✍🏻 3일 공부 이야기.

오늘 공부한 실습코드는 위 깃허브에 올려두었습니다 :) 사진 클릭시 깃허브로 이동해요 !
텐서플로
딥러닝 프레임워크
🤔 딥러닝 프레임워크를 왜 공부해야할까?
먼저 딥러닝 알고리즘이 기존의 머신러닝 알고리즘과 다른 점이 있기 때문이다. 다른 점은 바로 <연산량>
입력받는 픽셀의 크기와 노드의 수가 증가함에 따라 연산량은 어마무시하게 커져버린다.
딥러닝의 성능이 안 나오는데에는 학습시키는 데이터가 부족하다는 이유가 있을 것이다.
어마어마한 연산량을 뚫고 파라미터를 최적화시키려면 데이터가 어느정도 있어야하기 때문이다.
또, 텍스트 데이터같은 경우는 이미지 데이터와 달리 수학적으로 표현하기 힘들다는 특징이 있다. 이런 수학적인 모델링이 힘든 것을 수학적으로 표현하려고 하니 연산량이 어마무시할 수 밖에 없을 것이다.
그렇다면 이 많은 연산량을 어떻게 처리할 수 있을까?
-
분산 처리, 병렬 처리, 동시 처리에서 답을 찾았고
이를 도와주는 것이 바로 <딥러닝 프레임워크>이다. -
그리고 분산 처리에 용이한 GPU를 이용하면 딥러닝을 그래프 형태로 만들어 많은 연산량을 커버하기 좋겠다는 생각으로 딥러닝 알고리즘은 발전해왔다고 한다.
딥러닝 프레임워크에는 아래와 같이 많은 종류가 있지만,

우리가 딥러닝 프레임워크를 왜 배워야하는지에 대해 알았으니 중요한 4가지만 할 줄 알면 하나의 딥러닝 프레임워크는 익혔다고 말할 수 있을 것이다.
1. Tensor를 생성하고 다루기(Tensor를 원하는 방향대로 다룰 수 있는가)

2. 연산 정의하기(모델을 어떻게 연결할 것인가)
3. 최적화(딥러닝 프레임워크는 미분을 어떻게 지원하는가)
4. 데이터 다루기(딥러닝 프레임워크마다 입력 데이터를 GPU에 보내는 명령어가 다른데, 그것을 알고 있는가)
+) 모델 파일 저장, 학습 과정 모니터링 등등 추가 요소가 있긴 함 😚😚
TensorFlow vs PyTorch
TensorFlow 와 PyTorch를 사용하는데에 있어서 어떤 차이점이 있는지 살펴보자.
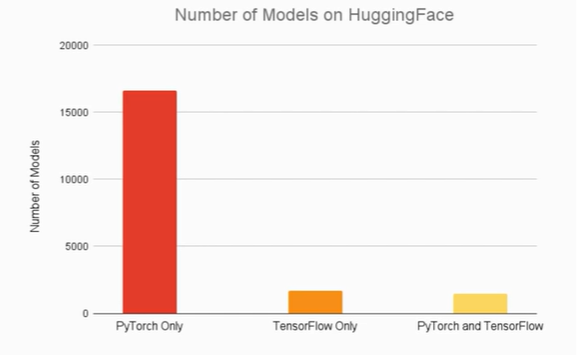
최근들어 많은 논문들이 TensorFlow 보다는 PyTorch를 사용하고 있는 것으로 보여졌다.
그렇다고 하더라도 구글의 연구나, Reinforcement Learning 분야, 상품화하기에는 여전히 TensorFlow를 많이 사용하고 있다.
우리는 둘 다 배워보쟈 :)
1. Tensor 다루기
import tensorflow as tf
[이번 챕터에서 기억해야할 것]
📌 Tensor를 다룰 땐
shape과dtype꼭 항상 체크하기
📌 Random seed 관리하기
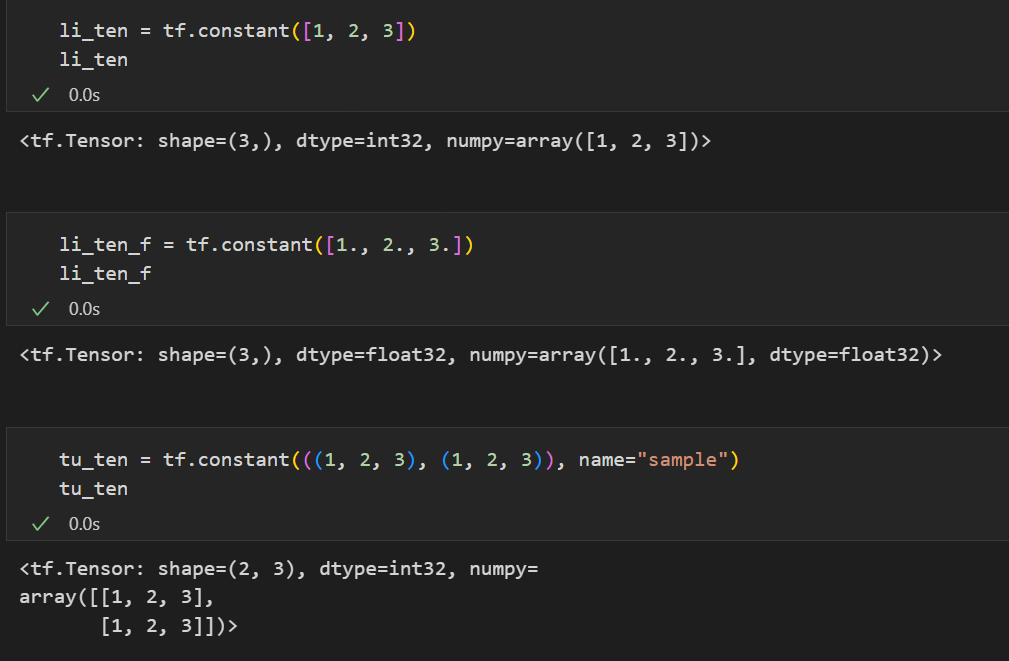
01. Constants(상수)
tf.constant(): 기존의 데이터 타입을 Tensor로 변환시켜줌
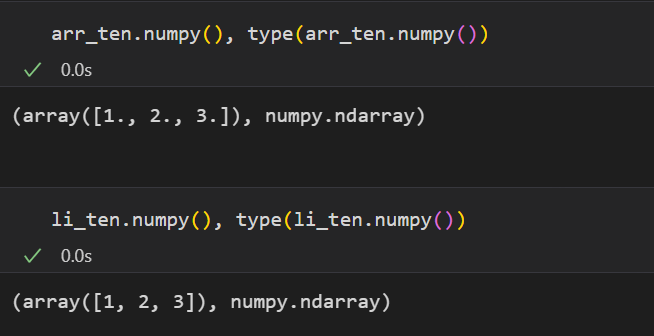
.numpy(): 데이터타입을 numpy로 변환시켜줌
Tensor의 shape과 dtype확인
Tensor를 다룰 때에는 제일 에러가 많이 나고, 제일 헷갈리는 이유가 shape과 dtype 때문이다.
🌟 따라서 Tensor를 다룬다면 shape과 dtype 꼭 항상 체크해주는 습관을 기르자.
.shape.dtype
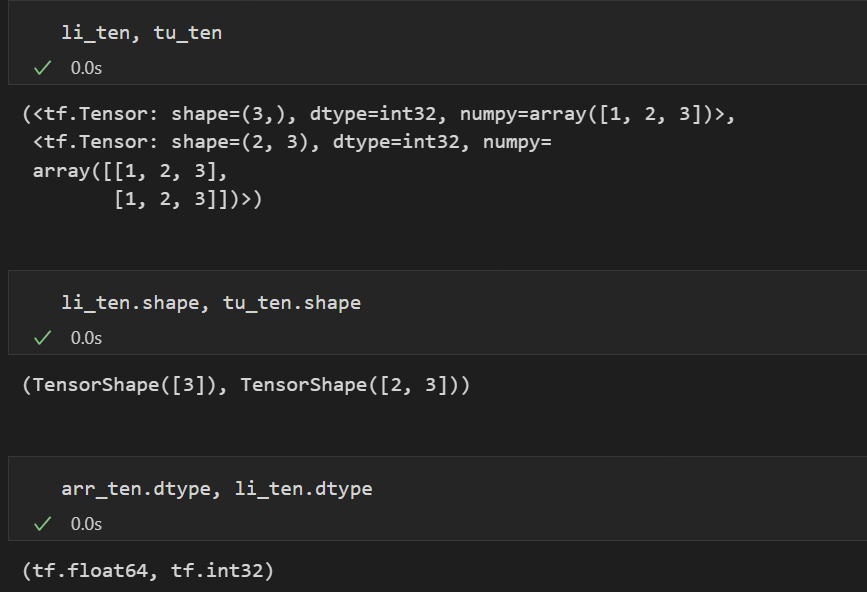
굳이 명령어가 아니더라도 변수를 출력할 때 shape과 dtype을 함께 보여준다.
연산이 되지 않는 이유에는 크게 3가지가 있다. 따라서 연산을 하기 전 각각을 확인하고 연산을 하는 습관을 꼭 길러두자.
- Dim이 맞지 않아 연산 불가
- Rank 수가 맞지 않아 연산 불가 ->
.ndim - Dtype이 맞지 않아 연산 불가
3번의 경우가 발생했다고 하자.
데이터 타입이 다른걸 확인했다면 데이터 타입을 맞춰주고 다시 연산을 진행시켜주면 된다.
3-1. 상수 선언 시, 데이터 타입을 미리 지정해주는 방법
3-2. tf.cast를 이용하여 이후에 데이터 타입을 지정해주는 방법
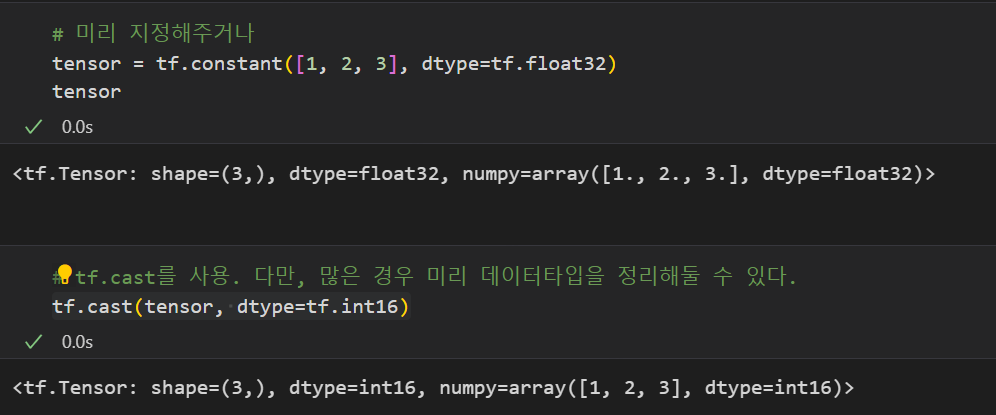
나머지 1, 2번의 경우는 이후 03_Tensor 연산 파트에서 알아보자.
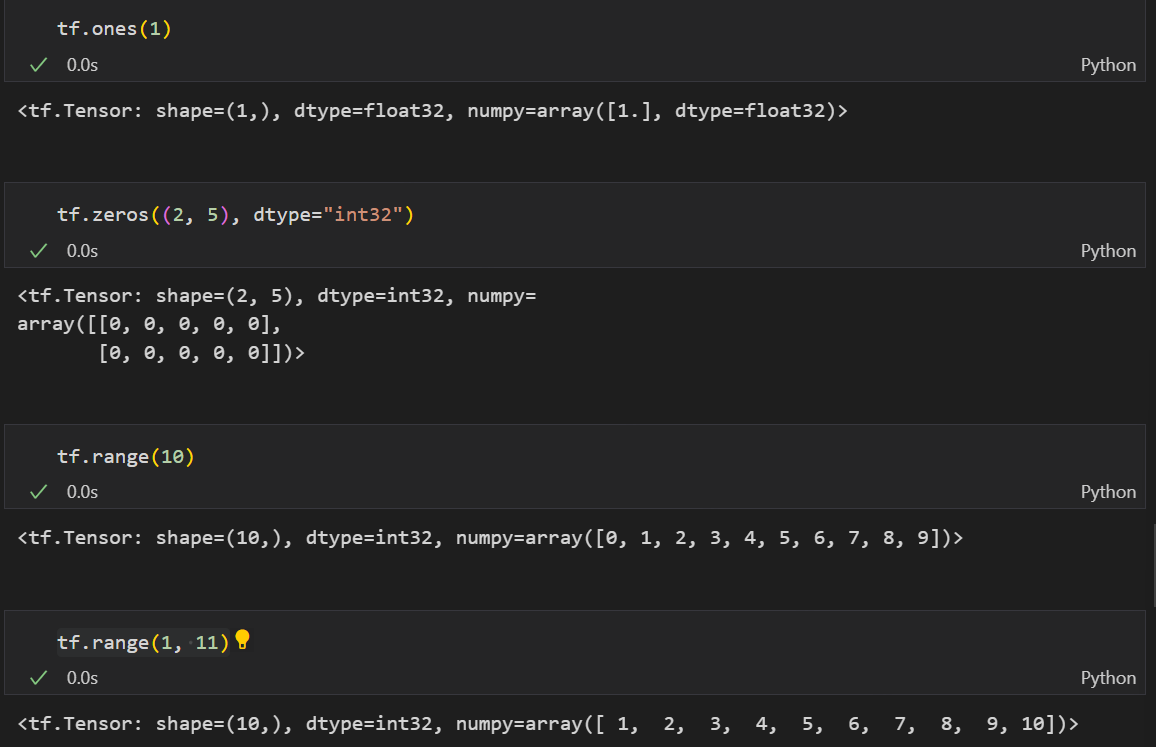
특정 값의 Tensor 생성
tf.ones: 1이 들어간 Tensor 생성tf.zeros: 0이 들어간 Tensor 생성tf.range: 설정한 숫자들의 Tensor 생성
Random Value 생성
Noise를 재현한다거나, Test를 할 때 무작위의 값을 생성하기 위해 난수를 많이 생성한다.
tf.random을 통해 난수를 생성할 수 있으며 대표적으로 tf.random.normal , tf.random.uniform을 많이 사용하나, 아주 많은 분포가 있으니 아래 사이트를 참고하길 바란다.
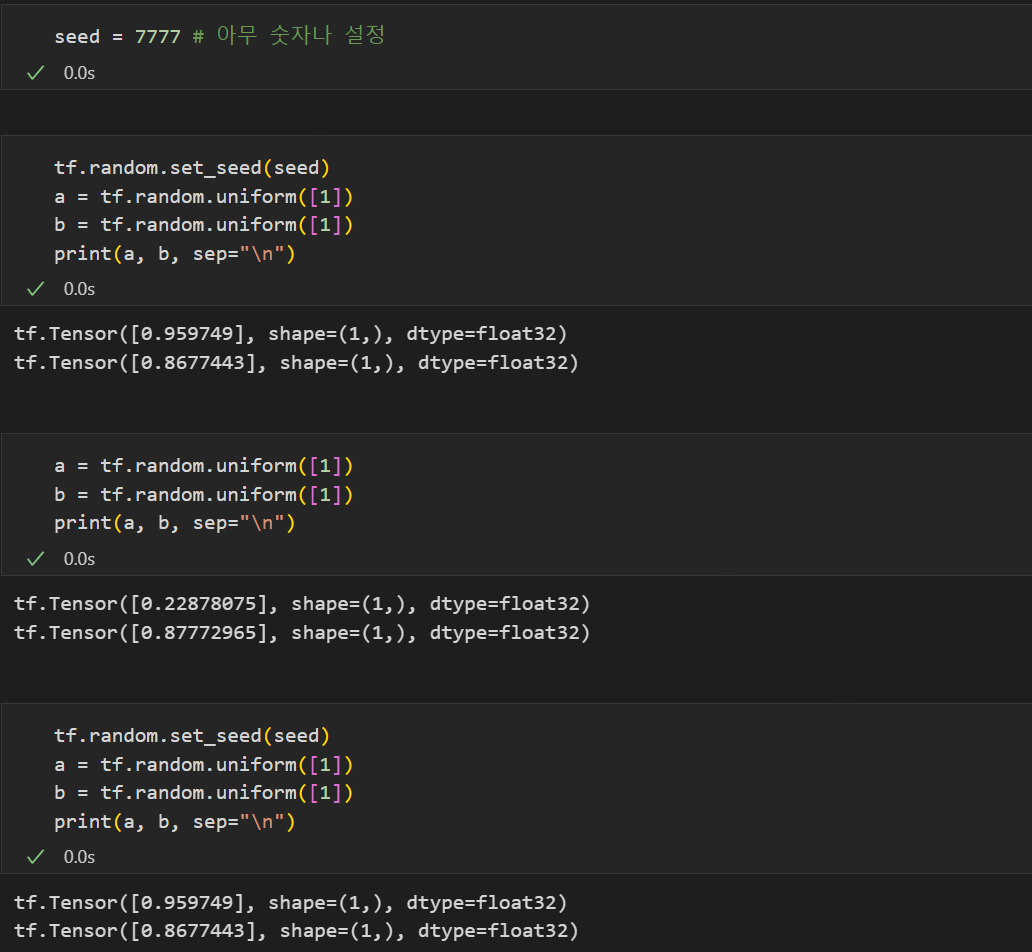
난수를 생성하는 것은 좋으나, 매번 난수가 바뀌어버리면 자신이 했던 작업이 동일하게 복구 또는 재현이 되질 않는다.
🌟 따라서 우리는 Random seed를 관리하는 습관도 기를 필요가 있다.
tf.random.set_seed(원하는 숫자)
원하는 숫자를 넣은 위 코드를 난수를 생성할 때마다 계속 출력하여 난수를 지정할 수 있다.
02_Variable(변수)
변수는 일정 메모리 공간을 만들어두고 해당 공간에 값을 넣어주어 사용하는 것이다.
tf.Variable을 통해 변수를 생성할 수 있다.
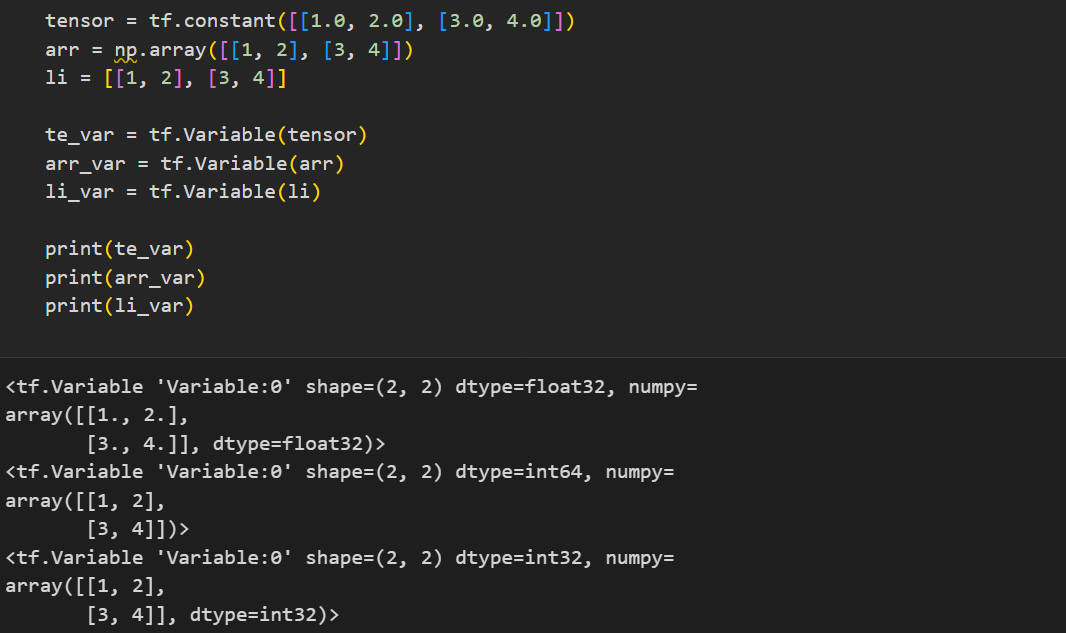
constant와 같이 .shape, .dtype, .numpy 등 기본 속성값들을 사용할 수도 있다.
또한 기존에 변수를 만들어 두었다 하더라도 텐서를 재할당할 수도 있다.
.assign(할당할 값)
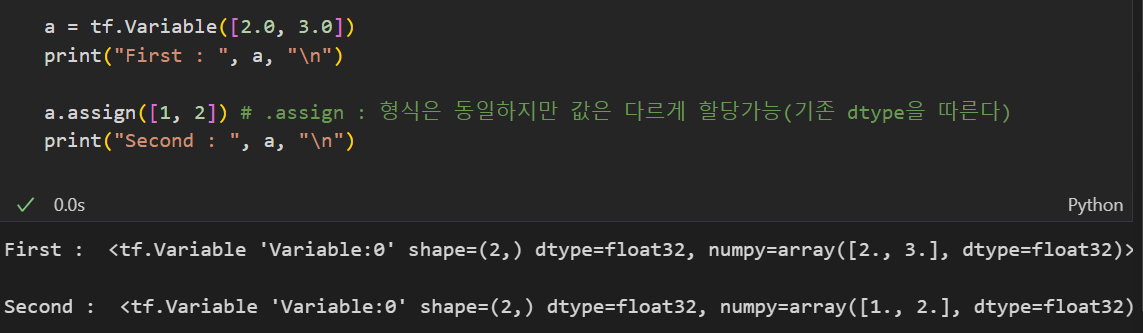
이때 dtype은 기존 dtype을 따르며 기존 메모리의 shape과 맞지 않으면 할당할 수 없다.
03_Tensor 연산
📌 Axis 이해하기
기존 연산자 기호를 사용해도 되는 연산자
tf.add: 덧셈tf.subtract: 뺄셈tf.multiply: 곱셈tf.divide: 나눗셈tf.pow: n-제곱tf.negative: 음수 부호
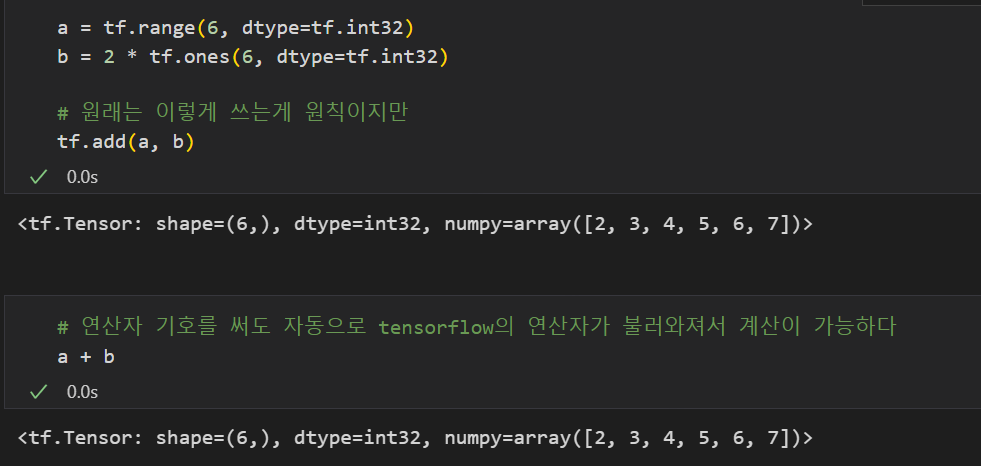
그 외 여러가지 연산자
tf.abs: 절대값tf.sign: 부호tf.round: 반올림tf.ceil: 올림tf.floor: 내림tf.square: 제곱tf.sqrt: 제곱근tf.maximum: 두 텐서의 각 원소에서 최댓값만 반환.tf.minimum: 두 텐서의 각 원소에서 최솟값만 반환.tf.cumsum: 누적합tf.cumprod: 누적곱
Axis 이해하기
기본적인 개념은 가장 바깥에서부터 axis 0이라 하고 안쪽으로 갈수록 axis가 깊어진다고 생각하면 된다.
2차원 텐서
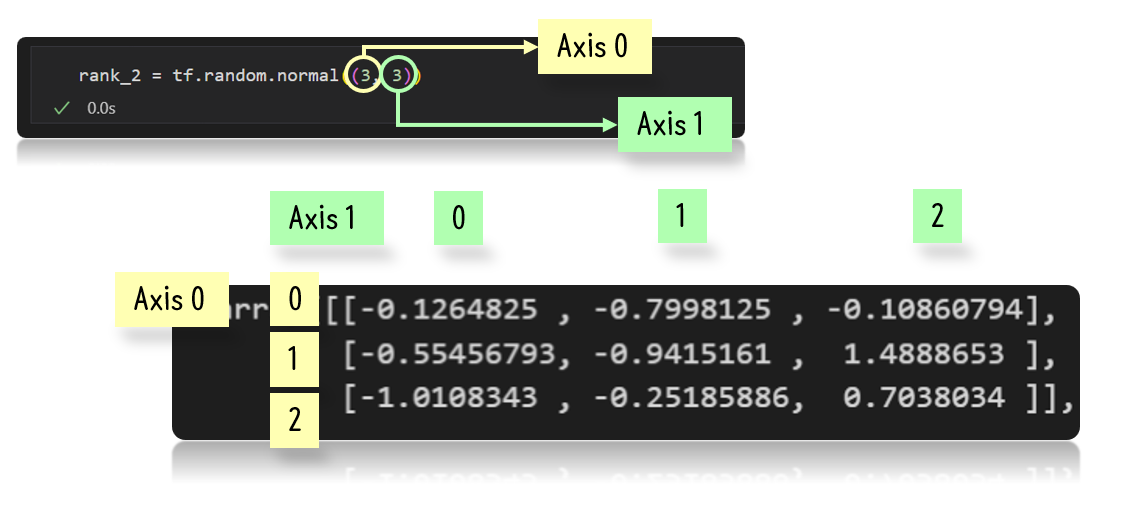
위와 같은 형태로 되어있어 아래와 같은 값이 나오게 된다.
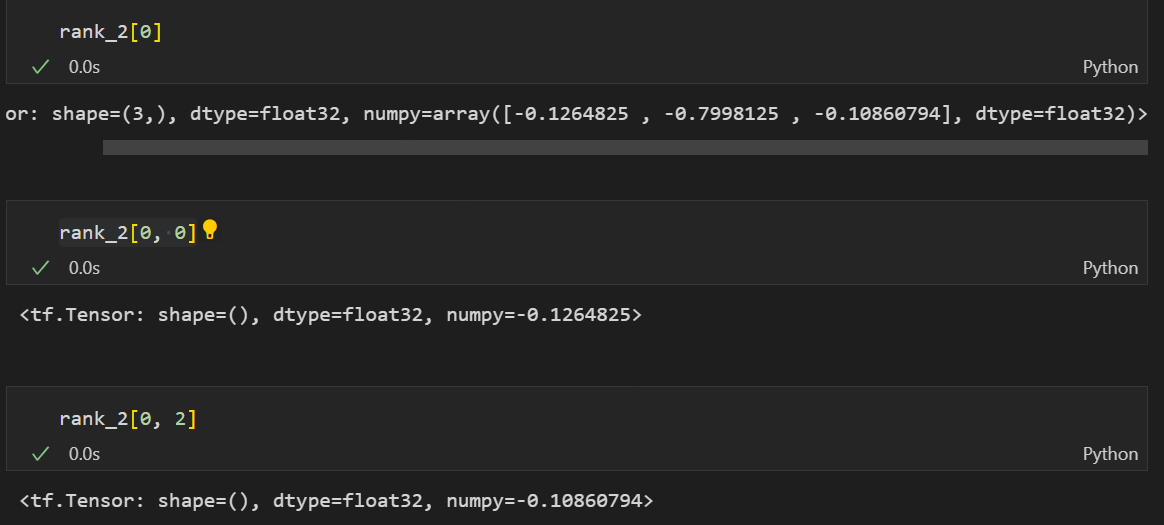
3차원 텐서
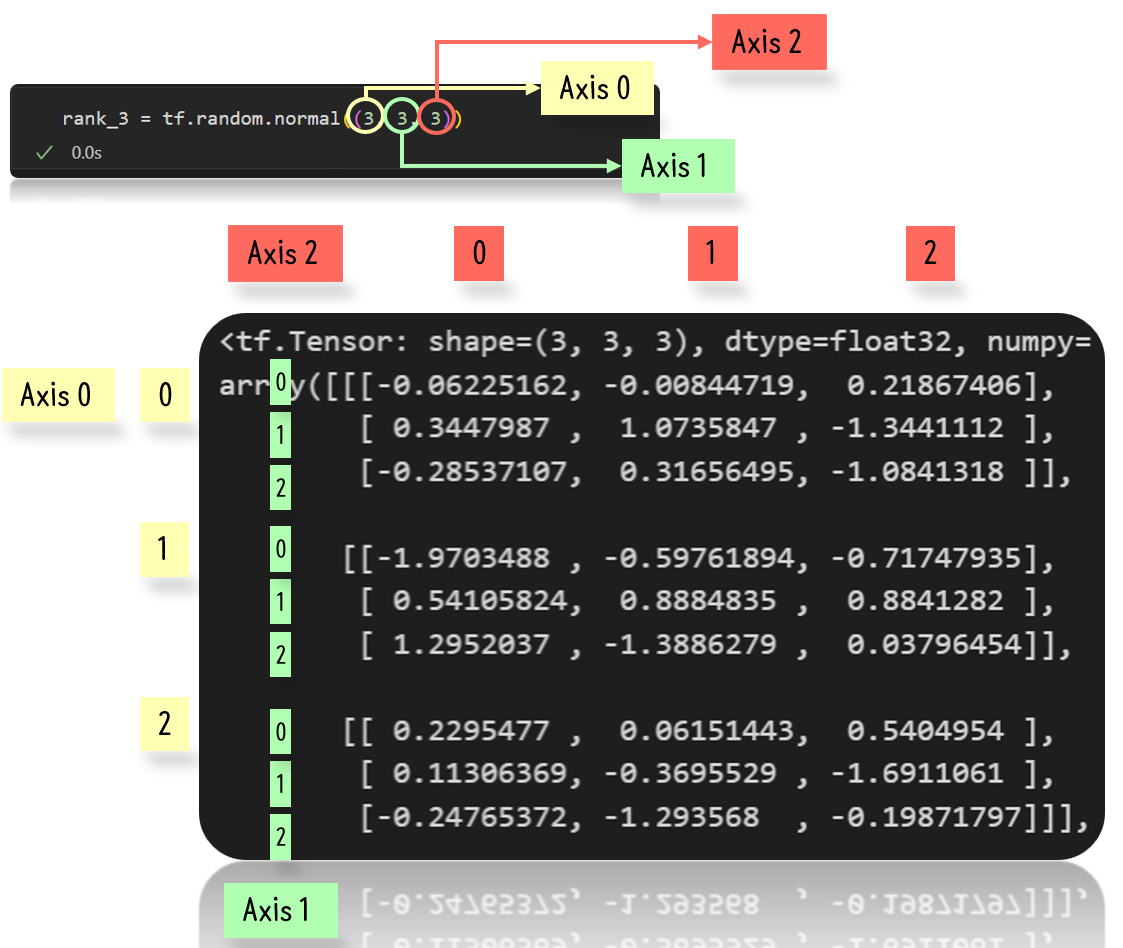
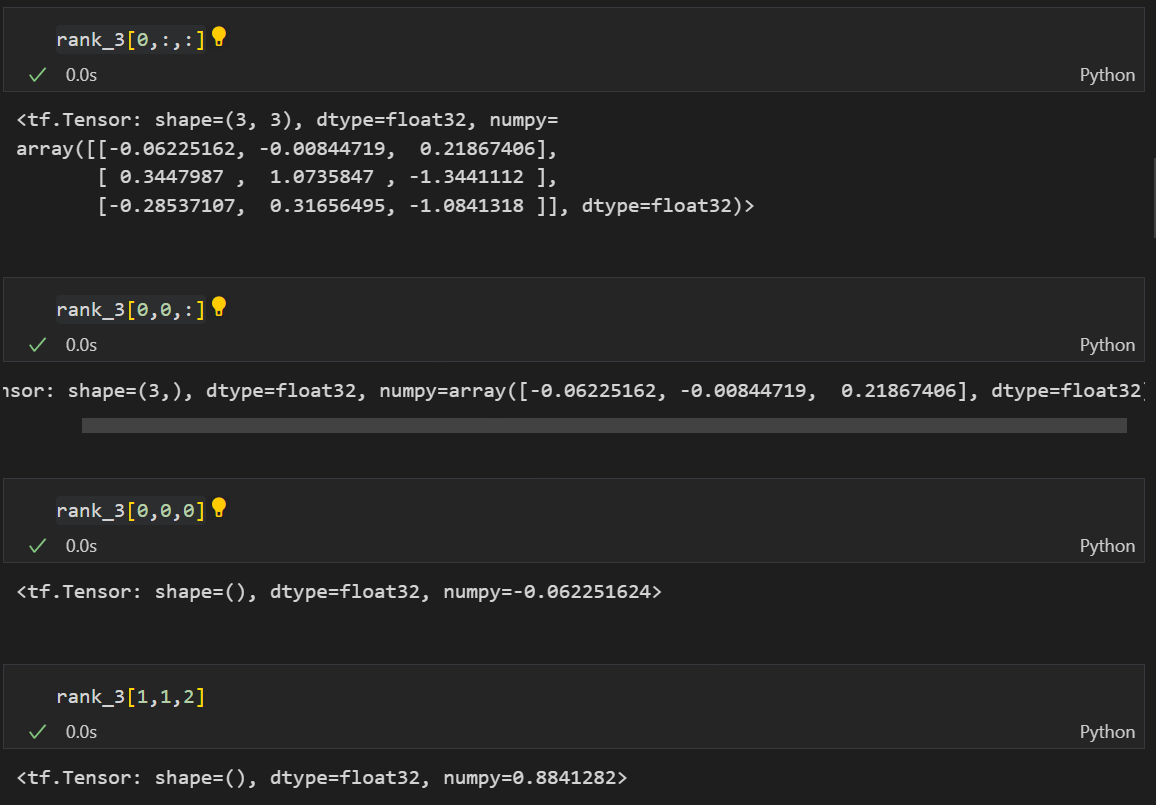
그리고 3차원 텐서도 위와 같이 바깥에서부터 axis 0이라고 생각하면 아래와 같이 원하는 위치에 있는 값을 추출할 수 있다.
차원 축소 연산
tf.reduce_mean: 설정한 축의 평균을 구한다.tf.reduce_max: 설정한 축의 최댓값을 구한다.tf.reduce_min: 설정한 축의 최솟값을 구한다.tf.reduce_prod: 설정한 축의 요소를 모두 곱한 값을 구한다.tf.reduce_sum: 설정한 축의 요소를 모두 더한 값을 구한다.
행렬 연산
tf.matmul: 내적tf.linalg.inv: 역행렬
🌟 크기 및 차원을 바꾸는 명령
그리고 앞서 크기와 차원이 맞지 않으면 연산이 되지 않는다고 언급한 적이 있다. 그런 경우 아래의 명령어를 통해 크기 및 차원을 맞춰준 후 연산을 진행하면 된다.
tf.reshape: 벡터 행렬의 크기 변환tf.transpose: 전치 연산tf.expand_dims: 지정한 축으로 차원을 추가tf.squeeze: 벡터로 차원을 축소
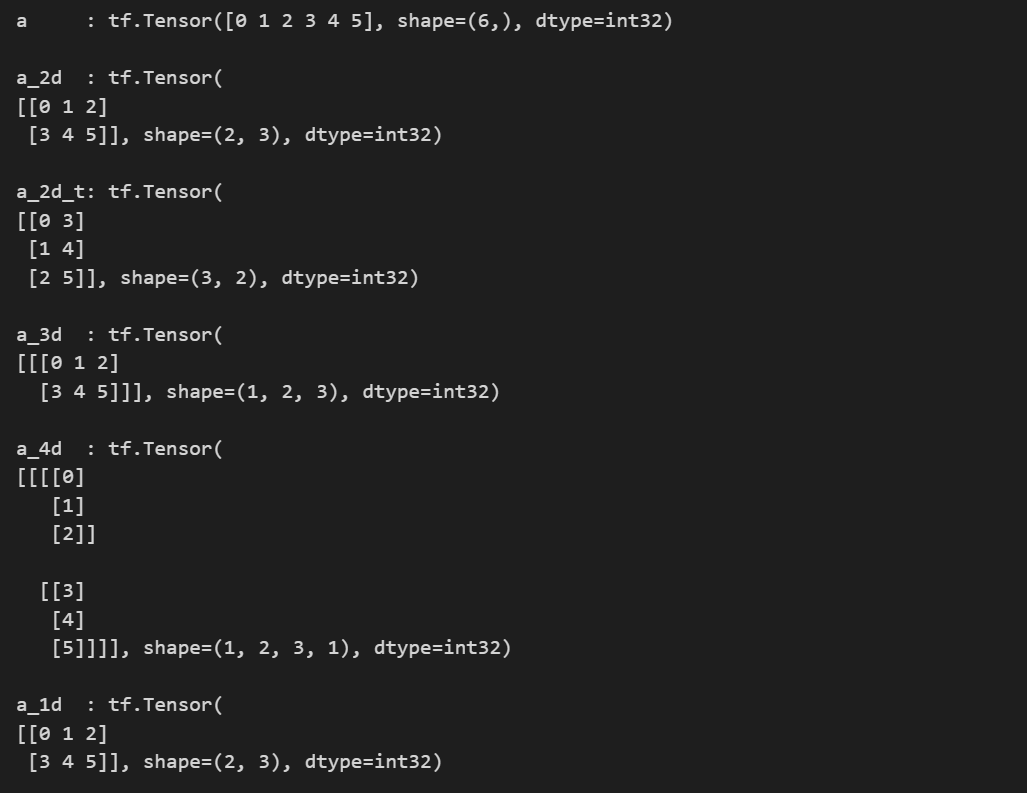
a = tf.range(6, dtype=tf.int32) # [0, 1, 2, 3, 4, 5]
print("a :", a, "\n")
a_2d = tf.reshape(a, (2, 3)) # 1차원 벡터는 2x3 크기의 2차원 행렬로 변환
print("a_2d :", a_2d, "\n")
a_2d_t = tf.transpose(a_2d) # 2x3 크기의 2차원 행렬을 3x2 크기의 2차원 행렬로 변환
print("a_2d_t:", a_2d_t, "\n")
a_3d = tf.expand_dims(a_2d, 0) # 2x3 크기의 2차원 행렬을 1x2x3 크기의 3차원 행렬로 변환
print("a_3d :", a_3d, "\n")
'''
딥러닝의 배치 개념(데이터를 한 묶음으로 바라볼 때)을 이용할 때 차원이 하나 더 필요하므로
0으로 설정 시, 기존 차원의 맨 앞에 차원 하나를 더 추가해줌
3(-1)으로 설정 시, 기존 차원의 맨 마지막에 차원 하나를 더 추가해줌
'''
a_4d = tf.expand_dims(a_3d, 3) # 1x2x3 크기의 3차원 행렬을 1x2x3x1 크기의 4차원 행렬로 변환
print("a_4d :", a_4d, "\n")
a_1d = tf.squeeze(a_4d) # 1x2x3x1 크기의 4차원 행렬을 1차원 벡터로 변환
print("a_1d :", a_1d, "\n")
'''
원소의 개수가 1개인 차원을 없애주는 역할
'''💻 출력
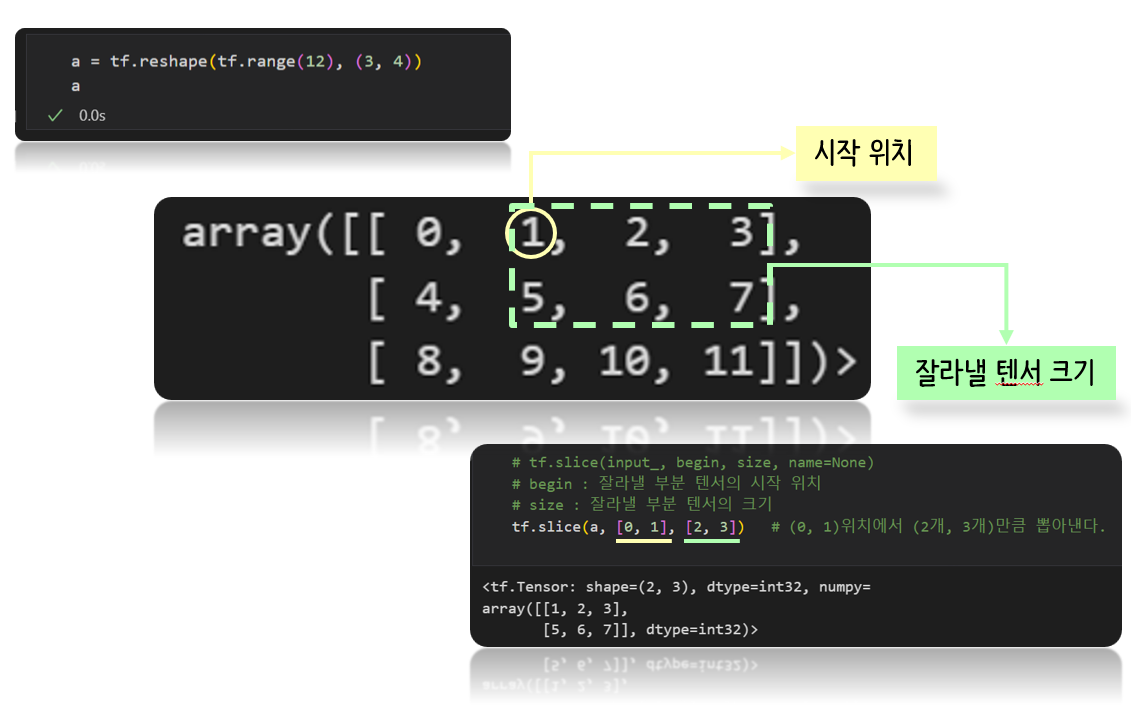
텐서를 나누거나 두 개 이상의 텐서를 합치는 명령
-
tf.slice: 특정 부분을 추출 -
tf.split: 분할
-
tf.concat: 합치기(rank가 동일)
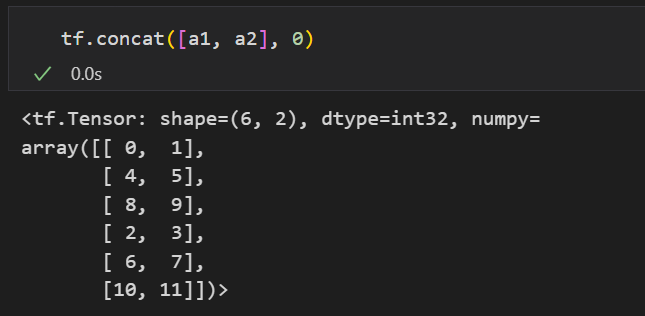
-
tf.tile: 복제-붙이기 -
tf.stack: 합성(concat과 달리 추가적으로 차원을 붙이며 합쳐줌)
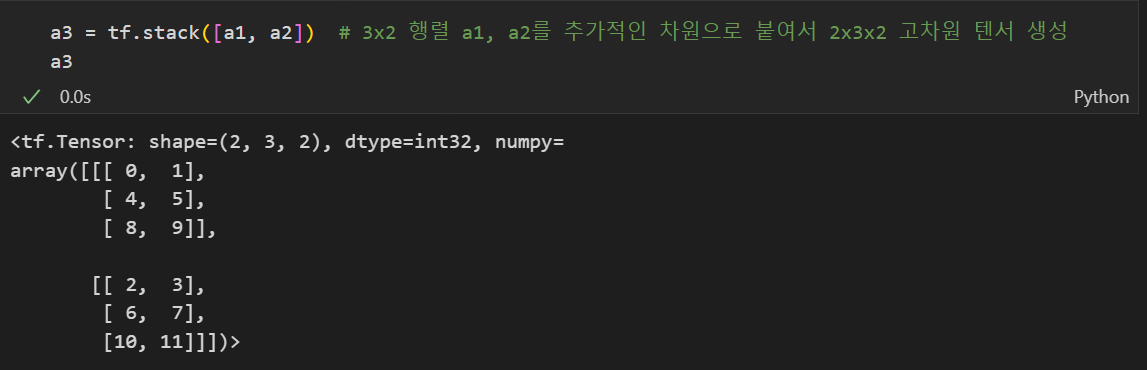
-
tf.unstack: 분리
2. 최적화
자동 미분
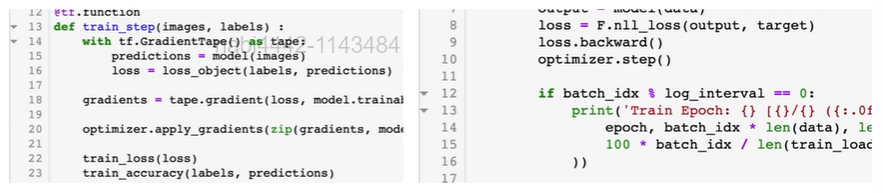
tf.GradientTape
tf.GradientTape는 컨텍스트(context) 안에서 실행된 모든 연산을 테이프(tape)에 "기록"한다.
그 다음 텐서플로는 후진 방식 자동 미분(reverse mode differentiation)을 사용해 테이프에 "기록된" 연산의 그래디언트를 계산하는 흐름으로 진행된다.
딥러닝은 loss라는 스칼라를 모델의 가중치들인 벡터로 미분시키는 작업이므로 스칼라를 벡터로 미분하는 실습을 해보자면 아래와 같다.
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
# 하고자하는 연산 진행
# persistent=True : 2번 이상 부를 때 에러가 나지 않기 위함
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b # 원하는 함수 식
loss = tf.reduce_mean(y**2) # loss 식
# 미분 계산
# tape.gradient(무엇을 , 뭐로)
# 방법 1. 리스트로 받기
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
# 방법 2. 딕셔너리 형태로 받기
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b'] # <tf.Tensor: shape=(2,), dtype=float32, numpy=array([ 0.5419482, -1.9879353], dtype=float32)>위와 같이
1. with문 안에 원하는 loss 계산을 해주고 그것을 tape라 칭한다음,
2. tape.gradient()로 미분값을 받으면 된다.
만약에 이때 미분 기록을 하고 싶지 않은 변수가 있다면 trainable 옵션을 False로 설정해주면 된다.
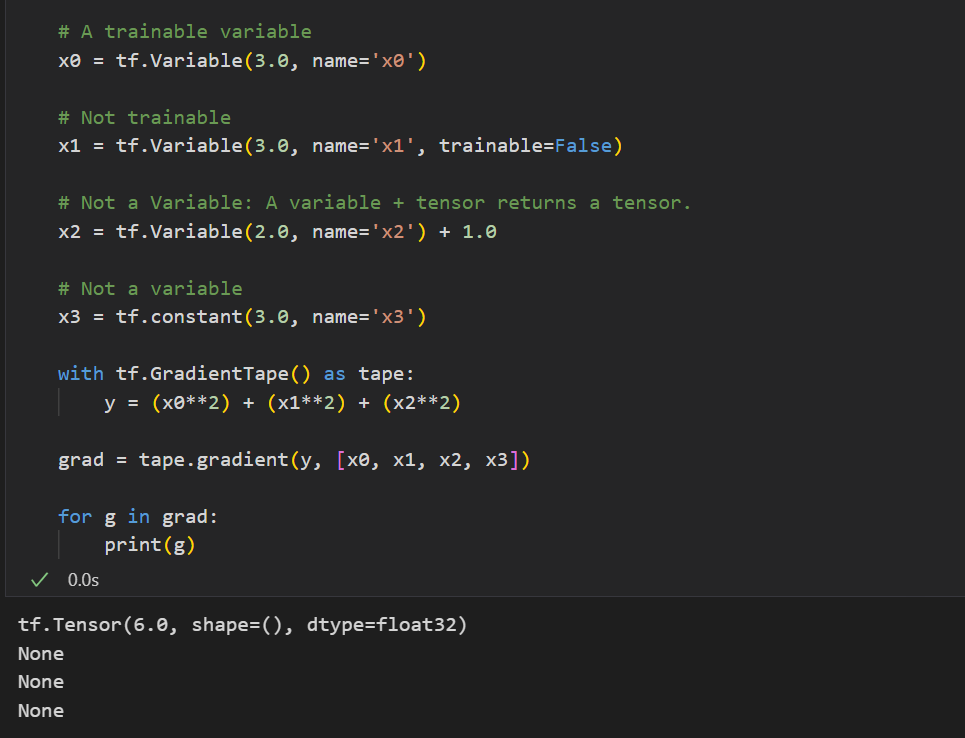
기록되고 있는 variable이 무엇인지 확인하고 싶다면 watched_variables()을 통해 확인 가능!

linear regression
가상의 데이터셋을 만들어 확인해보자.
📌 가상의 데이터셋 준비
lr = 0.03
# 실제 가중치의 값
W_true = 3.0
B_true = 2.0
X = tf.random.normal((500, 1)) # X값
noise = tf.random.normal((500, 1)) # noise 값
y = X * W_true + B_true + noise이제 실제값들을 미분하여 해당 가중치들이 나오는지 확인해보자.
# 미분을 구하기 위해 사용될 변수들
w = tf.Variable(5.)
b = tf.Variable(0.)
# 학습 과정을 기록하기 위한 변수들
w_records = [w.numpy()]
b_records = [b.numpy()]
loss_records = []
for epoch in range(100): # 500개의 데이터셋을 100번 돌겠다.
# 매 epoch마다 한 번씩 학습
with tf.GradientTape() as tape:
y_hat = X * w + b
loss = tf.reduce_mean(tf.square(y - y_hat)) # mse
dw, db = tape.gradient(loss, [w, b]) # gradient 값이 저장됨
w.assign_sub(lr * dw) # w.assign(w - lr * dw) 와 동일한 기능
b.assign_sub(lr * db)
# 학습 과정 저장
w_records.append(w.numpy())
b_records.append(b.numpy())
loss_records.append(loss.numpy())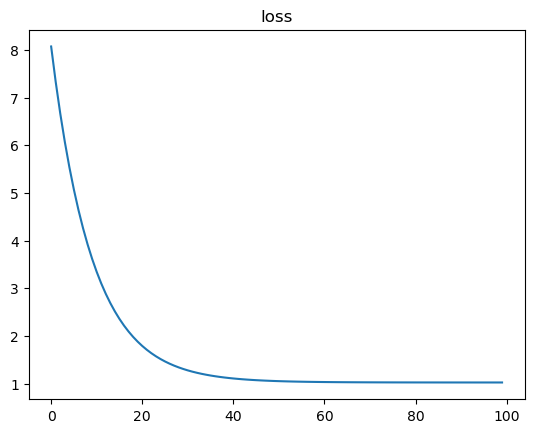 loss loss | 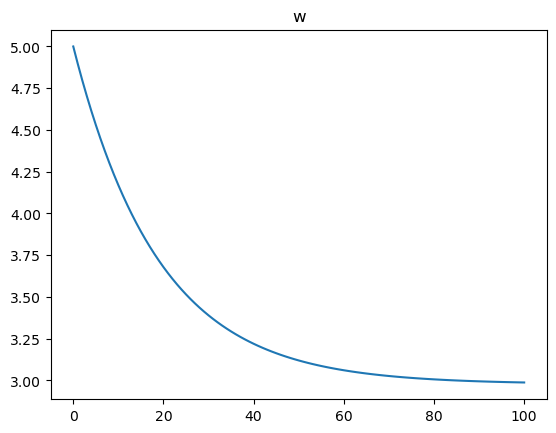 w w | 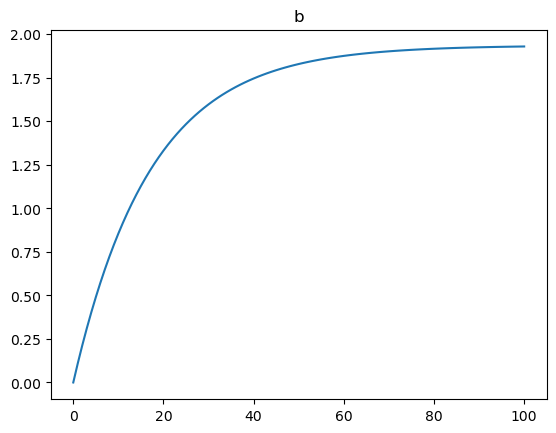 b b |
|---|
loss는 점점 떨어지고 w와 b는 w_true와 b_true에 점점 가까워지는 형태를 띄고 있으므로 잘 학습이 되는 것 같다.
linear regression - 당뇨병 데이터
이번에는 실제 데이터를 이용해 lineaer regression을 학습해보자.
📌 데이터 준비
from sklearn.datasets import load_diabetes
import pandas as pd
import numpy as np
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names, dtype=np.float32)
df['const'] = np.ones(df.shape[0])역행렬을 이용한 가중치 구하는 방식

이때 const 변수를 생성해 주었다.
이 덕분에 bias는 const의 가중치가 되므로 우리는 가중치만 고려하면 된다!
📌 shape 확인
diabetes.target.shape # (442,)
X = df
y = np.expand_dims(diabetes.target, axis = 1)
X.shape, y.shape # ((442, 11), (442, 1))그 전에 target의 차원을 하나 늘려줌으로써 X와 y의 차원을 맞춰주었다.
지금 당장은 에러가 안 날 수 있지만 후 작업에 에러가 날 수 있는 경우의 수를 줄여주기 위해 이렇게 맞춰주는 습관을 길러두는 것이 좋다.
📌 예측
# tf.transpose(X)는 많이 사용되므로 따로 정의해두자.
XT = tf.transpose(X)
w = tf.matmul(tf.matmul(tf.linalg.inv(tf.matmul(XT , X)), XT), y)
y_pred = tf.matmul(X, w)
print("예측한 진행도 :", y_pred[0].numpy(), "실제 진행도 :", y[0])
print("예측한 진행도 :", y_pred[19].numpy(), "실제 진행도 :", y[19])
print("예측한 진행도 :", y_pred[31].numpy(), "실제 진행도 :", y[31])💻 출력
예측한 진행도 : [206.11667747] 실제 진행도 : [151.]
예측한 진행도 : [124.01754101] 실제 진행도 : [168.]
예측한 진행도 : [69.47575835] 실제 진행도 : [59.]
SGD 방식
SGD를 사용하고 가중치는 Gaussian normal distribution 난수로 초기화된 것을 사용하며 lr는 0.03, 100 iteration을 도는 과정을 코드로 짜보자.
# 정의
lr = 0.03
num_iter = 100
w_init = tf.random.normal([df.shape[1], 1], dtype=tf.float64)
w = tf.Variable(w_init)
# 학습 과정을 기록하기 위한 변수들
w_records = [w.numpy()]
loss_records = []
for epoch in range(num_iter):
with tf.GradientTape() as tape:
y_hat = tf.matmul(X, w)
loss = tf.reduce_mean(tf.square(y - y_hat))
dw = tape.gradient(loss, w)
w.assign_sub(lr * dw)
# 학습 과정 저장
w_records.append(w.numpy())
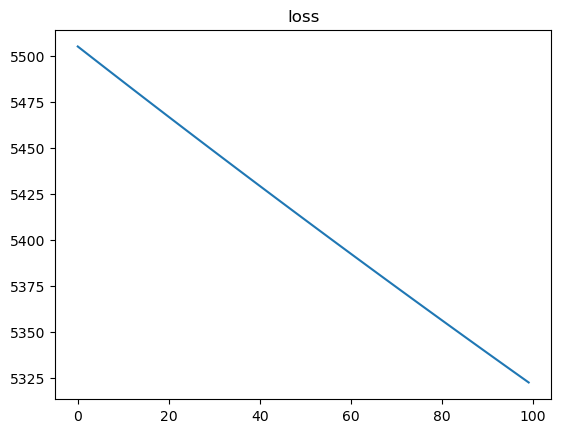
loss_records.append(loss.numpy())📌 확인
plt.plot(loss_records)
plt.title('loss')
plt.show()
print("예측한 진행도 :", y_hat[0].numpy(), "실제 진행도 :", y[0])
print("예측한 진행도 :", y_hat[19].numpy(), "실제 진행도 :", y[19])
print("예측한 진행도 :", y_hat[31].numpy(), "실제 진행도 :", y[31])💻 출력
예측한 진행도 : [155.91650454] 실제 진행도 : [151.]
예측한 진행도 : [146.29034167] 실제 진행도 : [168.]
예측한 진행도 : [140.40297749] 실제 진행도 : [59.]
퍼셉트론
퍼셉트론은 classification에 쓰이는 모델 중 하나로,
입력특성에 대한 가중합이 threshold를 넘는지 아닌지를 기준으로 1 또는 -1의 클래스를 예측하는 모델이다.
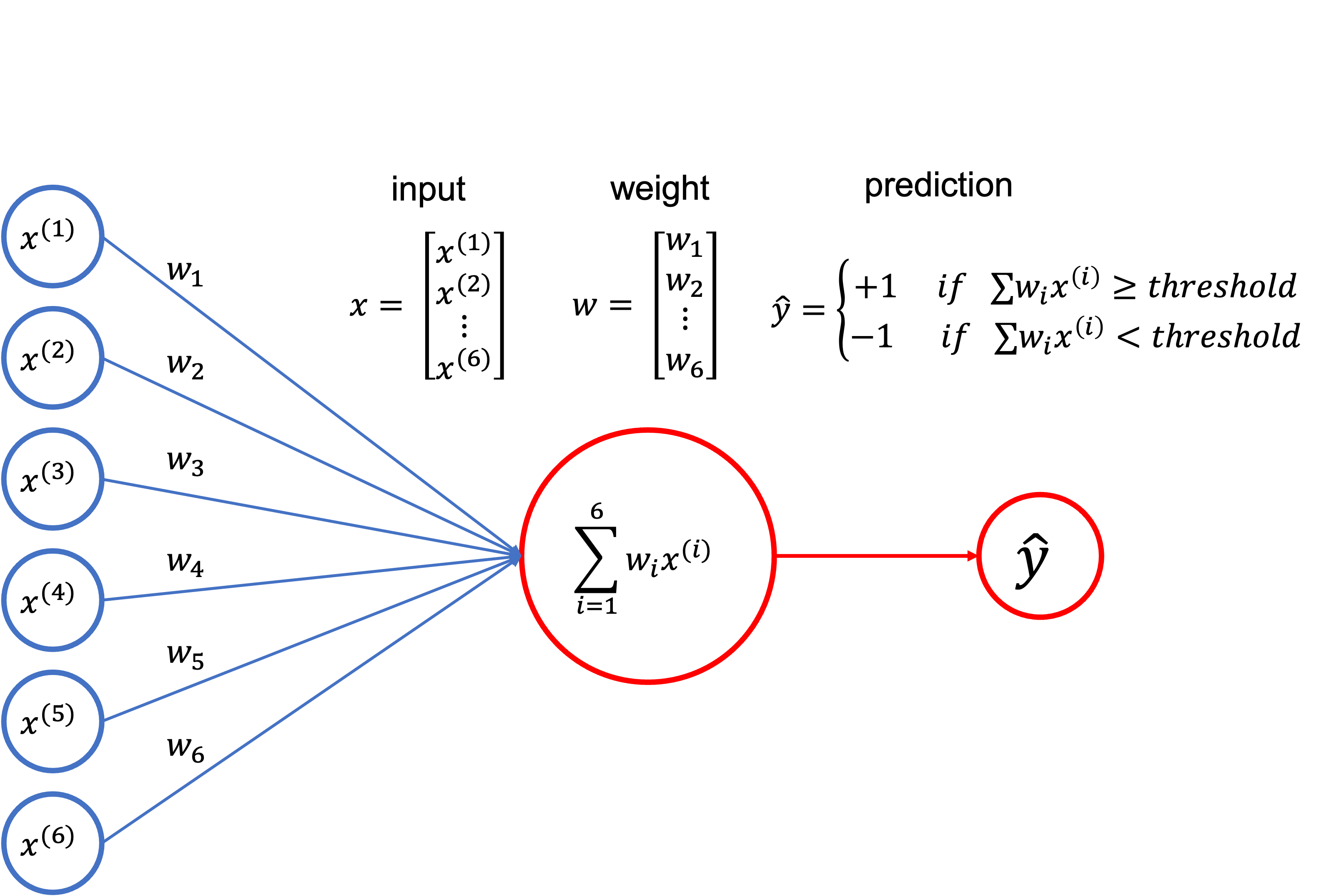
따라서 비용함수로 쓰는 아래의 식은
실제값과 예측값이 다른 데이터의 개수로도 생각할 수 있는데 그 이유는 아래와 같다.
-
실제값과 예측값이 같은 경우 (-1, -1) 또는 (1, 1)가 되므로 는 음수가 된다. 따라서 Loss는 0이 될 것이다.
-
반대로 실제값과 예측값이 다른 경우((-1, 1) 또는 (1, -1))에 는 양수가 되므로 Loss는 1이 될 것이다.
iris 데이터를 이용해 Perceptron을 구현해보자.
📌 데이터 준비
from sklearn.datasets import load_iris
iris = load_iris()
idx = np.in1d(iris.target, [0, 2]) # setosa와 virginica 클래스만 사용
X_data = iris.data[idx, 0:2] # feature로 sepal 컬럼만 사용
y_data = (iris.target[idx] - 1.0)[:, np.newaxis]
X_data.shape, y_data.shape # ((100, 2), (100, 1))📌 Perceptron 구현
데이터 하나당 한 번씩 weights가 업데이트하고 learning_rate는 0.0003, iteration 은 500 인 Perceptron을 구현해보자.
# 정의
num_iter = 500
lr = 0.0003
# 가중치 초기 설정
w_init = tf.random.normal([X_data.shape[1], 1], dtype=tf.float64)
w = tf.Variable(w_init)
b_init = tf.random.normal([1, 1], dtype=tf.float64)
b = tf.Variable(b_init)
# Perceptron
zero = tf.constant(0, dtype=tf.float64) # 그냥 0으로 써도 됨
for epoch in range(num_iter):
# 데이터 하나당
for i in range(X_data.shape[0]):
# shape을 맞춰주기 위함
x = X_data[i:i+1] #expand_dims를 써도 됨
y = y_data[i:i+1]
with tf.GradientTape() as tape:
y_hat = tf.tanh(tf.matmul(x, w) + b)
loss = tf.maximum(zero, tf.multiply(-y, y_hat))
dw, db = tape.gradient(loss, [w, b])
w.assign_sub(lr * dw)
b.assign_sub(lr * db)
# 확인
y_pred = tf.tanh(tf.matmul(X_data, w) + b)
print("예측치 :", -1 if y_pred[0] < 0 else 1, "정답 :", y_data[0])
print("예측치 :", -1 if y_pred[51] < 0 else 1, "정답 :", y_data[51])
print("예측치 :", -1 if y_pred[88] < 0 else 1, "정답 :", y_data[88])💻 출력
예측치 : -1 정답 : [-1.]
예측치 : 1 정답 : [1.]
예측치 : 1 정답 : [1.]
그리고 -1과 1로 분류될 수 있도록 예측치를 작업해주고 실제값과 비교해서 성능을 평가하면 된다.
간단한 모델 학습하기
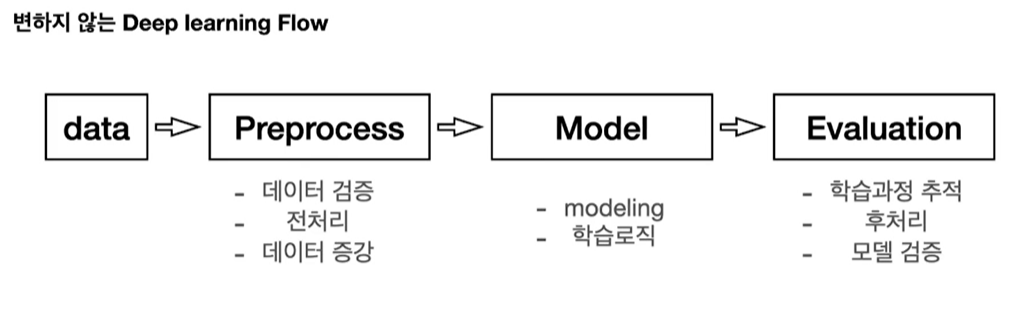
일반적으로 딥러닝 프로젝트를 한다면 위와 같은 4단계의 흐름으로 프로젝트가 진행될 것이다. 이번에는 전반적인 흐름에 대해 알아보자.
Deep Learning Flow
MNIST 데이터를 실습해보자.
먼저, .shape , .dtype을 이용해 데이터의 shape과 dtype을 확인해주어야한다.(기본 중에 기본!!!)
그리고 하나의 데이터를 추출하여 데이터가 어떻게 생겼는지 볼 필요가 있다.
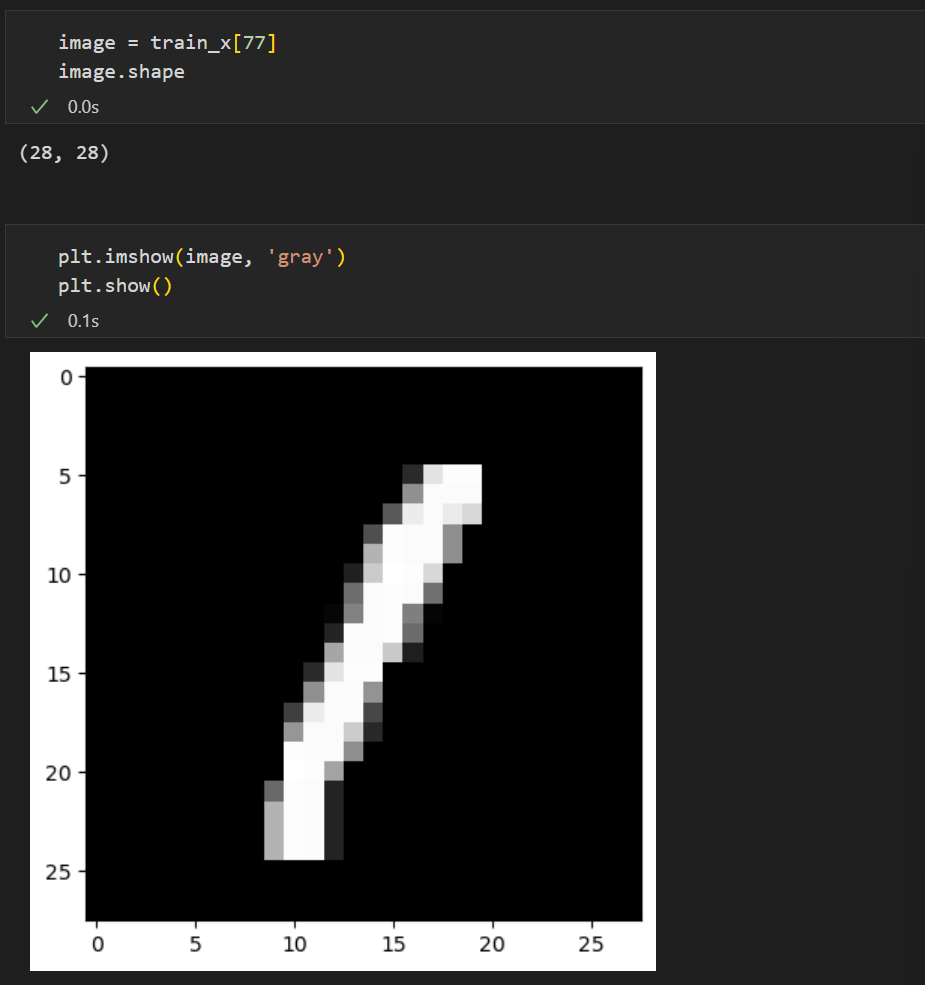
이렇듯 데이터를 받으면 데이터를 이해하기 위해 많은 노력을 할 것...!!
데이터셋에 각 숫자의 그림이 몇 개씩 얼만큼 들어있는지 확인(target 데이터 분포 확인)도 할 수 있다.
y_unique, y_counts = np.unique(train_y, return_counts=True)물론 이렇게 보는 것보단, 데이터프레임화하거나 시각화하여 보는게 더 좋겠지??
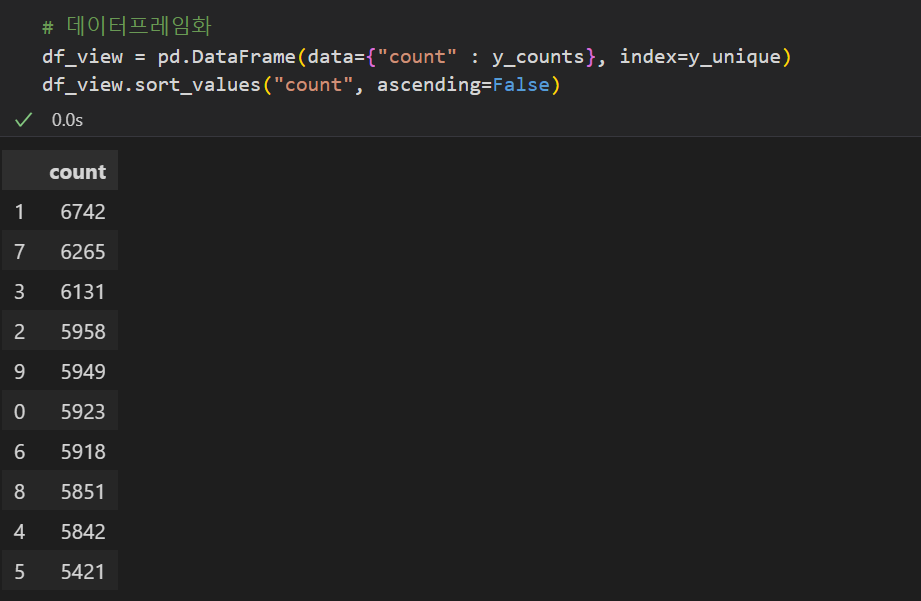 | 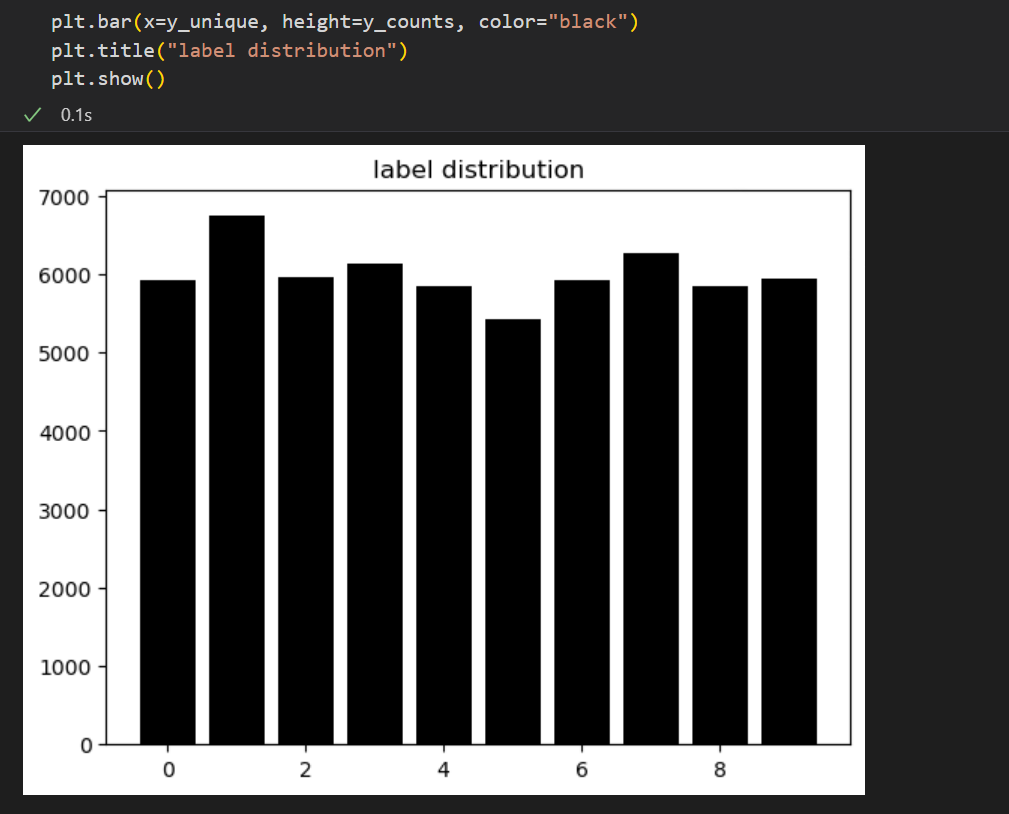 |
|---|
Preprocessing
Preprocessing 단계에는 데이터 검증, 전처리, 데이터 증강 등이 포함된다. 이런 작업들을 거쳐 모델의 입력값이 될 수 있게끔 변형시켜주는 것이 이 단계의 목적이다.
데이터 검증
데이터 검증이란, 데이터 중에 학습에 포함되면 안 되는 것이 있는지 , (개인정보가 들어간 데이터, 테스트용 데이터, 중복 데이터 등) 학습 의도와 다른 데이터가 있는지, 라벨이 잘못된 데이터가 있는지를 확인하는 과정이다.
예를 들어 아래의 코드는 픽셀 값이 이상한 데이터를 걸러내는 작업으로 아래와 같이 함수를 적용시켜 데이터 검증을 할 수 있다.
# preprocessing할 때 로직에 대한 실수를 하지 않기 위해
# 함수와 클래스로 구현을 많이 함
def validate_pixel_scale(x):
return 255 >= x.max() and 0 <= x.min() # 픽셀값이 이상한 데이터는 걸러내는 작업
validated_train_x = np.array([x for x in train_x if validate_pixel_scale(x)])
validated_train_y = np.array([y for x, y in zip(train_x, train_y) if validate_pixel_scale(x)])
# 걸러진 데이터가 있는지 shape 확인
print(validated_train_x.shape)
print(validated_train_y.shape)전처리
전처리 단계는 입력하기 전에 모델링에 적합하게 처리하기 위한 단계로 Scaling, Resizing, label encoding 등이 있다.
이 또한 전처리 후 dtype, shape 체크는 기본!!
아래는 Scaling을 진행한 과정이다.
def scale(x):
return (x / 255.0).astype(np.float32) # 0 ~ 1사이의 값을 갖도록
# 확인
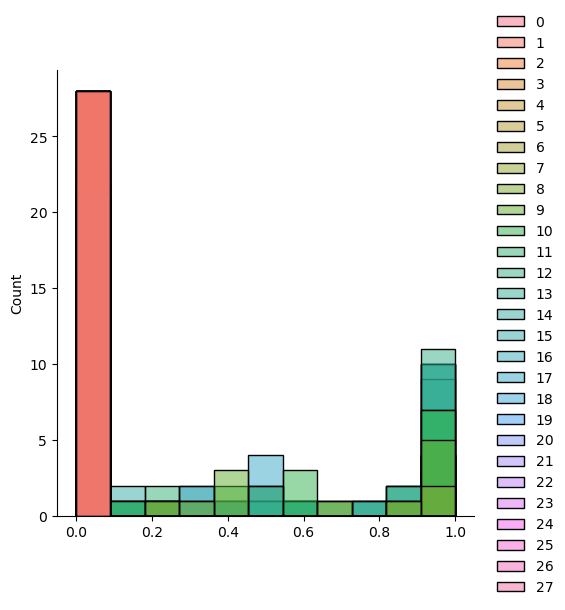
sample = scale(validated_train_x[777])
sample.max(), sample.min() # 직접 확인해보거나
sns.displot(sample) # 시각화하는 방법도 있다.
# 실제 데이터에 대한 실행 코드
scaled_train_x = np.array([scale(x) for x in validated_train_x])💻 출력
(1.0, 0.0)
Flattening
가끔 사용하는 모델에 따라 1차원 벡터가 input이 되는 레이어들이 있다. 이런 경우 모델에 입력하기 전 flatten 해주는 작업이 필요하다.
# 실행
flattend_train_x = scaled_train_x.reshape(60000, -1)
# 확인
flattend_train_x.shape # (60000, 784)Label Encoding
타겟 데이터가 범주형인 경우 'frog', 'deer'와 같은 이름이 들어간 것은 훈련에 사용할 수 없다. 이런 데이터가 받았을 땐 이를 카테고리 데이터로 변형시켜주어야한다.
그 중 하나가 One-Hot Encoding 작업으로 각 클래스에 해당하면 1, 나머지 클래스에 대해서는 0으로 매겨주는 작업이다.
tf.keras.utils.to_categorical(5, num_classes=10)💻 출력
array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)
# 실행
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_train_y])
# 확인
ohe_train_y.shape # (60000, 10)보통 이런 큰 작업들은 하나의 클래스로 만들어 보관함으로써 모든 데이터에 동일하게 적용하게끔 관리하고 있다.
class DataLoader():
def __init__(self):
# 데이터 불러오기
(self.train_x, self.train_y), \
(self.test_x, self.test_y) = tf.keras.datasets.mnist.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
"""
Make pixels within 0 ~ 1
return
scaled image (dtype=float32)
"""
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
"""
feature
shape : (num_data, 28, 28)
target
shape : (num_data,)
return
feature
shape : (num_data, 28, 28)
target
shape : (num_data,)
"""
(feature, target) = dataset
validated_x = np.array(
[x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target)
if self.validate_pixel_scale(x)])
# scaling #
scaled_x = np.array([self.scale(x) for x in validated_x])
# flattening #
flattend_x = scaled_x.reshape((scaled_x.shape[0], -1))
# label encoding #
ohe_y = np.array([tf.keras.utils.to_categorical(
y, num_classes=10) for y in validated_y])
return flattend_x, ohe_y
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))위와 같이 클래스로 작성해주고 아래와 같이 객체를 생성하여 코드를 실행시켜주면 된다.
# 객체 생성
mnist_loader = DataLoader()
# train 데이터에 대해 실시
train_x, train_y = mnist_loader.get_train_dataset()
# test 데이터에 대해 실시
test_x, test_y = mnist_loader.get_test_dataset()
# 확인
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)
print(test_x.shape, test_x.dtype)
print(test_y.shape, test_y.dtype)Modeling
Modeling에는 크게 3가지의 과정이 있다.
- 모델 정의
- 학습 로직 - 비용함수, 학습 파라미터 세팅
- 학습
3단계를 한 번 실습해보자.
1. 모델 정의
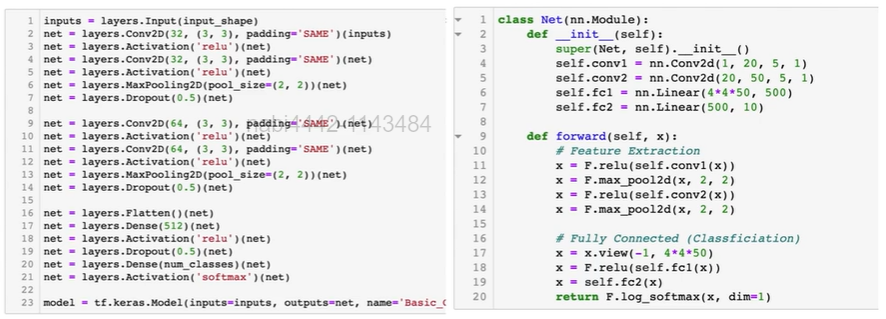
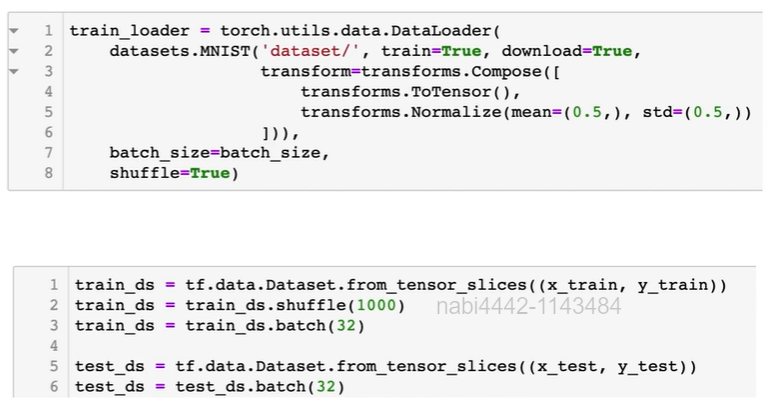
tensorflow에는 모델을 정의할 수 있는 방법이 여러가지가 있는데 지금은 그 첫 번째 방법인 Sequential을 통해 생성해보자.
.add를 통해 레이어를 추가해주면 된다.
from tensorflow.keras.layers import Dense, Activation
model = tf.keras.Sequential()
# .add를 통해 레이어를 추가할 수 있음
model.add(Dense(15, input_dim = 784))
model.add(Activation('sigmoid'))
model.add(Dense(10)) # output dim에 맞게 설정
model.add(Activation('softmax'))
# 모델 정보 확인
model.summary()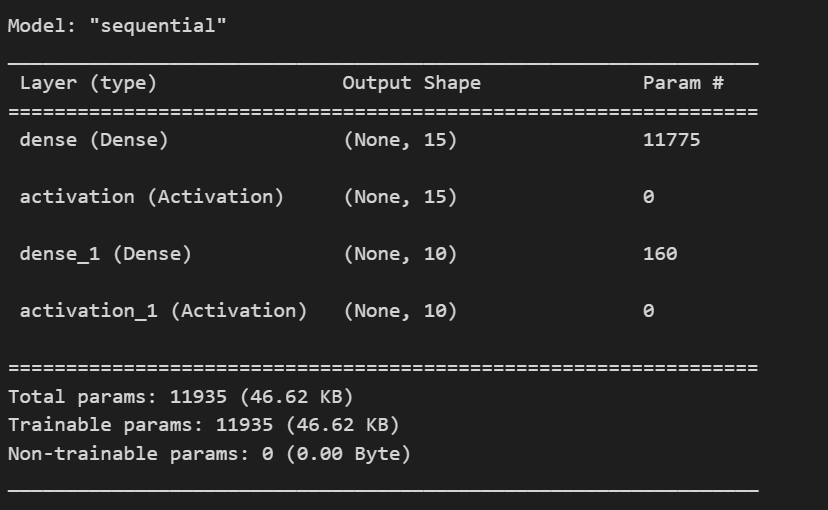
2. 학습 로직
이 단계에서는 optimizer와 loss 를 정의하고 compile 하는 과정을 말한다.
learning_rate = 0.03
opt = tf.keras.optimizers.SGD(learning_rate) # 최적화
loss = tf.keras.losses.categorical_crossentropy # loss
# 모델 정의(최적화를 어떻게 하고, loss 함수는 무엇을 할건지, 모델의 성능의 지표는 무엇으로 할건가)
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])3. 학습
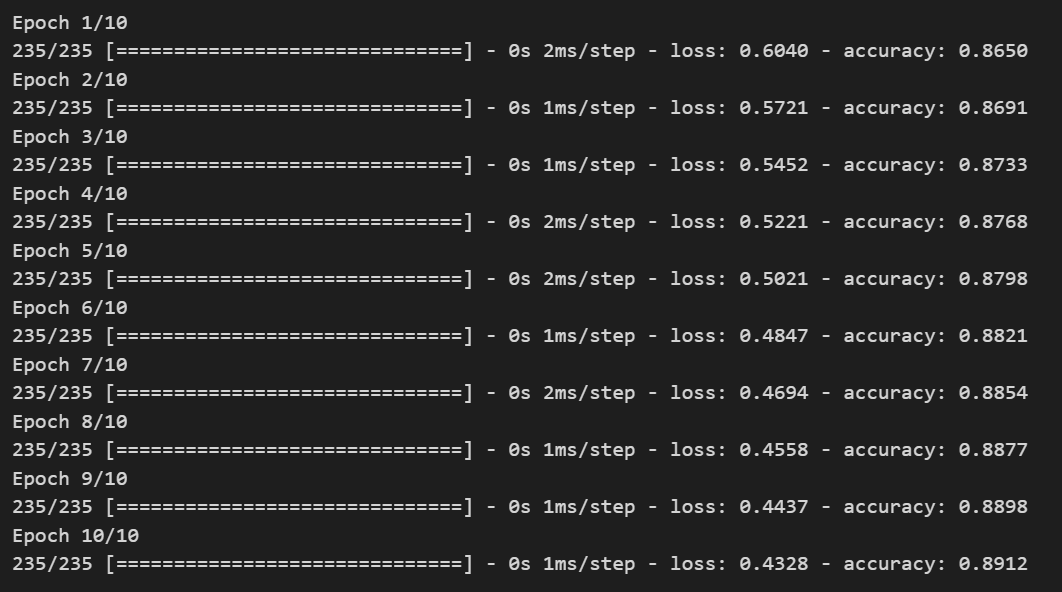
학습은 .fit을 통해 진행할 수 있다.
# .fit
hist = model.fit(train_x, train_y, epochs = 10, batch_size=256)💻 출력
Evaluation
학습을 다 했다면 모델을 평가하는 과정이 필요하다.
이 단계도
- 학습 과정을 추적하고
- Test 데이터에 대해 모델을 다시 또 검증해보고
- 후처리하는
단계로 이루어진다.
1. 학습 과정 추적
plt.figure(figsize = (10, 5))
plt.subplot(121)
plt.plot(hist.history['loss'])
plt.subplot(122)
plt.plot(hist.history['accuracy'])
plt.show()💻 출력
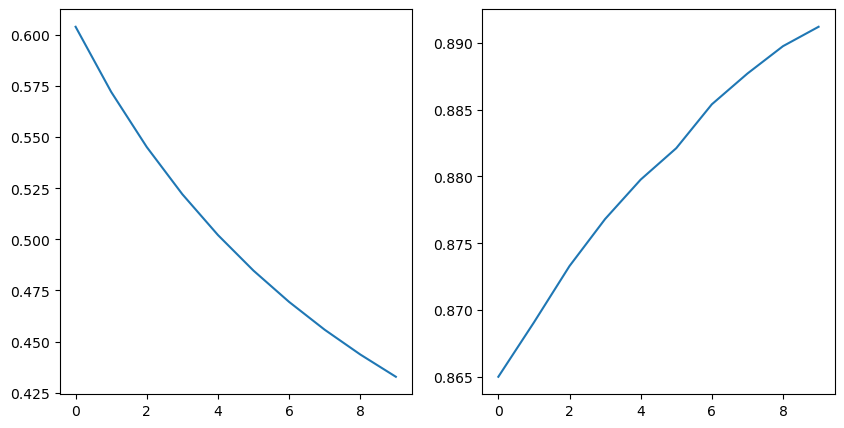
기본적으로 위와 같이 시각화하는 방식이 있다.
원래 loss가 어느정도 떨어지고 유지되는 구간이 있어야 안정적으로 수렴했다고 보는데 계속 떨어지는 추세를 보이고 있으므로 더 학습시킬 필요가 있구나! 라는 인사이트를 얻어갈 수 있다.
2. 모델 검증
Test 데이터에 대해 모델을 검증해보는 과정으로 .evaluate를 사용하면 된다.
# .evaluate
model.evaluate(test_x, test_y)💻 출력

위와 같이 Test 데이터에 대한 loss와 acc을 반환해준다.
3. 후처리
만약 학습이 만족스럽게 되었다면 실제로 배포하거나, 만족스럽지 못했다면 모델을 수정할 수 있을 것이다.
학습이 만족스러웠다는 가정하에 Test 데이터에 대해 어떻게 예측을 했는지 확인을 할 수 있는데 .predict를 통해 예측을 해주자.
# .predict
pred = model.predict(test_x[:1])
pred.argmax()이 문제는 분류 문제이므로 argmax를 통해 가장 큰 값을 가지는 인덱스가 무엇인지 추출해주어야한다.
그리고 실제 데이터와 맞는지 확인해보면 된다.
test_y[0] # 이렇게 확인해도 되지만
# array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], dtype=float32)
# 이미지로 확인하는 것이 더 좋음
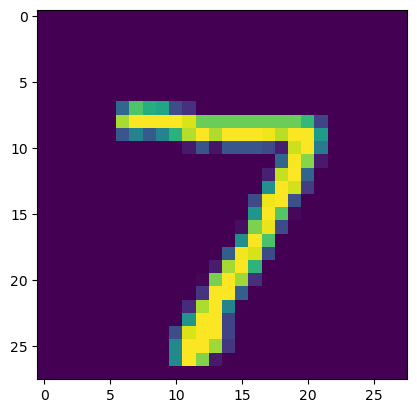
sample_image = test_x[0].reshape((28, 28)) * 255 # 복구
plt.imshow(sample_image)
plt.show()💻 출력