HistGradientBoostingRegressor
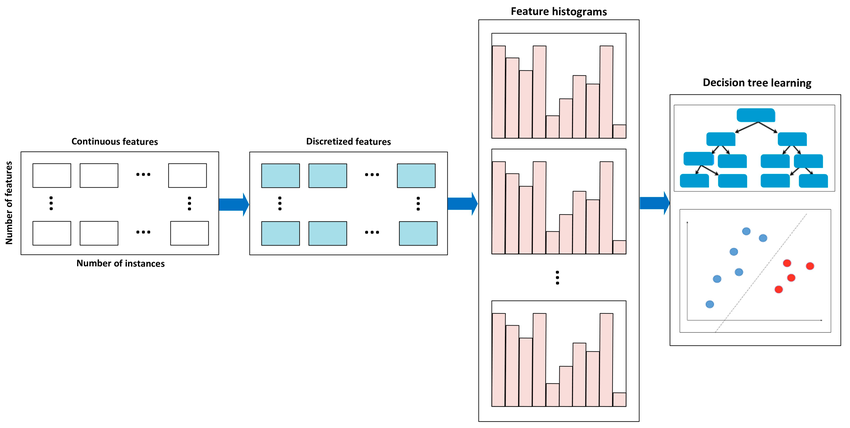
Scikit-Learn HistGradientBoostingRegressor는 대용량 데이터에 최적화된 고속 Gradient Boosting 회귀 모델로, LightGBM의 핵심 아이디어(히스토그램 기반 분할)를 반영한 sklearn 내장 모델입니다.
-
데이터가 커서 일반
GradientBoostingRegressor가 너무 느릴 때 -
결측치와 범주형 변수를 자동 처리하고 싶을 때
-
외부 라이브러리 설치가 어려운 환경에서 XGBoost, LightGBM을 대체해야 할 때
-
CPU 자원만으로 빠른 부스팅 모델이 필요한 경우
히스토그램 기반 트리는 기본적으로 CART 이진 의사결정트리 구조를 사용하되, 학습 시에는 Gradient Boosting Tree 알고리즘을 적용하면서 연속형 특성을 먼저 binning(구간화) 하고, 이 bin들로 구성된 히스토그램을 기반으로 split 후보를 탐색하며, 각 분기점의 품질은 gradient + hessian 기반의 gain 계산을 통해 결정한다. 이 방식은 정렬 과정이 필요 없어 매우 빠르고 메모리 효율적이며, 대규모 데이터에서도 성능이 우수하고 LightGBM·XGBoost와 유사한 수준의 효율을 제공하며, scikit-learn 환경에서도 GPU 없이 고속으로 학습할 수 있다는 장점이 있다.
2. 핵심 특징
-
히스토그램 기반 학습: 연속형 변수를 binning → 학습 속도 크게 향상
-
결측치 자동 처리: 별도 imputation 불필요
-
범주형 변수 자동 처리
-
대규모 데이터에 최적화
-
Scikit-Learn 내장 → 배포/운영 단순
3. 주요 파라미터 정리 및 실무 팁
learning_rate
-
작을수록 안정적, 더 많은 트리 필요
-
실무 추천값: 0.05 ~ 0.2
max_leaf_nodes / max_depth
-
모델 복잡도를 결정하는 핵심
-
일반적으로
max_leaf_nodes=31또는63에서 시작
max_bins
-
히스토그램 구간 수
-
크면 성능↑, 속도↓
-
대개 기본값 255 유지
categorical_features
-
범주형 컬럼 인덱스를 리스트로 전달하면 자동 인코딩
-
대규모 카테고리 처리에 유리
early_stopping
-
기본값 True 사용 권장
-
자동으로 적절한 트리 수에서 멈추므로 실무 효율 높음
4. 장점
-
기존 GBM 대비 수배 빠름
-
결측치·범주형 변수 자동 처리
-
외부 라이브러리 설치 필요 없음
-
대규모 데이터에서도 안정적
5. 단점
-
LightGBM, XGBoost보다 성능이 약간 낮을 수 있음
-
GPU 지원 없음
-
커스텀 손실 함수 제한적
6. 코드 예시 (Regression)
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingRegressor
model = HistGradientBoostingRegressor(
learning_rate=0.1,
max_leaf_nodes=63,
max_bins=255,
early_stopping=True,
categorical_features=[0, 2, 5] # 범주형 컬럼 인덱스
)
model.fit(X_train, y_train)
pred = model.predict(X_test)7. 실무 활용
-
수십만~수백만 row 데이터에서 속도 이점 매우 큼
-
feature importance는 Permutation Importance로 조회 권장
-
LightGBM 대비 성능 차이가 크지 않은 경우가 많아, 환경 제약이 있는 프로젝트에 활용하기 좋음
-
CPU 기반 병렬처리 최적화가 잘 되어 있어 서버 비용 절감 효과
