
✍🏻 1일 공부 이야기.

오늘 실습한 코드 내용은 위 깃허브에 업로드해두었습니다. 사진을 클릭하면 이동해요 !
Pytorch
!pip3 install torch torchvision torchaudio
torch는 numpy대신 tensor를 사용하여 딥러닝에 많이 쓰이고 있다.
예를들어 아래와 같은 계산을 numpy가 아닌 tensor로 할 수 있고 제일 좋은 점은 기울기 계산을 .grad하나로 해결할 수 있다는 것이다.
import torch
# 일반적인 코드
x = 3.5
y = x*x + 2
# 토치에서
x = torch.tensor(3.5)
# 기울기를 계산할 수 있는 옵션 : requires_grad
x = torch.tensor(3.5, requires_grad=True)
# 만약 어떤 함수에서 x가 3.5일 때의 함수값을 찾고 싶다면
y = (x-1)*(x-2)*(x-3) # tensor(1.8750, grad_fn=<MulBackward0>)
# x값에서의 기울기 계산
y.backward()
x.gradpytroch를 활용해 다양한 실습을 해보자.
보스턴 집 값 예측(회귀)
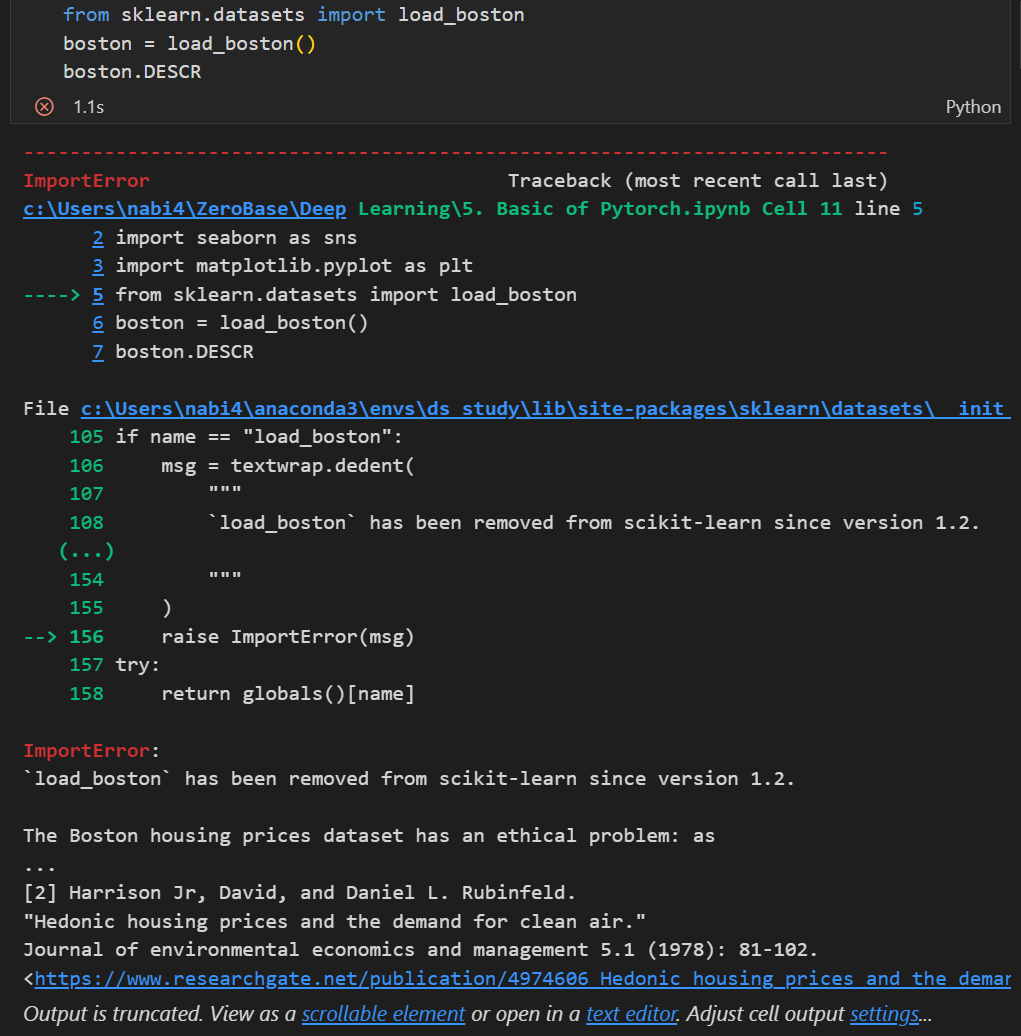
현재 버전에서 load_boston은 사라졌다.
그러므로 아래와 같이 데이터를 받거나 아니면 csv 파일을 다운받아 사용하면 된다.
📌 데이터 준비
from sklearn import datasets
X, y = datasets.fetch_openml('boston', return_X_y=True)EDA
torch에서 사용할 수 있도록 위 데이터를 변환시켜주어야한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 필요한 특성 선택
cols = ['INDUS', 'RM', "LSTAT", "NOX", "DIS"]
# numpy배열을 torch 텐서로 변환하고 float으로 변환
data_x = torch.from_numpy(X[cols].values).float()
data_y = torch.from_numpy(y.values).float()
data_x.shape # torch.Size([506, 5])
# 변수 정리
X = data_x
y = data_y.reshape(len(y), 1)
print(X.shape, y.shape) # torch.Size([506, 5]) torch.Size([506, 1])필요한 컬럼들을 선택하고 numpy 배열을 tensor로 변환시켜준 후, 변수명을 정리해주었다.
 데이터프레임 데이터프레임 |  tensor tensor |
|---|
모델링
📌 하이퍼파라미터 설정
# 하이퍼파라미터
n_epochs = 2000
learning_rate = 1e-3
print_interval = 100📌 모델 구성

회귀 예측이므로 linear 모델을 한 번 사용해보자.
# 모델링
# nn.Linear(X 사이즈, y 사이즈, bias)
model = nn.Linear(X.size(-1), y.size(-1))
# optimizer
optimizer = optim.SGD(model.parameters(), lr = learning_rate)X.size(-1)는 X.size의 마지막 dim을 반환해준다. 이때 size는 shape과 동일한 기능을 한다.
위와 같이 모델을 구성하고 optimizer 설정까지 다 끝났다면 학습을 시켜주자.
📌 학습
# 학습
for i in range(n_epochs):
y_hat = model(X) # 예측값
loss = F.mse_loss(y_hat, y) # loss 계산
optimizer.zero_grad() # optimizer의 gradient 초기화
# 각 학습 단계마다의 gradient값 그 자체를 가지기 위해
# 이전 학습 단계에서 사용했던 gradient는 초기화해주어야함
loss.backward() # 모델의 파라미터에 대한 gradient 계산 -> 역전파 계산
optimizer.step() # 계산된 gradient를 사용하여 파라미터(weight, bias) 업데이트
if (i + 1) % print_interval == 0: # 100번째마다 loss 출력
print('Epoch %d : loss = %.4e' % (i + 1, loss))💻 출력
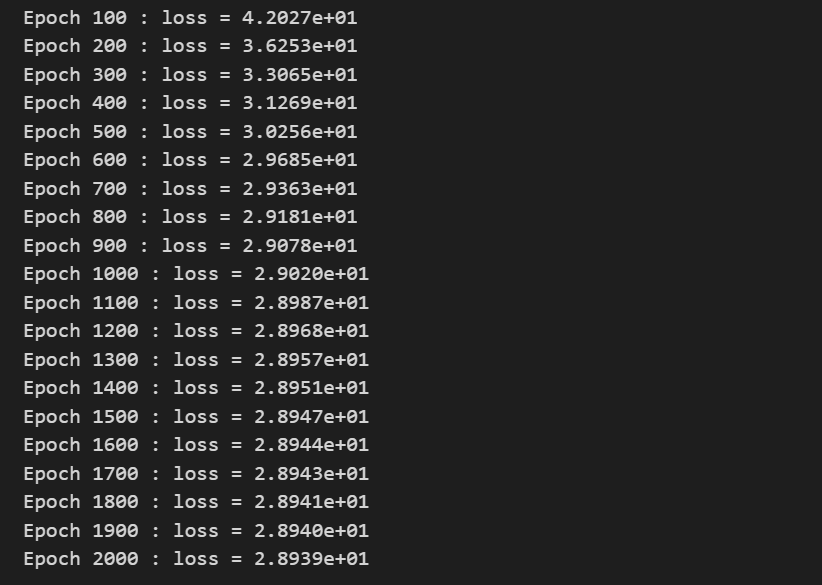
torch에서 학습을 시키는 코드는 위와 같다.
조금 복잡해보이지만.. 살펴보면 오히려 더 간단하다.
y_hat: 모델을 통해 예측값 계산loss: loss 계산(예측값 - 실제값).zero_grad():Gradient초기화 (🌟🌟🌟🌟🌟).backward(): 모델의 파라미터(weight, bias)에 대한Gradient계산 ->역전파계산.step(): 계산된Gradient를 통해 파라미터(weight, bias) 업데이트- 위 과정 반복
이때 각 학습 단계마다의 gradient 값으로 파라미터를 업데이트해야하므로 이전 학습단계의 gradient를 초기화하고 다시 계산해야한다는 것이 제일 중요하다!!!
📌 성능 확인
# 결과 정리
df = pd.DataFrame(torch.cat([y, y_hat], dim = 1).detach_().numpy(),
columns = ['y', 'y_hat'])
sns.pairplot(df, height=5)
plt.show()💻 출력
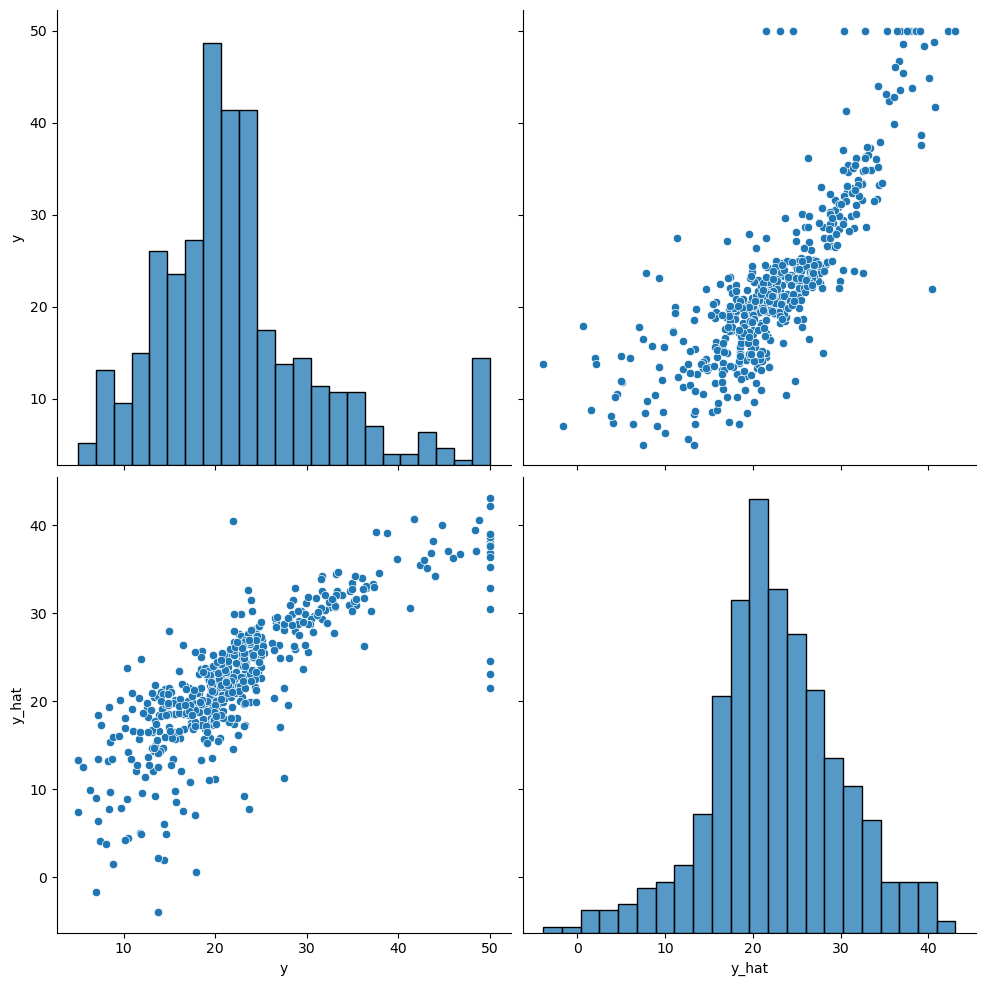
대부분 잘 예측한 것 같다!
Breast Cancer(이진 분류)
다음으로는 단일 분류 문제인 암 판정 데이터를 딥러닝으로 예측해보자.
📌 데이터 준비
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
# 데이터 정리
df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
df['class'] = cancer.target
# 특정 컬럼 추출
cols = ['mean radius', 'mean texture','mean smoothness', 'mean compactness','mean concave points',
'worst radius', 'worst texture','worst smoothness', 'worst compactness','worst concave points',
'class']
# torch화
data = torch.from_numpy(df[cols].values).float()
# 데이터 분리
X = data[:, :-1]
y = data[:, -1:]
X.shape, y.shape # (torch.Size([569, 10]), torch.Size([569, 1]))모델링
이번에는 이진 분류 문제이므로 linear 모델을 통과시키고 마지막에 sigmoid함수를 통과시켜 output이 2개만 나오도록 해주었다.
그리고 이번에는 모델을 클래스로 정의해보았다.
📌 모델 구성
# 하이퍼파라미터
n_epochs = 200000
learning_rate = 1e-2
print_interval = 10000
# 모델링(Pytorch 모델을 구현하기 위한 클래스)
class MyModel(nn.Module): # nn.Module을 상속받는 클래스 정의
# 모델의 초기화
def __init__(self, input_dim, output_dim):
self.input_dim = input_dim
self.output_dim = output_dim
# super 설정을 해주어야지만 nn.Module의 속성을 상속받음
super().__init__()
# 모델 설정
self.linear = nn.Linear(input_dim, output_dim) # 선형 모델
self.act = nn.Sigmoid() # output은 sigmoid(데이터가 이진분류이니깐)
# 순방향 연산
def forward(self, x):
y = self.act(self.linear(x))
return y
# 모델 선언 및 loss, optimizer 선언
model = MyModel(input_dim = X.size(-1), output_dim = y.size(-1))
crit = nn.BCELoss() # loss function : Binary Cross Entropy
optimizer = optim.SGD(model.parameters(), lr = learning_rate)📌 학습 및 성능 평가
# 학습
for i in range(n_epochs):
y_hat = model(X)
loss = crit(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % print_interval == 0: # 100번째마다 loss 출력
print('Epoch %d : loss = %.4e' % (i + 1, loss))
# 성능 평가
correct_cnt = (y == (y_hat > .5)).sum()
total_cnt = float(y.size(0))
print('Accuracy : %.4f' % (correct_cnt / total_cnt))💻 출력
Accuracy : 0.9649
이진 분류의 값을 갖도록 0.5 이상인 값은 1로 판단하도록 한 후 성능을 평가해본 결과 96.4%의 준수한 성능을 보여주었다.
MNIST(다중 분류)
cuda(GPU 설정)
계산량이 많아지면 cpu보단 gpu에서 학습시키는 것이 계산 속도가 빨라진다.
아래와 같은 코드를 실행시켜 gpu를 사용할 수 있다면 cuda가 출력되는데 현재 내가 사용하고 있는 노트북에선 gpu 설정이 되어있지 않아서 cpu로 작동시켰다.
# cuda 환경 설정
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
print('Current cuda device is ', device)아마 colab에서 [런타임 유형]을 gpu로 설정하고 해당 코드를 실행시키면 cuda 환경으로 작동시킬 수 있을 것이다!
이제 본격적으로 데이터를 준비하고 torch로 MNIST를 학습시켜보자.
📌 데이터 준비
# 데이터 준비
# datasets 모듈에 있는 MNIST 데이터를 바로 다운받고
# tensor로 까지 변환까지 해줌
train_data = datasets.MNIST(root = './data', train = True,
download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST(root = './data', train = False,
transform=transforms.ToTensor())
print('Number of training data : ' , len(train_data))
print('Number of test data : ' , len(test_data))💻 출력
Number of training data : 60000
Number of test data : 10000
위 코드는 datasets 모듈에서 제공하는 MNIST 데이터를 바로 다운받아 사용할 수 있는 코드이다.
transform 옵션 설정을 하면 다운 받을 때 tensor로 변환까지 한 번에 할 수 있어 아주 유용하다!! (MNIST 데이터 받는 방법이 참 많은 것 같다 🫠)
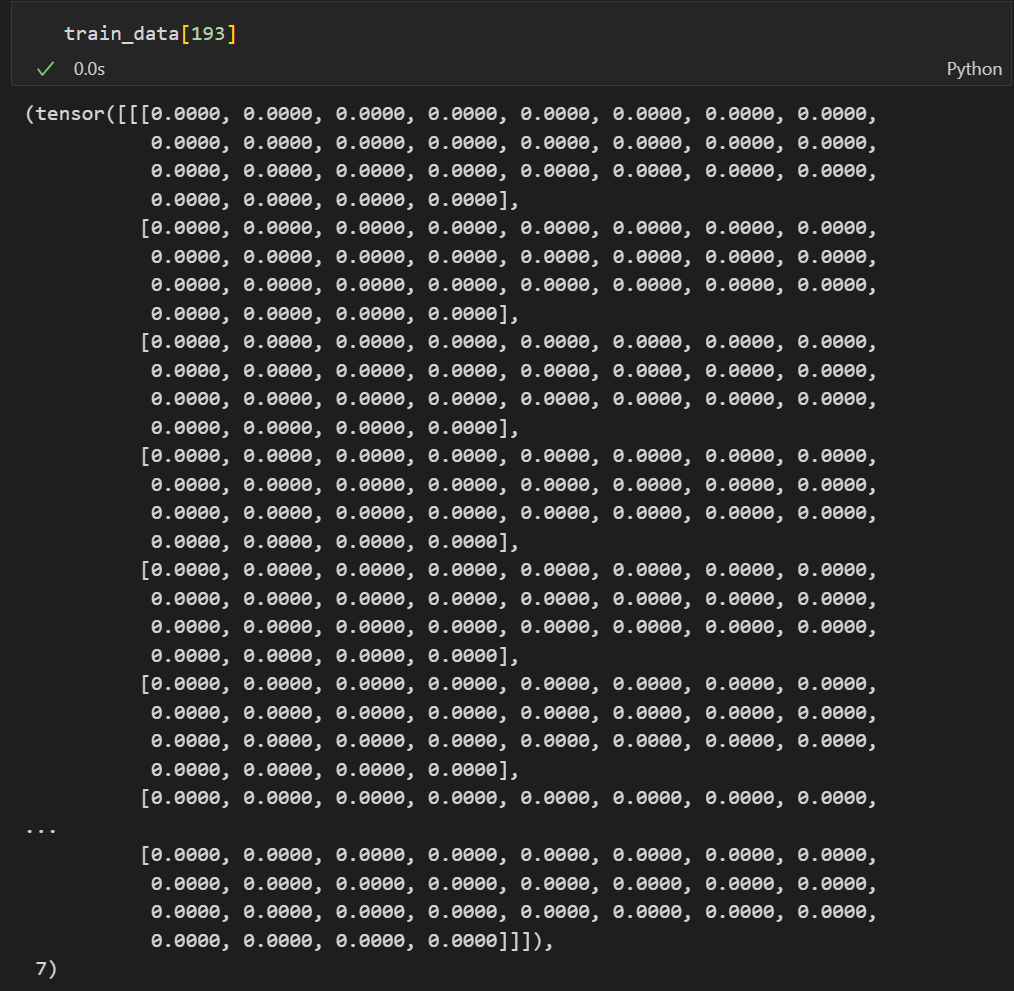
데이터를 하나 랜덤으로 추출해보았는데 train_data[193][0].shape 을 통해 torch.Size([1, 28, 28]) 사이즈임을 알 수 있었고
출력된 결과를 보아 앞에는 픽셀 데이터, 마지막은 라벨 데이터로 보인다.
이 데이터를 직접 보려면 아래와 같은 코드를 실행시키면 된다.
# 데이터 보기
image, label = train_data[193]
# sqeeze() : dim이 1인 것을 삭제시킴
plt.imshow(image.squeeze().numpy(), cmap = 'gray')
plt.title('label : %s' %label)
plt.show()💻 출력
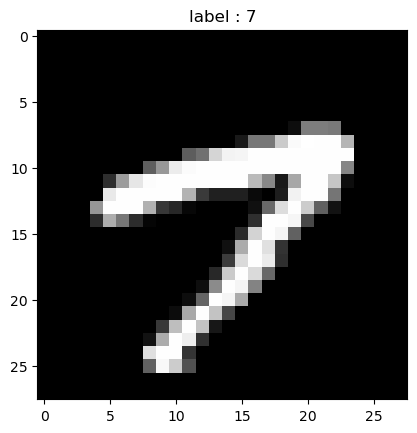
중요하게 보고 넘어가야할 점은 torch 에서 shape이 torch.Size([1, 28, 28]) 이렇게 나온 것과 연관이 있다.
tensor에서는 채널에 해당하는 dim이 맨 앞에 위치해있고 numpy에서는 채널에 해당하는 dim이 맨 마지막에 위치해있으므로 두 모듈을 번갈아 사용할 때 꼭 dim을 생각하면서 코드를 짜주어야한다!!!
그래서 위 그림을 출력할 땐 sqeeze()를 이용해 dim이 1에 해당하는 값은 삭제시키고 numpy로 변환시켜 imshow를 통과시켰다.
모델링
이번에는 앞선 과정과는 좀 다르게 배치를 나누어볼까 한다.
배치란, 데이터를 쪼개서 학습시킴으로써 메모리 사용량을 감소시키고 학습 속도를 향상시키는 등 다양한 이점을 가지게 해주는 것이다.
📌 미니 배치 구성
# 미니 배치 구성
batch_size = 50
learning_rate = 0.0001
epoch_num = 15
train_loader = torch.utils.data.DataLoader(dataset = train_data,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_data,
batch_size = batch_size,
shuffle = True)
first_batch = train_loader.__iter__().__next__() # 첫번째 배치만 가져옴📌 모델 구성
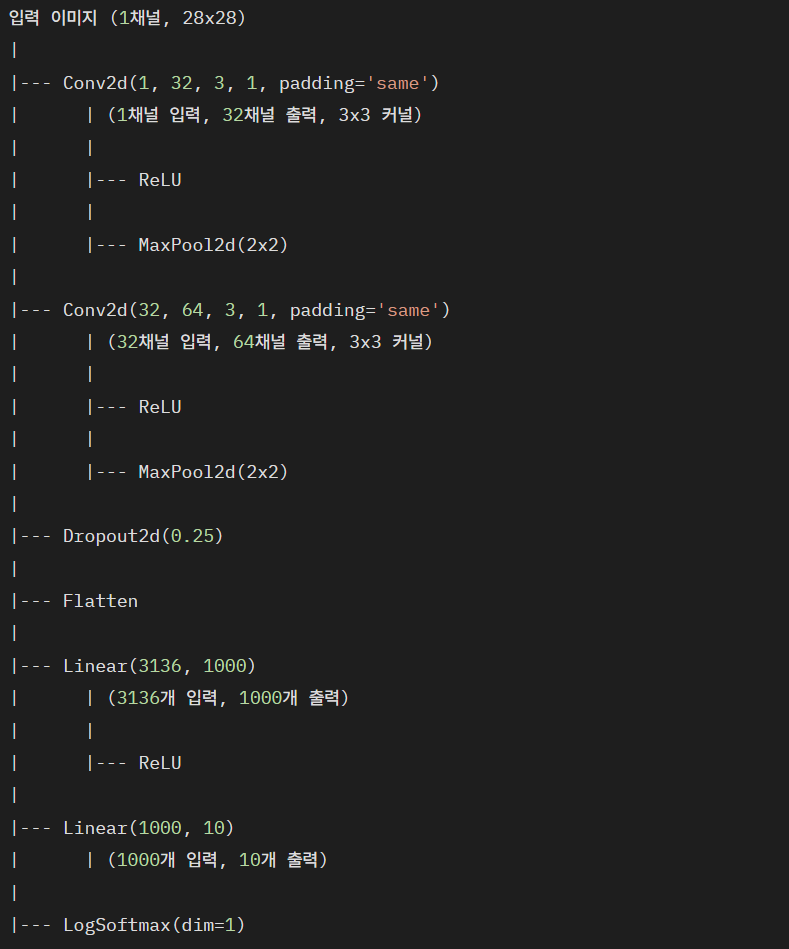
위와 같은 구조를 가진 CNN 모델을 클래스로 정의하면 아래와 같다.
# 모델링
class CNN(nn.Module): # nn.Module을 상속받는 클래스 정의
# 모델의 초기화
def __init__(self):
super(CNN, self).__init__()
## nn.Conv2D(입력받는 채널 수, 출력할 채널 수, 커널 사이즈, stride 수, 제로패딩 옵션)
self.conv1 = nn.Conv2d(1, 32, 3, 1, padding = 'same')
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding = 'same')
self.dropout = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(3136, 1000) # 7*7*64 = 3136
self.fc2 = nn.Linear(1000, 10)
# 순방향 연산
def forward(self, x):
x = self.conv1(x) # (28, 28)
x = F.relu(x)
x = F.max_pool2d(x, 2) # (14, 14)
x = self.conv2(x) # (14, 14)
x = F.relu(x)
x = F.max_pool2d(x, 2) # (7, 7)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim = 1)
return output
# 선언
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr = learning_rate)
criterion = nn.CrossEntropyLoss()📌 학습 및 성능 평가
# 학습
model.train() # 학습 모드 선언
i = 1 # 실제 학습
for epoch in range(epoch_num):
for data, target in train_loader: # 배치 단위로 나눈 데이터
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if i % 1000 == 0: # 100번째마다 loss 출력
print('Train Step : {}\tLoss: {:.3f}'.format(i, loss.item()))
i += 1
# 성능 평가
model.eval() # 평가 모드 선언 (dropout 기능 꺼짐)
correct = 0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
prediction = output.data.max(1)[1] # argmax 기능. max값을 가지는 인덱스를 추출
correct += prediction.eq(target.data).sum() # 정답지 개수를 계속 증가시켜줌
print('Test set Accuracy : {:.2f}%'.format(100. * correct / len(test_loader.dataset)))💻 출력
Test set Accuracy : 99.20%
학습(model.train())과 성능 평가(model.eval())를 할 때 모드를 선언할 수 있다.
모드를 선언해주면 아래와 같은 기능을 얻을 수 있다고 한다.
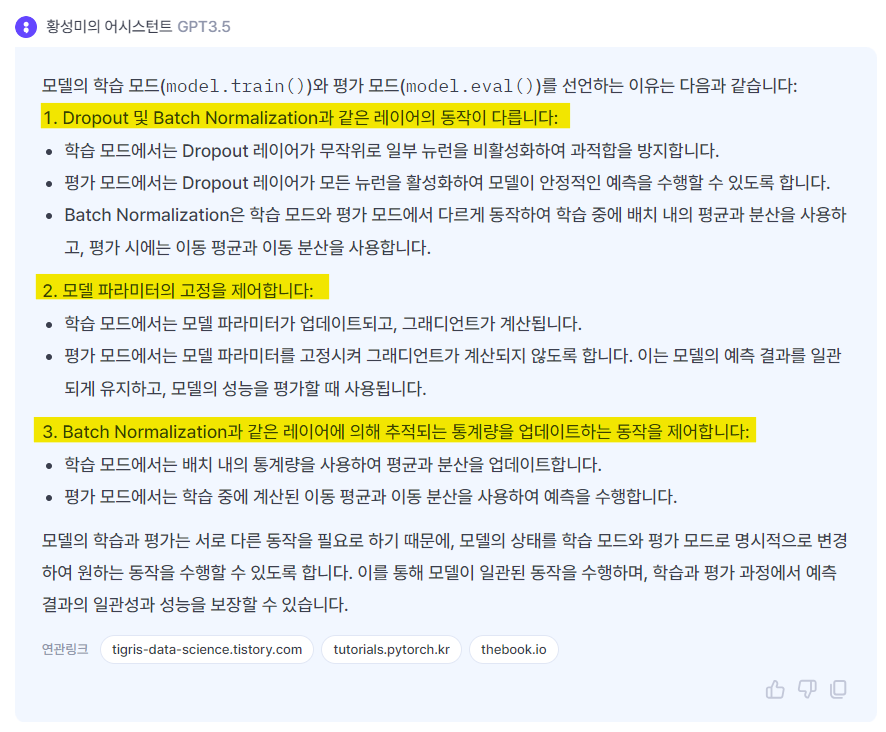
CNN으로 MNIST를 학습시켰더니... 무려 정확도가 99%로 라니 😚😚 정말 대단한 것 같다 ㅎㅎ
