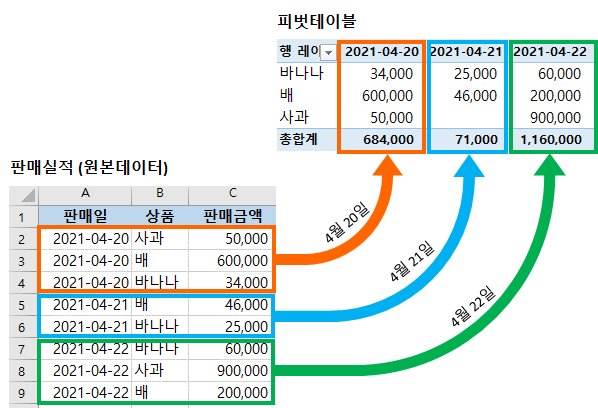
1. df.pivot_table()
-
pivot_table()은 그룹 집계(aggregation) + pivot 변환을 한 번에 처리하는 pandas 함수입니다. -
복잡한 집계를 단 한 줄로 처리할 수 있어 분석/리포트/모델링에서 가장 많이 쓰는 pivot 기능입니다.
2. pivot_table 주요 인자 설명
values
-
집계할 숫자형 컬럼
-
예: "QTY", "AMOUNT"
index
-
행(row) 기준으로 사용할 컬럼
-
예: "DATE", "TYPE"
columns
-
열(column)으로 펼칠 기준 컬럼
-
예: "OP_CD", "CATEGORY"
aggfunc
-
집계 함수 지정 (기본 "mean")
-
실무에서 자주 사용하는 값
-
'sum'
-
'mean'
-
'max'
-
'min'
-
-
여러 개 동시 지정 가능
- 예: aggfunc=['sum', 'mean']
fill_value
-
NaN을 특정 값으로 채움
-
예: fill_value=0
margins
-
총계(TOTAL) 행/열 추가
-
예: margins=True
margins_name
-
총계 표기의 이름 지정
-
예: margins_name='TOTAL'
dropna
-
전체 NaN 컬럼 제거 여부
-
기본값: True
3. 실무 예시 코드
1) 공정별 생산량 합계 Pivot
df.pivot_table(
values='QTY',
index='DATE',
columns='OP_CD',
aggfunc='sum',
fill_value=0
)2) 평균 + 최대값 동시에 요약
df.pivot_table(
values='TEMP',
index='FURNACE',
columns='SHIFT',
aggfunc=['mean','max']
)3) 총계(TOTAL) 포함 Pivot
df.pivot_table(
values='AMOUNT',
index='LINE',
columns='TYPE',
aggfunc='sum',
margins=True,
margins_name='TOTAL'
)4. pivot vs pivot_table 차이
pivot은 깔끔한 테이블일 때만, pivot_table은 모든 상황에서 안전하게 사용 가능 → 실무 기본값
pivot
-
단순 wide-format 변환
-
중복 값 허용 X
-
집계 기능 없음
-
결측치 처리 옵션 없음
-
데이터가 완벽히 unique key일 때만 사용 가능
pivot_table
-
pivot + 집계 + 결측치 처리 + 총계까지 포함
-
중복값 자동 집계 (aggfunc)
-
실무에서 가장 많이 사용
-
모델링 전처리에서도 핵심 도구
5. 기존 사용자 함수 → pivot_table로 리팩터링
예: 공장별 제품 생산량 피벗을 만들어주는 사용자 함수를 pivot_table로 대체
기존 사용자 함수 (예시)
def create_pivot_iron(df):
return df.groupby(['LINE','GRADE'])['QTY'].sum().unstack().fillna(0)pivot_table로 대체
df.pivot_table(
values='QTY',
index='LINE',
columns='GRADE',
aggfunc='sum',
fill_value=0
)장점
-
한 줄로 대체 가능
-
MultiIndex 자동 처리
-
집계 방식을 자유롭게 변경 가능 (sum → mean 등)
-
가독성 개선
6. MultiIndex pivot 응용 (실무 자주 사용)
예: 공장/라인 2단 index + 제품 컬럼 pivot
df.pivot_table(
values='QTY',
index=['FACTORY','LINE'],
columns='PRODUCT',
aggfunc='sum',
fill_value=0
)출력 예
FACTORY | LINE | A | B | C
A | 1 | 20 | 10 | 0
A | 2 | 15 | 8 | 5
B | 1 | 22 | 11 | 3
→ 리포트/대시보드에서 많이 쓰는 형태
7. 모델링(ML)을 위한 pivot 전처리 패턴
1) 고객 × 상품 구매 pivot → 예측 모델 feature
pivot = df.pivot_table(
values='buy_cnt',
index='cust_id',
columns='product',
aggfunc='sum',
fill_value=0
)2) 고객 속성 merge
pivot = pivot.merge(cust_df[['cust_id','age','gender']], on='cust_id')3) 모델 입력으로 사용
X = pivot.drop('churn', axis=1)
y = pivot['churn']4) 분류 모델 학습
model.fit(X_train, y_train)이 패턴이 고객/거래 기반 모델링(Churn, CLTV, RFM 분석 등)에서 가장 흔하게 사용됨.
