
✍🏻 2일 공부 이야기.

오늘 실습한 코드 내용은 위 깃허브 사진을 클릭하면 이동합니다 :)
Autoencoders , Image Augmentation
오토인코더
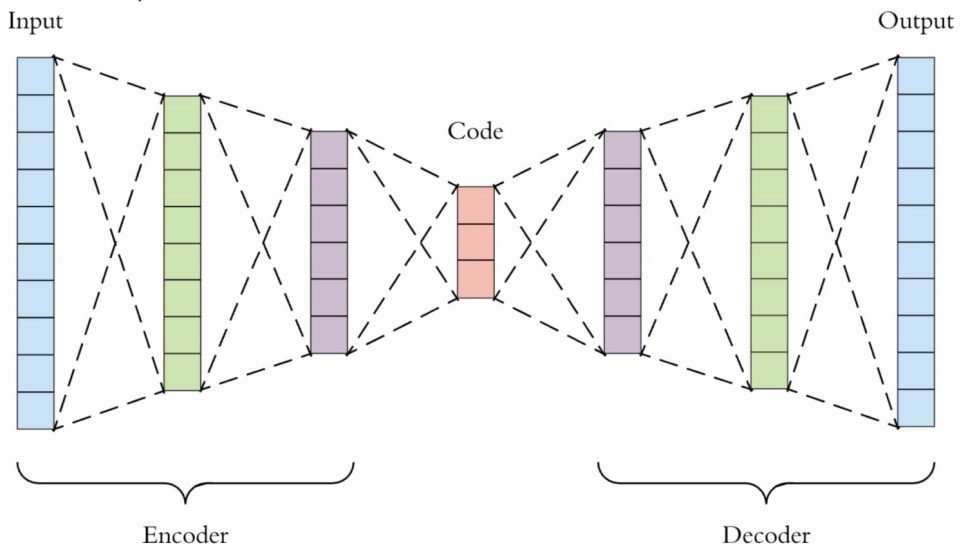
입력에서부터 제일 작아지는 지점까지를 Encoder라고 하고 다시 출력지점까지를 Decoder라고 한다.
이때 제일 작아진 지점(붉은색)을 Latent Vector(잠재 변수)라 부른다.
Encoder는 일종의 특징 추출기 같은 역할이고
Decoder는 압축된 데이터를 다시 복원하는 역할을 하고
AutoEncoder는 자기 자신을 재생성하는 모델로, 입력과 출력이 동일하다.
MNIST
이미지 증강
YOLO

먼저 딥러닝의 이미지의 분류에는 크게 위와 같이 구분된다.
- Image Classification : 이미지에서 가장 잘 두드러지는 사물 하나를 찾음
- 입력 이미지에 대해 하나의 클래스 레이블을 할당 - Object Localization : 이미지에서 해당 사물의 클래스와 위치를 찾음
- 이미지 내에 존재하는 사물의 위치를 바운딩 박스(bounding box)로 표시하고, 해당 사물의 클래스를 분류 - (Multiple) Object Detection : 이미지에서 여러 사물의 클래스를 찾음
- 이미지 내에 존재하는 여러 사물의 위치를 바운딩 박스로 표시하고, 각 사물의 클래스를 분류 - Semantic Segmentation : 이미지에서 각 사물을 클래스별로 위치를 찾음(같은 클래스는 하나로 파악)
- 같은 클래스의 사물들은 하나로 파악하는 것이 아니라, 각 픽셀 단위로 클래스를 분류하여 이미지를 세분화 - Instance Segmentation : 이미지에서 각 사물마다 위치를 찾음(같은 클래스도 다른 위치에 있다면 다르게 파악)
- 같은 클래스라도 서로 다른 인스턴스에 대해 개별적으로 위치를 파악 - Keypoint Detection : 이미지에서 특정한 위치나 물체의 핵심적인 지점, 예를 들어 얼굴에서 눈, 코, 입 등을 찾음.
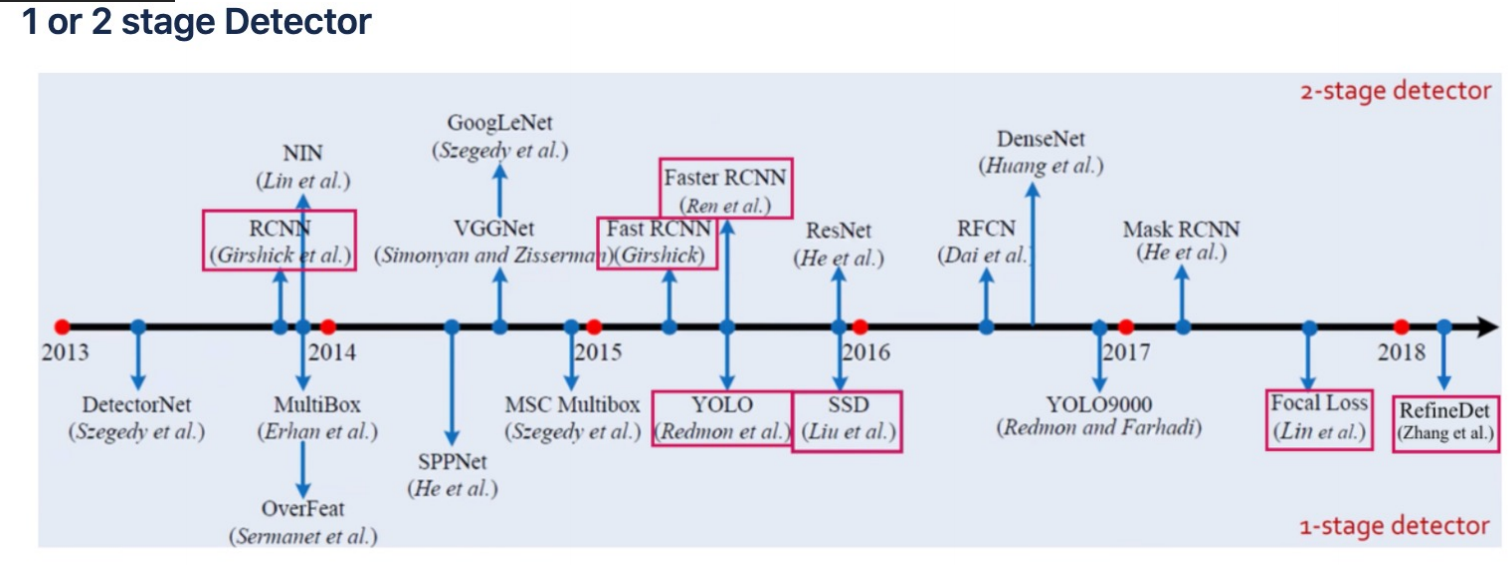
그리고 이미지 분류의 모델들이 주목받기 시작한 시점을 그래프로 표현해본 것인데, 분류 모델에 따라 1 stage Detector와 2 stage Detector로 구분된다.
1 stage Detector와 2 stage Detector
-
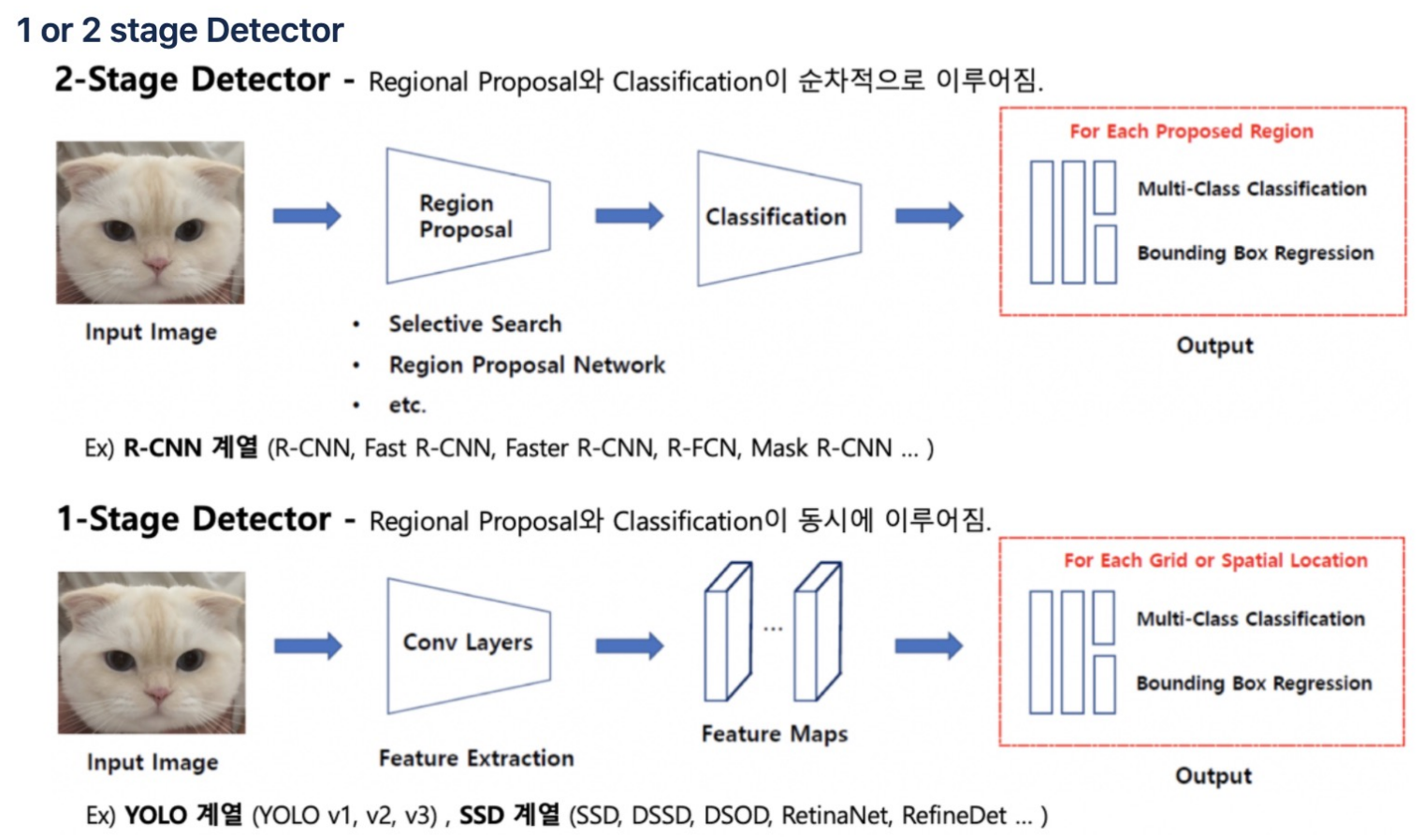
2 stage Detector
: 2 stage Detector는 이미지를 입력받으면 먼저 사물이 위치한 곳을 찾아내는 작업을 한다.(= Region Proposal) 그 후 해당 사물이 무엇인지 분류하는 작업을 진행한다.(= Classification)
이렇듯 2번 딥러닝 모델이 돌기 때문에 2 stage라는 이름이 붙여졌다.
당연히 속도가 느리다. -
1 stage Detector
: 위와 달리, 1 stage Detector는 딥러닝이 1번만 돈다.
먼저 이미지를 입력받으면 이미지를 잘게 그리드 형태로 쪼개고 각 그리드에 대해 Detection을 진행하는데 이때 같은 사물이면 연결짓는 흐름으로 진행된다.
You Only Look Once 라는 의미를 가진 YOLO도 1 stage Detector에 해당한다.
YOLO
우리가 1 stage Detector에서 주목해서 보아야할 점은
Multi class를 object detection을 하는데 어떻게 1 stage로 했는가? 이다.
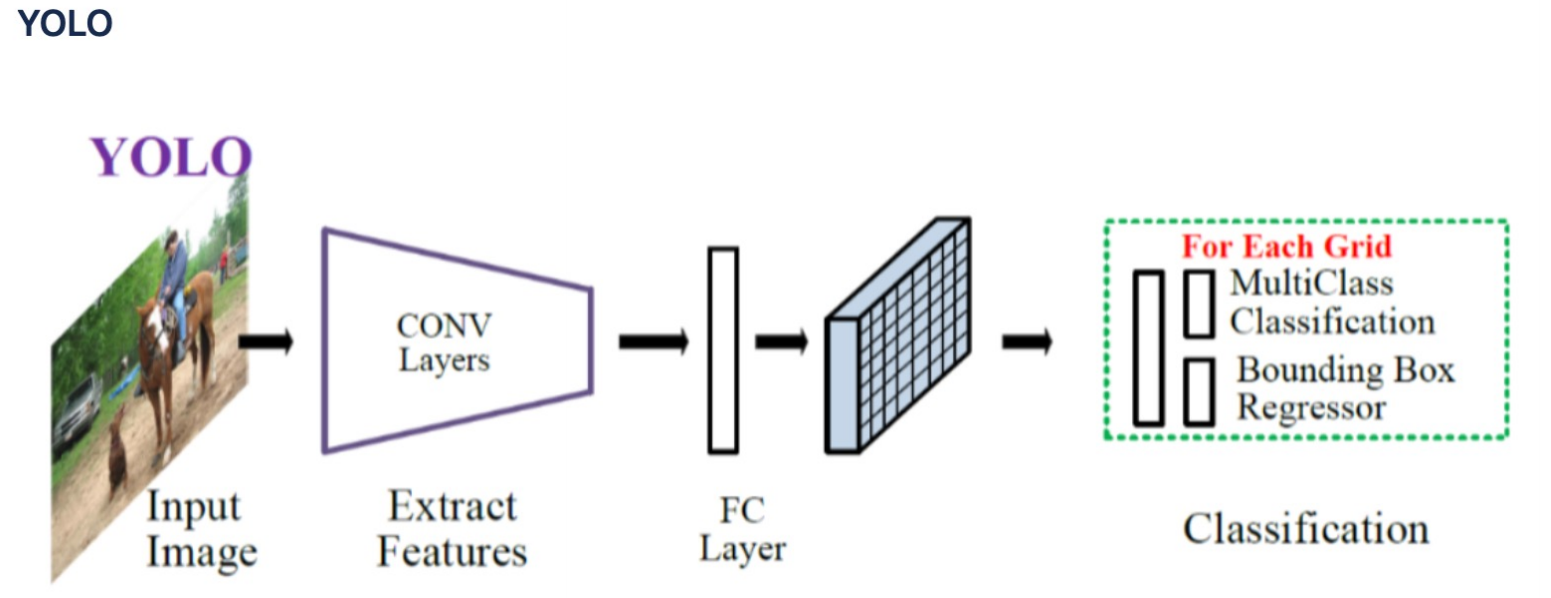
그러므로 우리가 주목해서 볼 점은
- Multiclass는 classification으로 해결하고
- Bounding Box는 Regressor로 해결한
이 부분이다.
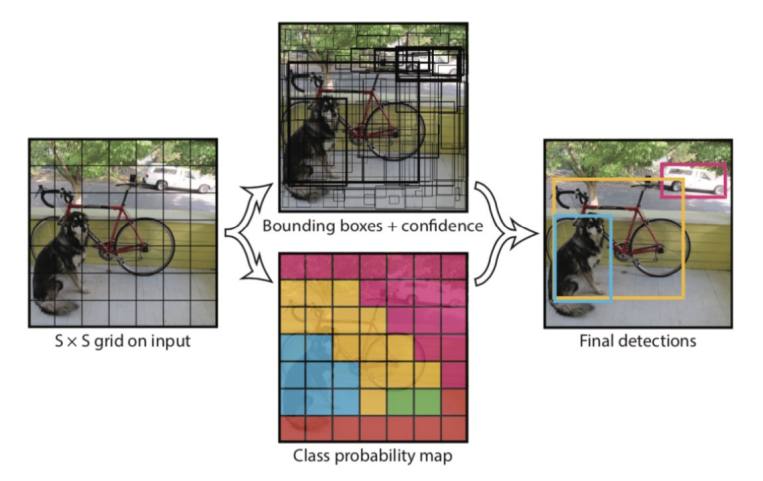
먼저 YOLO의 전체적인 흐름은 위 이미지를 생각하면 된다.
1 stage이기 때문에 YOLO는 한 번에 위 작업을 모두 수행하게 되는데
대략적인 흐름은 위 사진을 참고하자.
classification 전까지 YOLO는 GoogleNet을 변형한 형태를 띄고 있다.
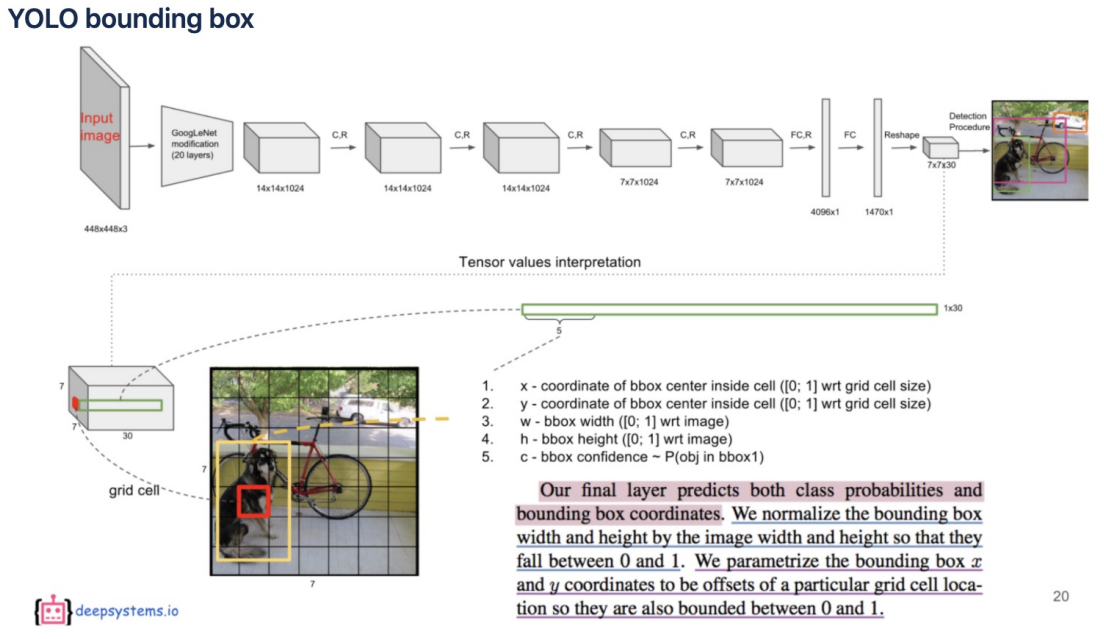
그리고 4번 과정에 대해 논문에서는 위와 같이 설명하여 강의에서도 위 자료로 설명을 해주셨는데 잘 이해가 되질 않았다 🫠

위 사이트에서는 사진과 같이 설명을 이해하기 쉽게 해두셔서 YOLO를 이해하는데 많은 도움을 받았다 😚
실제로 사용해보기
YOLOv3 를 배포하신 원작자분의 깃허브이다.
이를 clone하거나 다운받으면 되는데 나는 colab에 clone해주었다.
위 사이트를 참고하여 아래와 같이 순서대로 실행해본 결과,
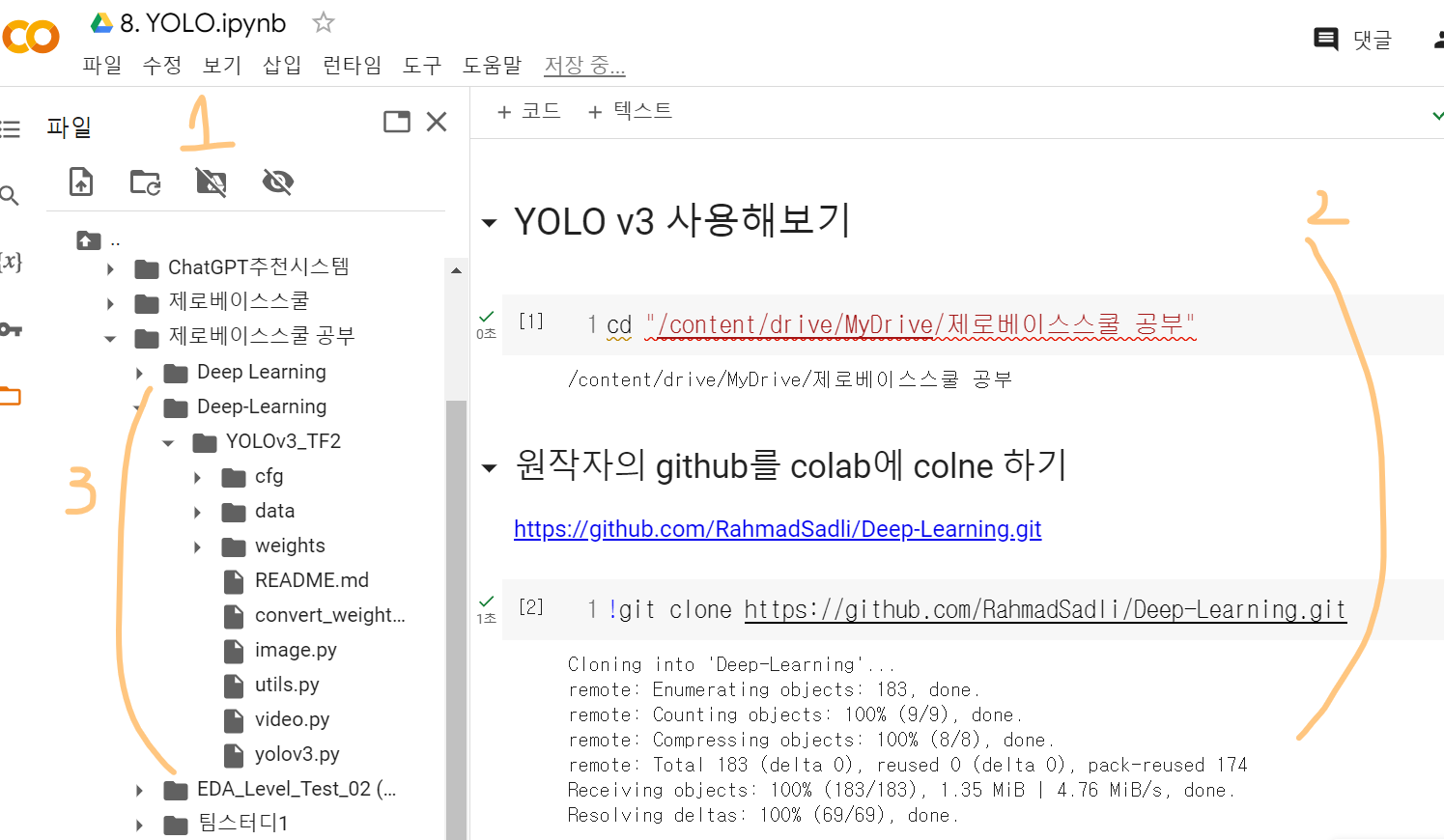
3번과 같이 나의 구글 드라이브에 YOLO v3가 clone되었다.
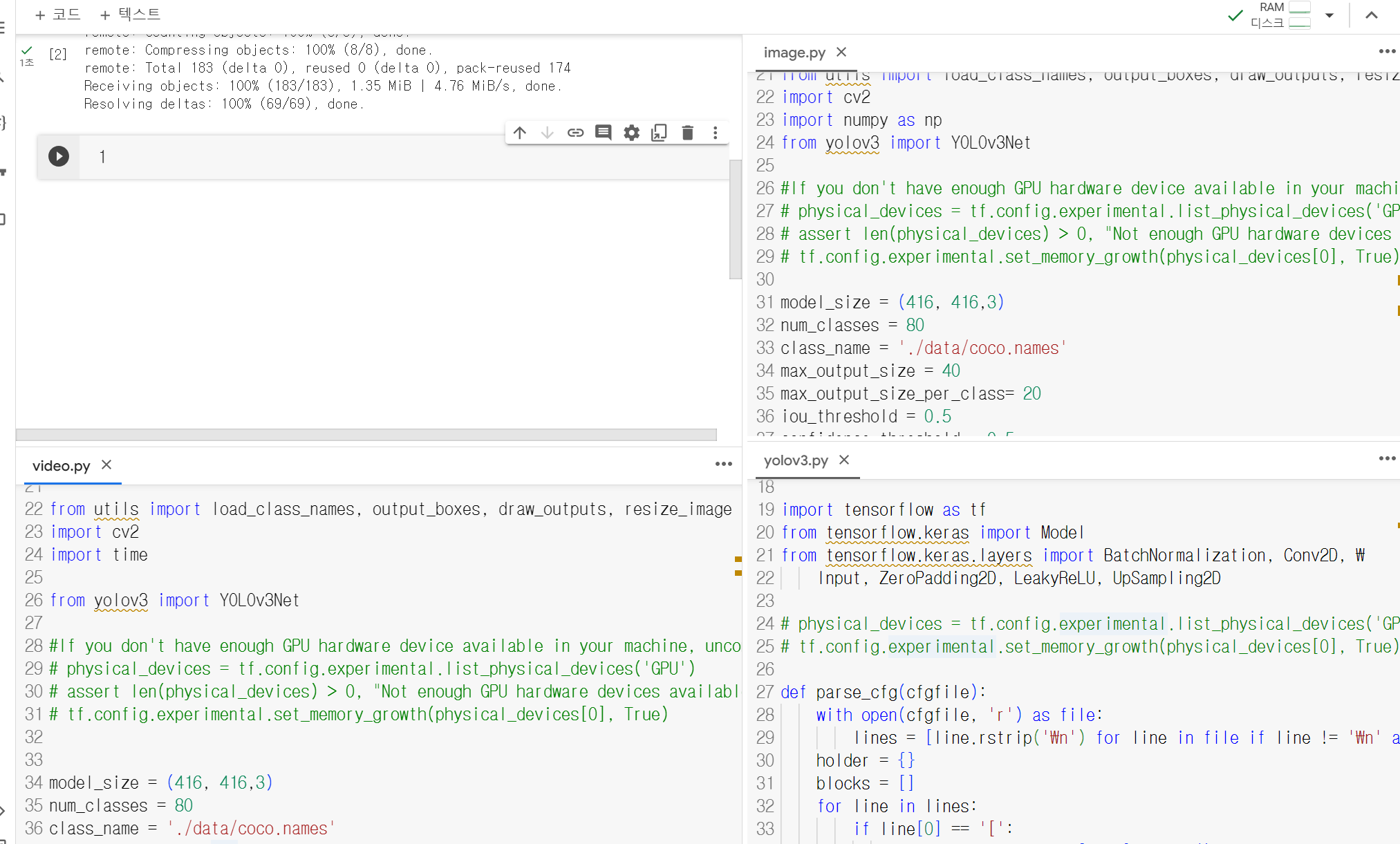
그리고 image.py, video.py, yolov3.py 파일을 열어 GPU를 가동시키는 부분을 주석처리 해주었다.
실제 모델을 학습시킬 때는 GPU가 필요하지만 우리는 그냥 이용만 할거라서 CPU에서도 충분히 사용가능하기 때문에 위와 같은 설정을 해주었다.
그 다음 !python convert_weight.py을 실행시키려했는데 convert_weight.py라는 파일이 없다고 떴다.
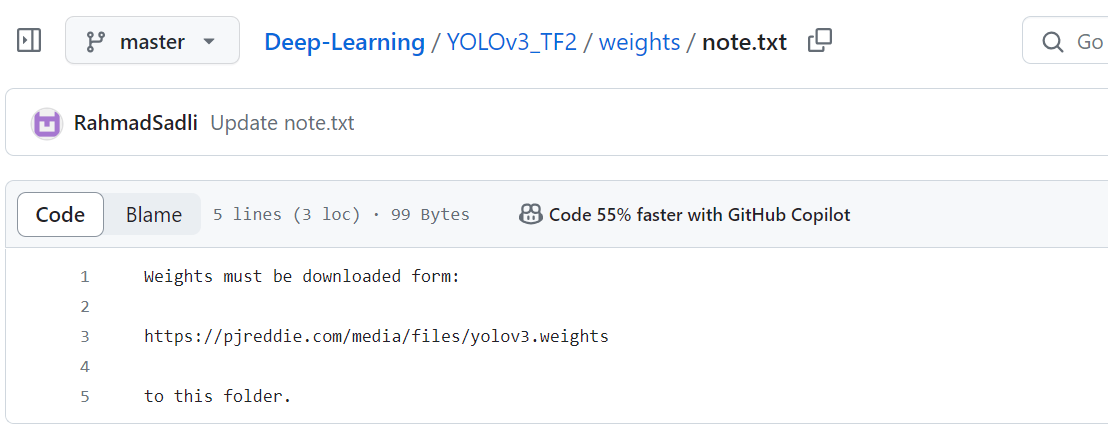
원작자의 깃허브에 weights 폴더의 글을 보니, 위와 같이 쓰여있었고 해당 링크를 통해 다운받은 convert_weight.py 파일을 weights 폴더에 넣어준 후 다시 실행시켰다.
(직접 실습해보려고 했는데.. 자꾸 실패해서 일단 시간 상 강의 내용만 학습했다)
