(LLM) 기반의 혁신.
- LLM은 '트랜스포머(Transformer)' 구조를 기반으로 하며,
방대한 양의 텍스트 데이터로 "사전 학습(Pre-training)"되어 언어의 문맥과 의미를 매우 깊이 이해.
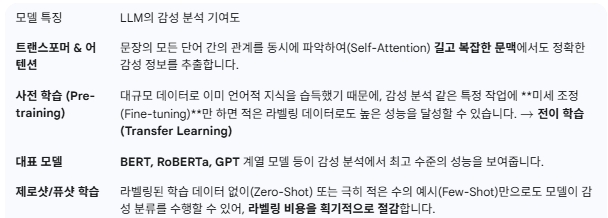
4. 감성 분석과 딥러닝 (Deep Learning)
최근에는 전통적인 기계 학습을 넘어서 "딥러닝(Deep Learning)" 모델이
감성 분석의 성능을 혁신적으로 향상시키는 중.
워드 임베딩 (Word Embedding)의 등장과 중요성.
전통적인 방식은 단어를 단순히 카운트하거나(TF-IDF 등) 원-핫 인코딩(One-Hot Encoding)을 사용하여 표현했는데, 이는 단어 간의 의미적 유사성이나 문맥적 관계를 전혀 반영하지 못하는 문제(희소성 문제)
- 개념 : 단어를 "저차원 공간의 실수 벡터"로 변환하여 표현하는 기법.
-
특징 : 의미가 유사한 단어일수록 벡터 공간에서 "가깝게 배치"되어
단어들 간의 어휘적, 문맥적 관계를 수학적으로 표현.- 예: Vector(’왕’)−Vector(’남자’)+Vector(’여자’)≈Vector(’여왕’)
-
대표 기법
: Word2Vec (Google), GloVe 등이 있으며, 이 임베딩 벡터를 딥러닝 모델의 입력값으로 사용하면 텍스트의 의미를 훨씬 깊이 있게 학습
대표적인 딥러닝 모델들
워드 임베딩을 통해 입력된 텍스트 데이터를 처리하여 감성을 분류하는 데 사용되는 주요 딥러닝 모델은 다음과 같음.
합성곱신경망: CNN (Convolutional Neural Network)
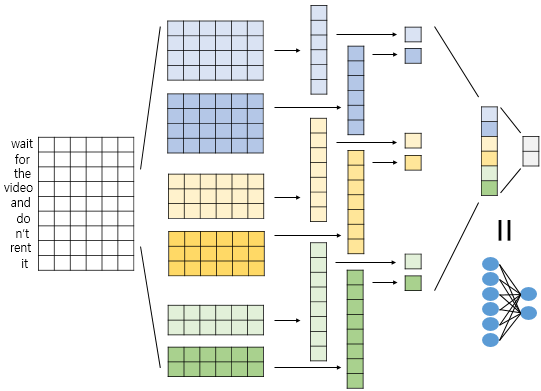
- 원리 : 원래는 이미지 처리에 사용되던 모델
- 텍스트에서도 "주요 특징(Feature)", 즉 문장에서 감성을 나타내는 "핵심 구절이나 패턴"을
필터(Kernel)를 통해 추출하는데 효과적.
- 텍스트에서도 "주요 특징(Feature)", 즉 문장에서 감성을 나타내는 "핵심 구절이나 패턴"을
- 장점 : 지역적 특성(N-gram과 같은 짧은 구절) 추출에 능하며, 처리 속도가 비교적 빠름.
순환신경망: RNN/장단기 기억: LSTM (Recurrent Neural Network / Long Short-term Memory Network)
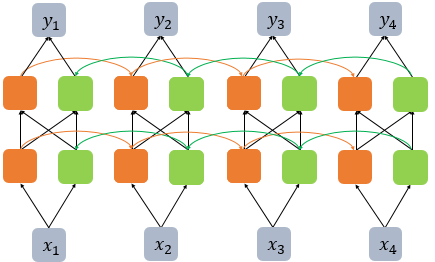
- 원리 : 텍스트는 "순서(Sequence)"를 가지므로, 이전 단어의 정보가 다음 단어의 해석에 영향을 미치는 "시퀸스 데이터"
- RNN은 이러한 순환 구조를 통해 텍스트의 "문맥(Context)"을 파악.
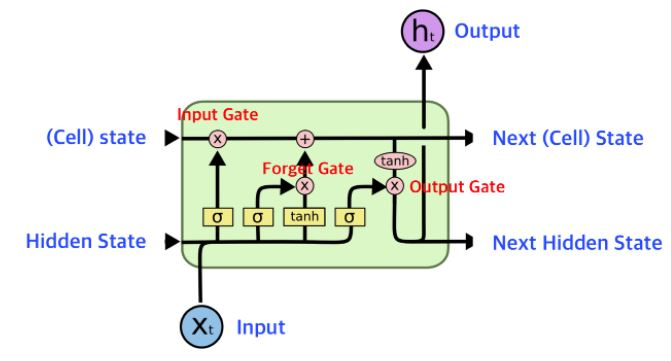
- LSTM : 기본적인 RNN의 장기 의존성(Long-term Dependency) 문제와 기울기 소실(Vanishing Gradient) 문제를 해결하기 위해
- 게이트(Gate) 구조(입력, 망각, 출력 게이트)를 도입.
- 먼 과거의 중요한 정보도 기억할 수 있게 함.
- 감성 분석에서 문장 전체의 의미를 파악하는데 매우 중요.
Transformer 기반 모델 (BERT 등)
- 최신 트렌드
: 최근에는 Attention 메커니즘을 기반으로 한 Transformer 구조가 압도적인 성능을 보임.
- BERT
- 구글에서 개발한 모델로, 문맥을 양방향으로 이해(기존 RNN은 단방향)
- 사전 학습(Pre-Training)된 대규모 언어 모델을 감성 분석 등 특정 작업에 미세 조정(Fine-tuning)하여 사용하는 방식으로 우수한 결과..
