1. Pandas 인덱싱(indexing)
-
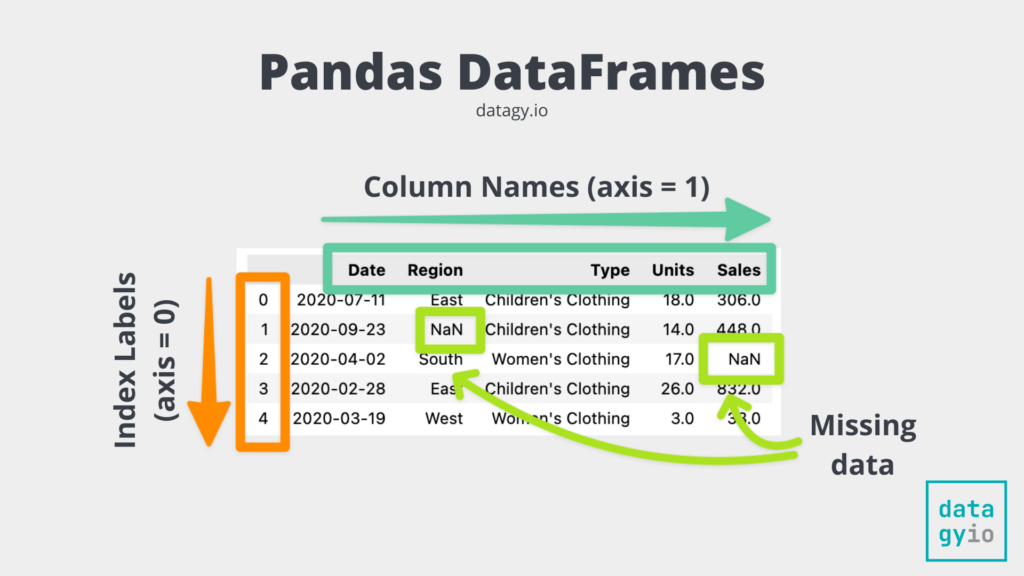
Pandas에서 데이터 작업의 핵심은 행/열을 어떻게 선택하느냐이다.
-
그중 가장 많이 쓰는 인덱싱 도구는 아래 네 가지:
-
loc→ 라벨(label) 기반 선택 -
iloc→ 번호(position) 기반 선택 -
df['col']→ 단일 컬럼 선택 (Series 반환) -
df[['col']]→ 컬럼 리스트 선택 (DataFrame 반환)
이 네 가지를 정확히 이해하면 대부분의 실무 인덱싱 문제를 해결할 수 있다.
-
2. loc vs iloc
1) 공통점
-
둘 다 DataFrame의 행/열을 선택하는 인덱서(indexer)
-
모두
[행, 열]형태로 사용
2) 핵심 차이
-
loc→ 컬럼/인덱스 이름(label) 로 선택 -
iloc→ 정수 기반 위치(position) 로 선택
3) 사용 예시
loc (라벨 기반)
df.loc['2024-01-01']
df.loc[:, 'value']
df.loc['2024':'2025'] # 끝값 포함iloc (위치 기반)
df.iloc[0]
df.iloc[:, 1]
df.iloc[10:20] # 끝값 미포함2.4 슬라이싱 규칙
-
loc[a:b]→ b 포함 -
iloc[a:b]→ b 미포함
2.5 실무 팁
-
시간순 Train/Test split → iloc
-
날짜 구간 추출 → loc
-
특정 컬럼 선택 → loc
-
특정 행 번호 선택 → iloc
3. DataFrame에서 대괄호가 자주 보이는 이유
DataFrame은 2차원 구조라서 “여러 개 선택” 시 반드시 리스트가 필요하다.
예시:
df[['A', 'B']] # 여러 컬럼 선택
df.iloc[:, [1, 2]] # 여러 열 번호 선택
df.loc[:, ['A', 'B']] # 여러 라벨 선택즉, 이중 대괄호는 "리스트 기반 선택" 을 의미한다.
4. df['col'] vs df[['col']]
-
df['col']→ Series(1차원)-
1차원
-
컬럼명 없음
-
shape =
(n,) -
계산, 조건 필터 등에 적합
-
-
df[['col']]→ DataFrame(2차원)- 2차원
-
컬럼명 유지
-
shape =
(n, 1) -
모델 입력(X), DataFrame 유지 작업에 적합
X = df[['A', 'B']] # 2차원 → 모델 입력 가능
y = df['target'] # 1차원 → 라벨
df['A'] # Series, (n,)
df[['A']] # DataFrame, (n,1)5. loc / iloc + 대괄호 실무 패턴
loc는 이름(label)iloc는 위치(position)df['col']은 Series,df[['col']]은 DataFrame- 여러 개 선택할 때는 리스트, 그래서 이중 대괄호
df[['A', 'B']] # 여러 컬럼
df.loc[df['value'] > 0, ['A', 'B']] # 조건 + 컬럼
df.iloc[10:20, [0, 2]] # 행 범위 + 특정 열
df.loc['2024-01':'2024-06', ['price','qty']] # 날짜 범위 + 컬럼
Hi!